您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
小编给大家分享一下python爬虫中requests库怎么用,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
requests是python实现的简单易用的HTTP库,使用起来比urllib简洁很多,requests 允许你发送 HTTP/1.1 请求。指定 URL并添加查询url字符串即可开始爬取网页信息等操作
因为是第三方库,所以使用前需要cmd安装
pip install requests
安装完成后import一下,正常则说明可以开始使用了
基本用法:
requests.get()用于请求目标网站,类型是一个HTTPresponse类型
import requests
response = requests.get('http://www.baidu.com')
print(response.status_code) # 打印状态码
print(response.url) # 打印请求url
print(response.headers) # 打印头信息
print(response.cookies) # 打印cookie信息
print(response.text) #以文本形式打印网页源码
print(response.content) #以字节流形式打印以打印状态码为例,运行结果:
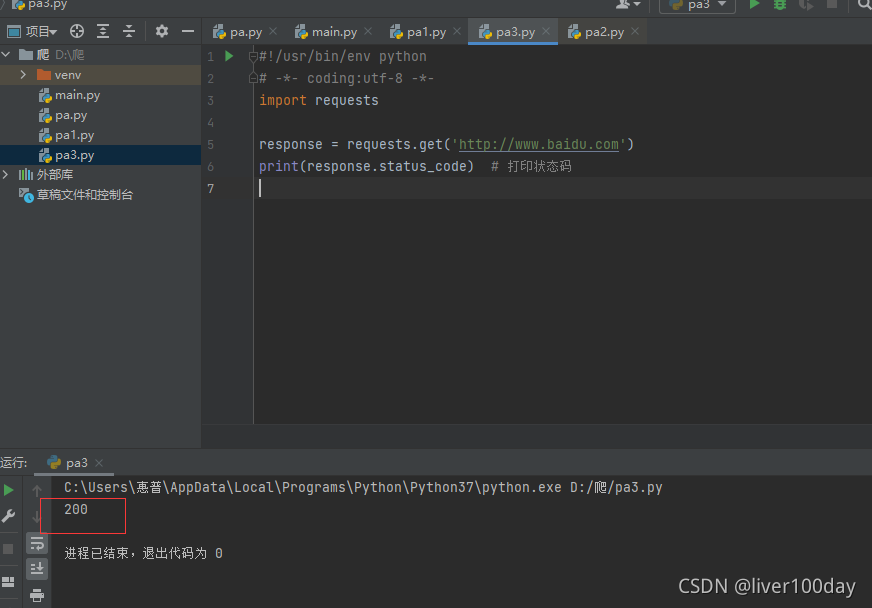
状态码:200,证明请求目标网站正常
若状态码为403一般是目标存有防火墙,触发了反爬策略被限制了IP
各种请求方式:
import requests
requests.get('http://www.baidu.com')
requests.post('http://www.baidu.com')
requests.put('http://www.baidu.com')
requests.delete('http://www.baidu.com')
requests.head('http://www.baidu.com')
requests.options('http://www.baidu.com')import requests
response = requests.get('http://www.baidu.com')
print(response.text)
第一种直接将参数放在url内
import requests
response = requests.get("https://www.crrcgo.cc/admin/crr_supplier.html?params=1")
print(response.text)
另一种先将参数填写在data中,发起请求时将params参数指定为data
import requests
data = {
'params': '1',
}
response = requests.get('https://www.crrcgo.cc/admin/crr_supplier.html?', params=data)
print(response.text)
基本POST请求:
import requests
response = requests.post('http://baidu.com')
import requests
response = requests.get('http://httpbin.org/get')
print(response.text)
print(response.json()) #response.json()方法同json.loads(response.text)
print(type(response.json()))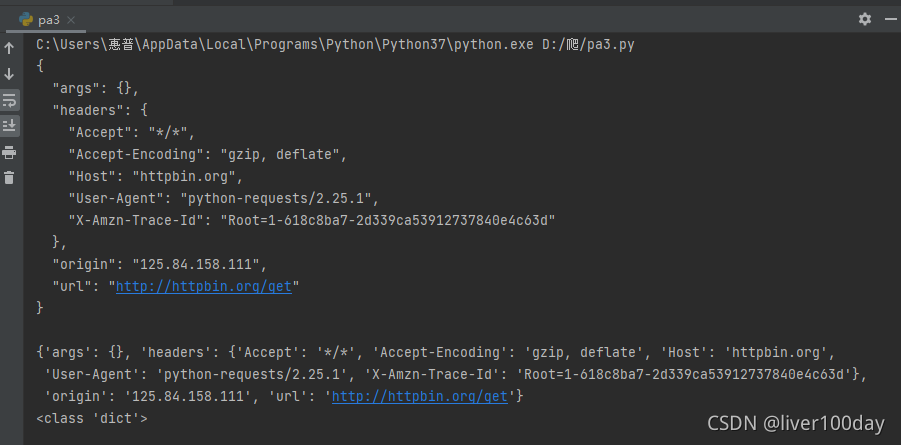
简单保存一个二进制文件
import requests
response = requests.get('http://img.ivsky.com/img/tupian/pre/201708/30/kekeersitao-002.jpg')
b = response.content
with open('F://fengjing.jpg','wb') as f:
f.write(b)为你的请求添加头信息
import requests
heads = {}
heads['User-Agent'] = 'Mozilla/5.0 ' \
'(Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 ' \
'(KHTML, like Gecko) Version/5.1 Safari/534.50'
response = requests.get('http://www.baidu.com',headers=headers)此方法可以有效地避开防火墙的检测,隐藏自己身份
同添加headers方法一样,代理参数也是一个dict这里使用requests库爬取了IP代理网站的IP与端口和类型。因为是免费的,使用的代理地址很快就失效了。
import requests
import re
def get_html(url):
proxy = {
'http': '120.25.253.234:812',
'https' '163.125.222.244:8123'
}
heads = {}
heads['User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'
req = requests.get(url, headers=heads,proxies=proxy)
html = req.text
return html
def get_ipport(html):
regex = r'<td data-title="IP">(.+)</td>'
iplist = re.findall(regex, html)
regex2 = '<td data-title="PORT">(.+)</td>'
portlist = re.findall(regex2, html)
regex3 = r'<td data-title="类型">(.+)</td>'
typelist = re.findall(regex3, html)
sumray = []
for i in iplist:
for p in portlist:
for t in typelist:
pass
pass
a = t+','+i + ':' + p
sumray.append(a)
print('高匿代理')
print(sumray)
if __name__ == '__main__':
url = 'http://www.baidu.com'
get_ipport(get_html(url))import requests
response = requests.get('http://www.baidu.com')
print(response.cookies)
print(type(response.cookies))
for k,v in response.cookies.items():
print(k+':'+v)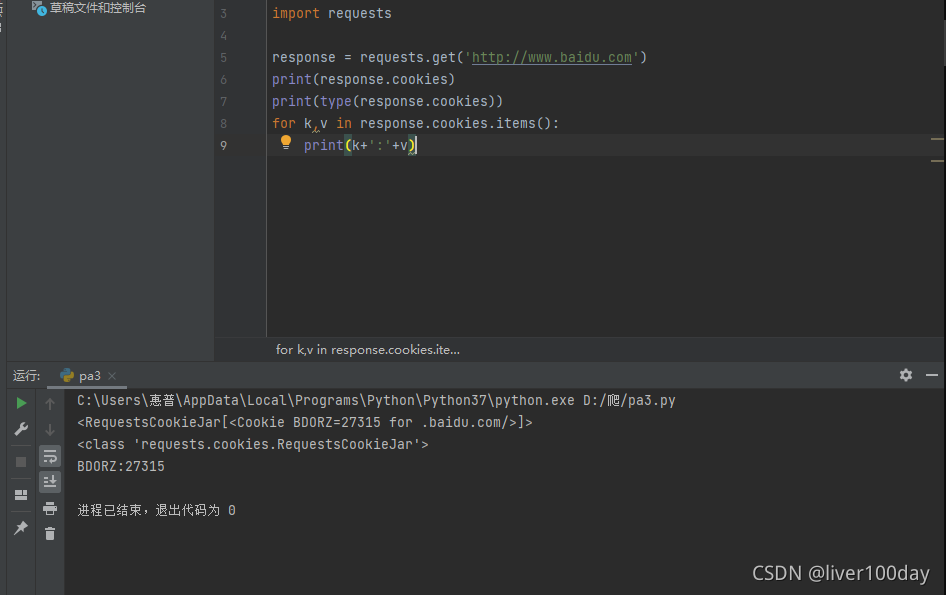
import requests
session = requests.Session()
session.get('https://www.crrcgo.cc/admin/crr_supplier.html')
response = session.get('https://www.crrcgo.cc/admin/')
print(response.text)import requests
from requests.packages import urllib3
urllib3.disable_warnings() #从urllib3中消除警告
response = requests.get('https://www.12306.cn',verify=False) #证书验证设为FALSE
print(response.status_code)import requests
from requests.exceptions import ReadTimeout
try:
res = requests.get('http://httpbin.org', timeout=0.1)
print(res.status_code)
except ReadTimeout:
print(timeout)使用try…except来捕获异常
import requests
from requests.exceptions import ReadTimeout,HTTPError,RequestException
try:
response = requests.get('http://www.baidu.com',timeout=0.5)
print(response.status_code)
except ReadTimeout:
print('timeout')
except HTTPError:
print('httperror')
except RequestException:
print('reqerror')以上是“python爬虫中requests库怎么用”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。