您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
小编给大家分享一下Python如何批量操作Excel文件,希望大家阅读完这篇文章之后都有所收获,下面让我们一起去探讨吧!
OS的全称是Operation System,指操作系统。在Python里面OS模块中主要提供了与操作系统即电脑系统之间进行交互的一些功能。我们很多的自动化操作都会依赖于该模块的功能。
我们在最开始Python基础知识那一章节给讲了如何安装Anaconda以及如何利用Jupyter notebook写代码。可是你们知道你们写在Jupyter notebook里面的代码存储在电脑的哪里吗?
是不是很多同学不知道?想要知道也很简单,只需要在Jupyter notebook中输入如下代码,然后运行:
import os os.getcwd()
运行上面代码会得到如下结果:
'C:\\Users\\zhangjunhong\\python库\\Python报表自动化'
上面这个文件路径就是此时notebook代码文件所在的路径,你的代码存储在哪个文件路径下,运行就会得到对应结果。
我们经常会将电脑本地的文件导入到Python中来处理,在导入之前需要知道文件的存储路径以及文件名。如果只有一两个文件的话还好,我们直接把文件名和文件路径手动输入即可,但是有的时候需要导入的文件会有很多。这个时候手动输入效率就会比较低,就需要借助代码来提高效率。
如下文件夹中有四个Excel文件:
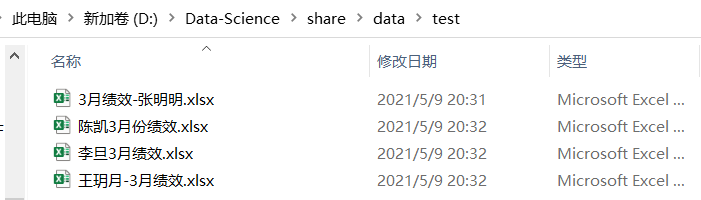
我们可以使用os.listdir(path)来获取path路径下所有的文件名。具体实现代码如下:
import os
os.listdir('D:/Data-Science/share/data/test')运行上面代码会得到如下结果:
['3月绩效-张明明.xlsx', '李旦3月绩效.xlsx', '王玥月-3月绩效.xlsx', '陈凯3月份绩效.xlsx']
对文件进行重命名也是比较高频的一种需求,我们可以利用os.rename('old_name','new_name')来对文件进行重命名。old_name就是旧文件名,new_name就是新文件名。
我们先在test文件夹下面新建一个名为test_old的文件,然后再利用如下代码,就可以把test_old文件名改成test_new:
os.rename('D:/Data-Science/share/data/test/test_old.xlsx'
,'D:/Data-Science/share/data/test/test_new.xlsx')运行上面代码以后,再到test文件夹下面,就可以看到test_old文件已经不存在了,只有test_new。
当我们想要在指定路径下创建一个新的文件夹时,可以选择手动新建文件夹,也可以利用os.mkdir(path)进行新建,只需要指明具体的路径(path)即可。
如下所示,当我们运行下面代码,就表示在D:/Data-Science/share/data路径下新建一个名为test11的文件夹:
os.mkdir('D:/Data-Science/share/data/test11')
删除文件夹与创建文件夹是相对应的,当然了,我们也可以选择手动删除一个文件夹,也可以利用os.removedirs(path)进行删除,指明要删除的路径(path)。
如下所示,当我们运行如下代码,就表示把刚刚创建的test11文件夹删除了:
os.removedirs('D:/Data-Science/share/data/test11')删除文件时删除一个具体的文件,而删除文件夹是将一整个文件夹,包含文件夹中的所有文件进行删除。删除文件利用的是os.remove(path),指明文件所在的路径(path)。
如下所示,当我们运行如下代码,就表示将test文件夹中test_new文件进行删除:
os.remove('D:/Data-Science/share/data/test/test_new.xlsx')有的时候一个文件夹下面会包含多个相类似的文件,比如一个部门不同人的绩效文件,我们需要把这些文件批量读取到Python里面中,然后进行处理。
我们在前面学过,如何读取一个文件,可以用load_work,也可以用read_excel,不管用哪种方式,都只需要指明要读取文件的路径即可。
那如何批量读取呢?先获取该文件下的所有文件名,然后再遍历读取每一个文件。具体实现代码如下所示:
import pandas as pd
#获取文件夹下的所有文件名
name_list = os.listdir('D:/Data-Science/share/data/test')
#for循环遍历读取
for i in name_list:
df = pd.read_excel(r'D:/Data-Science/share/data/test/' + i)
print('{}读取完成!'.format(i))如果要对读取进来的文件进行数据操作的时候,把具体的操作实现代码放置在读取代码之后即可。比如我们要对每一个读取进来的文件进行删除重复值处理,实现代码如下:
import pandas as pd
#获取文件夹下的所有文件名
name_list = os.listdir('D:/Data-Science/share/data/test')
#for循环遍历读取
for i in name_list:
df = pd.read_excel(r'D:/Data-Science/share/data/test/' + i)
df = df.drop_duplicates() #删除重复值处理
print('{}读取完成!'.format(i))有的时候我们需要根据特定的主题来创建特定的文件夹,比如需要根据月份创建12个文件夹。我们前面学过如何创建单个文件夹,要批量创建多个文件夹,只需要遍历执行单个文件夹的语句即可。具体实现代码如下:
month_num = ['1月','2月','3月','4月','5月','6月','7月','8月','9月','10月','11月','12月']
for i in month_num:
os.mkdir('D:/Data-Science/share/data/' + i)
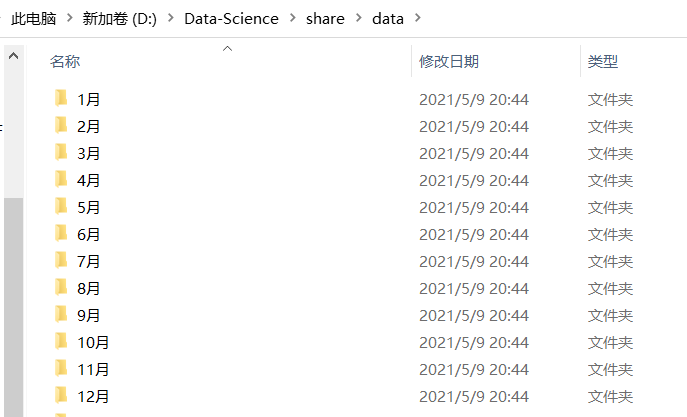
print('{}创建完成!'.format(i))运行上面代码以后就会在该文件路径下新建了12个文件夹:
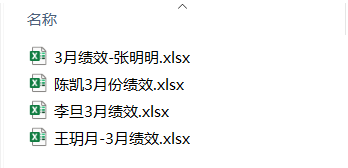
有的时候我们有好多相同主题的文件,但是这些文件的文件名比较混乱,比如下面这些文件,是各个员工的3月绩效情况,但是命名格式都不太一样,我们要将其统一成名字+3月绩效这样的格式。要达到这种效果,可以通过前面学到的对文件进行重命名操作来实现,前面只讲了对单一文件的操作,那如何同时对多个文件进行批量操作呢?
具体实现代码如下:
import os
#获取指定文件下所有文件名
old_name = os.listdir('D:/Data-Science/share/data/test')
name = ["张明明","李旦","王玥月","陈凯"]
#遍历每一个姓名
for n in name:
#遍历每一个旧文件名
for o in old_name:
#判断旧文件名中是否包含特定的姓名
#如果包含就进行重命名
if n in o:
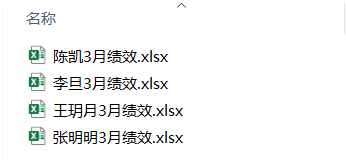
os.rename('D:/Data-Science/share/data/test/' + o, 'D:/Data-Science/share/data/test/' + n +"3月绩效.xlsx")运行上面代码以后可以看到文件下的原文件名全部已被重命名完成。
如下所示,该文件夹下面有1-6月的分月销售日报,已知这些日报的结构是相同的,只有日期和销量两列,现在我们想要把这些不同月份的日报合并成一份。
将分月销售日报合并成一份文件的具体实现代码如下:
import os
import pandas as pd
#获取指定文件下所有文件名
name_list = os.listdir('D:/Data-Science/share/data/sale_data')
#创建一个相同结构的空DataFrame
df_o = pd.DataFrame({'日期':[],'销量':[]})
#遍历读取每一个文件
for i in name_list:
df = pd.read_excel(r'D:/Data-Science/share/data/sale_data/' + i)
#进行纵向拼接
df_v = pd.concat([df_o,df])
#把拼接后的结果赋值给df_o
df_o = df_v
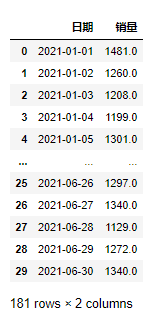
df_o运行上面代码就会得到合并后的文件df_o,如下所示:
上面讲了如何批量合并多个文件,我们也有合并多个文件逆需求,即按照指定列将一个文件拆分成多个文件。
还是上面的数据集,假设我们现在拿到了一份1-6月份的文件,这份文件除了日期和销量两列以外,还多了一列月份,现在我们需要做的就是根据月份这一列将这一份文件拆分成多个文件,每个月份单独存储为一个文件。
具体实现代码如下:
#生成一列新的月份列 df_o['月份'] = df_o['日期'].apply(lambda x:x.month) #遍历每一个月份值 for m in df_o['月份'].unique(): #将特定月份值的数据筛选出来 df_month = df_o[df_o['月份'] == m] #将筛选出来的数据进行保存 df_month.to_csv(r'D:/Data-Science/share/data/split_data/' + str(m) + '月销售日报_拆分后.csv')
运行上面代码我们就可以在目标路径下看到拆分后的多个文件:
看完了这篇文章,相信你对“Python如何批量操作Excel文件”有了一定的了解,如果想了解更多相关知识,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。