您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本期内容:
解密Spark Streaming 运行机制
解密Spark Streaming 框架
Spark Streaming是Spark的一个子框架,但是它更像是运行在Spark Core上的一个应用程序。Spark Streaming在启动时运行了很多的job,并且job之间相互配合。
Job围绕了两个方面:
1. 对输入数据流进行计算的Job
2. 框架自身运行需要的Job,例如Receiver启动。
Spark Streaming本身就是一个非常复杂的应用程序,如果你对SparkStreaming了如指掌,那么你将非常轻松的编写任意的应用程序。
我们看一下Spark的架构图:
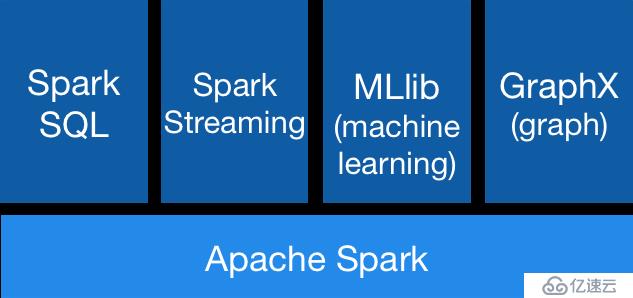
Spark core上面有4个流行的框架:SparkSQL、流计算、机器学习、图计算
除了流计算,其他的框架大多都是在SparkCore上对一些算法或者接口进行了高层的封装。例如SparkSQL 封装了SQL语法,主要功能就是将SQL语法解析成SparkCore的底层API。而机器学习则是封装了很多的数学向量及算法。GraphX目前也没有太大的更新。
只有对SparkStreaming彻底了解,才能对提升我们写应用程序有很大的帮助。
基于Spark Core的时候,都是基于RDD编程,而基于SparkStreaming则是基于DStream编程。DStream就是在RDD的基础上,加上了时间维度:
private[streaming] var generatedRDDs = new HashMap[Time, RDD[T]] ()
DStream的compute需要传入一个时间参数,通过时间获取相应的RDD,然后再对RDD进行计算
/** Method that generates a RDD for the given time */ def compute(validTime: Time): Option[RDD[T]]
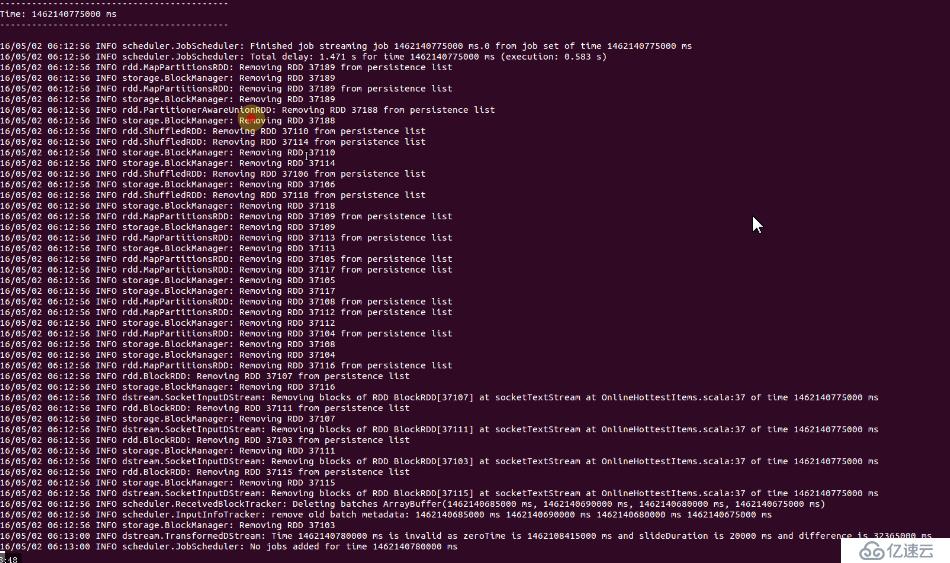
我们查看SparkStreaming的运行日志,就可以看出和RDD的运行几乎是一致的:
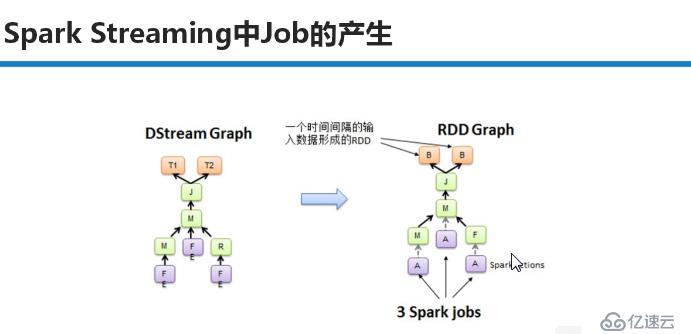
SparkStreaming Job在运行的时候,首先会生成DStream的Graph,在特定的时间将DStream Graph转换成RDD Graph。然后再去运行RDD的job 。如下图:
如果我们把RDD看成一个空间上的维度,那么DStream就是在RDD上加入了时间维度的时空维度。
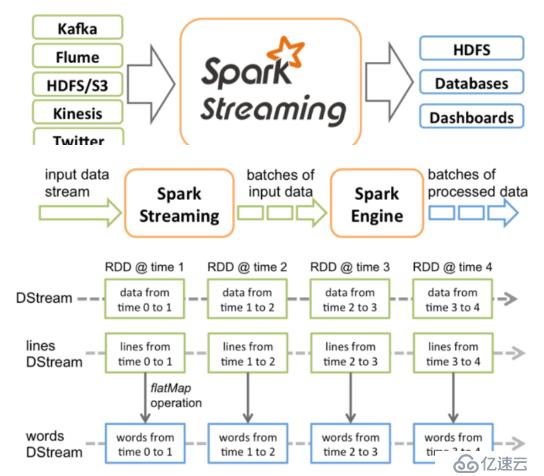
我们可以想象一下,在一个二维空间中,X轴是时间,Y轴是对RDD的操作,也就是所谓的RDD的依赖关系构成的整个job的逻辑。随着时间的进行,会生成一个个的job实例。
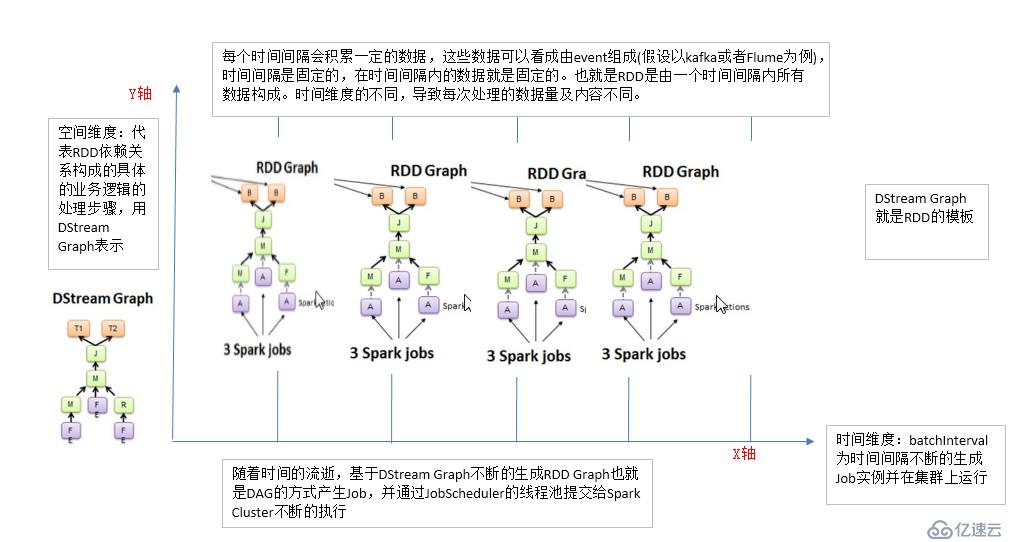 所以SparkStreaming需要提供如下的功能:
所以SparkStreaming需要提供如下的功能:
需要RDD Graph生成的模板DStreamGraph
需要基于时间的job控制器
需要InputStream和OutputStream代表数据的输入和输出
将具体的job提交到Spark Cluster上,因为SparkStreaming是不断的在运行job,更容易出现问题,所以容错就至关重要(单个job的容错是基于Sparkcore的,SparkStreaming还要提供自己框架的容错功能)。
事务处理,数据一定会被处理,并且只会被处理一次。也就是说每次处理数据的时候,要知道数据的边界。特别是出现崩溃的情况下。
备注:
1、DT大数据梦工厂微信公众号DT_Spark
2、IMF晚8点大数据实战YY直播频道号:68917580
3、新浪微博: http://www.weibo.com/ilovepains
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。