жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷжңҹеҶ…е®№еҪ“дёӯе°Ҹзј–е°Ҷдјҡз»ҷеӨ§е®¶еёҰжқҘжңүе…іC++й«ҳ并еҸ‘еңәжҷҜдёӢиҜ»еӨҡеҶҷе°‘зҡ„дјҳеҢ–ж–№жЎҲжҳҜд»Җд№ҲпјҢж–Үз« еҶ…е®№дё°еҜҢдё”д»Ҙдё“дёҡзҡ„и§’еәҰдёәеӨ§е®¶еҲҶжһҗе’ҢеҸҷиҝ°пјҢйҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еёҢжңӣеӨ§е®¶еҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
дёҖи°ҲеҲ°й«ҳ并еҸ‘зҡ„дјҳеҢ–ж–№жЎҲпјҢеҫҖеҫҖиғҪжғіеҲ°жЁЎеқ—ж°ҙе№іжӢҶеҲҶгҖҒж•°жҚ®еә“иҜ»еҶҷеҲҶзҰ»гҖҒеҲҶеә“еҲҶиЎЁпјҢеҠ зј“еӯҳгҖҒеҠ mqзӯүпјҢиҝҷдәӣйғҪжҳҜд»Һзі»з»ҹжһ¶жһ„дёҠи§ЈеҶігҖӮеҚ•жЁЎеқ—дҪңдёәзі»з»ҹзҡ„з»„жҲҗеҚ•е…ғпјҢе…¶жҖ§иғҪеҘҪеқҸд№ҹиғҪеҫҲеӨ§зҡ„еҪұе“Қж•ҙдҪ“жҖ§иғҪпјҢжң¬ж–Үд»ҺеҚ•жЁЎеқ—дёӢиҜ»еӨҡеҶҷе°‘зҡ„еңәжҷҜеҮәеҸ‘пјҢжҺўи®Ёе…¶и§ЈеҶіж–№жЎҲпјҢд»Ҙе…¶жӣҙеҘҪзҡ„е®һзҺ°й«ҳ并еҸ‘гҖӮ
дёҚеҗҢзҡ„дёҡеҠЎеңәжҷҜпјҢиҜ»е’ҢеҶҷзҡ„йў‘зҺҮеҗ„жңүдҫ§йҮҚпјҢжңүдёӨз§Қеёёи§Ғзҡ„дёҡеҠЎеңәжҷҜпјҡ
иҜ»еӨҡеҶҷе°‘пјҡе…ёеһӢеңәжҷҜеҰӮе№ҝе‘ҠжЈҖзҙўз«ҜгҖҒзҷҪеҗҚеҚ•жӣҙж–°з»ҙжҠӨгҖҒloadbalancer
иҜ»е°‘еҶҷеӨҡпјҡе…ёеһӢеңәжҷҜеҰӮqpsз»ҹи®Ў
жң¬ж–Үй’ҲеҜ№иҜ»еӨҡеҶҷе°‘пјҲд№ҹз§°дёҖеҶҷеӨҡиҜ»пјүеңәжҷҜдёӢйҒҮеҲ°зҡ„й—®йўҳиҝӣиЎҢеҲҶжһҗпјҢ并жҺўи®ЁдёҖз§ҚеҗҲйҖӮзҡ„и§ЈеҶіж–№жЎҲгҖӮ
иҜ»еӨҡеҶҷе°‘зҡ„еңәжҷҜпјҢжңҚеҠЎеӨ§йғЁеҲҶжғ…еҶөдёӢйғҪжҳҜеӨ„дәҺиҜ»пјҢиҖҢдё”иҰҒжұӮиҜ»зҡ„иҖ—ж—¶дёҚиғҪеӨӘй•ҝпјҢдёҖиҲ¬жҳҜжҜ«з§’жҲ–иҖ…жӣҙдҪҺзҡ„зә§еҲ«пјӣжӣҙж–°зҡ„йў‘зҺҮе°ұдёҚжҳҜйӮЈд№Ҳйў‘з№ҒпјҢеҰӮеҮ з§’й’ҹжӣҙж–°дёҖж¬ЎгҖӮйҖҡиҝҮз®ҖеҚ•зҡ„еҠ дә’ж–Ҙй”ҒпјҢи…ҫеҮәдёҖзүҮдёҙз•ҢеҢәпјҢеҫҖеҫҖиғҪеҲ°иҫҫйў„жңҹзҡ„ж•ҲжһңпјҢдҝқиҜҒж•°жҚ®жӣҙж–°жӯЈзЎ®гҖӮ
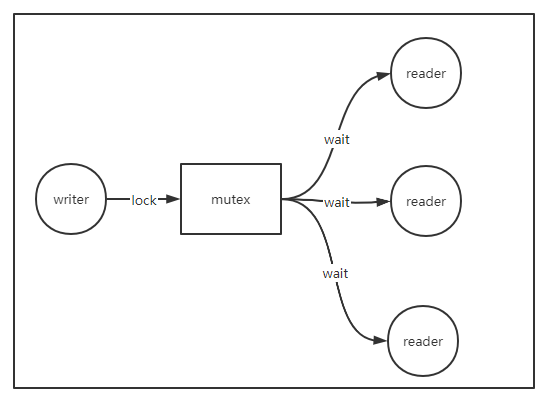
дҪҶжҳҜпјҢеҸӘиҰҒеҠ дәҶй”ҒпјҢе°ұдјҡеёҰжқҘз«һдәүпјҢеҚідҪҝеҠ зҡ„жҳҜиҜ»еҶҷй”ҒпјҢиҷҪ然иҜ»д№Ӣй—ҙдёҚдә’ж–ҘпјҢдҪҶеҶҷдёҖж ·дјҡеҪұе“ҚиҜ»пјҢиҖҢдё”иҜ»еҶҷеҗҢж—¶дәүеӨәй”Ғзҡ„ж—¶еҖҷпјҢй”Ғдјҳе…ҲеҲҶй…Қз»ҷеҶҷпјҲиҜ»еҶҷй”Ғзҡ„зү№жҖ§пјүгҖӮдҫӢеҰӮпјҢеҶҷзҡ„ж—¶еҖҷпјҢиҰҒжұӮжүҖжңүзҡ„иҜ»иҜ·жұӮйҳ»еЎһдҪҸпјҢзӯүеҲ°еҶҷзәҝзЁӢжҲ–еҚҸзЁӢйҮҠж”ҫй”Ғд№ӢеҗҺжүҚиғҪиҜ»гҖӮеҰӮжһңеҶҷзҡ„дёҙз•ҢеҢәиҖ—ж—¶жҜ”иҫғеӨ§пјҢеҲҷжүҖжңүзҡ„иҜ»иҜ·жұӮйғҪдјҡеҸ—еҪұе“ҚпјҢд»Һзӣ‘жҺ§еӣҫдёҠзңӢпјҢиҝҷж—¶еҖҷдјҡжңүдёҖж №еҫҲе°–зҡ„иҖ—ж—¶жҜӣеҲәпјҢжүҖжңүзҡ„иҜ»иҜ·жұӮйғҪеңЁйҳҹеҲ—дёӯзӯүеҫ…еӨ„зҗҶпјҢеҰӮжһңеңЁдёӢдёӘжӣҙж–°е‘ЁжңҹжқҘд№ӢеүҚпјҢжңҚеҠЎиғҪеӨ„зҗҶе®ҢиҝҷдәӣиҜ»иҜ·жұӮпјҢеҸҜиғҪжғ…еҶөжІЎйӮЈд№Ҳзіҹзі•гҖӮдҪҶжһҒз«Ҝжғ…еҶөдёӢпјҢеҰӮжһңдёӢдёӘжӣҙж–°е‘ЁжңҹжқҘдәҶпјҢиҜ»иҜ·жұӮиҝҳжІЎеӨ„зҗҶе®ҢпјҢе°ұдјҡеҪўжҲҗдёҖдёӘжҒ¶жҖ§еҫӘзҺҜпјҢдёҚж–ӯзҡ„жңүиҜ»иҜ·жұӮеңЁйҳҹеҲ—дёӯзӯүеҫ…пјҢжңҖз»ҲеҜјиҮҙйҳҹеҲ—иў«жҢӨж»ЎпјҢжңҚеҠЎеҮәзҺ°еҒҮжӯ»пјҢжғ…еҶөеҶҚжҒ¶еҠЈдёҖзӮ№зҡ„иҜқпјҢдёҠжёёжңҚеҠЎеҸ‘зҺ°жҹҗдёӘиҠӮзӮ№еҒҮжӯ»еҗҺпјҢз”ұдәҺиҙҹиҪҪеқҮиЎЎзӯ–з•ҘпјҢдёҖиҲ¬дјҡйҮҚиҜ•иҜ·жұӮе…¶д»–иҠӮзӮ№пјҢиҝҷж—¶еҖҷе…¶д»–иҠӮзӮ№зҡ„еҺӢеҠӣи·ҹзқҖеўһеҠ дәҶпјҢжңҖз»ҲеҜјиҮҙж•ҙдёӘзі»з»ҹеҮәзҺ°йӣӘеҙ©гҖӮ
еӣ жӯӨпјҢеҠ й”ҒеңЁй«ҳ并еҸ‘еңәжҷҜдёӢиҰҒе°ҪйҮҸйҒҝе…ҚпјҢеҰӮжһңйҒҝе…ҚдёҚдәҶпјҢйңҖиҰҒи®©й”Ғзҡ„зІ’еәҰе°ҪйҮҸе°ҸпјҢжҺҘиҝ‘ж— й”ҒпјҲlock-freeпјүжӣҙеҘҪпјҢз®ҖеҚ•зҡ„еҜ№дёҖеӨ§зүҮдёҙз•ҢеҢәеҠ й”ҒпјҢеңЁй«ҳ并еҸ‘еңәжҷҜдёӢдёҚжҳҜдёҖз§ҚеҗҲйҖӮзҡ„и§ЈеҶіж–№жЎҲ
жңүдёҖз§Қж•°жҚ®з»“жһ„еҸ«еҸҢзј“еҶІпјҢе…¶иҝҷз§Қж•°жҚ®з»“жһ„еҫҲеёёи§ҒпјҢдҫӢеҰӮжҳҫзӨәеұҸзҡ„жҳҫзӨәеҺҹзҗҶпјҢжҳҫзӨәеұҸжҳҫзӨәзҡ„еҪ“еүҚеё§пјҢдёӢдёҖеё§е·Із»ҸеңЁеҗҺеҸ°зҡ„bufferеҮҶеӨҮеҘҪпјҢзӯүж—¶й—ҙе‘ЁжңҹдёҖеҲ°пјҢе°ұзӣҙжҺҘжӣҝжҚўеүҚеҸ°её§пјҢиҝҷж ·иғҪеҒҡеҲ°ж— еҚЎйЎҝзҡ„еҲ·ж–°пјҢе…¶е®һзҺ°зҡ„жҢҮеҜјжҖқжғіжҳҜз©әй—ҙжҚўж—¶й—ҙпјҢиҝҷз§Қж•°жҚ®з»“жһ„зҡ„е·ҘдҪңеҺҹзҗҶеҰӮдёӢпјҡ
ж•°жҚ®еҲҶдёәеүҚеҸ°е’ҢеҗҺеҸ°
жүҖжңүиҜ»зәҝзЁӢиҜ»еүҚеҸ°ж•°жҚ®пјҢдёҚз”ЁеҠ й”ҒпјҢйҖҡиҝҮдёҖдёӘжҢҮй’ҲжқҘжҢҮеҗ‘еҪ“еүҚиҜ»зҡ„еүҚеҸ°ж•°жҚ®
еҸӘжңүдёҖдёӘзәҝзЁӢиҙҹиҙЈжӣҙж–°пјҢжӣҙж–°зҡ„ж—¶еҖҷпјҢе…ҲеҮҶеӨҮеҘҪеҗҺеҸ°ж•°жҚ®пјҢжҺҘзқҖзӣҙжҺҘеҲҮжҢҮй’ҲпјҢиҝҷд№ӢеҗҺжүҖжңүж–°иҝӣжқҘзҡ„иҜ»иҜ·жұӮйғҪзңӢеҲ°дәҶж–°зҡ„еүҚеҸ°ж•°жҚ®
жңүйғЁеҲҶиҜ»иҝҳиҗҪеңЁиҖҒзҡ„еүҚеҸ°йӮЈйҮҢеӨ„зҗҶпјҢеӣ дёәжӣҙж–°иҝҳдёҚз®—е®ҢжҲҗпјҢд№ҹе°ұдёҚиғҪйҖҖеҮәеҶҷзәҝзЁӢпјҢеҶҷзәҝзЁӢйңҖиҰҒзӯүеҫ…жүҖжңүиҗҪеңЁиҖҒеүҚеҸ°зҡ„зәҝзЁӢиҜ»е®ҢжҲҗеҗҺпјҢжүҚиғҪйҖҖеҮәпјҢеңЁйҖҖеҮәд№ӢеүҚпјҢйЎәдҫҝеҶҚжӣҙж–°дёҖйҒҚиҖҒеүҚеҸ°ж•°жҚ®пјҲд№ҹе°ұеҪ“еүҚзҡ„ж–°еҗҺеҸ°пјүпјҢеҸҜд»ҘдҝқиҜҒеүҚеҗҺеҸ°ж•°жҚ®дёҖиҮҙпјҢиҝҷзӮ№еңЁеҒҡеўһйҮҸжӣҙж–°зҡ„ж—¶еҖҷжңүз”Ё
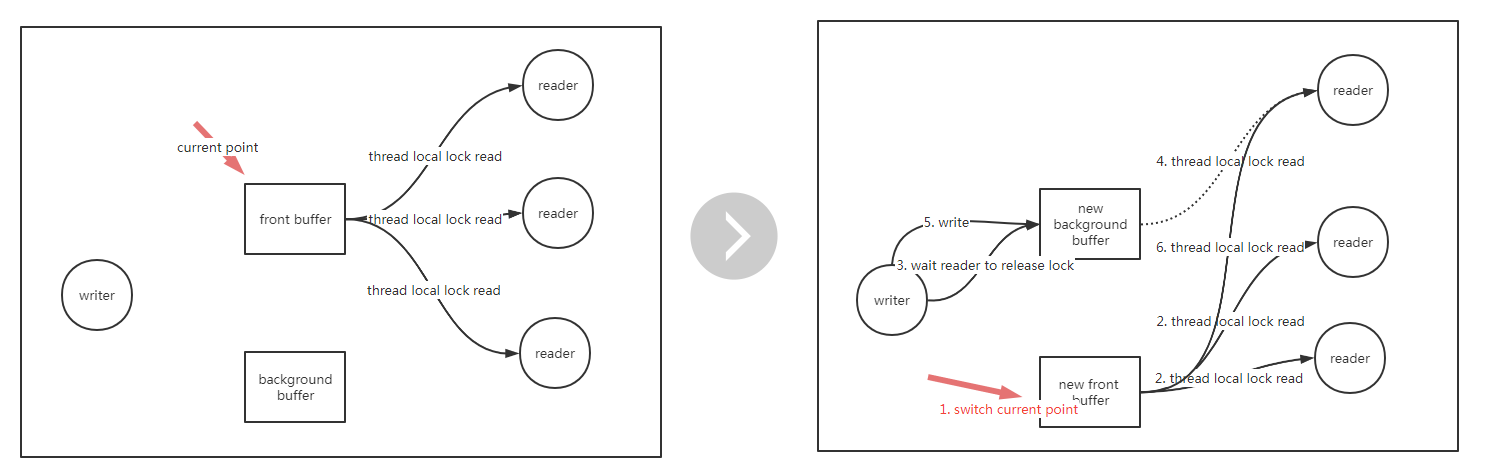
еҶҷзәҝзЁӢиҰҒжҖҺд№ҲзҹҘйҒ“жүҖжңүзҡ„иҜ»зәҝзЁӢеңЁиҖҒеүҚеҸ°дёӯзҡ„иҜ»е®ҢжҲҗдәҶе‘ўпјҹ
дёҖз§ҚеҒҡжі•жҳҜи®©еҗ„дёӘиҜ»зәҝзЁӢйғҪз»ҙжҠӨдёҖжҠҠй”ҒпјҢиҜ»зҡ„ж—¶еҖҷй”ҒдҪҸпјҢиҝҷж—¶еҖҷдёҚдјҡеҪұе“Қе…¶д»–зәҝзЁӢзҡ„иҜ»пјҢдҪҶдјҡеҪұе“ҚеҶҷпјҢиҜ»е®ҢеҗҺйҮҠж”ҫй”Ғ(жҹҗдәӣж—¶еҖҷеҸҜиғҪдјҡжңүйҖҡзҹҘеҶҷзәҝзЁӢзҡ„ејҖй”ҖпјҢдҪҶеҶҷжң¬иә«еҫҲе°‘)пјҢеҶҷзәҝзЁӢеҸӘйңҖиҰҒзЎ®и®Өй”ҒжңүжІЎжңүйҮҠж”ҫдәҶпјҢзЎ®и®Өе®ҢдәҶеҗҺ马дёҠйҮҠж”ҫпјҢзЎ®и®ӨиҝҷдёӘеҠЁдҪңйқһеёёеҝ«пјҲе°ҸдәҺ25nsпјҢ1s=103ms=106us=10^9nsпјүпјҢиҜ»зәҝзЁӢеҮ д№ҺдёҚдјҡж„ҹи§үеҲ°й”Ғзҡ„еӯҳеңЁгҖӮ
жҜҸдёӘзәҝзЁӢйғҪжңүдёҖжҠҠиҮӘе·ұзҡ„й”ҒпјҢйңҖиҰҒз”Ёе…ЁеұҖзҡ„mapжқҘеҒҡзәҝзЁӢidе’Ңй”Ғзҡ„жҳ е°„еҗ—пјҹ
дёҚйңҖиҰҒпјҢиҖҢдё”иҝҷж ·еҒҡе…ЁеұҖmapе°ұиҰҒеҠ е…ЁеұҖй”ҒдәҶпјҢеҸҲеӣһеҲ°дәҶеҲҡејҖе§ӢеҲҶжһҗдёӯйҒҮеҲ°зҡ„й—®йўҳдәҶгҖӮе…¶е®һпјҢжҜҸдёӘзәҝзЁӢеҸҜд»Ҙжңүз§ҒжңүеӯҳеӮЁпјҲthread local storageпјҢз®Җз§°TLSпјүпјҢеҰӮжһңжҳҜеҚҸзЁӢпјҢе°ұеҜ№еә”иҝҷеҚҸзЁӢзҡ„TLSпјҲдҪҶеҜ№дәҺgoиҜӯиЁҖпјҢе®ҳж–№жҳҜдёҚж”ҜжҢҒTLSзҡ„пјҢжғіе®һзҺ°зұ»дјјеҠҹиғҪпјҢиҰҒд№Ҳе°ұжғіеҠһжі•иҺ·еҸ–еҲ°TLSпјҢиҰҒд№Ҳе°ұдёҚиҰҒеҹәдәҺеҚҸзЁӢй”ҒпјҢиҖҢжҳҜз”Ёе…ЁеұҖй”ҒпјҢдҪҶе°ҪйҮҸи®©й”ҒзІ’еәҰе°ҸпјҢжң¬ж–Үдё»иҰҒй’ҲеҜ№C++иҜӯиЁҖпјҢжҡӮж—¶дёҚж·ұе…Ҙи®Ёи®әе…¶д»–иҜӯиЁҖзҡ„е®һзҺ°пјүгҖӮиҝҷж ·жҜҸдёӘиҜ»зәҝзЁӢй”Ғзҡ„жҳҜиҮӘе·ұзҡ„й”ҒпјҢдёҚдјҡеҪұе“ҚеҲ°е…¶д»–зҡ„иҜ»зәҝзЁӢпјҢй”Ғзҡ„зӣ®зҡ„д»…д»…жҳҜдёәдәҶдҝқиҜҒиҜ»дјҳе…ҲгҖӮ
еҜ№дәҺзәҝзЁӢз§ҒжңүеӯҳеӮЁпјҢеҸҜд»ҘдҪҝз”Ёpthread_key_create, pthread_setspecificпјҢpthread_getspecificзі»еҲ—еҮҪж•°
иҜ»
template <typename T, typename TLS>
int DoublyBufferedData<T, TLS>::Read(
typename DoublyBufferedData<T, TLS>::ScopedPtr* ptr) { // ScopedPtrжһҗжһ„зҡ„ж—¶еҖҷпјҢдјҡйҮҠж”ҫй”Ғ
Wrapper* w = static_cast<Wrapper*>(pthread_getspecific(_wrapper_key)); //йқһйҰ–ж¬ЎиҜ»пјҢиҺ·еҸ–pthread local lock
if (BAIDU_LIKELY(w != NULL)) {
w->BeginRead(); // й”ҒдҪҸ
ptr->_data = UnsafeRead();
ptr->_w = w;
return 0;
}
w = AddWrapper();
if (BAIDU_LIKELY(w != NULL)) {
const int rc = pthread_setspecific(_wrapper_key, w); // йҰ–ж¬ЎиҜ»пјҢи®ҫзҪ®pthread local lock
if (rc == 0) {
w->BeginRead();
ptr->_data = UnsafeRead();
ptr->_w = w;
return 0;
}
}
return -1;
}еҶҷ
template <typename T, typename TLS>
template <typename Fn>
size_t DoublyBufferedData<T, TLS>::Modify(Fn& fn) {
BAIDU_SCOPED_LOCK(_modify_mutex); // еҠ й”ҒпјҢдҝқиҜҒеҸӘжңүдёҖдёӘеҶҷ
int bg_index = !_index.load(butil::memory_order_relaxed); // жҢҮеҗ‘еҗҺеҸ°buffer
const size_t ret = fn(_data[bg_index]); // дҝ®ж”№еҗҺеҸ°buffer
if (!ret) {
return 0;
}
// еҲҮжҢҮй’Ҳ
_index.store(bg_index, butil::memory_order_release);
bg_index = !bg_index;
// зӯүжүҖжңүиҜ»иҖҒеүҚеҸ°зҡ„зәҝзЁӢиҜ»з»“жқҹ
{
BAIDU_SCOPED_LOCK(_wrappers_mutex);
for (size_t i = 0; i < _wrappers.size(); ++i) {
_wrappers[i]->WaitReadDone();
}
}
// зЎ®и®ӨжІЎжңүиҜ»дәҶпјҢзӣҙжҺҘдҝ®ж”№ж–°еҗҺеҸ°ж•°жҚ®пјҢеҜ№е…¶ж–°еүҚеҸ°
const size_t ret2 = fn(_data[bg_index]);
return ret2;
}е®Ңж•ҙе®һзҺ°иҜ·еҸӮиҖғbrpcзҡ„DoublyBufferData
жҷ®йҖҡзҡ„еҸҢзј“еҶІеҠ иҪҪе®һзҺ°
еҹәдәҺи®Ўж•°еҷЁпјҢз”ЁatomicпјҢдҝқиҜҒеҺҹеӯҗжҖ§пјҢиҜ»иҝӣе…Ҙдёҙз•ҢеҢәпјҢи®Ўж•°еҷЁ+1пјҢйҖҖеҮә-1пјҢеҶҷеҲӨж–ӯи®Ўж•°еҷЁдёә0еҲҷеҲҮжҚўпјҢдҪҶи®Ўж•°еҷЁжҳҜе…ЁеұҖй”ҒгҖӮиҝҷз§Қж–№жЎҲC++д№ҹеҸҜд»ҘйҮҮеҸ–пјҢеҸӘжҳҜи®Ўж•°еҷЁжҜ•з«ҹд№ҹжҳҜе…ЁеұҖй”ҒпјҢжҖ§иғҪдјҡе·®йӮЈд№ҲдёҖдёўдёўгҖӮеҚідҪҝз”ЁжҷәиғҪжҢҮй’Ҳshared_ptrпјҢд№ҹдјҡйқўдёҙжҷәиғҪжҢҮй’Ҳеј•з”Ёи®Ўж•°дә’ж–Ҙзҡ„й—®йўҳгҖӮд№ӢжүҖд»Ҙз”Ёи®Ўж•°еҷЁпјҢиҖҢдёҚз”ЁTLSпјҢжҳҜеӣ дёәgoдёҚж”ҜжҢҒTLSпјҢеҜ№жҜ”TLSзүҲжң¬е’Ңи®Ўж•°еҷЁзүҲжң¬пјҢTLSжҖ§иғҪжӣҙдјҳпјҢеӣ дёәжІЎжңүжҠўи®Ўж•°еҷЁзҡ„дә’ж–Ҙй—®йўҳпјҢдҪҶжҠўи®Ўж•°еҷЁжң¬иә«еҫҲеҝ«пјҢжҖ§иғҪжІЎжөӢиҜ•иҝҮпјҢеҸҜд»ҘиҜ•иҜ•гҖӮ
sync.Mapзҡ„е®һзҺ°
д№ҹжҳҜеҹәдәҺи®Ўж•°еҷЁпјҢеҸӘжҳҜи®Ўж•°еҷЁжҳҜдёәдәҶи®©иҜ»еүҚеҸ°зј“еӯҳеӨұж•Ҳзҡ„жҰӮзҺҮдёҚиҰҒеӨӘй«ҳпјҢжңүжҠ‘еҲ¶е’Ң收ж•ӣзҡ„дҪңз”ЁпјҢе®һзҺ°дәҶиҜ»зҡ„ж— й”ҒпјҢе°‘йғЁеҲҶжғ…еҶөдёӢпјҢеүҚеҸ°зј“еӯҳиҜ»дёҚеҲ°ж•°жҚ®зҡ„ж—¶еҖҷпјҢдјҡеҺ»иҜ»еҗҺеҸ°зј“еӯҳпјҢиҝҷж—¶еҖҷд№ҹиҰҒеҠ й”ҒпјҢеҗҢж—¶и®Ўж•°еҷЁ+1гҖӮи®Ўж•°еҷЁж•°еҖјиҫҫеҲ°дёҖе®ҡзЁӢеәҰпјҲи¶…иҝҮеҗҺеҸ°зј“еӯҳзҡ„е…ғзҙ дёӘж•°пјүпјҢе°ұжү§иЎҢеҲҮжҚў
жҳҜеҗҰйҖӮз”ЁдәҺиҜ»е°‘еҶҷеӨҡзҡ„еңәжҷҜ
дёҚеҗҲйҖӮпјҢеҸҢзј“еҶІдјҳе…ҲдҝқиҜҒиҜ»зҡ„жҖ§иғҪпјҢеҶҷеӨҡиҜ»е°‘зҡ„еңәжҷҜйңҖиҰҒдјҳе…ҲдҝқиҜҒеҶҷзҡ„жҖ§иғҪгҖӮ
дёҠиҝ°е°ұжҳҜе°Ҹзј–дёәеӨ§е®¶еҲҶдә«зҡ„C++й«ҳ并еҸ‘еңәжҷҜдёӢиҜ»еӨҡеҶҷе°‘зҡ„дјҳеҢ–ж–№жЎҲжҳҜд»Җд№ҲдәҶпјҢеҰӮжһңеҲҡеҘҪжңүзұ»дјјзҡ„з–‘жғ‘пјҢдёҚеҰЁеҸӮз…§дёҠиҝ°еҲҶжһҗиҝӣиЎҢзҗҶи§ЈгҖӮеҰӮжһңжғізҹҘйҒ“жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ