жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒдёәеӨ§е®¶еұ•зӨәдәҶвҖңеҹәдәҺpycharmзҡ„beautifulsoup4еә“жҖҺд№Ҳз”ЁвҖқпјҢеҶ…е®№з®ҖиҖҢжҳ“жҮӮпјҢжқЎзҗҶжё…жҷ°пјҢеёҢжңӣиғҪеӨҹеё®еҠ©еӨ§е®¶и§ЈеҶіз–‘жғ‘пјҢдёӢйқўи®©е°Ҹзј–еёҰйўҶеӨ§е®¶дёҖиө·з ”究并еӯҰд№ дёҖдёӢвҖңеҹәдәҺpycharmзҡ„beautifulsoup4еә“жҖҺд№Ҳз”ЁвҖқиҝҷзҜҮж–Үз« еҗ§гҖӮ
第дёҖжӯҘпјҡеңЁжҺ§еҲ¶еҸ°иҫ“е…ҘеҰӮдёӢе‘Ҫд»ӨпјҢе®үиЈ…beautifulsoup4еә“гҖӮ
pip install beautifulsoup4
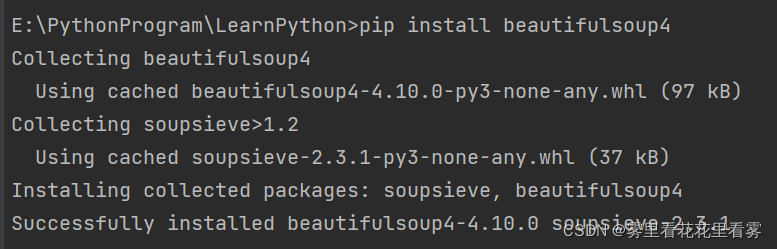
第дәҢжӯҘпјҡеңЁжҺ§еҲ¶еҸ°иҫ“е…ҘеҰӮдёӢе‘Ҫд»ӨпјҢйӘҢиҜҒжҳҜеҗҰжҲҗеҠҹе®үиЈ…beautifulsoup4еә“гҖӮ
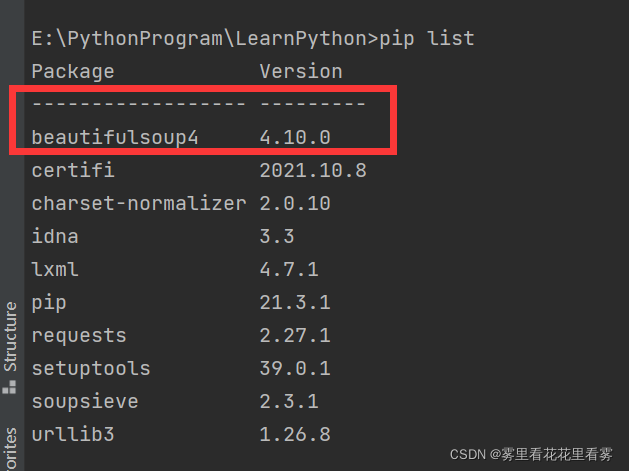
第дёүжӯҘпјҡеңЁpycharmдёӯпјҢзӮ№еҮ»file——settings——project——python interpreter——зӮ№еҮ»+еҸ·——жҗңзҙўbeautifulsoup4——install packageпјҒ

иҝҷж ·е°ұеҸҜд»ҘеңЁ.pyж–Ү件дёӯеҜје…ҘжЁЎеқ—дәҶпјҒ
import requests
# иҷҪ然еә“еҗҚеҸ«еҒҡbeautiful4 дҪҶжҳҜеңЁеҜје…Ҙж—¶ дҪҝз”Ёзҡ„жҳҜе…¶зј©еҶҷbs4 е…¶дёӯBeautifulSoupжҳҜдёҖдёӘзұ»еҗҚ
from bs4 import BeautifulSoup
url = 'https://www.baidu.com/s?'
# з”ұдәҺдёҖиҲ¬зҪ‘з«ҷйғҪжҳҜдҫӣз”ЁжҲ·и®ҝй—® еҰӮжһңжЈҖжөӢеҲ°User-AgentжҳҜй»‘е®ўжҲ–иҖ…е…¶д»–еҸҜиғҪжӢ’з»қи®ҝй—® ж•…жӯӨеӨ„жЁЎжӢҹжөҸи§ҲеҷЁ
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
# д»ҘйҳІд№ұз Ғ жӯӨеӨ„е°Ҷе…¶зј–з Ғи®ҫзҪ®дёәutf-8 еӣ дёәжңүдёӯж–Ү
response.encoding = 'utf-8'
# print(response.text)
# дҪҝз”Ёзҡ„и§ЈжһҗеҷЁжҳҜhtml.parser жіЁж„ҸжҳҜ.еҘҘ
soup = BeautifulSoup(response.text, 'html.parser')
# жү“еҚ°и§ЈжһҗеҗҺзҡ„з»“жһң
print(soup.prettify())йңҖиҰҒи®Іи§Јзҡ„йғҪеңЁд»Јз ҒжіЁйҮҠдёӯдәҶеҘҘпјҒ
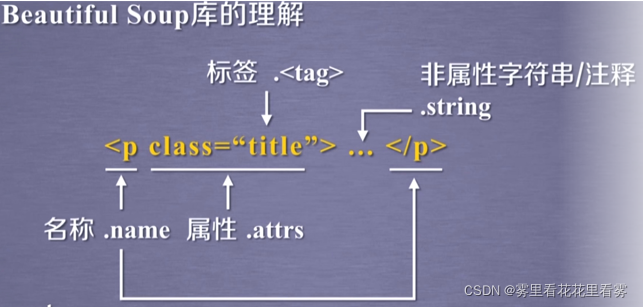
beautifulsoup4еә“жҳҜи§ЈжһҗгҖҒйҒҚеҺҶгҖҒз»ҙжҠӨвҖңж Үзӯҫж ‘вҖқзҡ„еҠҹиғҪеә“гҖӮ
йҰ–е…ҲжқҘзңӢBeautifulSoupеә“и§ЈжһҗеҷЁпјҢеүҚдёӨдёӘжҜ”иҫғеёёз”ЁпјҒ

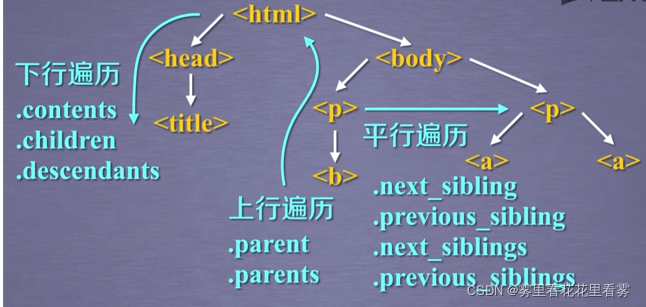
еҶҚжқҘзңӢBeautifulSoupеә“зҡ„еҹәжң¬е…ғзҙ пјҢеҸҜд»Ҙиҝҷж ·зҗҶи§ЈпјҢж Үзӯҫж ‘е’ҢHTMLд»ҘеҸҠBeautifulSoupжҳҜдёҖж ·зҡ„пјҢжҲ‘们иҰҒзңӢHTMLзҡ„жҹҗдәӣеҶ…е®№е°ұдҪҝз”ЁBeautifulSoupзҡ„е®һдҫӢеҢ–еҜ№иұЎжҹҘзңӢеҚіеҸҜгҖӮ

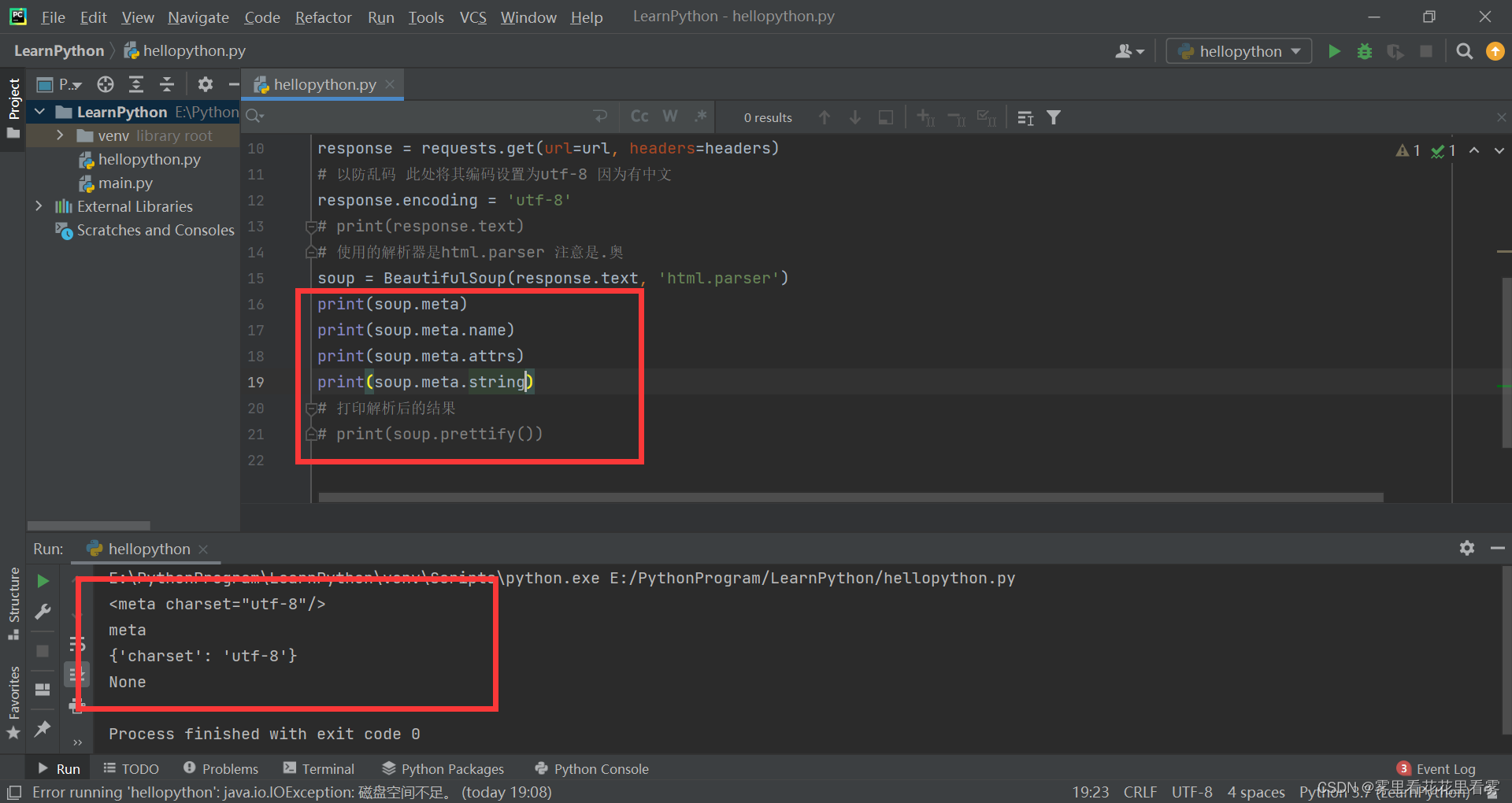
еңЁдёҠиҝ°д»Јз Ғзҡ„еҹәзЎҖдёҠпјҢеўһеҠ еҰӮдёӢеҮ иЎҢпјҢз»“еҗҲеҹәжң¬е…ғзҙ зҡ„дҪҝз”ЁпјҢеҸҜеҫ—еҲ°еҰӮеӣҫжүҖзӨәгҖӮ
йңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢ.stringеҸҜд»Ҙи·Ёж ҮзӯҫпјҢжүҖд»ҘеҫҲжңүеҸҜиғҪз»“жһңд№ҹдёәжіЁйҮҠпјҢдёәдәҶеҢәеҲҶжҳҜж ҮзӯҫеҶ…зҡ„еӯ—з¬ҰдёІиҝҳжҳҜжіЁйҮҠпјҢеҸҜд»ҘйҖҡиҝҮжү“еҚ°зұ»еһӢжқҘеҲӨж–ӯгҖӮ
жҖ»з»“иө·жқҘпјҢеҸҜеҰӮдёӢпјҡ


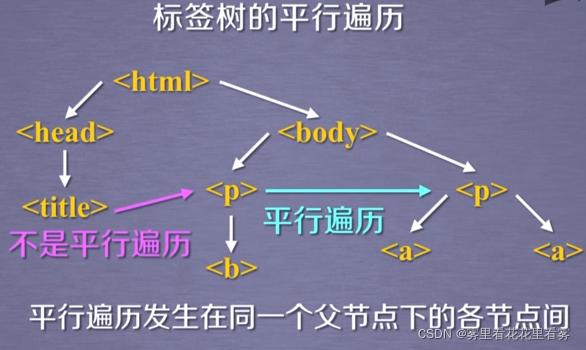
жҺҘдёӢжқҘпјҢзңӢдёҖдёӢBeautifulSoupеә“зҡ„йҒҚеҺҶпјҢе…¶дёӯз”»зәўжЎҶзҡ„иҝӯд»ЈйҒҚеҺҶпјҢеҸҜд»Ҙз”ЁдәҺfor inеҫӘзҺҜдёӯгҖӮ
find_all( name , attrs , recursive , string , **kwargs )
find_all() ж–№жі•жҗңзҙўеҪ“еүҚtagзҡ„жүҖжңүtagеӯҗиҠӮзӮ№,并еҲӨж–ӯжҳҜеҗҰз¬ҰеҗҲиҝҮж»ӨеҷЁзҡ„жқЎд»¶гҖӮ
name еҸӮж•°еҸҜд»ҘеҜ№еҗҚеӯ—дёә name зҡ„ж ҮзӯҫиҝӣиЎҢжЈҖзҙўгҖӮ
attrsеҸӮж•°еҸҜд»ҘеҜ№ж ҮзӯҫеұһжҖ§еҖјдёәattrsзҡ„ж ҮзӯҫиҝӣиЎҢжЈҖзҙўгҖӮ
recursiveеҸӮж•°иЎЁзӨәжҳҜеҗҰеҜ№еӯҗеӯҷе…ЁйғЁжЈҖзҙўпјҢй»ҳи®ӨжҳҜTRUEпјҢеҰӮжһңеҸӘжғіжҗңзҙўеҪ“еүҚиҠӮзӮ№зҡ„е„ҝеӯҗдҝЎжҒҜпјҢеҸҜд»ҘзҪ®е…¶дёәFALSEгҖӮ
string еҸӮж•°еҸҜд»Ҙж Үзӯҫдёӯзҡ„еӯ—з¬ҰдёІеҶ…е®№иҝӣиЎҢжЈҖзҙўгҖӮ

жҲ‘们еӯҰиҝҮjsзҡ„жҲ–иҖ…javaзҡ„пјҢеә”иҜҘеҜ№JsonдёҚйҷҢз”ҹеҗ§пјҒ
JsonжҳҜдёҖз§Қжңүзұ»еһӢзҡ„й”®еҖјеҜ№пјҒ
йңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢй”®е’ҢеҖјйғҪйңҖиҰҒз”Ё"вҖңжӢ¬иө·жқҘпјҢеҰӮжһңеҖјжҳҜж•ҙж•°пјҢеҲҷеҸҜд»ҘдёҚз”ЁвҖқ"пјҒ
еҰӮжһңеҖјжҳҜеӨҡеҖјпјҢеҲҷеҸҜд»Ҙз”Ё[,]пјӣеҰӮжһңеҖјжҳҜй”®еҖјеҜ№пјҢеҲҷеҸҜд»Ҙз”Ё{:,:,}пјҢеҸҜд»ҘеөҢеҘ—дҪҝз”ЁгҖӮ

JSONдёҖиҲ¬з”ЁдәҺжҺҘеҸЈпјҢиҖҢYAMLжҳҜж— зұ»еһӢй”®еҖјеҜ№пјҢдёҖиҲ¬з”ЁдәҺй…ҚзҪ®ж–Ү件гҖӮ
д»ҘдёҠжҳҜвҖңеҹәдәҺpycharmзҡ„beautifulsoup4еә“жҖҺд№Ҳз”ЁвҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒзӣёдҝЎеӨ§е®¶йғҪжңүдәҶдёҖе®ҡзҡ„дәҶи§ЈпјҢеёҢжңӣеҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүжүҖеё®еҠ©пјҢеҰӮжһңиҝҳжғіеӯҰд№ жӣҙеӨҡзҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ