您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
HDFS全称是Hadoop Distribute File System,是一个能运行在普通商用硬件上的分布式文件系统。
与其他分布式文件系统显著不同的特点是:
综合上述的设计假设和后面的架构分析,HDFS特别适合于以下场景:
整体预算有限
想利用分布式计算的便利,又没有足够的预算购买HPC、高性能小型机等场景
在如下场景其性能不尽如人意:
低延迟数据访问
低延迟数据访问意味着快速数据定位,比如10ms级别响应,系统若忙于响应此类要求,
则有悖于快速返回大量数据的假设。
本文将从以下几个方面分析HDFS架构,探讨HDFS架构是如何满足设计目标的。
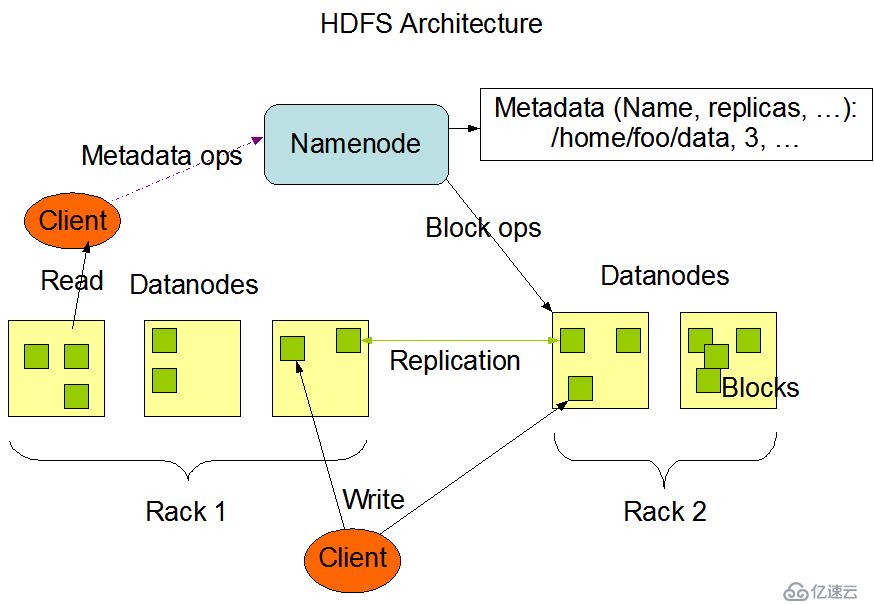
下面这张HDFS架构图来自于hadoop官方网站.
DataNode
DataNode提供文件内容的存储、操作功能。
文件数据块本身存储在不同的DataNode当中,DataNode可以分布在不同机架。
HDFS的Client会分别访问NameNode和DataNode以获取文件的元信息以及内容。HDFS集群的Client将
直接访问NameNode和DataNode,相关数据直接从NameNode或者DataNode传送到客户端。
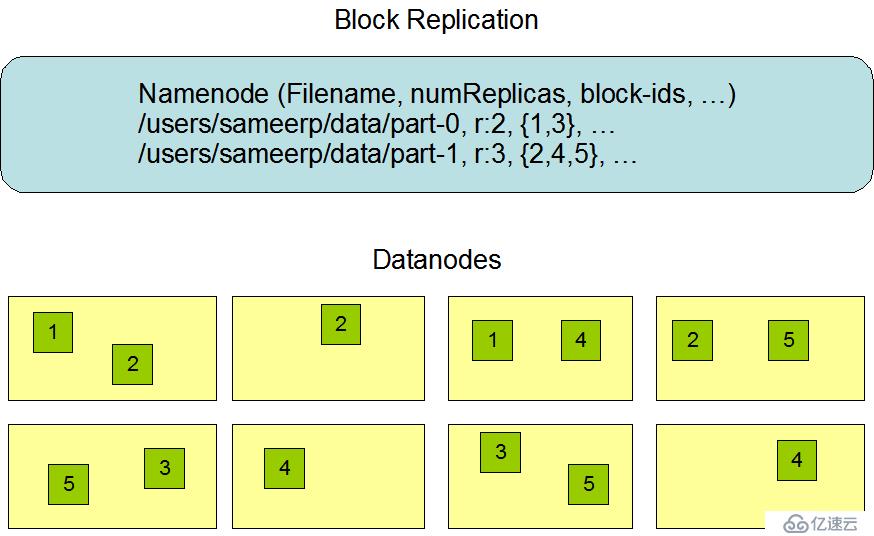
HDFS的数据组织分成两部分进行理解,首先是NameNode部分,其次是DataNode数据部分,数据的组织图如下所示:
HDFS的文件访问机制为流式访问机制,即通过API打开文件的某个数据块之后,可以顺序读取或者写入某个文件,不可以指定
读取文件然后进行文件操作。
由于HDFS中存在多个角色,且对应应用场景主要为一次写入多次读取的场景,因此其读和写的方式有较大不同。读写操作都由
客户端发起,并且进行整个流程的控制,服务器角色(NameNode和DataNode)都是被动式响应。
下面分别对其进行 介绍:
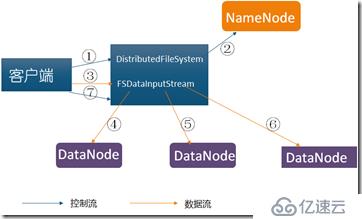
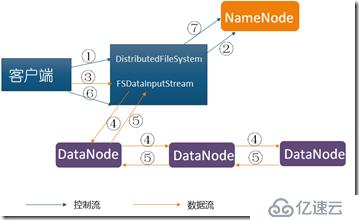
?使用HDFS提供的客户端开发库Client,向远程的Namenode发起RPC请求;
?Namenode会检查要创建的文件是否已经存在,创建者是否有权限进行操作,成功则会为文件 创建一个记录,否则会让客户端抛出异常;
?当客户端开始写入文件的时候,会将文件切分成多个packets,并在内部以数据队列"data queue"的形式管理这些packets,并向Namenode申请新的blocks,获取用来存储replicas的合适的datanodes列表,列表的大小根据在Namenode中对replication的设置而定。
?开始以pipeline(管道)的形式将packet写入所有的replicas中。把packet以流的方式写入第一个datanode,该datanode把该packet存储之后,再将其传递给在此pipeline中的下一个datanode,直到最后一个datanode,这种写数据的方式呈流水线的形式。
?最后一个datanode成功存储之后会返回一个ack packet,在pipeline里传递至客户端,在客户端的开发库内部维护着"ack queue",成功收到datanode返回的ack packet后会从"ack queue"移除相应的packet。
?如果传输过程中,有某个datanode出现了故障,那么当前的pipeline会被关闭,出现故障的datanode会从当前的pipeline中移除,剩余的block会继续剩下的datanode中继续以pipeline的形式传输,同时Namenode会分配一个新的datanode,保持replicas设定的数量。
HDFS文件系统的安全机制采取类linux的ACL安全访问机制。每一个文件默认继承其父对象即目录的访问权限,默认的用户和属组来自于
上传客户端的用户。相关控制方法也与linux类似,可以通过命令或者API指定某个用户对某个文件的读写权限。当用户没有对应的权限时,
若进行文件读写操作将会得到对应的错误提示。
HDFS作为一个高可用集群,其可用性设计是非常用心的,主要体现在:
集群的动态扩展方式方便用户以动态的方式对集群进行扩容和缩容。若有新服务器加入,则后续的IO会有更多的机会被
发送到新服务器上执行,对集群中现有文件的充分分布,可以通过命令进行,但是数据重新分布将只占用少量网络IO,这样保证集群上的应用不会因为重分布而受到重大影响。同样机器下架也通过命令进行,此时集群表现出与机器宕机类似情况,会不再往其上发IO请求以及重新复制以保证副本数量。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。