您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
鲁春利的工作笔记,谁说程序员不能有文艺范?
Hive对外提供了三种服务模式,即CLI(command line interface)、Hive Web和Hive Client(如JavaApi方式)。
1、Hive命令行模式(CLI)
启动Hive命令行模式有两种方式
bin/hive 或 bin/hive --service cli
hive命令选项
[hadoop@nnode hive1.2.0]$ bin/hive --help Usage ./hive <parameters> --service serviceName <service parameters> Service List: beeline cli help hiveburninclient hiveserver2 hiveserver hwi jar lineage metastore metatool orcfiledump rcfilecat schemaTool version # 这里对应hive <parameters>对应的参数 Parameters parsed: # 允许用户指定一个以冒号分割的附属jar包,如自定义的扩展等。 --auxpath : Auxillary jars # 指定文件目录,覆盖$HIVE_HOME/conf中默认的属性配置 --config : Hive configuration directory # 需要启动的服务,默认为cli,其他见Service List: --service : Starts specific service/component. cli is default Parameters used: HADOOP_HOME or HADOOP_PREFIX : Hadoop install directory HIVE_OPT : Hive options For help on a particular service: # 查询特定服务名的帮助 ./hive --service serviceName --help Debug help: ./hive --debug --help ## 使用version服务 [hadoop@nnode hive1.2.0]$ bin/hive --service version Hive 1.2.0 Subversion git://localhost.localdomain/home/sush/dev/hive.git -r 7f237de447bcd726bb3d0ba332cbb733f39fc02f Compiled by sush on Thu May 14 18:00:25 PDT 2015 From source with checksum 03a73b649153ba8e11467a779def6315 [hadoop@nnode hive1.2.0]$ ## 执行--service不跟任何参数 [hadoop@nnode hive1.2.0]$ bin/hive --service等效于bin/hive --service cli
Service List包括绝大多数将要使用的CLI,可以通过--service name服务名称来启动,默认为启动cli。注意,个别服务实际上已提供了快捷启动方式。
常用服务如下图所示:
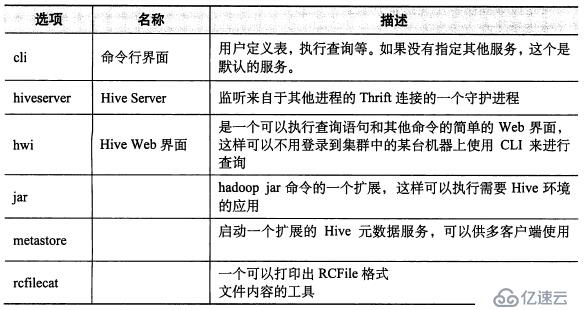
hive cli命令参数
[hadoop@nnode hive1.2.0]$ bin/hive --verbose --help usage: hive -d,--define <key=value> 定义hive命令行使用的参数,如-d A=B or --define A=B --database <databasename> 指定使用的数据库 -e <quoted-query-string> 通过命令行执行SQL语句 -f <filename> 执行文件中的SQL语句 -H,--help 显示帮助 --hiveconf <property=value> 给定参数值覆盖hive-default.xml或hive-site.xml中参数值 --hivevar <key=value> 定义应用到hive中的变量,如--hivevar A=B(等价于-d) -i <filename> 初始化的sql文件 -S,--silent 静态模式(无输出) -v,--verbose 详细模式 [hadoop@nnode hive1.2.0]$ ## 如 #hive -e "" #hive -e "">aaa #hive -S -e "">aaa #hive -e 'select a.col from tab1 a' #hive -f hdfs://<namenode>:<port>/hive-script.sql #hive -i /home/my/hive-init.sql #hive>source file #hive>!ls # 使用shell命令 #hive>dfs -ls / # 使用hdfs dfs命令(省略hdfs)
变量或属性
在CLI中,可以通过set命令显示或修改变量值,也可以通过命令空间指定。
Set操作示例
hive> set env:HOME; env:HOME=/home/hadoop hive> set env:HIVE_HOME; env:HIVE_HOME=/usr/local/hive1.2.0 hive>
命令空间指定方式为

示例代码:
#hive --hivevar column=name
#hive --hiveconf hive.cli.print.current.db=true hive.cli.print.header=true
#system: java定义的配置属性,如system:user.name(也就是System的properties的内容)
#env:shell环境变量,如env:USER、env.HIVE_HOME
## 验证hivevar、system、env
[hadoop@nnode hive1.2.0]$ hive --hivevar column=name
hive> create table test(id int, ${hivevar:column} string, ${system:user.name} string, path string);
OK
Time taken: 1.687 seconds
hive> insert into table test values(1000, 'lisi', 'root', '${env:HOME}');
# mapreduce过程略
hive> set hive.cli.print.header=true; # 显示header
hive> select * from test;
OK
test.id test.name test.hadoop test.path # 获取变量的值
1000 lisi root /home/hadoop
Time taken: 0.147 seconds, Fetched: 1 row(s)
hive>
## 验证hiveconf
[hadoop@nnode hive1.2.0]$ hive --hiveconf hive.cli.print.current.db=true
hive (default)> use mywork;
OK
Time taken: 1.089 seconds
hive (mywork)> set hive.cli.print.header=true;
hive (mywork)> select eno, ename from employee;
OK
eno ename
1000 zhangsan
Time taken: 0.223 seconds, Fetched: 1 row(s)
hive (mywork)>
2、Hive的Web模式
HWI是Hive Web Interface的简称,是hive cli的一个web替换方案。
通过service启动hwi服务的命令为bin/hive --service hwi
[hadoop@nnode hive1.2.0]$ bin/hive --service hwi ls: cannot access /usr/local/hive1.2.0/lib/hive-hwi-*.war: No such file or directory 15/12/12 22:30:08 INFO hwi.HWIServer: HWI is starting up 15/12/12 22:30:10 INFO mortbay.log: Logging to org.slf4j.impl.Log4jLoggerAdapter(org.mortbay.log) via org.mortbay.log.Slf4jLog 15/12/12 22:30:10 INFO mortbay.log: jetty-6.1.26 15/12/12 22:30:11 INFO mortbay.log: Started SocketConnector@0.0.0.0:9999 [hadoop@nnode hive1.2.0]$
提示hwi的war文件不存在,通过find命令查看时确实无法找到hwi的war文件,采用将src下hwi/web目录下的文件打成war包的形式来处理:
E:\Hive\apache-hive-1.2.0-src\hwi\web>jar cvf hive-hwi-1.2.0.war ./*
并将该war文件上传到$HIVE_HOME/lib目录下,并通过配置文件(hive-site.xml)修改hwi的配置参数
<property>
<name>hive.hwi.listen.host</name>
<value>nnode</value>
<description>This is the host address the Hive Web Interface will listen on</description>
</property>
<property>
<name>hive.hwi.listen.port</name>
<value>9999</value>
<description>This is the port the Hive Web Interface will listen on</description>
</property>
<property>
<name>hive.hwi.war.file</name>
<value>lib/hive-hwi-1.2.0.war</value>
<description>This sets the path to the HWI war file, relative to ${HIVE_HOME}.</description>
</property>再次起启动hwi的service服务,并通过web进行访问
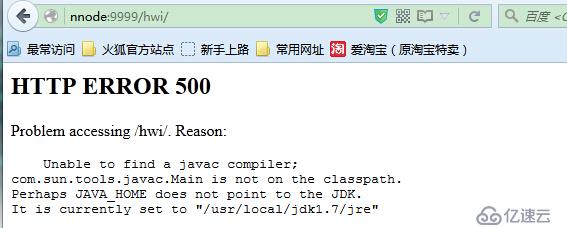
实际上已经将tools.jar添加到了classpath路径中了,没办法,只能将jdk路径下的tools.jar拷贝到hive的lib目录下,然后再次通过hive --service hwi启动,启动后访问,OK了。
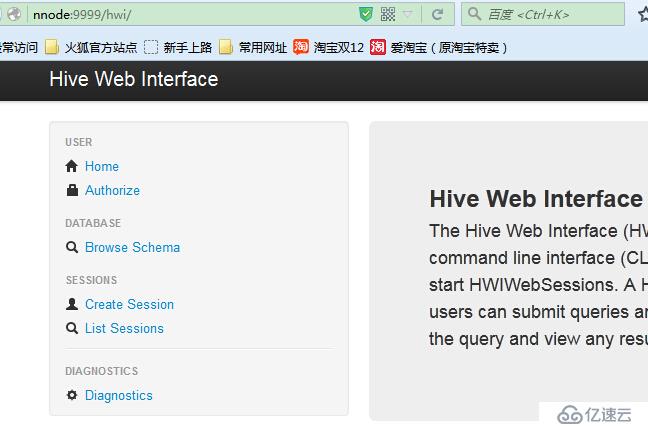
主要包括:
USER 用户信息,主要包括: 用户认证(Authorize) 创建会话(Create Session) 会话管理(List Sessions) DATABASE 浏览数据库及数据库的表,类似于show databases;show tables;describe table; DIAGNOSTICS 查看系统诊断信息,如System.getProperties的值等。
在hwi中的用户认证需要输入用户名和用户组,如:
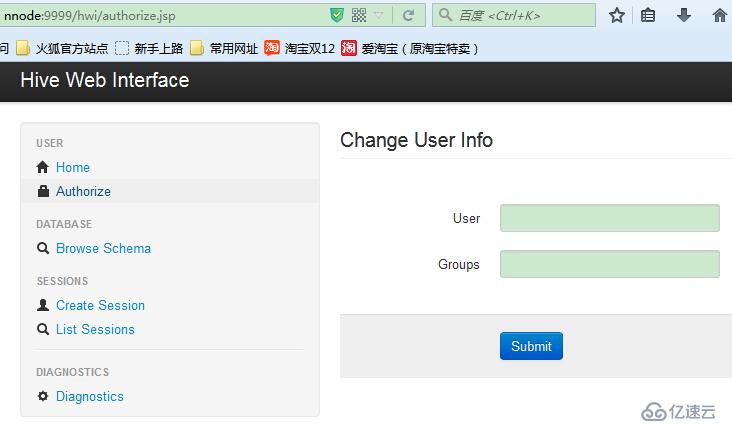
每一个用户认证(Authorize)信息对应着一组会话(session)。这些数据在hive重启后,session信息都会丢失。
在执行查询之前需要先通过Create Session创建会话,可以通过List Session查看创建的会话。
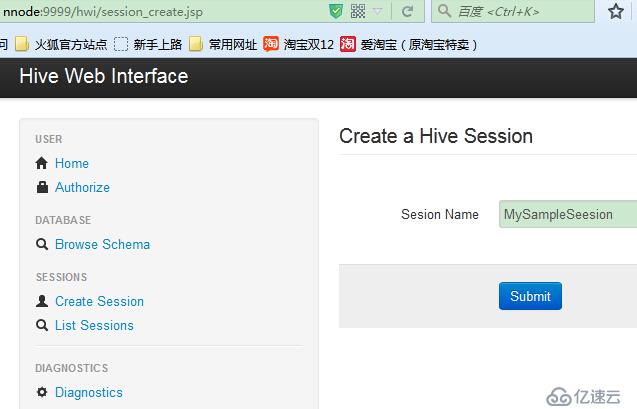
通过List Session就可以查看到该认证用户所对应的会话组了(实际没感觉到什么用)。
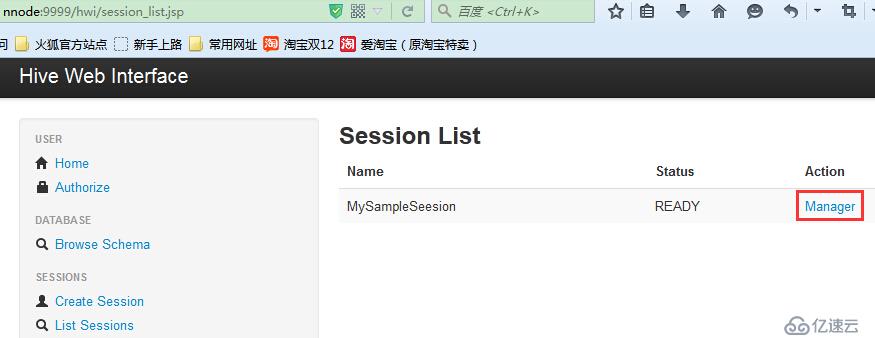
点击Manager执行查询操作
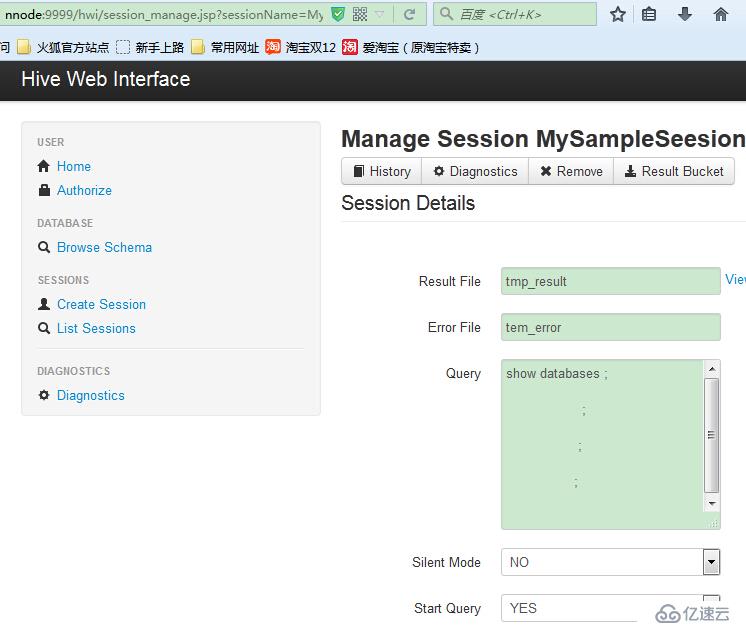
提交查询(Submit),会在Session Details显示session的执行状态,并可以通过View File查看结果
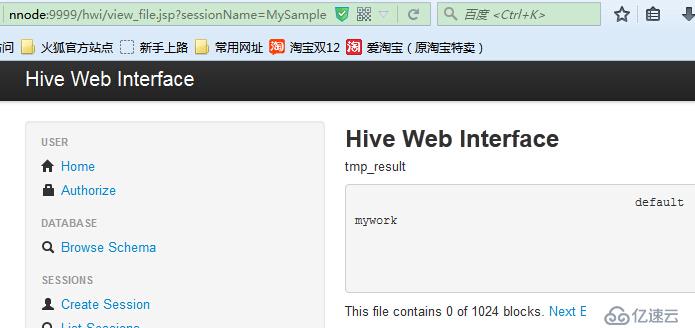
总结:个人感觉没什么用,还不如cli操作方便。
3、Hive的远程服务
实际上是将hive服务作为server启动,然后通过JDBC连接到hive,提交需要执行的SQL语句,通过hive解析执行后将结果返回。
[hadoop@nnode hive1.2.0]$ bin/hive --service hiveserver Starting Hive Thrift Server Exception in thread "main" java.lang.ClassNotFoundException: org.apache.hadoop.hive.service.HiveServer at java.net.URLClassLoader$1.run(URLClassLoader.java:366) at java.net.URLClassLoader$1.run(URLClassLoader.java:355) at java.security.AccessController.doPrivileged(Native Method) at java.net.URLClassLoader.findClass(URLClassLoader.java:354) at java.lang.ClassLoader.loadClass(ClassLoader.java:425) at java.lang.ClassLoader.loadClass(ClassLoader.java:358) at java.lang.Class.forName0(Native Method) at java.lang.Class.forName(Class.java:274) at org.apache.hadoop.util.RunJar.run(RunJar.java:214) at org.apache.hadoop.util.RunJar.main(RunJar.java:136) [hadoop@nnode hive1.2.0]$
Hive JDBC驱动连接分为两种,早期的是HiveServer,最新的是HiveServer2,前者本身存在很多的问题,如安全性、并发性等,后者很好的解决了诸如安全性和并发性等问题。
简介: 2015年02月08日Apache Hive 1.0.0 正式发布了。该版本原本是要命名为 Hive 0.14.1,但是团队感觉 到了该用 1.x.y 的方式命名的时候了。不过该版本改变的内容并不多,值得关注的有两个: 为 HiveMetaStoreClient 定义 API; 移除 HiveServer 1,全面使用 HiveServer 2。 参见:https://cwiki.apache.org/confluence/display/Hive/HiveServer
服务启动程序为${HIVE_HOME}/bin/hiveserver2里面,通过下面的方式来启动:
$HIVE_HOME/bin/hiveserver2 或 $HIVE_HOME/bin/hive --service hiveserver2 [hadoop@nnode hive1.2.0]$ ll bin/ total 32 -rwxr-xr-x 1 hadoop hadoop 1031 Apr 30 2015 beeline drwxr-xr-x 3 hadoop hadoop 4096 Jun 28 13:14 ext -rwxr-xr-x 1 hadoop hadoop 7844 May 8 2015 hive -rwxr-xr-x 1 hadoop hadoop 1900 Apr 30 2015 hive-config.sh -rwxr-xr-x 1 hadoop hadoop 885 Apr 30 2015 hiveserver2 -rwxr-xr-x 1 hadoop hadoop 832 Apr 30 2015 metatool -rwxr-xr-x 1 hadoop hadoop 884 Apr 30 2015 schematool [hadoop@nnode hive1.2.0]$
注意:
hiveserver默认端口是10000,可通过hive --service hiveserver -p 10002,更改默认启动端口,此端口也是JDBC连接端口。
hiveserver不能和hwi服务同时启动使用。
如果之前的代码使用的是HiveServer(或者叫HiveServer1),当hive升级采用HiveServer2后,代码部分需要做如下调整:
private static String driverName = "org.apache.hadoop.hive.jdbc.HiveDriver";
改为
private static String driverName = "org.apache.hive.jdbc.HiveDriver";
Connection con = DriverManager.getConnection("jdbc:hive://ip:10002/default", "username", "");
改为
Connection con = DriverManager.getConnection("jdbc:hive2://ip:10002/default", "username", "");启动服务
[hadoop@nnode hive1.2.0]$ bin/hiveserver2
JavaApi调用
package com.lucl.hive;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
/**
*
* @author lucl
*
*/
public class JDBCHiveDriver {
private static String driver = "org.apache.hive.jdbc.HiveDriver";
private static String url = "jdbc:hive2://nnode:10000/mywork";
private static String user = "hadoop"; // 这里的用户是hadoop集群的用户
private static String pwd = "";
public static void main(String[] args) {
String sql = "show tables";
try{
Class.forName(driver);
Connection con = DriverManager.getConnection(url, user, pwd);
Statement st = con.createStatement();
ResultSet rs = st.executeQuery(sql);
while (rs.next()) {
System.out.println(rs.getString(1));
}
con.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}Eclipse的Console输出结果
11:25:11,348 INFO Utils:310 - Supplied authorities: nnode:10000 11:25:11,351 INFO Utils:397 - Resolved authority: nnode:10000 11:25:11,461 INFO HiveConnection:203 - Will try to open client transport with JDBC Uri: jdbc:hive2://nnode:10000/mywork table name is : employee table name is : employee_02 table name is : student
关于HiveServer2的使用帮助参见:
https://cwiki.apache.org/confluence/display/Hive/HiveServer2+Clients#HiveServer2Clients-UsingJDBC
总结:
个人感觉通过JDBC方式操作Hive生产环境中意义不大,hive的查询主要还是基于MapReduce实现(尽管部分功能已做了优化可以无需MR处理),而MapReduce属于离线计算模型,时效性上可能会比较差,执行一次调用等几分钟甚至更长,一般人接收不了,比较好的方式还是通过JDBC访问RDBMS来完成。
Hive的主要功能可能是其方便了对HDFS数据的处理,毕竟熟悉SQL的那波人不见得对JAVA或者MR编程熟悉,属于HDFS的客户端工具但毕竟能力有限。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。