您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
wordcount.toDebugString查看RDD的继承链条
所以广义的讲,对任何函数进行某一项操作都可以认为是一个算子,甚至包括求幂次,开方都可以认为是一个算子,只是有的算子我们用了一个符号来代替他所要进行的运算罢了,所以大家看到算子就不要纠结,他和f(x)的f没区别,它甚至和加减乘除的基本运算符号都没有区别,只是他可以对单对象操作罢了(有的符号比如大于、小于号要对多对象操作)。又比如取概率P{X<x},概率是集合{X<x}(他是属于实数集的子集)对[0,1]区间的一个映射,我们知道实数域和[0,1]区间是可以一一映射的(这个后面再说),所以取概率符号P,我们认为也是一个算子,和微分,积分算子算子没区别。
总而言之,算子就是映射,就是关系,就是**变换**!
**mapPartitions(f)**
f函数的输入输出都是每个分区集合的迭代器Iterator
def mapPartitions[U](f: (Iterator[T]) => Iterator[U], preservesPartitioning: Boolean = false)(implicit arg0: ClassTag[U]): RDD[U]
该函数和map函数类似,只不过映射函数的参数由RDD中的每一个元素变成了RDD中每一个分区的迭代器。如果在映射的过程中需要频繁创建额外的对象,使用mapPartitions要比map高效的过。
比如,将RDD中的所有数据通过JDBC连接写入数据库,如果使用map函数,可能要为每一个元素都创建一个connection,这样开销很大,如果使用mapPartitions,那么只需要针对每一个分区建立一个connection。
参数preservesPartitioning表示是否保留父RDD的partitioner分区信息。
参考文章:
http://lxw1234.com/archives/2015/07/348.htm
union(other: RDD[T])操作不去重,去重需要distinct()
subtract取两个RDD中非公共的元素
sample返回RDD,takeSample直接返回数组(数组里面的元素为RDD中元素,类似于collect)
keyvalue之类的操作都在**PairRDDFunctions.scala**中
mapValues只对value进行运算
groupBy相同key的元素的value组成集合
coGroup是在groupBy的基础上
coGroup操作多个RDD,是两个RDD里相同key的两个value集合组成的元组
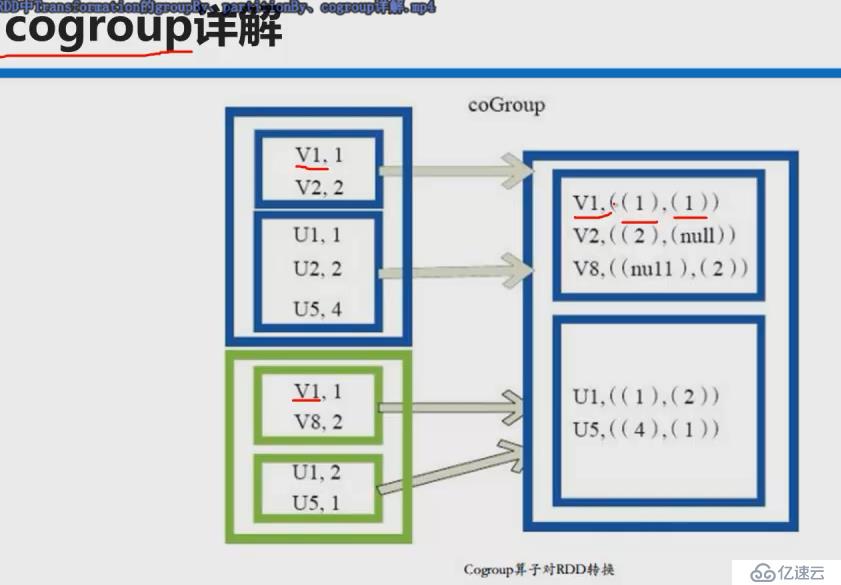
参考文章:
http://www.iteblog.com/archives/1280
**combineByKey和reduceByKey,groupByKey(内部都是通过combineByKey)**
源码分析:
reduceByKey mapSideCombine: Boolean = true
groupByKey mapSideCombine=false
所以优先使用reduceByKey,参考文章:http://www.iteblog.com/archives/1357
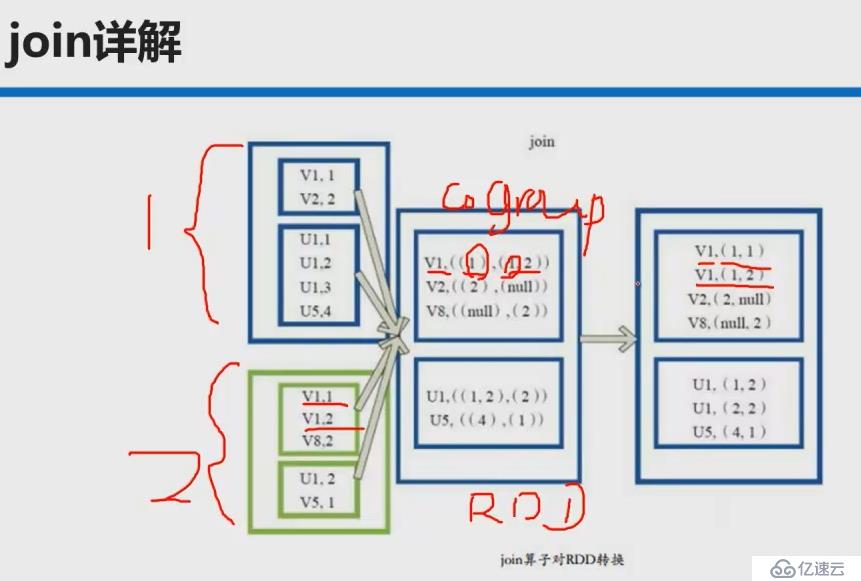
**join操作**
本质是先coGroup再笛卡尔积
def join[W](other: RDD[(K, W)], partitioner: Partitioner): RDD[(K, (V, W))] = {
this.cogroup(other, partitioner).flatMapValues( pair =>
for (v <- pair._1.iterator; w <- pair._2.iterator) yield (v, w)
)
}
**yield** 关键字的简短总结:
针对每一次 for 循环的迭代, yield 会产生一个值,被循环记录下来 (内部实现上,像是一个缓冲区).
当循环结束后, 会返回所有 yield 的值组成的集合.
返回集合的类型与被遍历的集合类型是一致的.
参考文章:
http://unmi.cc/scala-yield-samples-for-loop/
cache persist也是lazy级别的
Action本质sc.runJob
foreach
collect()相当于toArray返回一个数组
collectAsMap()对keyvalue类型的RDD操作返回一个HashMap,key重复后面的元素会覆盖前面的元素reduce
源码解析:先调用collect()再放到HashMap[K, V]中
def collectAsMap(): Map[K, V] = {
val data = self.collect()
val map = new mutable.HashMap[K, V]
map.sizeHint(data.length)
data.foreach { pair => map.put(pair._1, pair._2) }
map
}
**reduceByKeyLocally**相当于reduceByKey+collectAsMap()
该函数将RDD[K,V]中每个K对应的V值根据映射函数来运算,运算结果映射到一个Map[K,V]中,而不是RDD[K,V]。
参考文章:
http://lxw1234.com/archives/2015/07/360.htm
**lookup**也是针对keyvalue返回指定key对应的value形成的seq
def lookup(key: K): Seq[V]
**reduce fold(每个分区是串行,有个初始值) aggregate(并行,与fold类似)**
前两个元素作用的结果与第三元素作用依次类推
**SequenceFile**文件是Hadoop用来存储二进制形式的key-value对而设计的一种平面文件(Flat File)。目前,也有不少人在该文件的基础之上提出了一些HDFS中小文件存储的解决方案,他们的基本思路就是将小文件进行合并成一个大文件,同时对这些小文件的位置信息构建索引。不过,这类解决方案还涉及到Hadoop的另一种文件格式——**MapFile**文件。SequenceFile文件并不保证其存储的key-value数据是按照key的某个顺序存储的,同时不支持append操作。
参考文章:http://blog.csdn.net/xhh298781/article/details/7693358
**saveAsTextFile**->TextOutputFormat (key为null,value为元素toString)
**saveAsObjectFile**(二进制)->saveAsSequenceFile->SequenceFileOutputFormat(key为null,value为BytesWritable)
cache\persist
**checkpoint()**机制避免缓存丢失(内存不足)要重新计算带来的性能开销,会导致另外一个作业,比缓存更可靠
SparkContex.setCheckpointDir设置目录位置
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。