жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ

пјҲ1пјүеҲӣе»әж•°жҚ®еә“create database db_hive2;`<br/>`жҲ–иҖ…`<br/>`create database if not exists db_hive;
ж•°жҚ®еә“еңЁHDFSдёҠзҡ„й»ҳи®ӨеӯҳеӮЁи·Ҝеҫ„/user/hive/warehouse/*.db
пјҲ2пјүжҳҫзӨәжүҖжңүж•°жҚ®еә“show databases;
пјҲ3пјүжҹҘиҜўж•°жҚ®еә“show database like вҖҳdb_hiveвҖҷ;
пјҲ4пјүжҹҘиҜўж•°жҚ®еә“иҜҰжғ…desc database db_hive;
пјҲ5пјүжҳҫзӨәж•°жҚ®еә“ desc database extended db_hive;
пјҲ6пјүеҲҮжҚўеҪ“еүҚж•°жҚ®еә“use db_hive;
пјҲ7пјүеҲ йҷӨж•°жҚ®еә“
#еҲ йҷӨдёәз©әзҡ„ж•°жҚ®жҺ§drop database db_hive;
#еҰӮжһңеҲ йҷӨзҡ„ж•°жҚ®еә“дёҚеӯҳеңЁпјҢжңҖеҘҪйҮҮз”Ёif existsеҲӨж–ӯж•°жҚ®еә“жҳҜеҗҰеӯҳеңЁdrop database if exists db_hive;
#еҰӮжһңж•°жҚ®еә“дёӯжңүиЎЁеӯҳеңЁпјҢйңҖиҰҒдҪҝз”ЁcascadeејәеҲ¶еҲ йҷӨж•°жҚ®еә“drop database if exists db_hive cascade;
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name[(col_name data_type [COMMENT col_comment], ...)][COMMENT table_comment] иЎЁзҡ„жҸҸиҝ°еҸҜеҠ еҸҜдёҚеҠ [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] еҲҶеҢә[CLUSTERED BY (col_name, col_name, ...) еҲҶжЎ¶[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
йҮҚзӮ№пјҡиҜ»еҸ–ж–Үжң¬жҳҜиҜ»дёҖиЎҢж•°жҚ®пјҢйңҖиҰҒз”ЁеҲҶйҡ”з¬ҰеҲҶеүІпјҢз”ЁжқҘеҢ№й…ҚиЎЁзҡ„еҲ—[ROW FORMAT row_format] row format delimited fields terminated by вҖңеҲҶйҡ”з¬ҰвҖқ[STORED AS file_format] еӯҳеӮЁеҜ№еә”зҡ„ж–Үд»¶ж јејҸ[LOCATION hdfs_path]еӯҳеӮЁеңЁhdfsзҡ„е“ӘдёӘзӣ®еҪ•
еӯ—ж®өи§ЈйҮҠиҜҙжҳҺпјҡ
CREATE TABLE пјҡеҲӣе»әжҢҮе®ҡеҗҚз§°зҡ„иЎЁпјҢеҰӮжһңеӯҳеңЁжҠҘејӮеёёпјҢеҸҜд»ҘдҪҝз”Ё IF NOT EXISTS пјҡжқҘйҒҝе…ҚиҝҷдёӘејӮеёёгҖӮEXTERNALпјҡеҲӣе»әеӨ–йғЁиЎЁпјҢеңЁе»әиЎЁзҡ„еҗҢж—¶еҸҜд»ҘжҢҮе®ҡжәҗж•°жҚ®зҡ„и·Ҝеҫ„LOCATIONпјҡеҲӣе»әеҶ…йғЁиЎЁж—¶пјҢдјҡе°Ҷж•°жҚ®з§»еҠЁеҲ°ж•°жҚ®д»“еә“жҢҮеҗ‘зҡ„и·Ҝеҫ„пјҢиӢҘеҲӣе»әеӨ–йғЁиЎЁдёҚдјҡжңүд»»дҪ•ж”№еҸҳгҖӮеңЁеҲ йҷӨиЎЁж—¶пјҢеҶ…йғЁиЎЁзҡ„е…ғж•°жҚ®е’Ңжәҗж•°жҚ®йғҪдјҡиў«еҲ йҷӨпјҢеӨ–йғЁиЎЁдёҚдјҡеҲ йҷӨжәҗж•°жҚ®гҖӮCOMMENTпјҡдёәиЎЁе’ҢеҲ—еўһеҠ жіЁйҮҠPARTITIONED BYпјҡеҲӣе»әеҲҶеҢәиЎЁCLUSTERED BYпјҡеҲӣе»әеҲҶжЎ¶иЎЁSORTED BYпјҡеҲӣе»әжҺ’еәҸеҗҺеҲҶжЎ¶иЎЁпјҲдёҚеёёз”ЁпјүSTORED AS пјҡжҢҮе®ҡеӯҳеӮЁж–Ү件зұ»еһӢsequencefileпјҲдәҢиҝӣеҲ¶еәҸеҲ—ж–Ү件пјүгҖҒtextfileпјҲж–Үжң¬пјүгҖҒrcfileпјҲеҲ—ејҸеӯҳеӮЁж јејҸж–Ү件пјүпјҢеҰӮжһңж–Ү件数жҚ®жҳҜзәҜж–Үжң¬пјҢеҸҜд»ҘдҪҝз”ЁSTORED AS TEXTFILEгҖӮеҰӮжһңйңҖиҰҒдҪҝз”ЁеҺӢзј©пјҢдҪҝз”ЁSTORED AS SEQUENCEFILELOCATION жҢҮе®ҡиЎЁеңЁ hdfs дёҠзҡ„еӯҳеӮЁдҪҚзҪ®
1гҖҒзӣҙжҺҘдҪҝз”Ёж ҮеҮҶзҡ„е»әиЎЁиҜӯеҸҘпјҡ
create table if not exists student11(id int,name string)row format delimited fields terminated by '\t'stored as textfile;
дҪҝз”Ёж–Үжң¬data.txt
1 zhang
2 lisi
2гҖҒжҹҘиҜўе»әиЎЁжі•:
йҖҡиҝҮASжҹҘиҜўиҜӯеҸҘе®ҢжҲҗе»әиЎЁпјҡе°ҶеӯҗжҹҘиҜўзҡ„з»“жһңеӯҳж”ҫеңЁж–°иЎЁйҮҢпјҢжңүж•°жҚ®
create table if not exists student1 as select id,name from student;
3гҖҒlikeе»әиЎЁжі•пјҡ
ж №жҚ®е·ІеӯҳеңЁзҡ„иЎЁз»“жһ„еҲӣе»әиЎЁ
create table if not exists student2 like student;
4гҖҒжҹҘиҜўиЎЁзҡ„зұ»еһӢпјҡ
desc formatted student;
5гҖҒеҶ…йғЁиЎЁзҡ„й»ҳи®ӨдҪҚзҪ®пјҡ
пјҲж №жҚ®иҮӘе·ұжғ…еҶөжқҘе®ҡпјү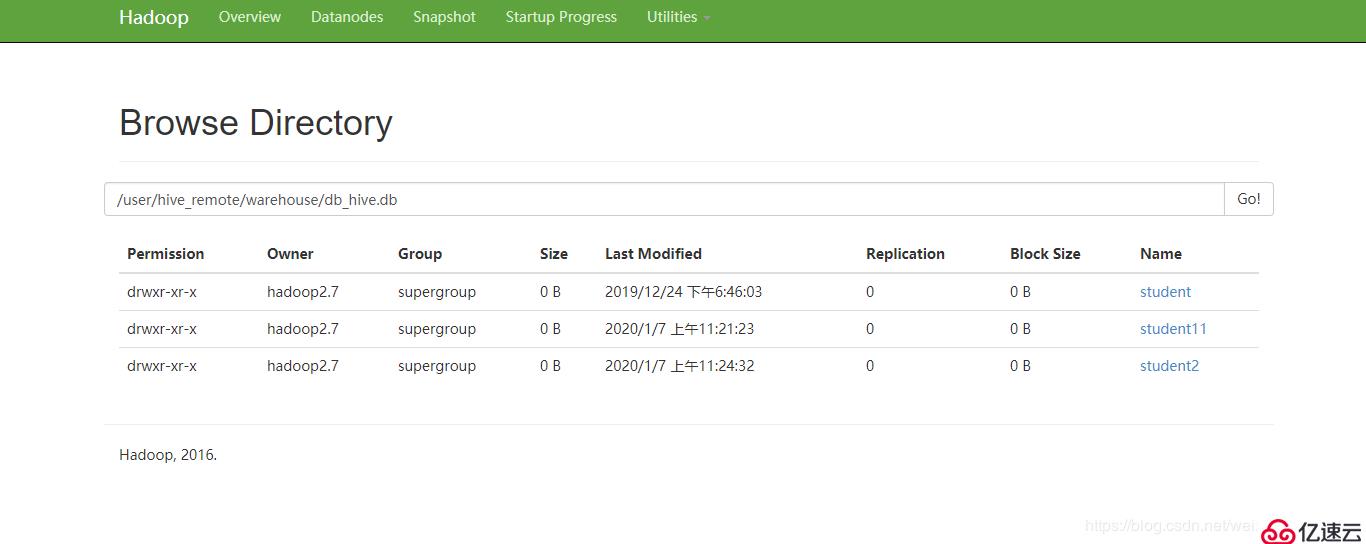
/user/hive_remote/warehouse/db_hive.db
6гҖҒе°Ҷж•°жҚ®еҜје…ҘеҲ°HiveиЎЁдёӯпјҡ
дёҫеҲ—еӯҗпјҡstudent11sжҳҜHiveиЎЁ
load data local inpath '/opt/bigdata2.7/hivedata/student.txt' into table student11;
жіЁж„ҸпјҡdefaultжҳҜж•°жҚ®еә“зҡ„еҗҚ
create external table if not exists default.emp(id int,name string)row format delimited fields terminated by '\t'location '/ opt/bigdata2.7/hivedata'
еҲӣе»әеӨ–йғЁиЎЁзҡ„ж—¶еҖҷйңҖиҰҒеҠ дёҠexternalе…ій”®еӯ—пјҢlocationеӯ—ж®өеҸҜд»ҘжҢҮе®ҡпјҢд№ҹеҸҜд»ҘдёҚжҢҮе®ҡпјҢдёҚжҢҮе®ҡзҡ„иҜқе°ұжҳҜдҪҝз”Ёй»ҳи®Өзӣ®еҪ•/user/hive/warehouse
вҖӢ 1гҖҒеҶ…йғЁиЎЁиҪ¬жҚўдёәеӨ–йғЁиЎЁ
#жҠҠstudent еҶ…йғЁиЎЁж”№дёәеӨ–йғЁиЎЁ
alter table student set tblproperties('EXTERNAL'='TRUE');
вҖӢ 2гҖҒеӨ–йғЁиЎЁиҪ¬жҚўжҲҗеҶ…йғЁиЎЁ
alter table student set tblproperties('EXTERNAL'='FALSE');
1гҖҒе»әиЎЁиҜӯжі•дёҚеҗҢпјҡ
еӨ–йғЁиЎЁе»әиЎЁзҡ„ж—¶еҖҷйңҖиҰҒеҠ дёҠexternalе…ій”®еӯ—
2гҖҒж•°жҚ®еӯҳеӮЁдҪҚзҪ®дёҚеҗҢпјҡ
еҲӣе»әеҶ…йғЁиЎЁзҡ„ж—¶еҖҷпјҢдјҡе°Ҷж•°жҚ®з§»еҠЁеҲ°ж•°жҚ®д»“еә“жҢҮеҗ‘зҡ„и·Ҝеҫ„пјӣиӢҘеҲӣе»әеӨ–йғЁиЎЁпјҢд»…д»…и®°еҪ•ж•°жҚ®жүҖеңЁзҡ„и·Ҝеҫ„пјҢдёҚеҜ№ж•°жҚ®зҡ„дҪҚзҪ®иҝӣиЎҢд»»дҪ•ж”№еҸҳгҖӮ
2гҖҒеҲ йҷӨиЎЁд№ӢеҗҺпјҡ
еҶ…йғЁиЎЁдјҡеҲ йҷӨе…ғж•°жҚ®пјҢеҲ йҷӨиЎЁзҡ„ж•°жҚ®гҖӮ
еӨ–йғЁиЎЁеҲ йҷӨд№ӢеҗҺпјҢд»…д»…жҳҜжҠҠиЎЁзҡ„е…ғж•°жҚ®еҲ йҷӨдәҶпјҢзңҹе®һзҡ„ж•°жҚ®иҝҳеңЁпјҢеҗҺжңҹиҝҳеҸҜд»ҘжҒўеӨҚеҮәжқҘгҖӮ
1гҖҒж•°жҚ®ж јејҸпјҡ
жҲҳзӢј1,еҗҙдә¬1:еҗҙеҲҡ1:е°ҸжҳҺ1,2017-08-01
жҲҳзӢј2,еҗҙдә¬2:еҗҙеҲҡ2:е°ҸжҳҺ2,2017-08-02
жҲҳзӢј3,еҗҙдә¬4:еҗҙеҲҡ4:е°ҸжҳҺ4,2017-08-03
жҲҳзӢј4,еҗҙдә¬3:еҗҙеҲҡ3:е°ҸжҳҺ3,2017-08-04
жҲҳзӢј5,еҗҙдә¬5:еҗҙеҲҡ5:е°ҸжҳҺ5,2017-08-05
2гҖҒе»әиЎЁиҜӯеҸҘпјҡ
create table t_movie(movie_name string,actors array<string>,first_date string)row format delimited fields terminated by ','collection items terminated by ':';
3гҖҒеҜје…Ҙж•°жҚ®пјҡ
зЎ®дҝқhadoopз”ЁжҲ·еҜ№иҜҘж–Ү件еӨ№жңүиҜ»еҶҷжқғйҷҗгҖӮload data local inpath '/opt/bigdata2.7/hive/movie';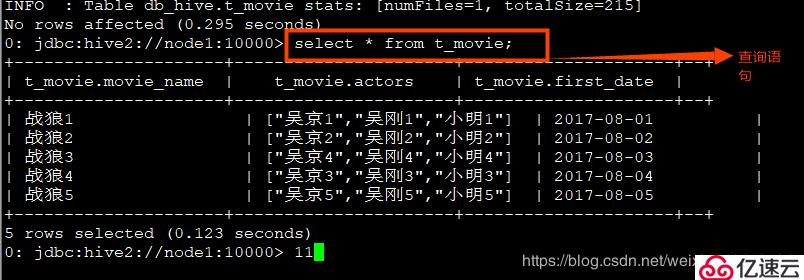
4гҖҒжҹҘиҜўжҜҸдёӘз”өеҪұзҡ„第дәҢдёӘдё»жј”пјҡ
select movie_name,actors[1] from t_movie;
[еӨ–й“ҫеӣҫзүҮиҪ¬еӯҳеӨұиҙҘ,жәҗз«ҷеҸҜиғҪжңүйҳІзӣ—й“ҫжңәеҲ¶,е»әи®®е°ҶеӣҫзүҮдҝқеӯҳдёӢжқҘзӣҙжҺҘдёҠдј (img-hgfz0RZZ-1579482997640)(2%E3%80%81Hive%E7%9A%84DDL%E8%AF%AD%E6%B3%95%E6%93%8D%E4%BD%9C.assets/image-20200109093038358.png)]
5гҖҒжҹҘиҜўжҜҸйғЁз”өеҪұжңүеҮ еҗҚдё»жј”:
select movie_name,size(actors) as num from t_movie;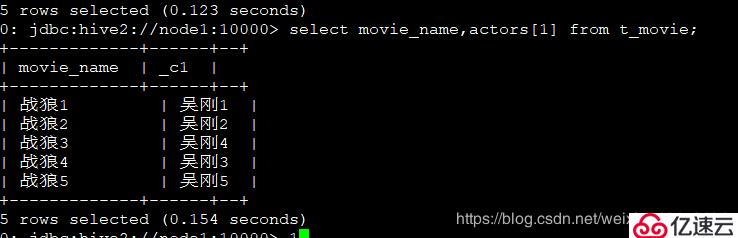
6гҖҒдё»жј”йҮҢеҢ…еҗ«еҗҙеҲҡ5зҡ„з”өеҪұ
select movie_name,actors from t_movie where array_contains(actors,'еҗҙеҲҡ5');
и§Јжһҗпјҡ
иҝҷйҮҢжҲ‘们йҰ–е…ҲзңӢеҲ°жҜ”иҫғзү№ж®Ҡзҡ„жҳҜдё»жј”зҡ„еҗҚеӯ—пјҢиҖҢеҗҚеӯ—жңүйғҪжҳҜstringзұ»еһӢзҡ„пјҢжүҖд»ҘиҖғиҷ‘еҲ°дҪҝз”Ёarrayзұ»еһӢпјҢд»ҘдёәarrayеӯҳеӮЁзҡ„йғҪжҳҜжғіеҗҢзұ»еһӢзҡ„е…ғзҙ гҖӮиҝҷйҮҢжҲ‘们иҰҒдҪҝз”Ёcollection items terminated by ':',жқҘи®ҫзҪ®жҢҮе®ҡеӨҚжқӮе…ғзҙ ж•°жҚ®зұ»еһӢдёӯе…ғзҙ зҡ„еҲҶйҡ”з¬ҰгҖӮ
йңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҡcollection items terminated byдёҚд»…жҳҜз”ЁжқҘеҲҶйҡ”arrayзҡ„пјҢе®ғзҡ„дҪңз”ЁжҳҜеҲҶйҡ”еӨҚжқӮж•°жҚ®зұ»еһӢйҮҢйқўзҡ„е…ғзҙ зҡ„гҖӮsizeеҶ…зҪ®еҮҪж•°жҳҜз”ЁжқҘеҲӨж–ӯarrayе…ғзҙ зҡ„дёӘж•°пјҢarray_contains()жҳҜеҲӨж–ӯarrayжҳҜеҗҰжңүиҝҷдёӘе…ғзҙ гҖӮ
1гҖҒж•°жҚ®ж јејҸпјҡ
1пјҢеј дёүпјҢ18:male:еҢ—дә¬
2пјҢжқҺеӣӣпјҢ19:male:еҚ—дә¬
3пјҢзҺӢдә”пјҢ20:male:дёҠжө·
4пјҢе“Ҳе“ҲпјҢ18:male:еҢ—дә¬
5пјҢеҳҝеҳҝпјҢ12:male:жҲҗйғҪ
6пјҢеҳ»еҳ»пјҢ14:male:жөҺеҚ—
7пјҢеј дёҪпјҢ17:male:ж·ұеңі
8пјҢжқҺзү©пјҢ19:male:йҮҚеәҶ
2гҖҒе»әиЎЁиҜӯеҸҘпјҡ
create table t_user(id int,name string,info struct<age:string,sex:string,addr:string>)row format delimited fields terminated by ','collection items terminated by ':';
3гҖҒеҜје…Ҙж•°жҚ®пјҡ
load data local inpath '/opt/bigdata2.7/hive/user' into table t_user;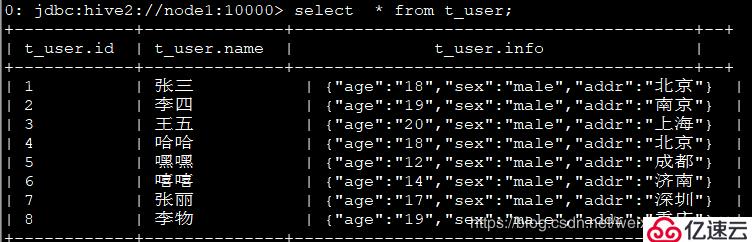
4гҖҒ жҹҘиҜўжҜҸдёҖдёӘдәәзҡ„id,еҗҚеӯ—,еұ…дҪҸең°еқҖпјҡ
select id,name,info.addr from t_user;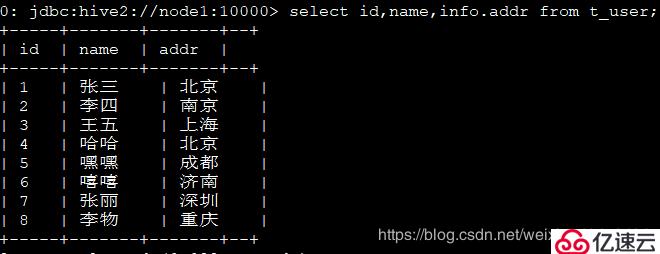
и§Јжһҗпјҡ
иҝҷйҮҢжҜ”иҫғзү№ж®Ҡзҡ„еӯ—ж®өжҳҜ18:male:еҢ—дә¬пјҢеҜ№еә”зҡ„жҳҜе№ҙйҫ„пјҡжҖ§еҲ«пјҡең°еқҖпјҢжҜҸдёҖдёӘйғҪжңүзү№ж®Ҡзҡ„еҗ«д№үпјҢжҲ‘们иҖғиҷ‘еҲ°ж— жі•жһ„жҲҗдёҖдёӘй”®еҖјеҜ№пјҢжүҖд»ҘmapдёҚеҗҲйҖӮпјҢarrayеҸӘиғҪеҢ…еҗ«зӣёеҗҢзҡ„е…ғзҙ пјҢиҖҢе№ҙйҫ„жҳҜintзұ»еһӢпјҢең°еқҖжҳҜstrinзұ»еһӢпјҢжүҖд»ҘarrayдёҚеҗҲйҖӮпјҢжүҖд»ҘиҖғиҷ‘structгҖӮ
1гҖҒж•°жҚ®жҸҸиҝ°пјҡ
1,е°ҸжҳҺ,father:еј дёү#mother:жқҺдёҪ#brother:е°ҸеҲҡ,28
2,е°Ҹйёҝ,father:жқҺеӣӣ#mother:зҺӢдёҪ#brother:е°Ҹеҝ—,28
3,е°Ҹй№Ҹ,father:еј зү©#mother:жқҺзҫҺ#brother:е°ҸиӢұ,28
4,еј йЈһ,father:еј дә”#mother:жқҺеҪұ#brother:е°Ҹе…Ё,28
2гҖҒе»әиЎЁиҜӯеҸҘпјҡ
create table t_family(id int,name string,family_mem map<string,string>,age int)row format delimited fields terminated by ','collection items terminated by '#'map keys terminated by ':';
3гҖҒеҜје…Ҙж•°жҚ®пјҡ
load data local inpath '/opt/bigdata2.7/hive/family' into table t_family;
4гҖҒжҹҘзңӢжҜҸдёӘдәәзҡ„зҲ¶дәІпјҡ
select name,family_mem["father"] from t_family;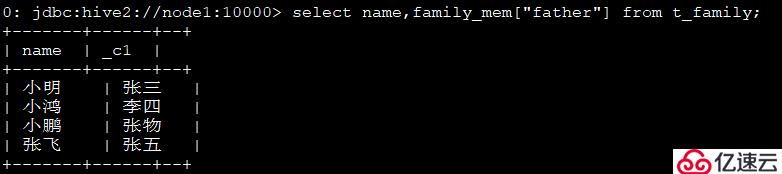
5гҖҒжҹҘзңӢжңүе“ӘдәӣдәІеұһе…ізі»пјҡselect name,map_keys(family_mem),age from t_family;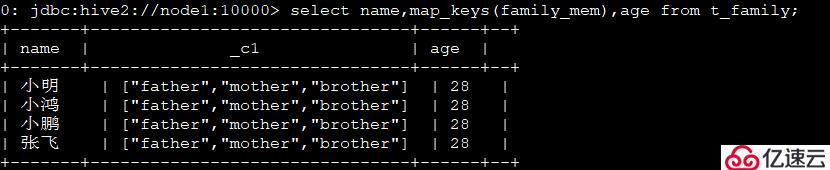
6гҖҒжҹҘеҮәжҜҸдёӘдәәзҡ„дәІдәәеҗҚеӯ—пјҡ
select name,map_values(family_mem) as relations,age from t_family;
7гҖҒжҹҘеҮәжҜҸдёӘдәәдәІдәәзҡ„ж•°йҮҸпјҡ
select id,name,size(family_mem) as relation_num,age from t_family;
alter table student_partition1 rename to student_partition2
desc student_partition3;
desc formated student_partition3;
еўһеҠ еҲ—пјҡ
alter table student_partition3 add columns(address string);
дҝ®ж”№еҲ—пјҡ
alter table student_partition3 change column address address_id int;
жӣҝжҚўеҲ—пјҡ
alter table student_partition3 replace columns(deptno string,dname string,loc string);
1гҖҒж·»еҠ еҲҶеҢә:
пјҲ1пјүж·»еҠ еҚ•дёӘеҲҶеҢәпјҡ
alter table student_partition1 add partition(dt='20170601');
пјҲ2пјүж·»еҠ еӨҡдёӘеҲҶеҢәпјҡ
alter table student_partition1 add partition(dt='20170602') partition(dt='20170603');
2гҖҒеҲ йҷӨеҲҶеҢә:
alter table student_partition1 drop partition (dt='20170601');
alter table student_partition1 drop partition (dt='20170601') partition (dt='20170602');
3гҖҒжҹҘзңӢеҲҶеҢә:
show partitions student_partition1;
load data [local] impath 'datapath' overwrite | into table student [partition (partcol1=val1,...)];
load data: иЎЁзӨәеҠ иҪҪж•°жҚ®
local:иЎЁзӨәд»Һжң¬ең°еҠ иҪҪж•°жҚ®еҲ°hiveиЎЁдёӯпјӣеҗҰеҲҷд»ҺHDFSеҠ иҪҪеҲ°hiveиЎЁдёӯ
inpath: иЎЁзӨәеҠ иҪҪж•°жҚ®зҡ„и·Ҝеҫ„
overwiteпјҡиЎЁзӨәиҰҶзӣ–иЎЁдёӯе·Іжңүж•°жҚ®пјҢеҗҰеҲҷиЎЁзӨәиҝҪеҠ
into table:иЎЁзӨәеҠ иҪҪеҲ°е“Әеј иЎЁ
жҷ®йҖҡиЎЁдёҫдҫӢпјҡ
load data local inpath '/opt/bigdata2.7/hive/person.txt' into table person;
еҲҶеҢәиЎЁдёҫдҫӢпјҡ
load data local inpath '/opt/bigdata2.7/hive/person.txt' into table person partition (dt="20190202");
д»ҺжҢҮе®ҡзҡ„иЎЁдёӯжҹҘиҜўж•°жҚ®з»“жһң然еҗҺжҸ’е…ҘеҲ°зӣ®ж ҮиЎЁдёӯ
insert into/overwrite table tablename select **** from tablename;
insert into table student_partion1 partition(dt="2019-07-08") select * from tablename;
create table if not exists tablename as select id,name from tablename;
еҲӣе»әиЎЁпјҢ并жҢҮе®ҡеңЁhdfsдёҠзҡ„дҪҚзҪ®
create table if not exists student1(id int,name string)row format delimited fields terminated by '\t'location '/usr/hive_remote/warehouse/student1';
create table if not exists person(id int,name string,age int,sex string)row format delimited fields terminated by ',';
дёҠдј ж•°жҚ®ж–Ү件еҲ°hdfsеҜ№еә”зҡ„зӣ®еҪ•дёӯ
еңЁLinuxдёӯиҝҗиЎҢпјҢжіЁж„ҸдёҚжҳҜhiveз«ҜеҸЈ
hdfs dfs -put /opt/bigdata2.7/hive/student1.txt /usr/hive_remote/warehouse/student1
жіЁж„Ҹпјҡе…Ҳз”ЁexportеҜјеҮәд№ӢеҗҺпјҢеҶҚе°Ҷж•°жҚ®еҜје…Ҙ
create table student2 like student1;
export table student1 to '/export/student1';
import table student2 from 'export/student1'
1гҖҒе°ҶжҹҘиҜўж•°жҚ®зҡ„з»“жһңеҜјеҮәеҲ°жң¬ең°
insert overwrite local directory '/opt/bigdata/export/student' select * from student;
2гҖҒе°ҶжҹҘиҜўз»“жһ„ж јејҸеҢ–зҡ„еҜјеҮәеҲ°жң¬ең°
insert overwrite local directory '/opt/bigdata/export/student' row format delimited fields teminated by ','select * from student;
3гҖҒе°ҶжҹҘиҜўз»“жһңеҜјеҮәеҲ°HDFSпјҲжІЎжңүlocalпјү
insert overwrite directory '/user/export/student' row format delimited fields terminated by ','select * from student;
hdfs dfs -get /user/hive_remote/warehouse/student/student.txt /opt/bigdata2.7/data
hive -e 'select * from default.student' > /opt/bigdata/data/student1.txt
export table default.student to '/user/hive/warehouse/export/student1';
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ