您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
创建数据库
create database if not exists sopdm
comment 'this is test database'
with dbproperties('creator'='gxw','date'='2014-11-12')
--数据库键值对属性信息
location '/my/preferred/directory';
显示所有表
show tables ;
显示表的描述信息
desc [extended,formatted] tablename;
显示建表语句
show create table tablename;
删除表
drop table tablename;
由一个表创建另一个表,相当于复制,表结构复制,数据没复制
create table test3 like test2;
由其他表查询创建表
create table test4 as select name,addr from test5;
stored as textfile
可以直接查看
stored as sequencefile
必须用hadoop fs -text查看
stored as rcfile
hive -service rcfilecat path 查看
stored as inputformat 'class'(自定义的)
加载jar包
shell窗口add jar path(作用范围本shell)
加载到分布式缓存中供各个节点使用
或者直接拷贝到hive安装目录下的lib目录
SerDe(hive使用SerDe读、写表的行)
读写顺序:
HDFS文件-->InputFileFormat--> <key,value>-->Deserializer-->Row对象(供hive使用)
Row对象-->Serializer--> <key,value>-->OutputFileFormat-->HDFS文件
hive自带RegexSerDe.class 正则表达式匹配每一行的数据
create table apachelog(
host STRING,
identity STRING,
user STRING,
time STRING,
request STRING,
status STRING,
size STRING,
refer STRING,
agent STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex="([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) ([0-9]*) ([0-9]*) ([^ ]*) ([^ ]*)"
) stored AS TEXTFILE;
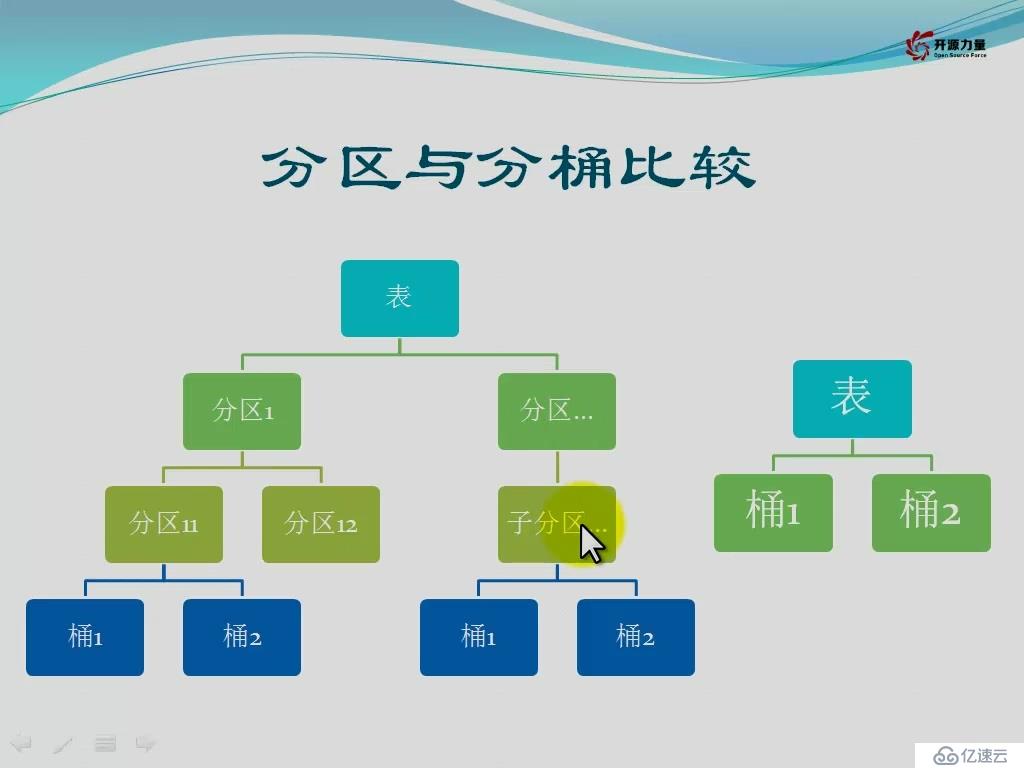
分区表(相当于表的子目录)
create table tablename (name string) partitioned by (key type,...)
create external table employees(
name string,
salary float,
subordinates array<string>,
deductions map<string,float>,
address struct<street:string,city:string,state:string,zip:int)
)
partitioned by (dt string,type string)
row format delimited fields terminated by '\t'
collection items terminated by ','
map keys terminated by ':'
lines terminated by '\n'
stored as textfile
location '/data';
数据格式:
wang 123 a1,a2,a3 k1:1,k2:2,k3:3 s1,s2,s3,4
查看分区:
show partitions employees
增加分区
alter table employees add if not exists partition(country='xxx'[,state='yyy'])
删除分区
alter table employees drop if exists partition(country='xxx'[,state='yyy'])
动态分区:
1.不需要为不同的分区添加不同的插入语句
2.分区不确定,需要从数据中获取
参数:(动态分区前两个必须开启)
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrick;
//无限制模式,如果是strict,则必须有一个静态分区,且放在最前面
set hive.exec.max.dynamic.partitions.pernode=10000;
//每个节点生成动态分区的最大个数
set hive.exec.max.dynamic.partitions=100000;
//每次sql查询生成动态分区的最大个数
set hive.exec.max.created.files=150000;
//一个任务最多可以创建的文件数目
set dfs.datanode.max.xcievers=8182;
//限定一次最多打开的文件数
1. 创建分区表
create table d_part (
name string
)
partitioned by (value string)
row format delimited fields terminated by '\t'
lines terminated by '\n'
stored as textfile;
2. 插入动态分区
insert overwrite table d_part partition(value)
select name,addr as value
from testtext;
分桶
set hive.enforce.bucketing=true;
按id分桶
create table bucketed_user
(id string,
name string)
clustered by (id) sorted by(name) into 4 buckets
row format delimited fields terminated by '\t'
lines terminated by '\n'
stored as textfile;
分桶抽样
select * from bucketed_user tablesample(bucket 1 out of 2 on id )
取一半的桶
优化
set hive.optimize.bucketmapjoin=true;
set hive.optimize.bucketmapjoin.sortedmerge=true;
set hive.input.format=org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
beeline底层使用的jdbc,命令行使用jdbc(可以远程访问)
hive -help
hive --help
hive --service -help
查询结果写到文件
hive -V -e "select name from testtext" > /home/data/result
hive命令行输入list jar
显示当前分布式缓存有哪些jar包也就是add jar命令加载的jar包)
命令行执行hql文件(类似于hive -f),常用于设置初始化参数
source /home/data/hql/select_hql
配置变量
set val='';
hql使用hive变量
${hiveconf:val}
select * from testtext where name ='${hiveconf:val}';
env查看linux环境变量
HOME=/root
hql使用linux环境变量
select '${env:HOME}' from testtext;
1.内表数据加载(overwrite和into不能同时存在,只能存在一个)
(1) 创建表时加载
create table newtable as select col1,col2 from oldtable;
(2)创建表时指定数据位置(对location下的数据具有拥有权,删除内表时也会删除数据)
create table tablename() location '';
(3)本地数据加载
load data local inpath 'localpath' [overwrite] into table tablename;
(4)加载hdfs数据(移动数据,原来的数据移动到表的位置下)
load data inpath 'hdfspath' [overwrite] into table tablename;
hive命令行执行linux shell命令在前面加个!
!ls /home/data
(5)通过查询语句加载数据
insert into table test_m select name,addr from testtext where name ='wer';
或者
from testtext insert into table test_m select name,addr where name ='wer';
或者
select name,addr from testtext where name ='wer' insert into table test_m ;
2.外部表数据加载
(1)创建表时指定数据位置
create external table tablename() location '';
(2)查询插入,同内表
(3)使用hadoop命令拷贝数据到指定位置(hive的shell中执行和linux的shell执行)
3.分区表数据加载
(1)内部分区表数据加载类似于内表
(2)外部分区表数据加载方式类似于外表
注意:数据存放的路径层次要和表的分区一致,并且表要增加相应分区才能查到数据
load data local inpath 'localpath' [overwrite] into table tablename partition(dt='20140905');
4.数据类型对应问题
Load数据,字段类型不能相互转化时,查询返回NULL;
select查询输入,字段类型不能相互转化时,插入数据为NULL(文件保存是 \N);
select查询输入数据,字段名称可不一致,数据加载不做检查,查询时检查
数据导出
导出到本地,默认分隔符^A
insert overwrite local directory '/home/data3'
row format delimited fields terminated by '\t'
select name,addr from testtext;
导出到hdfs,不支持row format delimited fields terminated by '\t',只能采用默认分隔符是I
insert overwrite directory '/home/data3'
select name,addr from testtext;
表属性操作
1.修改表名
alter table table_name rename to new_table_name;
2.修改列名
alter table tablename change column c1 c2 int comment 'xxx' after severity;
c1旧列,c2新列,int代表新列数据类型
after severity;可以把该列放到指定列的后面,或者使用'first'放到第一位
3.增加列(默认新增列放到最末尾)
alter table tablename add column (c1 string comment 'xxxx',c2 string comment 'yyyy');
4.修改tblproperties
alter table test set tblproperties('comment'='xxxx');
5.修改分隔符(分区表比较特殊)
方式一
alter table city set serdeproperties('field.delim'='\t');(对分区表原始数据无效,对新加分区有效)
方式二 对分区表原始数据也使用最新的分隔符
alter table city partitin(dt='20140908') set serdeproperties('field.delim'='\t');
6.修改location
alter table city [partition(...)] set location 'hdfs://master:9000/location' ;
7.内部表和外部表转换
alter table test set tblproperties('EXTERNAL'='TRUE');内部表转外部表
alter table test set tblproperties('EXTERNAL'='FALSE');外部表转内部表
聚合操作
1.count计数
count(*)所有的字段不全为null,全为null不加1
count(1)不管记录是啥,只要有这条记录都加1
count(col)列不为空加1
2.sum求和
sum(可转成数字的值) 返回bigint
sum(col)+cast(1 as bigint)
3.avg
avg(可转成数字的值) 返回double
where条件在map端执行
group by是在reduce端执行 分组的列组合为key
having字句聚合操作之后执行判断,也是在reduce端执行
groupby数据倾斜优化
hive.groupby.skewindata=true;(多起一个job)
join操作(普通join不支持不等值链接)
优化参数set hive.optimize.skewjoin=true;
样例
select m.col as col,m.col2 as col2,n.col3 as col3
from
(select col,col2
from test
where ...(map端执行)
) m
[left outer|right outer|left semi] join
n (右表)
on m.col=n.col
where condition (reduce端执行)
LEFT SEMI JOIN 是 IN/EXISTS 子查询的一种更高效的实现
Hive 当前没有实现 IN/EXISTS 子查询,所以你可以用 LEFT SEMI JOIN 重写你的子查询语句。LEFT SEMI JOIN 的限制是, JOIN 子句中右边的表只能在
ON 子句中设置过滤条件,在 WHERE 子句、SELECT 子句或其他地方过滤都不行。
SELECT a.key, a.value
FROM a
WHERE a.key in
(SELECT b.key
FROM b);
可以被重写为:
SELECT a.key, a.val
FROM a LEFT SEMI JOIN b on (a.key = b.key)
order by全局排序,只有一个reduce
distribute by col分散数据,按col分散到不同的reduce
和sort by结合保证每个reduce输出是有序的
union all(不去重)和union(去重)
hive只支持union all,子查询不允许起别名
select col from
(select a as col from t1
union all
select b as col from t2
) tmp;
要求:
1.字段名字一样
2.字段类型一样
3.字段个数一样
4.子表不能有别名
5.如果需要从合并之后的表中查询数据,那么合并之后的表必须要有别名
hive创建索引表
hive> create index user_index on table user(id) > as 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler' > with deferred rebuild > IN TABLE user_index_table; hive> alter index user_index on user rebuild; hive> select * from user_index_table limit 5;
直接用hadoop命令复制删除hive存储数据后,需要add partition或alter来同步源数据信息,否则drop表等操作时会查询元数据metastore,查到metastore信息和hdfs信息不一致,会报错。这个也可算是hive的bug,尚未修复,但也可以理解为初衷不建议直接操作hdfs数据。
目前,可以采用命令:
MSCK REPAIR TABLE table_name;
该命令会把没添加进partition的数据,都增加对应的partition。同步源数据信息metadata。
Recover Partitions
Hive在metastore中存储每个表的分区列表,如果新的分区加入HDFS后,metastore不会注意这些分区,除非
ALTER TABLE table_name ADD PARTITION
当然可以通过
MSCK REPAIR TABLE table_name;
类似EMR版本中的如下命令
ALTER TABLE table_name RECOVER PARTITIONS;
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。