您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
大数据:海量数据
结构化数据:即行数据,能够存储在二维表中的数据
非结构化数据:无法使用数据的二维逻辑表示数据。如word,ppt,图片
半结构化数据:在结构化与非结构化之间,自我描述,将结构与数据本身存储在一起的数据:xml、json、html
goole的论文:MapReduce:Simplified Date Processing On Large Clusters
Dynam
Map:把大数据映射为分割的多个节点处理的小数据
Reduce:折叠
i1,i2 ==> o1,i3 ==>o2,i4==>o4
MapReduce:将大数据中映射为键值对
数据的搜集,监控,分析,处理
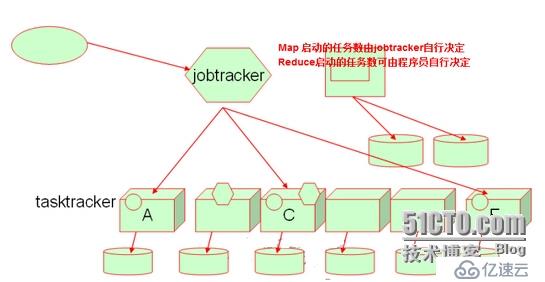
hadoop: jobtracker、tasktracker,namenode,datanode
hadoop的的特性:
(1)向外扩展
(2)数据冗余
(3)将程序移向数据
(4)顺序处理数据,避免随机访问
(5)向程序员隐藏系统级别的细节
(6)平滑扩展
如何将大数据切割为多个可处理的小数据,如何将处理的结果合并
如何选择将任务移向多个不同的小数据所在的主机处理任务
如何获取被分割的小数据
如何保证个Map进程如何同步
Map如何将处理的结果传输给Reduce
如何在出现软件故障或硬件故障后保证任务的完整性
mapreduce:
1.编程框架:API
2.运行平台
3.具体实现
hadoop:HDFS-->MapReduce(API,Java)
HDFS:
HDFS分布式集群 数据存储
1)HDFS
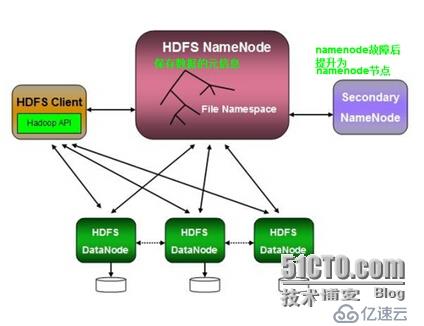
2)向HDFS分文件系统保存数据存储

MapReduce集群 数据处理 大文件
HBase,运行在HDFS之上 由zookeeper协调工作
Hadoop DataBase
通过zookeeper使hadoop能够存储单个小文件,实现随机存储
colum:列式存储
存储松散型数据,基于键值对的列式存储
将单个小文件合并为大文件
bigtable:大表
ETL
数据的抽取、转换、加载
日志搜集:
flume
scrible
chukwa
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。