жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒдёәеӨ§е®¶еұ•зӨәдәҶвҖңhadoopдёӯmapеҰӮдҪ•иҫ“еҮәвҖқпјҢеҶ…е®№з®ҖиҖҢжҳ“жҮӮпјҢжқЎзҗҶжё…жҷ°пјҢеёҢжңӣиғҪеӨҹеё®еҠ©еӨ§е®¶и§ЈеҶіз–‘жғ‘пјҢдёӢйқўи®©е°Ҹзј–еёҰйўҶеӨ§е®¶дёҖиө·з ”究并еӯҰд№ дёҖдёӢвҖңhadoopдёӯmapеҰӮдҪ•иҫ“еҮәвҖқиҝҷзҜҮж–Үз« еҗ§гҖӮ
Mapper зҡ„иҫ“е…Ҙе®ҳж–№ж–ҮжЎЈеҰӮдёӢ
The Mapper outputs are sorted and then partitioned per Reducer. The total number of partitions is the same as the number of reduce tasks for the job. Users can control which keys (and hence records) go to which Reducer by implementing a custom Partitioner.
mapperзҡ„иҫ“еҮәжҳҜе·Із»ҸжҺ’еәҸ并且й’ҲеҜ№жҜҸдёӘreducerеҲ’еҲҶејҖзҡ„пјҢйӮЈд№Ҳhadoopд»Јз ҒжҳҜеҰӮдҪ•еҲ’еҲҶзҡ„пјҢиҝҷйҮҢе°Ҷи·ҹд»Һд»Јз ҒеҲҶжһҗгҖӮ
иҝҳжҳҜж №жҚ®е®ҳж–№зӨәдҫӢWordCountзҡ„зӨәдҫӢ
第дёҖж¬ЎеҲҶжһҗдёәдәҶз®ҖеҢ–mapзҡ„иҫ“еҮәеӨҚжқӮжғ…еҶөпјҢ
еҸӘеҲҶжһҗдёҖдёӘж–ҮжЎЈпјҢ并且其дёӯеҸӘжңү10дёӘ'еҚ•иҜҚ'пјҢеҲҶеҲ«дёәвҖңJ", .."c", "b", "a" ( иҝҷйҮҢ10дёӘеӯ—жҜҚжңҖеҘҪжҳҜд№ұеәҸзҡ„пјҢеҗҺйқўдјҡзңӢеҲ°е…¶жҺ’еәҸ)пјҢ
жіЁйҮҠжҺүи®ҫзҪ®combine classзҡ„д»Јз ҒгҖӮ
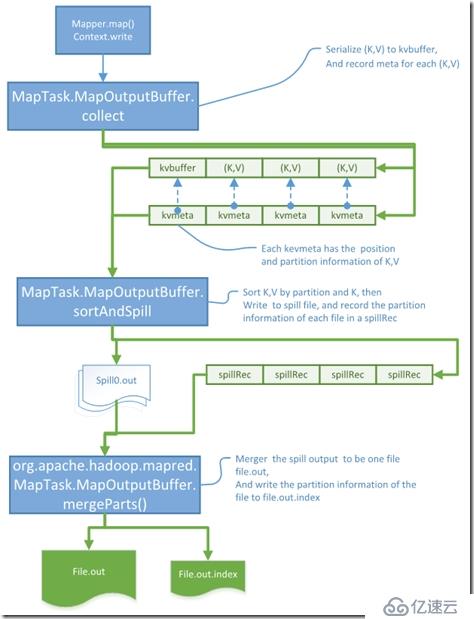
еҸҜд»ҘиҝҪиёӘеҲ°жңҖз»Ҳе®һйҷ…жҳҜз”ұorg.apache.hadoop.mapred.MapTask.MapOutputBuffer.collect(K, V, intпјү
иҝҷйҮҢеӣ дёәжҲ‘们зҡ„output еҸӘжңү10дёӘRecord дё”жҜҸдёӘеӨ§е°ҸйғҪжҜ”иҫғе°ҸпјҢжүҖд»Ҙи·іиҝҮдәҶspillдәҶеӨ„зҗҶд»ҘеҸҠcombineеӨ„зҗҶпјҢдё»иҰҒд»Јз ҒеҰӮдёӢпјҢ
public synchronized void collect(K key, V value, final int partition ) throws IOException {
{
...
keySerializer.serialize(key);
...
valSerializer.serialize(value);
.... kvmeta.put(kvindex + PARTITION, partition); kvmeta.put(kvindex + KEYSTART, keystart);
kvmeta.put(kvindex + VALSTART, valstart);
kvmeta.put(kvindex + VALLEN, distanceTo(valstart, valend)); ...
}
иҝҷйҮҢе®һйҷ…жҳҜе°ҶпјҲK,Vпјү еәҸеҲ—еҢ–еҲ°дәҶbyteж•°з»„org.apache.hadoop.mapred.MapTask.MapOutputBuffer.kvbuffer дёӯпјҢ
并е°ҶпјҲK,VпјүеңЁеҶ…еӯҳдёӯзҡ„дҪҚзҪ®дҝЎжҒҜ д»ҘеҸҠ е…¶partition(зӣёеҗҢpartitionзҡ„recordз”ұеҗҢдёҖдёӘreducerеӨ„зҗҶ) ж¶ҲжҒҜ еӯҳеңЁ kvmeta дёӯ.
еҲ°жӯӨmapзҡ„иҫ“еҮәйғҪеӯҳеңЁдәҶеҶ…еӯҳдёӯ
еҸҜд»ҘжүҫеҲ°еңЁ org.apache.hadoop.mapred.MapTask.MapOutputBuffer.sortAndSpill() дёӯжүҫеҲ°жңүдҪҝз”ЁпјҢи®ҫзҪ®ж–ӯзӮ№пјҢзңӢеҲ°еҰӮдёӢпјҢ
private void sortAndSpill() throws IOException, ClassNotFoundException, InterruptedException { ...
sorter.sort(MapOutputBuffer.this, mstart, mend, reporter);
...
for (int i = 0; i < partitions; ++i) {
...
if (combinerRunner == null) {
// spill directly DataInputBuffer key = new DataInputBuffer();
while (spindex < mend &&
kvmeta.get(offsetFor(spindex % maxRec) + PARTITION) == i) {
....
writer.append(key, value);
++spindex;
}
} ...
spillRec.putIndex(rec, i);
}
...
indexCacheList.add(spillRec);
...}
иҝҷйҮҢжңүдёүдёӘж“ҚдҪңпјҢ
1. Sorter.sort пјҡжҳҜд»Ҙpartition е’Ңkey жқҘжҺ’еәҸзҡ„,зӣ®зҡ„жҳҜиҒҡеҗҲзӣёеҗҢpartitionзҡ„record, 并д»Ҙkeyзҡ„йЎәеәҸжҺ’еҲ—гҖӮ
2. writer.append : е°ҶеәҸеҲ—еҢ–зҡ„record еҶҷе…Ҙиҫ“еҮәжөҒпјҢиҝҷйҮҢеҶҷе…ҘеҲ°ж–Ү件spill0.out
3. indexCacheList.add : жҜҸдёӘspillRecи®°еҪ•жҹҗдёӘspill outж–Ү件дёӯеҢ…еҗ«зҡ„partitionдҝЎжҒҜгҖӮ
еңЁжӯӨи®ҫзҪ®ж–ӯзӮ№пјҢеҸҜд»ҘзңӢеҲ°иҝҷйҮҢжҲ‘们еҸӘжңүдёҖдёӘspillж–Ү件пјҢдёҚйңҖиҰҒmergeпјҢ
иҝҷйҮҢеҸӘжҳҜе”ҜдёҖзҡ„spillRec еҶҷе…ҘеҲ°еҲ°ж–Ү件дёӯ, file.out.index
е°Ҷspill0.out йҮҚе‘ҪеҗҚдёәfile.outпјҢ еҸҜд»Ҙvimжү“ејҖиҝҷдёӘж–Ү件зңӢеҲ°йҮҢйқўеӯҳеңЁйЎәеәҸеҸ·зҡ„еӯ—з¬ҰгҖӮ
private void mergeParts() throws IOException, InterruptedException, ClassNotFoundException {
...
sameVolRename(filename[0],
mapOutputFile.getOutputFileForWriteInVolume(filename[0]));...
indexCacheList.get(0).writeToFile(
mapOutputFile.getOutputIndexFileForWriteInVolume(filename[0]), job);
...}
жҖ»з»“еҰӮдёӢпјҡ
1. mapзҡ„иҫ“еҮәйҰ–е…ҲеәҸеҲ—еҢ–еҲ°еҶ…еӯҳдёӯkvbufferпјҢkvmeta
2. sortAndSpill дјҡе°ҶеҶ…еӯҳдёӯзҡ„recordеҶҷе…ҘеҲ°ж–Ү件дёӯ
3. mergeе°ҶspillеҮәзҡ„ж–Ү件mergeй—®дёҖдёӘж–Ү件file.outпјҢ并е°ҶжҜҸдёӘж–Ү件дёӯpartitionзҡ„дҝЎжҒҜеҶҷе…Ҙfile.out.index
иҝҳжІЎеҲҶжһҗзҡ„жғ…еҶөпјҡ
map иҫ“еҮәеӨ§йҮҸж•°жҚ®пјҢеҮәзҺ°еӨҡдёӘspill ж–Ү件зҡ„еӨҚжқӮжғ…еҶөзҡ„з»ҶиҠӮпјҲ1. ејӮжӯҘspillпјҢ 2. merge еӨҡдёӘж–Ү件пјү
д»ҘдёҠжҳҜвҖңhadoopдёӯmapеҰӮдҪ•иҫ“еҮәвҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒзӣёдҝЎеӨ§е®¶йғҪжңүдәҶдёҖе®ҡзҡ„дәҶи§ЈпјҢеёҢжңӣеҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүжүҖеё®еҠ©пјҢеҰӮжһңиҝҳжғіеӯҰд№ жӣҙеӨҡзҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ