您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
最近有个SQL运行时长超过两个小时,所以准备优化下
首先查看hive sql 产生job的counter数据发现
总的CPU time spent 过高估计100.4319973小时
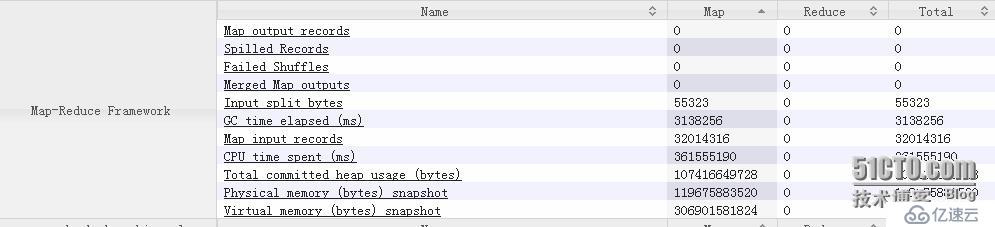
每个map的CPU time spent

排第一的耗了2.0540889小时
建议设置如下参数:
1、mapreduce.input.fileinputformat.split.maxsize现在是256000000 往下调增加map数(此招立竿见影,我设为32000000产生了500+的map,最后任务由原先的2小时提速到47分钟就完成)
2、优化UDF getPageID getSiteId getPageValue (这几个方法用了很多正则表达式的文本匹配)
2.1 正则表达式处理优化可以参考
http://www.fasterj.com/articles/regex1.shtml
http://www.fasterj.com/articles/regex2.shtml
2.2 UDF优化见
1 Also you should use class level privatete members to save on object
incantation and garbage collection.
2 You also get benefits by matching the args with what you would normally
expect from upstream. Hive converts text to string when needed, but if the
data normally coming into the method is text you could try and match the
argument and see if it is any faster.
Exapmle:
优化前:
>>>> import org.apache.hadoop.hive.ql.exec.UDF;
>>>> import java.net.URLDecoder;
>>>>
>>>> public final class urldecode extends UDF {
>>>>
>>>> public String evaluate(final String s) {
>>>> if (s == null) { return null; }
>>>> return getString(s);
>>>> }
>>>>
>>>> public static String getString(String s) {
>>>> String a;
>>>> try {
>>>> a = URLDecoder.decode(s);
>>>> } catch ( Exception e) {
>>>> a = "";
>>>> }
>>>> return a;
>>>> }
>>>>
>>>> public static void main(String args[]) {
>>>> String t = "%E5%A4%AA%E5%8E%9F-%E4%B8%89%E4%BA%9A";
>>>> System.out.println( getString(t) );
>>>> }
>>>> }优化后:
import java.net.URLDecoder;
public final class urldecode extends UDF {
private Text t = new Text();
public Text evaluate(Text s) {
if (s == null) { return null; }
try {
t.set( URLDecoder.decode( s.toString(), "UTF-8" ));
return t;
} catch ( Exception e) {
return null;
}
}
//public static void main(String args[]) {
//String t = "%E5%A4%AA%E5%8E%9F-%E4%B8%89%E4%BA%9A";
//System.out.println( getString(t) );
//}
}3 继承实现GenericUDF
3、如果是Hive 0.14 + 可以开启hive.cache.expr.evaluation UDF Cache功能
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。