您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
非延续分派许可一个程序疏散地装入到不相邻的内存分区中,依据分区的巨细能否固定分为分页存储治理方法和分段存储治理方法。
分页存储治理方法中,又依据运转功课时能否要把功课的一切页面都装入内存才干运转分为根本分页存储治理方法和恳求分页存储治理方法。下面引见根本分页存储治理方法。
固定分区会发生外部碎片,静态分区会发生内部碎片,这两种技巧对内存的应用率都比拟低。我们愿望内存的运用能尽量防止碎片的发生,这就引入了分页的思惟:把主存空间划分为巨细相等且固定的块,块绝对较小,作为主存的根本单元。每一个过程也以块为单元停止划分,过程在履行时,以块为单元逐一请求主存中的块空间。
分页的办法从方式上看,像分区相等的固定分区技巧,分页治理不会发生内部碎片。但它又有实质的分歧点:块的巨细绝对分区要小许多,并且过程也依照块停止划分,过程运转时按块请求主存可用空间并履行。如许,过程只会在为最初一个不完好的块请求一个主存块空间时,才发生主存碎片,所以虽然会发生外部碎片,然则这种碎片绝对于过程来说也是很小的,每一个过程均匀只发生半个块巨细的外部碎片(也称页内碎片)。
①页面和页面巨细。过程中的块称为页(Page),内存中的块称为页框(Page Frame,或页帧)。外存也以异样的单元停止划分,直接称为块(Block)。过程在履行时需求请求主存空间,就是要为每一个页面分派主存中的可用页框,这就发生了页和页框的逐个对应。
为便利地址转换,页面巨细应是2的整数幂。同时页面巨细应当适中,假如页面太小,会使过程的页面数过多,如许页表就过长,占用少量内存,并且也会添加硬件地址转换的开支,下降页面换入/换出的效力;页面过大又会使页内碎片增大,下降内存的应用率。所以页面的巨细应当适中,思索到耷间效力和工夫效力的衡量。
②地址构造。分页存储治理的逻辑地址构造如图3-7所示。
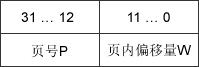
图3-7 分页存储治理的地址构造
地址构造包括两局部:前一局部为页号P,后一局部为页内偏移量W。地址长度为32 位,个中0~11位为页边疆址,即每页巨细为4KB;12~31位为页号,地址空间最多许可有220页。
③页表。为了便于在内存中找到过程的每一个页面所对应的物理块,零碎为每一个过程树立一张页表,记载页面在内存中对应的物理块号,页表普通寄存在内存中。
在设置装备摆设了页表后,过程履行时,经过查找该表,即可找到每页在内存中的物理块号。可见,页表的感化是完成从页号到物理块号的地址映射,如图3-8所示。
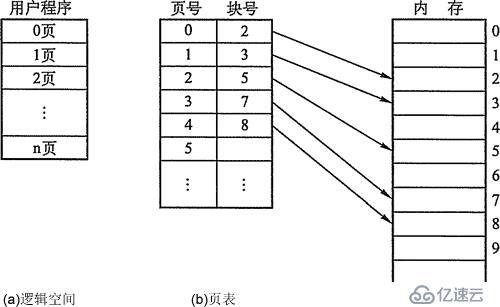
图3-8 页表的感化
地址变换机构的义务是将逻辑地址转换为内存中物理地址,地址变换是借助于页表完成的。图3-9给出了分页存储治理零碎中的地址变换机构。
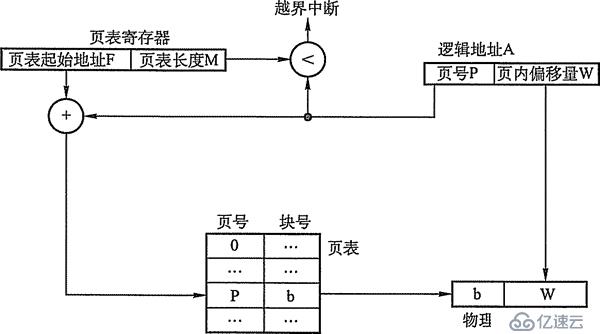
图3-9 分页存储治理的地址变换机构
在零碎中平日设置一个页表存放器(PTR),寄存页表在内存的始址F和页表长度M。过程未履行时,页表的始址和长度寄存在过程掌握块中,当过程履行时,才将页表始址和长度存入页表存放器。设页面巨细为L,逻辑地址A到物理地址E的变换进程如下:
盘算页号P(P=A/L)和页内偏移量W (W=A%L)。
比拟页号P和页表长度M,若P >= M,则发生越界中缀,不然持续履行。
页表中页号P对应的页表项地址 = 页表肇端地址F + 页号P * 页表项长度,掏出该页表项内容b,即为物理块号。
盘算E=b*L+W,用失掉的物理地址E去拜访内存。
以上全部地址变换进程均是由硬件主动完成的。
例如,若页面巨细L为1K字节,页号2对应的物理块为b=8,盘算逻辑地址A=2500 的物理地址E的进程如下:P=2500/1K=2,W=2500%1K=452,查找失掉页号2对应的物理块的块号为 8,E=8*1024+452=8644。
下面评论辩论分页治理方法存在的两个次要成绩:
每次访存操作都需求停止逻辑地址到物理地址的转换,地址转换进程必需足够快,不然访存速度会下降;
每一个过程引入了页表,用于存储映射机制,页表不克不及太大,不然内存应用率会下降。
由下面引见的地址变换进程可知,若页表全体放在内存中,则存取一个数据或一条指令至多要拜访两次内存:一次是拜访页表,肯定所存取的数据或指令的物理地址,第二次才依据该地址存取数据或指令。显然,这种办法比平日履行指令的速度慢了一半。
为此,在地址变换机构中增设了一个具有并行查找才能的高速缓冲存储器——快表,又称联想存放器(TLB),用来寄存以后拜访的若干页表项,以减速地址变换的进程。与此对应,主存中的页表也常称为慢表,配有快表的地址变换机构如图3-10所示。
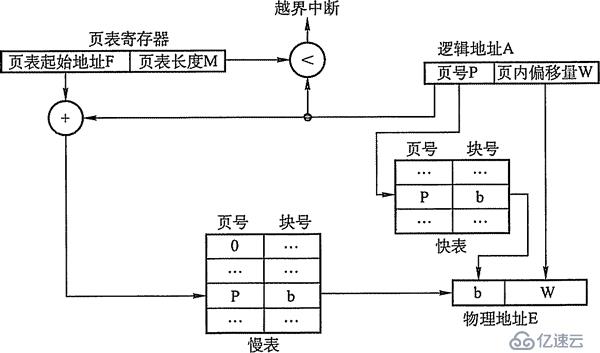
图3-10 具有快表的地址变换机构
在具有快表的分页机制中,地址的变换进程:
CPU给出逻辑地址后,由硬件停止地址转换并将页号送入高速缓存存放器,并将此页号与快表中的一切页号停止比拟。
假如找到婚配的页号,阐明所要拜访的页表项在快表中,则直接从中掏出该页对应的页框号,与页内偏移量拼接构成物理地址。如许,存取数据仅一次访存即可完成。
假如没有找到,则需求拜访主存中的页表,在读出页表项后,应同时将其存入快表,以便前面能够的再次拜访。但若快表已满,则必需依照必定的算法对旧的页表项停止交换。
留意:有些处置机设计为快表和慢表同时查找,假如在快表中查找胜利则终止慢表的查找。
普通快表的射中率可以到达90%以上,如许,分页带来的速度损掉就下降到10%以下。快表的无效性是基于有名的部分性道理,这在前面的虚拟内存中将会详细评论辩论。
第二个成绩:因为引入了分页治理,过程在履行时不需求将一切页调入内存页框中,而只需将保管有映射关系的页表调入内存中即可。然则我们依然需求思索页表的巨细。以32 位逻辑地址空间、页面巨细4KB、页表项巨细4B为例,若要完成过程对全体逻辑地址空间的映射,则每一个过程需求220,约100万个页表项。也就是说,每一个过程仅页表这一项就需求4MB主存空间,这显然是不实在际的。而即使不思索对全体逻辑地址空间停止映射的状况,一个逻辑地址空间稍大的过程,其页表巨细也能够是过大的。以一个40MB的过程为例,页表项共40KB,假如将一切页表项内容保管在内存中,那么需求10个内存页框来保管全部页表。全部过程巨细约为1万个页面,而实践履行时只需求几十个页面进入内存页框就可以运转,但假如请求10个页面巨细的页表必需全体进入内存,这绝对实践履行时的几十个过程页面的巨细来说,一定是下降了内存应用率的;从另一方面来说,这10页的页表项也并不需求同时保管在内存中,由于大多半状况下,映射所需求的页表项都在页表的统一个页面中。
将页表映射的思惟进一步延长,就可以失掉二级分页:将页表的10页空间也停止地址映射,树立上一级页表,用于存储页表的映射关系。这里对页表的10个页面停止映射只需求10个页表项,所以上一级页表只需求1页就足够(可以存储210=1024个页表项)。在过程履行时,只需求将这1页的上一级页表调入内存即可,过程的页表和过程自身的页面,可以在前面的履行中再i周入内存。
如图3-11所示,这是Intel处置器80x86系列的硬件分页的地址转换进程。在32位零碎中,全体32位逻辑地址空间可以分为220(4GB/4KB)个页面。这些页面可以再进一步树立顶级页表,需求210个顶级页表项停止索引,这正好是一页的巨细,所以树立二级页表即可。
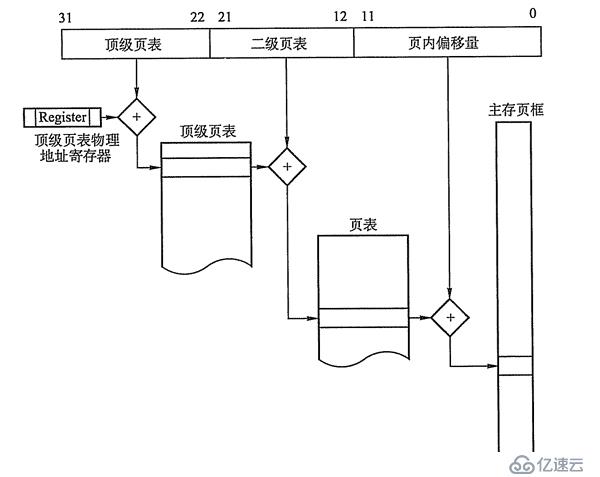
图3-11 硬件分页地址转换
举例,32位零碎中过程分页的任务进程:假定内核曾经给一个正在运转的过程分派的逻辑地址空间是0x20000000到0x2003FFFF,这个空间由64个页面构成。在过程运转时,我们不需求晓得全体这些页的页框的物理地址,很能够个中许多页还不在主存中。这里我们只留意在过程运转到某一页时,硬件是若何盘算失掉这一页的页框的物理地址即可。如今过程需求读逻辑地址0x20021406中的字节内容,这个逻辑地址按如下停止处置:
逻辑地址: 0x20021406 (0010 0000 0000 0010 0001 0100 0000 0110 B)
顶级页表字段:0x80 (00 1000 0000 B)
二级页表字段:0x21 (00 0010 0001B)
页内偏移量字段:0x406 (0100 0000 0110 B)
顶级页表字段的0x80用于选择顶级页表的第0x80表项,此表项指向和该过程的页相干的二级页表;二级页表字段0x21用于选择二级页表的第0x21表项,此表项指向包括所需页的页框;最初的页内偏移量字段0x406用于在目的页框中读取偏移量为0x406中的字节。
这是32位零碎下比拟实践的一个例子。看似较为复杂的例子,有助于比拟深化天文解,愿望读者能本人入手盘算一遍转换进程。
树立多级页表的目标在于树立索引,如许不必糜费主存空间去存储无用的页表项,也不必自觉地次序式查找页表项,而树立索引的请求是最高一级页表项不超越一页的巨细。在 64位操作零碎中,页表的划分则需求从新思索,这是许多教材和指点书中的罕见标题,然则许多都给出了毛病的剖析,需求留意。
我们假定依然釆用4KB页面巨细。偏移量字段12位,假定页表项巨细为8B。如许,其上一级分页时,每一个页框只能存储29(4KB/8B)个页表项,而不再是210个,所以上一级页表字段为9位。前面同理持续分页。64=12+9+9+9+9+9+7,所以需6级分页才干完成索引。许多书中依然按4B页表项剖析,固然异样得出6级分页的后果,但显然是毛病的。这里给出两个实践的64位操作零碎的分页级别(留意:外面没有运用全体64位寻址,不外因为地址字节对齐的设计思索,依然运用8B巨细的页表项),了解了表3-2中的分级方法,置信对多级分页就十分清晰了。
表3-2 两种零碎的分级方法
| 平台 | 页面巨细 | 寻址位数 | 分页级数 | 详细分级 |
|---|---|---|---|---|
| Alpha | 8KB | 43 | 3 | 13+10+10+10 |
| X86_64 | 4 KB | 48 | 4 | 12+9+9+9+9 |
分页治理方法是从盘算机的角度思索设计的,以进步内存的应用率,晋升盘算机的功能, 且分页经过硬件机制完成,对用户完整通明;而分段治理方法的提出则是思索了用户和程序员,以知足便利编程、信息维护和共享、静态增加及静态链接等多方面的需求。
段式治理方法依照用户过程中的天然段划分逻辑空间。例如,用户过程由主程序、两个子程序、栈和一段数据构成,于是可以把这个用户过程划分为5个段,每段从0 开端编址,并分派一段延续的地址空间(段内请求延续,段间不请求延续,因而全部功课的地址空间是二维的)。其逻辑地址由段号S与段内偏移量W两局部构成。
在图3-12中,段号为16位,段内偏移量为16位,则一个功课最多可有216=65536个段,最大段长为64KB。
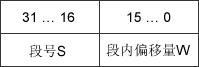
图3-12 分段零碎中的逻辑地址构造
在页式零碎中,逻辑地址的页号和页内偏移量对用户是通明的,但在段式零碎中,段号和段内偏移量必需由用户显示供给,在髙级程序设计言语中,这个任务由编译程序完成。
每一个过程都有一张逻辑空间与内存空间映射的段表,个中每个段表项对应过程的一个段,段表项记载该段在内存中的肇端地址和段的长度。段表的内容如图3-13所示。

图3-13 段表项
在设置装备摆设了段表后,履行中的过程可经过查找段表,找到每一个段所对应的内存区。可见,段表用于完成从逻辑段到物理内存区的映射,如图3-14所示。
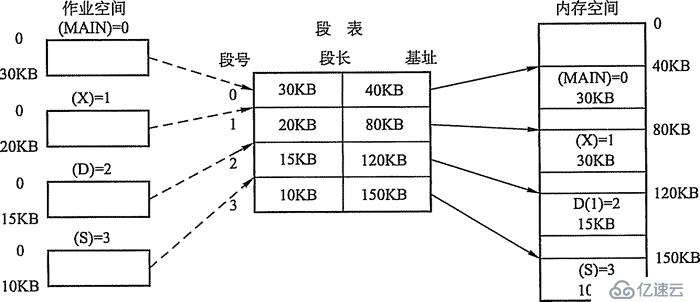
图3-14 应用段表完成地址映射
分段零碎的地址变换进程如图3-15所示。为了完成过程从逻辑地址到物理地址的变换功用,在零碎中设置了段表存放器,用于寄存段表始址F和段表长度M。其从逻辑地址A到物理地址E之间的地址变换进程如下:
从逻辑地址A中掏出前几位为段号S,后几位为段内偏移量W。
比拟段号S和段表长度M,若S多M,则发生越界中缀,不然持续履行。
段表中段号S对应的段表项地址 = 段表肇端地址F + 段号S * 段表项长度,掏出该段表项的前几位失掉段长C。若段内偏移量>=C,则发生越界中缀,不然持续履行。
掏出段表项中该段的肇端地址b,盘算 E = b + W,用失掉的物理地址E去拜访内存。

图3-15 分段零碎的地址变换进程
在分段零碎中,段的共享是经过两个功课的段表中响应表项指向被共享的段的统一个物理正本来完成的。当一个功课正从共享段中读取数据时,必需避免另一个功课修正此共享段中的数据。不克不及修正的代码称为纯代码或可重入代码(它不属于临界资本),如许的代码和不克不及修正的数据是可以共享的,而可修正的代码和数据则不克不及共享。
与分页治理相似,分段治理的维护办法次要有两种:一种是存取掌握维护,另一种是地址越界维护。地址越界维护是应用段表存放器中的段表长度与逻辑地址中的段号比拟,若段号大于段表长度则发生越界中缀;再应用段表项中的段长和逻辑地址中的段内位移停止比拟,若段内位移大于段长,也会发生越界中缀。
页式存储治理能无效地进步内存应用率,而分段存储治理能反应程序的逻辑构造并有利于段的共享。假如将这两种存储治理办法联合起来,就构成了段页式存储治理方法。
在段页式零碎中,功课的地址空间起首被分红若干个逻辑段,每段都有本人的段号,然后再将每一段分红若干个巨细固定的页。对内存空间的治理依然和分页存储治理一样,将其分红若干个和页面巨细相反的存储块,对内存的分派以存储块为单元,如图3-16所示。
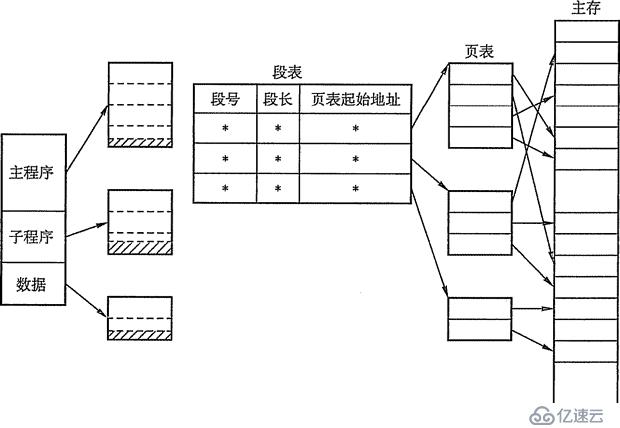
图3-16 段页式治理方法
在段页式零碎中,功课的逻辑地址分为三局部:段号、页号和页内偏移量,如图3-17 所示。

图3-17 段页式零碎的逻辑地址构造
为了完成地址变换,零碎为每一个过程树立一张段表,而每一个分段有一张页表。段表表项中至多包含段号、页表长度和页表肇端地址,页表表项中至多包含页号和块号。此外,零碎中还应有一个段表存放器,指出功课的段表肇端地址和段表长度。
留意:在一个过程中,段表只要一个,而页表能够有多个。
在停止地址变换时,起首经过段表查到页表肇端地址,然后经过页表找到页帧号,最初构成物理地址。如图3-18所示,停止一次拜访实践需求三次拜访主存,这里异样可以运用快表以放慢查找速度,其症结字由段号、页号构成,值是对应的页帧号和维护码。
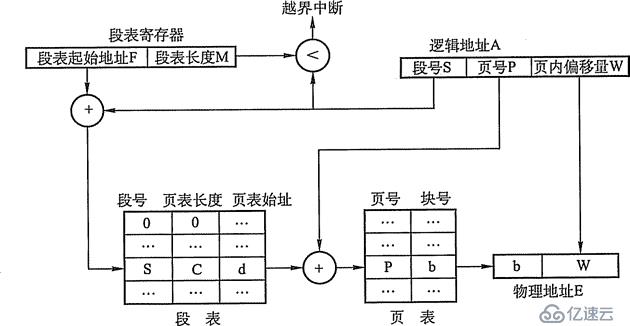
图3-18 段页式零碎的地址变换机构
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。