жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮеҶ…е®№дё»иҰҒи®Іи§ЈвҖңwebе®№еҷЁжҳҜжҖҺд№Ҳи§ЈжһҗhttpжҠҘж–Үзҡ„вҖқпјҢж„ҹе…ҙи¶Јзҡ„жңӢеҸӢдёҚеҰЁжқҘзңӢзңӢгҖӮжң¬ж–Үд»Ӣз»Қзҡ„ж–№жі•ж“ҚдҪңз®ҖеҚ•еҝ«жҚ·пјҢе®һз”ЁжҖ§ејәгҖӮдёӢйқўе°ұи®©е°Ҹзј–жқҘеёҰеӨ§е®¶еӯҰд№ вҖңwebе®№еҷЁжҳҜжҖҺд№Ҳи§ЈжһҗhttpжҠҘж–Үзҡ„вҖқеҗ§!
httpжҠҘж–Үе…¶е®һе°ұжҳҜдёҖе®ҡ规еҲҷзҡ„еӯ—з¬ҰдёІпјҢйӮЈд№Ҳи§Јжһҗе®ғ们пјҢе°ұжҳҜи§Јжһҗеӯ—з¬ҰдёІпјҢзңӢзңӢжҳҜеҗҰж»Ўи¶іhttpеҚҸи®®зәҰе®ҡзҡ„规еҲҷгҖӮ
start-line: иө·е§ӢиЎҢ,жҸҸиҝ°иҜ·жұӮжҲ–е“Қеә”зҡ„еҹәжң¬дҝЎжҒҜ *( header-field CRLF ): еӨҙ CRLF [message-body]: ж¶ҲжҒҜbodyпјҢе®һйҷ…дј иҫ“зҡ„ж•°жҚ®
д»ҘдёӢд»Јз ҒйғҪжҳҜjetty9.4.12зүҲжң¬
еҰӮдҪ•и§Јжһҗиҝҷд№Ҳй•ҝзҡ„еӯ—з¬ҰдёІе‘ўпјҢjettyжҳҜйҖҡиҝҮзҠ¶жҖҒжңәжқҘе®һзҺ°зҡ„гҖӮе…·дҪ“еҸҜд»ҘзңӢдёӢorg.eclipse.jetty.http.HttpParseзұ»
public enum State
{
START,
METHOD,
,
SPACE1,
STATUS,
URI,
SPACE2,
REQUEST_VERSION,
REASON,
PROXY,
HEADER,
CONTENT,
EOF_CONTENT,
CHUNKED_CONTENT,
CHUNK_SIZE,
CHUNK_PARAMS,
CHUNK,
TRAILER,
END,
CLOSE, // The associated stream/endpoint should be closed
CLOSED // The associated stream/endpoint is at EOF
}жҖ»е…ұеҲҶжҲҗдәҶ21з§ҚзҠ¶жҖҒпјҢ然еҗҺиҝӣиЎҢзҠ¶жҖҒй—ҙзҡ„жөҒиҪ¬гҖӮеңЁparseNextж–№жі•дёӯеҲҶеҲ«еҜ№иө·е§ӢиЎҢ -> header -> body contentеҲҶеҲ«и§Јжһҗ
public boolean parseNext(ByteBuffer buffer)
{
try
{
// Start a request/response
if (_state==State.START)
{
// еҝ«йҖҹеҲӨж–ӯ
if (quickStart(buffer))
return true;
}
// Request/response line иҪ¬жҚў
if (_state.ordinal()>= State.START.ordinal() && _state.ordinal()<State.HEADER.ordinal())
{
if (parseLine(buffer))
return true;
}
// headersиҪ¬жҚў
if (_state== State.HEADER)
{
if (parseFields(buffer))
return true;
}
// contentиҪ¬жҚў
if (_state.ordinal()>= State.CONTENT.ordinal() && _state.ordinal()<State.TRAILER.ordinal())
{
// Handle HEAD response
if (_responseStatus>0 && _headResponse)
{
setState(State.END);
return handleContentMessage();
}
else
{
if (parseContent(buffer))
return true;
}
}
return false;
}ж•ҙдҪ“жңүдёүжқЎи·Ҝеҫ„
ејҖе§Ӣ -> start-line -> header -> з»“жқҹ
ејҖе§Ӣ -> start-line -> header -> content -> з»“жқҹ
ејҖе§Ӣ -> start-line -> header -> chunk-content -> з»“жқҹ
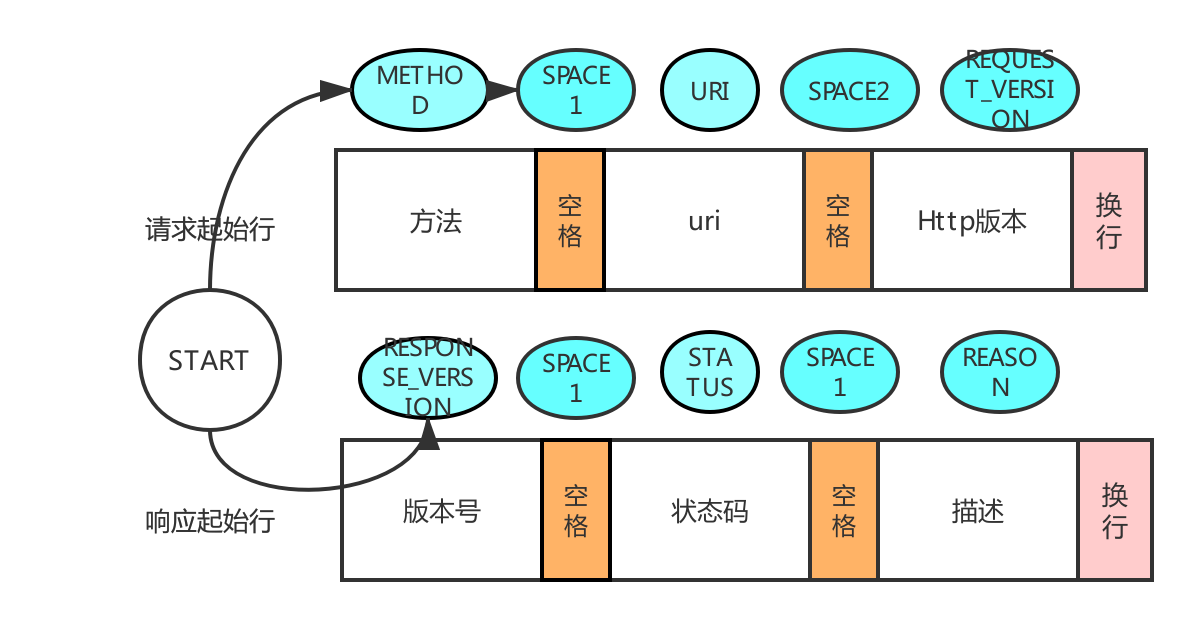
start-line = request-line(иҜ·жұӮиө·е§ӢиЎҢпјү/пјҲе“Қеә”иө·е§ӢиЎҢпјүstatus-line
иҜ·жұӮжҠҘж–Үи§ЈжһҗзҠ¶жҖҒиҝҒ移
иҜ·жұӮиЎҢпјҡSTART -> METHOD -> SPACE1 -> URI -> SPACE2 -> REQUEST_VERSION
е“Қеә”жҠҘж–Үи§ЈжһҗзҠ¶жҖҒиҝҒ移
е“Қеә”иЎҢпјҡSTART -> RESPONSE_VERSION -> SPACE1 -> STATUS -> SPACE2 -> REASON
HEADER зҡ„зҠ¶жҖҒеҸӘжңүдёҖз§ҚдәҶпјҢеңЁjettyзҡ„иҖҒзүҲжң¬дёӯиҝҳеҢәеҲҶдәҶHEADER_IN_NAM, HEADER_VALUE, HEADER_IN_VALUEзӯүпјҢ9.4дёӯйғҪеҺ»йҷӨдәҶгҖӮдёәдәҶжҸҗй«ҳеҢ№й…Қж•ҲзҺҮпјҢjettyдҪҝз”ЁдәҶTrieж ‘еҝ«йҖҹеҢ№й…ҚheaderеӨҙгҖӮ
static
{
CACHE.put(new HttpField(HttpHeader.CONNECTION,HttpHeaderValue.CLOSE));
CACHE.put(new HttpField(HttpHeader.CONNECTION,HttpHeaderValue.KEEP_ALIVE));
// д»ҘдёӢзңҒз•ҘдәҶеҫҲеӨҡдәҶйҖҡз”ЁheaderеӨҙиҜ·жұӮдҪ“пјҡ
CONTENT -> ENDпјҢиҝҷз§ҚжҳҜжҷ®йҖҡзҡ„еёҰContent-LengthеӨҙзҡ„жҠҘж–ҮпјҢHttpParserдёҖзӣҙиҝҗиЎҢCONTENTзҠ¶жҖҒпјҢзӣҙеҲ°жңҖеҗҺContentLengthиҫҫеҲ°дәҶжҢҮе®ҡзҡ„ж•°йҮҸпјҢеҲҷиҝӣе…ҘENDзҠ¶жҖҒ
chunkedеҲҶеқ—дј иҫ“зҡ„ж•°жҚ®
CHUNKED_CONTENT -> CHUNK_SIZE -> CHUNK -> CHUNK_END -> END
undertowжҳҜеҸҰдёҖз§Қwebе®№еҷЁпјҢе®ғзҡ„еӨ„зҗҶж–№ејҸдёҺjettyжңүд»Җд№ҲдёҚеҗҢе‘ў
зҠ¶жҖҒжңәз§Қзұ»дёҚдёҖж ·дәҶпјҢio.undertow.util.HttpString.ParseState
public static final int VERB = 0; public static final int PATH = 1; public static final int PATH_PARAMETERS = 2; public static final int QUERY_PARAMETERS = 3; public static final int VERSION = 4; public static final int AFTER_VERSION = 5; public static final int HEADER = 6; public static final int HEADER_VALUE = 7; public static final int PARSE_COMPLETE = 8;
е…·дҪ“еӨ„зҗҶжөҒзЁӢеңЁHttpRequestParserжҠҪиұЎзұ»дёӯ
public void handle(ByteBuffer buffer, final ParseState currentState, final HttpServerExchange builder) throws BadRequestException {
if (currentState.state == ParseState.VERB) {
//fast path, we assume that it will parse fully so we avoid all the if statements
// еҝ«йҖҹеӨ„зҗҶGET
final int position = buffer.position();
if (buffer.remaining() > 3
&& buffer.get(position) == 'G'
&& buffer.get(position + 1) == 'E'
&& buffer.get(position + 2) == 'T'
&& buffer.get(position + 3) == ' ') {
buffer.position(position + 4);
builder.setRequestMethod(Methods.GET);
currentState.state = ParseState.PATH;
} else {
try {
handleHttpVerb(buffer, currentState, builder);
} catch (IllegalArgumentException e) {
throw new BadRequestException(e);
}
}
// еӨ„зҗҶpath
handlePath(buffer, currentState, builder);
// еӨ„зҗҶзүҲжң¬
if (failed) {
handleHttpVersion(buffer, currentState, builder);
handleAfterVersion(buffer, currentState);
}
// еӨ„зҗҶheader
while (currentState.state != ParseState.PARSE_COMPLETE && buffer.hasRemaining()) {
handleHeader(buffer, currentState, builder);
if (currentState.state == ParseState.HEADER_VALUE) {
handleHeaderValue(buffer, currentState, builder);
}
}
return;
}
handleStateful(buffer, currentState, builder);
}дёҺjettyдёҚеҗҢзҡ„жҳҜеҜ№contentзҡ„еӨ„зҗҶпјҢеңЁheaderеӨ„зҗҶе®Ңд»ҘеҗҺпјҢе°Ҷж•°жҚ®ж”ҫеҲ°io.undertow.server.HttpServerExchange,然еҗҺж №жҚ®зұ»еһӢпјҢжңүдёҚеҗҢзҡ„contentиҜ»еҸ–ж–№ејҸпјҢжҜ”еҰӮеӨ„зҗҶеӣәе®ҡй•ҝеәҰзҡ„пјҢFixedLengthStreamSourceConduitгҖӮ
еҲ°жӯӨпјҢзӣёдҝЎеӨ§е®¶еҜ№вҖңwebе®№еҷЁжҳҜжҖҺд№Ҳи§ЈжһҗhttpжҠҘж–Үзҡ„вҖқжңүдәҶжӣҙж·ұзҡ„дәҶи§ЈпјҢдёҚеҰЁжқҘе®һйҷ…ж“ҚдҪңдёҖз•Әеҗ§пјҒиҝҷйҮҢжҳҜдәҝйҖҹдә‘зҪ‘з«ҷпјҢжӣҙеӨҡзӣёе…іеҶ…е®№еҸҜд»Ҙиҝӣе…Ҙзӣёе…ійў‘йҒ“иҝӣиЎҢжҹҘиҜўпјҢе…іжіЁжҲ‘们пјҢ继з»ӯеӯҰд№ пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ