жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
еңЁеүҚеҮ еӨ©еҶҷзҡ„дёҖзҜҮж–Үеӯ—дёӯпјҢжҲ‘жҸҸиҝ°дәҶдёҖж¬ЎеӨұиҙҘзҡ„з»ҸеҺҶпјҢеҜ№дәҺеҫҲеңЁд№ҺиҝҮзЁӢзҡ„жҲ‘пјҢжҸҸиҝ°дёӢжқҘе°ұжҳҜжҲҗеҠҹгҖӮ然иҖҢпјҢжҲ‘дёҚеҫ—дёҚеӣһйҖҖеҲ°DxRпјҢз ”з©¶дёҖдёӢе®ғзҡ„жң¬иҙЁиҖҢдёҚжҳҜе…¶з®—жі•жҖқ
жғігҖӮд№ӢжүҖд»ҘеӨұиҙҘпјҢжҳҜеӣ дёәжҲ‘зҡ„йҖҶеҸҚеҝғзҗҶеңЁдҪңжҖӘпјҢжҲ‘зңҹзҡ„жІЎжңүз ”з©¶DxRзҡ„жң¬иҙЁе°ұејҖе§ӢеҠЁжүӢпјҢж— з–‘дәҺжү“дёҖеңәжҜ«ж— еҮҶеӨҮдё”еҜ№еҜ№жүӢе®Ңе…ЁдёҚдәҶи§Јзҡ„жҒ¶д»—пјҢеҰӮжһңдёҚйҖӮеҸҜиҖҢжӯўпјҢе…¶
з»“жһңеҝ…然е’ҢеҪ“еҲқжӯ»зЈ•BloomдёҖж ·жӮІжғЁпјҒ
DxR并没жңүеҸ‘жҳҺд»Җд№Ҳж–°зҡ„з®—жі•пјҢе®ғд№ӢжүҖд»Ҙй«ҳж•ҲжҳҜеӣ дёәе®ғеҲҶзҰ»дәҶи·Ҝз”ұйЎ№дёӯзҡ„и·Ҝз”ұеүҚзјҖе’ҢдёӢдёҖи·іиҝҷдёӨдёӘеҹәжң¬е…ғзҙ гҖӮеңЁиҝҷдёӘзҡ„еҹәзЎҖдёҠпјҢе®ғе°ұеҸҜд»ҘйҮҮз”Ёдёүеј иЎЁжқҘе®һзҺ°иҮӘе·ұзҡ„ж—ўй«ҳж•ҲеҸҲеҚ з”Ёз©әй—ҙе°Ҹзҡ„зӣ®зҡ„гҖӮжҲ‘жқҘжҖ»з»“дёҖдёӢпјҡ
иҝҷ
дёӘеүҚжҸҗеҸҠе…¶йҮҚиҰҒпјҒеҲҶзҰ»еүҚзјҖе’ҢдёӢдёҖи·іеҸҜд»Ҙж¶ҲйҷӨж•°жҚ®еҶ—дҪҷпјҢжһ„е»әжҹҘжүҫиЎЁзҡ„зӣ®ж Үе°ұд»Һжһ„е»әеҚ•зәҜзҡ„жҹҘжүҫеҢ№й…ҚиЎЁиҪ¬жҚўжҲҗдәҶжһ„е»әIPv4ең°еқҖзҡ„жҹҗдёҖж®өеҢәй—ҙе’ҢдёӢдёҖи·іиЎЁзҡ„жҳ е°„е…і
зі»пјҢиҝҷе°ұзӣҙжҺҘеҜјиҮҙдәҶеҢәй—ҙжҹҘжүҫгҖӮжҲ‘们жқҘзңӢдёҖдёӢеҫҲзұ»дјјзҡ„Trieж ‘жҹҘжүҫз®—жі•пјҢиҝҷдёӘз®—жі•дёӯи·Ҝз”ұеүҚзјҖе’ҢдёӢдёҖи·іжҳҜдҪңдёәдёҖдёӘвҖңи·Ҝз”ұйЎ№вҖқз»‘е®ҡеңЁдёҖиө·зҡ„пјҢеӣ жӯӨжҹҘжүҫзҡ„иҝҮзЁӢе°ұ
жҳҜдёҖдёӘзІҫзЎ®еҢ№й…Қ+еӣһжәҜзҡ„иҝҮзЁӢгҖӮиҖҢDxRз®—жі•еҲҷж¶ҲйҷӨдәҶеӣһжәҜзҡ„иҝҮзЁӢгҖӮ
иҝҷдёӘжҲ‘еҗҺйқўиҝҳдјҡиҜҙпјҢдҪҶи®°дҪҸпјҢиҝҷдёҚжҳҜж ёеҝғпјҢиҝҷеҸӘжҳҜдёҖз§Қе®һзҺ°ж–№ејҸгҖӮ
зӣҙжҺҘзҙўеј•иЎЁеҗҲ并дәҶе·ЁеӨ§зҡ„IPv4ең°еқҖеҢәй—ҙпјҢд»ҘдҫҝеҢәй—ҙиЎЁеңЁеҗҲ并еҗҺзҡ„е°‘зҡ„еӨҡзҡ„еҢәй—ҙдёӯжӣҙеҝ«йҖҹең°иҝӣиЎҢжҗңзҙўпјҢдёӨдёӘиЎЁзҡ„зӣ®зҡ„йғҪжҳҜжҢҮеҗ‘дёӢдёҖи·іиЎЁзҡ„зҙўеј•гҖӮиҝҷе°ұе»әз«ӢдәҶеҢәй—ҙеҲ°дёӢдёҖи·ізҡ„жҳ е°„гҖӮ
еҰӮ
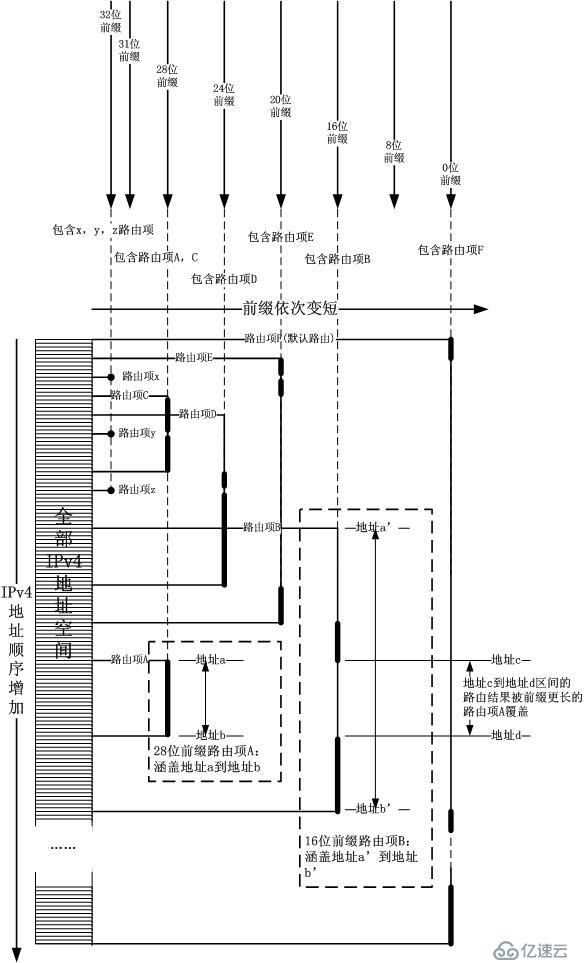
жһңеҲ°жӯӨдёәжӯўдҪ иҝҳдёҚзҹҘйҒ“DxRз®—жі•жҳҜд»Җд№ҲпјҢйӮЈд№ҹж— жүҖи°“пјҢе…¶е®һе®ғзҡ„жҖқжғіеҫҲз®ҖеҚ•гҖӮи·Ҝз”ұиЎЁзҡ„жңҖз»Ҳз»“жһңе°ұжҳҜе°ҶжҹҗдёӘиҝһз»ӯең°еқҖж®өеҜ№еә”еҲ°жҹҗдёӘдёӢдёҖи·і(дёҚе…Ғи®ёдёҚиҝһз»ӯжҺ©з Ғ
дәҶ...)пјҢеӣ жӯӨи·Ҝз”ұиЎЁе®һйҷ…дёҠжҳҜе°Ҷж•ҙдёӘIPv4ең°еқҖз©әй—ҙеҲҶеүІжҲҗдәҶиӢҘе№ІдёӘеҢәй—ҙпјҢжҜҸдёӘеҢәй—ҙеҸӘе’ҢдёҖдёӘдёӢдёҖи·іе…іиҒ”гҖӮжҲ‘жҠҠйӮЈзҜҮе…ідәҺи®°еҪ•еӨұиҙҘз»ҸеҺҶзҡ„ж–Үз« дёӯдёҖдёӘжӯЈзЎ®зҡ„еӣҫ
иҙҙеҰӮдёӢпјҡ
жӢҝ
зқҖзӣ®ж ҮIPең°еқҖеҪ“зҙўеј•пјҢеҗ‘еҸіиө°пјҢзў°еҲ°зҡ„第дёҖдёӘи·Ҝз”ұйЎ№е°ұжҳҜз»“жһңгҖӮжңҖй•ҝжҺ©з Ғзҡ„йҖ»иҫ‘е®Ңе…ЁдҪ“зҺ°еңЁжҸ’е…Ҙ/еҲ йҷӨиҝҮзЁӢдёӯпјҢеҚід»Һе·ҰеҲ°еҸіеүҚзјҖдҫқж¬ЎеҸҳзҹӯпјҢй•ҝеүҚзјҖзҡ„и·Ҝз”ұйЎ№дјҡзӣ–еңЁ
зҹӯеүҚзјҖзҡ„и·Ҝз”ұйЎ№зҡ„еүҚйқўпјҢиҝҷе°ұжҳҜж ёеҝғжҖқжғігҖӮиҷҪ然жҲ‘зҺ°еңЁе·Із»ҸеҗҰе®ҡдәҶжӢҝIPv4ең°еқҖзӣҙжҺҘеҺ»еҒҡзҙўеј•пјҢдҪҶжҳҜж ёеҝғжҖқжғіе№¶жІЎжңүеҸҳпјҢеҚівҖңжӢҝXXжҳ е°„еҲ°е…·дҪ“зҡ„дёӢдёҖи·івҖқпјҢеңЁйӮЈ
зҜҮеӨұиҙҘи®°еҪ•дёӯпјҢXXжҳҜIPv4ең°еқҖзҙўеј•пјҢиҖҢеңЁжӯЈзЎ®зҡ„еҒҡжі•дёӯпјҢXXжҳҜеҢәй—ҙгҖӮе…¶е®һеңЁHiPacйҳІзҒ«еўҷдёӯпјҢд№ҹжӯЈжҳҜдҪҝз”ЁдәҶиҝҷдёӘжҖқжғіпјҢеҚіеҢәй—ҙжҹҘжүҫгҖӮеңЁHiPacз®—жі•
дёӯпјҢеҢәй—ҙе°ұжҳҜmatchеҹҹпјҢиҖҢдёӢдёҖи·іеҜ№еә”RuleгҖӮ
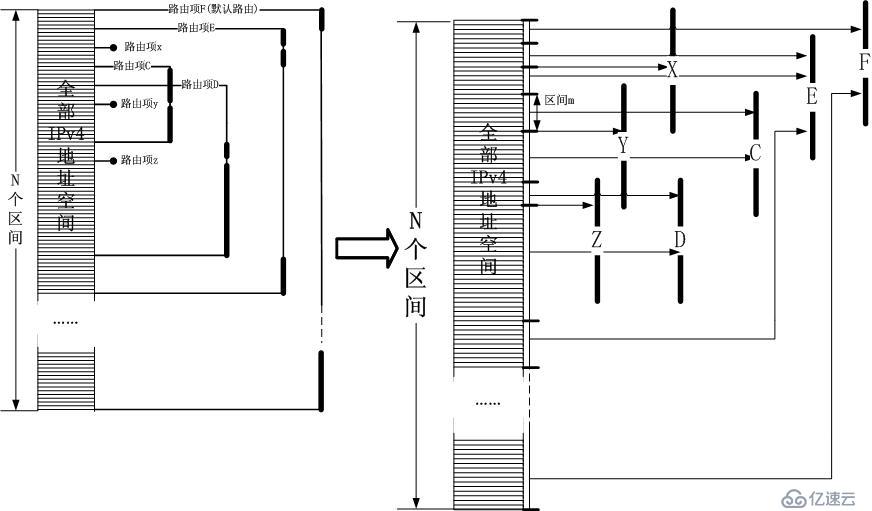
йӮЈд№ҲпјҢDxRз®—жі•е°ұжҳҜй’ҲеҜ№дёҠиҝ°еӣҫзӨәзҡ„дёҖжӯҘжӯҘдјҳеҢ–гҖӮдёәдәҶжӣҙеҘҪзҡ„иҜҙжҳҺDxRпјҢжҲ‘еҶҚж¬Ўз»ҷеҮәдёҠеӣҫзҡ„еҸҳжҚўеҪўејҸпјҡ
еҰӮ
жһңжҢүз…§дёҠйқўзҡ„еӣҫзӨәпјҢж•ҙдёӘIPv4ең°еқҖз©әй—ҙиў«еҲҶеүІжҲҗдәҶNдёӘеҢәй—ҙпјҢи·Ҝз”ұжҹҘжүҫзҡ„жңҖз»Ҳзӣ®ж ҮжҳҜе°ҶжҹҗдёӘIPv4ең°еқҖеҜ№еә”еҲ°жҹҗдёӘеҢәй—ҙдёӯпјҒеҲ°жӯӨдёәжӯўпјҢе…¶е®һе·ҘдҪңе·Із»Ҹе®ҢжҲҗдәҶгҖӮ
дҪҶжҳҜжңүдёӘеүҚжҸҗпјҢйӮЈе°ұжҳҜдҪ иҰҒжүҫеҮәжҲ–иҖ…иҮӘе·ұе®һзҺ°дёҖдёӘй«ҳжҖ§иғҪзҡ„вҖңеҢәй—ҙеҢ№й…Қз®—жі•вҖқпјҒпјҢеҚіе»әз«ӢдёҖдёӘеҢәй—ҙиЎЁпјҢеҶ…йғЁдҝқеӯҳNдёӘеҢәй—ҙйЎ№пјҢжҜҸдёӘеҢәй—ҙйЎ№еҜ№еә”дёҖдёӘдёӢдёҖи·ізҙўеј•пјҢжҜ”еҰӮ
еҢәй—ҙmеҜ№еә”дёӢдёҖи·іCпјҢжҲ‘们зҡ„зӣ®ж ҮжҳҜз»ҷе®ҡдёҖдёӘIPv4ең°еқҖпјҢеҲӨж–ӯе®ғеұһдәҺе“ӘдёӘеҢәй—ҙгҖӮиҝҷж ·зҡ„з®—жі•жҜ”жҜ”зҡҶжҳҜпјҢиҮӘе·ұе®һзҺ°дёҖдёӘдјјд№Һд№ҹдёҚйҡҫпјҢжҜ”еҰӮдәҢеҲҶжі•пјҢе“ҲеёҢз®—жі•зӯүпјҢжүҖ
д»Ҙжң¬ж–ҮдёҚе…іжіЁиҝҷдәӣгҖӮ然иҖҢDxRдјјд№Һ并дёҚж»Ўи¶іиҝҷдёӘеҸ‘зҺ°пјҢеҪ“然жҲ‘д№ҹдёҚж»Ўи¶ігҖӮDxRдјјд№ҺеёҢжңӣжүҫеҲ°дёҖз§ҚжӣҙеҠ дјҳеҢ–зҡ„ж–№ејҸе®һзҺ°иҝҷдёӘеҢәй—ҙеҢ№й…ҚгҖӮ
еңЁз»ҷеҮәDxRзҡ„жЎҶжһ¶д№ӢеүҚпјҢеҲ°жӯӨдёәжӯўпјҢжҲ‘们еҸ‘зҺ°пјҢDxRе®һиҙЁдёҠе°ұжҳҜдҪҝз”ЁдәҶеҢәй—ҙеҢ№й…ҚжқҘе°ҶдёҖдёӘзӣ®ж ҮIPv4ең°еқҖеҜ№еә”еҲ°дёҖдёӘеҢәй—ҙпјҢ然еҗҺеҸ–еҮәиҜҘеҢәй—ҙеҜ№еә”зҡ„дёӢдёҖи·іпјҒ
еҰӮ
жһңй’ҲеҜ№жҜҸдёҖдёӘеҲ°жқҘж•°жҚ®еҢ…зҡ„зӣ®ж ҮIPv4ең°еқҖйғҪиҰҒеңЁNдёӘеҢәй—ҙдёӯеҒҡеҢ№й…ҚпјҢдјјд№ҺдёҚеӨӘдјҳйӣ…гҖӮеҰӮжһңиғҪе°ҶиҝҷNдёӘеҢәй—ҙеҲ’еҲҶдёәиӢҘе№ІдёӘеӯҗеҢәй—ҙпјҢйӮЈд№ҲжҜҸж¬ЎеҢ№й…Қж—¶еҢ№й…Қзҡ„еҢәй—ҙж•°йҮҸ
е°ҶдјҡеӨ§еӨ§еҮҸе°‘пјҢжҜ”еҰӮNдёә100пјҢеҰӮжһңиғҪе°Ҷж•ҙдёӘIPv4ең°еқҖз©әй—ҙеҲ’еҲҶдёә20дёӘзӣёзӯүзҡ„еӯҗеҢәй—ҙпјҢйӮЈд№ҲжҜҸж¬ЎеҢ№й…Қзҡ„еҢәй—ҙж•°йҮҸе°ҶдјҡжҳҜ5дёӘпјҢиҖҢдёҚжҳҜ100дёӘпјҒпјҒдҪҶжҳҜиҝҷйҮҢ
еҸҲжңүдёҖдёӘеүҚжҸҗпјҢйӮЈе°ұжҳҜеҲ’еҲҶеӯҗеҢәй—ҙзҡ„ејҖй”ҖдёҖе®ҡиҰҒиғҪиў«з”ұдәҺеҮҸе°‘еҢәй—ҙж•°йҮҸиҖҢеёҰжқҘзҡ„收зӣҠжҠөж¶ҲжҺүпјҢ并且收зӣҠиҰҒжӣҙеӨ§пјҒ
иҝҷдёӘж—¶еҖҷпјҢеҰӮжһңдҪ ж·ұе…ҘзҗҶи§ЈдәҢзә§йЎөиЎЁе°ұеҘҪеҠһдәҶпјҢдёҖдёӘйЎөзӣ®еҪ•йЎ№еҢ…еҗ«1024дёӘйЎөиЎЁйЎ№пјҢдёҖдёӘйЎөиЎЁйЎ№жҢҮеҗ‘дёҖдёӘ4096еӯ—иҠӮеӨ§е°Ҹзҡ„йЎөйқўгҖӮе…¶дёӯйЎөзӣ®еҪ•е°ұжҠҠж•ҙдёӘ32дҪҚиҷҡ
жӢҹең°еқҖз©әй—ҙеҲҶеүІжҲҗдәҶ1024дёӘзӣёеҗҢеӨ§е°Ҹзҡ„еҢәй—ҙж®өпјҢжҜҸдёҖдёӘеҢәй—ҙж®өзҡ„еӨ§е°Ҹдёә4096*1024пјҢ32дҪҚиҷҡжӢҹең°еқҖеҜ№еә”32дҪҚIPv4ең°еқҖпјҢдәӢжғ…дёҚе°ұжҳҜиҝҷж ·еҗ—пјҹдёҚ
иҝҮпјҢдәҢзә§йЎөиЎЁжҲ–еӨҡзә§йЎөиЎЁи§ЈеҶізҡ„жҳҜзЁҖз–Ҹең°еқҖзҡ„й—®йўҳпјҢеҰӮжһңжҳҜдёҖзә§зҡ„йЎөиЎЁпјҢйӮЈд№Ҳдёӯй—ҙдјҡжңүеҫҲеӨҡзҡ„вҖңжҙһвҖқпјҢиҝҷжҳҜеӣ дёәиҝӣзЁӢеҰӮдҪ•е®үжҺ’иҷҡжӢҹең°еқҖеңЁеҶ…ж ёе’ҢMMUзңӢжқҘжҳҜз®ЎдёҚдәҶ
зҡ„гҖӮиҖҢеҜ№дәҺзӣ®еүҚжҲ‘们йҒҮеҲ°зҡ„й—®йўҳпјҢйҮҮз”Ёзұ»дјјзҡ„еҲҶзә§ж–№ејҸжҳҜдёәдәҶеҲ’еҲҶеӯҗеҢәй—ҙд»ҺиҖҢжҸҗй«ҳжҜҸж¬ЎеҢәй—ҙеҢ№й…Қзҡ„ж•ҲзҺҮпјҢжіЁж„ҸпјҢиҝҷ并дёҚжҳҜд»Ҙзҙўеј•дёәзӣ®зҡ„зҡ„пјҢжҲ‘й”ҷиҜҜзҡ„е°Ҷзҙўеј•дҪңдёәдәҶзӣ®
зҡ„иҖҢдёҚжҳҜжүӢж®өпјҢдәҺжҳҜи·ҢеҲ°дәҶдёҮеҠ«дёҚеӨҚзҡ„ж·ұжёҠпјҒ
дҪҶжҳҜпјҢеҜ№дәҺIPv4ең°еқҖпјҢ并дёҚйҮҮз”Ё10bit(иҝҷжҳҜиҖғиҷ‘еҲ°иҷҡжӢҹең°еқҖеҜ»еқҖзҡ„зү№зӮ№д»ҘеҸҠйЎөйқўзҡ„еӨ§е°ҸиҖҢи®ҫе®ҡзҡ„)иҝҷж ·зҡ„еҲ’еҲҶжі•пјҢиҖҢжҳҜйҮҮз”Ёk
bitеҲ’еҲҶжі•пјҢжіЁж„ҸпјҢи·Ҝз”ұ表并дёҚеӯҳеңЁйЎөйқўзҡ„жҰӮеҝөпјҒеҰӮжһңkзӯүдәҺ16пјҢйӮЈд№Ҳе°ұжҠҠIPv4ең°еқҖзҡ„й«ҳ16дҪҚе°ұжҲҗдәҶдёҖдёӘзҙўеј•пјҢз”ұдәҺдҪҺ16дҪҚзҡ„еӯҳеңЁдё”иҮӘз”ұеҸ–еҖјпјҢйӮЈд№ҲжҜҸ
дёҖдёӘзҙўеј•иЎЁйЎ№еҢ…жӢ¬16дҪҚж¶өзӣ–зҡ„IPv4ең°еқҖж•°йҮҸпјҢеҚі65535дёӘIPv4ең°еқҖгҖӮзӣ®еүҚзҡ„еҢәй—ҙжҹҘжүҫиЎЁеҸҳжҲҗдәҶдёӢйқўзҡ„ж ·еӯҗпјҡ
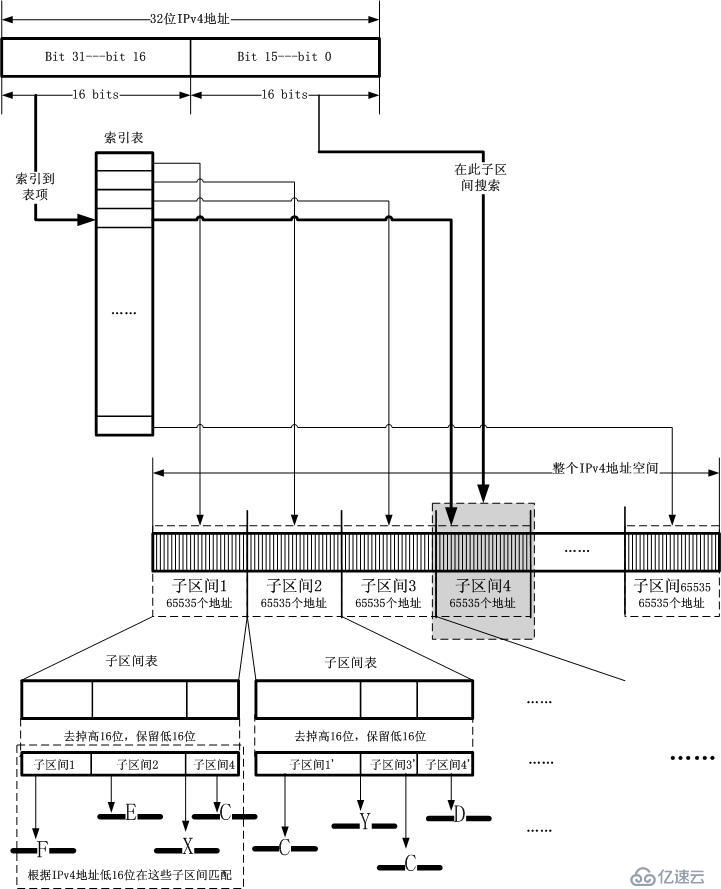
иҰҒзҹҘйҒ“пјҢIPv4ең°еқҖй«ҳ16дҪҚең°еқҖеҸҜд»ҘдёҖдёӢеӯҗзҙўеј•еҮәеӯҗеҢәй—ҙпјҢиҝҷжҳҜдёҖдёӘзһ¬й—ҙзҡ„ж“ҚдҪңпјҒ然еҗҺдёӢйқўзҡ„й—®йўҳе°ұжҳҜвҖңеҰӮдҪ•еҗҲзҗҶеёғеұҖиҝҷдәӣеӯҗеҢәй—ҙвҖқгҖӮ
еҰӮдҪ•е°ҶеӯҗеҢәй—ҙеёғеұҖжҲҗзҙ§еҮ‘зҡ„з»“жһ„дәӢе…ійҮҚеӨ§пјҢеӣ дёәзҙ§еҮ‘зҡ„ж•°жҚ®з»“жһ„ж„Ҹе‘ізқҖеҸҜд»ҘиҪҪе…ҘCPU CacheпјҒ
д»ҘдёҠйқўжңҖеҗҺдёҖе№…еӣҫдёәдҫӢеӯҗпјҢжҲ‘们еҪ“然еёҢжңӣжүҖжңүзҡ„еҢәй—ҙдҫқ然иҝһз»ӯеӯҳж”ҫпјҢиҝҷж ·дјјд№ҺжҳҜзҙ§еҮ‘зҡ„е”ҜдёҖж–№ејҸгҖӮжҲ‘们жҠҠиҝҷдёӘзҙ§еҮ‘зҡ„еҗҲ并еҗҺзҡ„еӯҗеҢәй—ҙиЎЁеҸ«еҒҡеҢәй—ҙиЎЁпјҢеҰӮдёӢеӣҫжүҖзӨәпјҡ
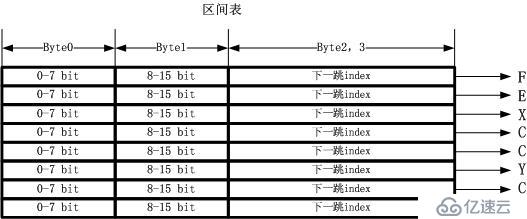
иҝҷдёӘж—¶еҖҷпјҢIPv4ең°еқҖзҡ„й«ҳ16дҪҚзҙўеј•иЎЁжҖҺд№ҲеҸҜд»ҘеҢәеҲҶеҮәиҮӘе·ұзҙўеј•зҡ„йӮЈеӣҠжӢ¬65535дёӘең°еқҖзҡ„еҢәй—ҙеҲ°еә•иҰҒеҲҶеүІдёәе“ӘдәӣеӯҗеҢәй—ҙе‘ўпјҹзӯ”жЎҲеҪ“然жҳҜжҢҮзӨәдёҖдёӘиө·е§ӢдҪҚзҪ®е’ҢеҢәй—ҙж•°йҮҸдәҶгҖӮеҰӮжһңжҲ‘们жҠҠжүҖжңүзҡ„еӣҫзӨәеұ•зӨәжҲҗдёҖз§ҚжңҖз»Ҳзҡ„ж–№ејҸпјҢйӮЈд№ҲиҜ·зңӢдёӢеӣҫпјҡ
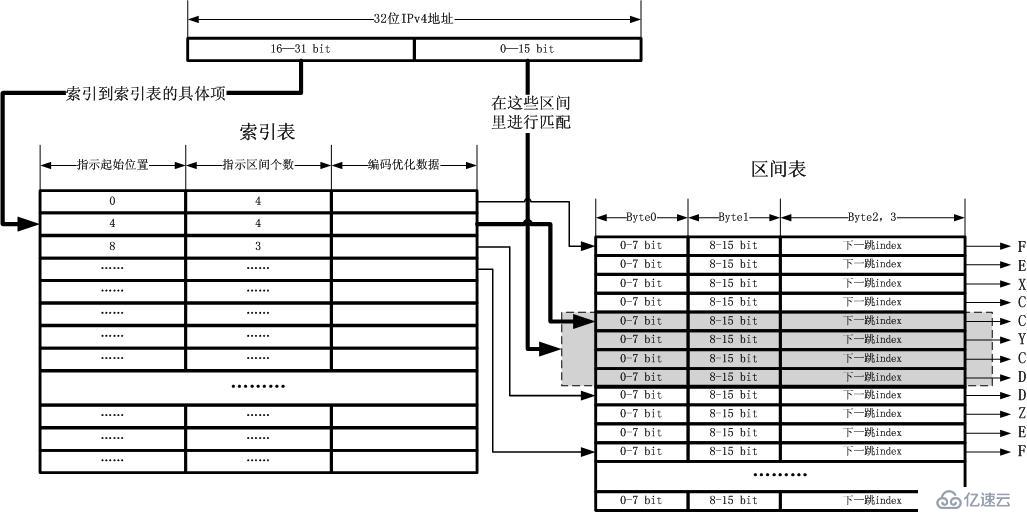
д»Ҙ
дёҠзҡ„еӣҫд»…д»…еҢ…еҗ«дёүдёӘиЎЁпјҢдёҖдёӘзҙўеј•иЎЁпјҢдёҖдёӘеҢәй—ҙиЎЁпјҢеҸҰеӨ–иҝҳжңүдёҖдёӘдёӢдёҖи·іиЎЁгҖӮе…ідәҺдёӢдёҖи·іиЎЁеӣҫдёӯжІЎжңүз”»еҮәпјҢиҝҷжҳҜеӣ дёәе®ғзҡ„еҶ…е®№дёҚеӣәе®ҡпјҢеҸҜд»Ҙд»…д»…жҳҜдёҖдёӘIPең°еқҖпјҢд№ҹ
еҸҜд»Ҙжңүи®ҫеӨҮдҝЎжҒҜд»ҘеҸҠзҠ¶жҖҒдҝЎжҒҜзӯүпјҢд№ҹеҸҜд»ҘжҳҜдёҖдёӘй“ҫиЎЁпјҢз”ЁдәҺиҙҹиҪҪеқҮиЎЎпјҢеҪ“然пјҢд№ҹеҸҜд»ҘжҢҮеҗ‘еҲ«зҡ„дёңиҘҝгҖӮе…¶дёӯжңҖе…ій”®зҡ„е°ұжҳҜеүҚдёӨдёӘиЎЁпјҢеҚізҙўеј•иЎЁе’ҢеҢәй—ҙиЎЁгҖӮиҝҷдёӨеј иЎЁйғҪеҸҜ
д»Ҙж”ҫеңЁеҫҲзҙ§еҮ‘зҡ„з©әй—ҙдёӯпјҢеҚ з”ЁеҫҲе°Ҹзҡ„еҶ…еӯҳпјҢиҝҷдёӨеј иЎЁе°Ҷд»ҘжңҖеӨ§зҡ„иғҪеҠӣжҜӣйҒӮиҮӘиҚҗд»Ҙиў«иҪҪе…ҘCPU CacheгҖӮ
жңүзӮ№дёҚеҘҪж„ҸжҖқгҖӮеӣ дёәдёҠйқўиҜҙзқҖиҜҙзқҖе°ұжҠҠиҜҘиҜҙзҡ„е…ЁйғЁиҜҙдәҶгҖӮ
е…¶е®һпјҢDxRе°ұжҳҜдёҠйқўзҡ„йӮЈе№…еӣҫжүҖиЎЁиҫҫзҡ„пјҒеҸӘжҳҜеңЁDxRдёӯпјҡ
жҖ»
зҡ„жқҘи®ІпјҢkеҖји¶ҠеӨ§пјҢзҙўеј•иЎЁеҚ жҚ®зҡ„з©әй—ҙи¶ҠеӨ§пјҢеҰӮжһңkеҖјеҸ–32пјҢйӮЈе°ұдёҚеҘҪж„ҸжҖқдәҶпјҢзҙўеј•иЎЁйЎ№дёә4GдёӘпјҢеҢәй—ҙиЎЁдёҚеӨҚеӯҳеңЁпјҢеӣ дёәжүҖжңүзҡ„IPең°еқҖеҲ°дёӢдёҖи·ізҡ„жҳ е°„йғҪжҳҺз»Ҷ
еҢ–дәҶпјҢиҝҷе°ұжҳҜжҲ‘иҮӘе·ұйӮЈж¬ЎжЁЎжӢҹMMUзҡ„и®ҫи®ЎжңҖз»Ҳзҡ„з»“жһңпјҢжҖ»д№ӢпјҢзҙўеј•иЎЁи¶ҠеӨ§пјҢе°ұжңүи¶ҠеӨҡзҡ„IPең°еқҖеҲ°дёӢдёҖи·ізҡ„жҳ е°„жҳҺз»ҶеҢ–пјҢеҢәй—ҙиЎЁзҡ„еӨ§е°ҸеңЁз»ҹи®Ўж„Ҹд№үдёҠе°ұдјҡи¶Ҡе°ҸпјҢиҝҷ
д№ҹжҳҜз©әй—ҙжҚўж—¶й—ҙзҡ„дҪ“зҺ°...еӣәе®ҡзҙўеј•иЎЁеӨ§е°Ҹзҡ„ж—¶еҖҷпјҢеҢәй—ҙиЎЁзҡ„еӨ§е°ҸжҳҜдёҚеӣәе®ҡзҡ„пјҢеҸ–еҶідәҺдҪ зҡ„и·Ҝз”ұиЎЁзҡ„и·Ҝз”ұйЎ№еёғеұҖпјҢеӣ жӯӨиҰҒжғіеҘҪеҘҪдҪҝз”ЁDxRпјҢжІЎжңүдёҖзӮ№и·Ҝз”ұ规еҲ’иғҪ
еҠӣжҳҜдёҚиЎҢзҡ„пјҢжҜ”еҰӮдҪ иҰҒе°ҪйҮҸдҪҝз”ЁиҜёеҰӮжұҮжҖ»д№Ӣзұ»зҡ„жҠҖе·§пјҢдёәдәҶдҪҝеҫ—и·Ҝз”ұеҸҜд»ҘжұҮжҖ»пјҢдҪ еҸҜиғҪдјҡиҝҳйңҖиҰҒйҮҚж–°еёғзәҝпјҢи®©еҸҜд»ҘжұҮжҖ»зҡ„и·Ҝз”ұеҸҜд»Ҙе…ұз”ЁеҗҢдёҖжҺҘеҸЈзӣёиҝһзҡ„дёӢдёҖи·іпјҢиҝҷеҸҲ
ж¶үеҸҠеҲ°дәҶдёҖдәӣи·Ҝз”ұеҲҶеҸ‘зҡ„иғҪеҠӣпјҢзү№еҲ«жҳҜдҪ еңЁж··з”ЁеҠЁжҖҒи·Ҝз”ұе’ҢйқҷжҖҒи·Ҝз”ұзҡ„ж—¶еҖҷгҖӮжҖ»д№ӢпјҢIPи·Ҝз”ұжҳҜжҜ”иҫғеӨҚжқӮзҡ„пјҢж¶үеҸҠеҲ°дәҶз»јеҗҲзҡ„иғҪеҠӣпјҢз®—жі•пјҢIPең°еқҖзҡ„зҗҶи§ЈпјҢең°еқҖ规
еҲ’пјҢи·Ҝз”ұеҲҶеҸ‘пјҢеҠЁжҖҒи·Ҝз”ұпјҢй…ҚзҪ®е‘Ҫд»ӨпјҢз”ҡиҮіз»јеҗҲеёғзәҝ...
жҲ‘并没жңүиҜҙиҝҷдёӘиЎЁеҰӮдҪ•еўһеҲ ж”№пјҢиҝҷдёӘжҲ‘и§үеҫ—жҳҜеҸҜд»ҘиҮӘе·ұеҲҶжһҗзҡ„пјҢе®ғдё»иҰҒеҸ—еҲ°еҠЁжҖҒи·Ҝз”ұзҡ„еҪұе“ҚпјҢжҜ•з«ҹпјҢеҰӮжһңзәҝи·ҜзҠ¶жҖҒдёҚжҳҜз»ҸеёёеҸҳеҢ–пјҢи·Ҝз”ұиЎЁдёҖиҲ¬д№ҹжҳҜзЁіе®ҡзҡ„гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ