您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
Python的线程开发使用标准库threading
Thread类
def __init__(self,group=None,target=None,name=None,args(),kwargs=None,*,daemon=None)
| 参数名 | 含义 |
| target | 线程调用的对象,就是目标函数 |
| name | 为线程起的名字 |
| args | 为目标函数传递实参,元组 |
| kwargs | 为目标函数传递关键字参数,字典 |
线程启动
import threading
def worker():
print("I'm working! wait a moment")
t=threading.Thread(target=worker,name='worker') # 线程对象
t.start(). # 启动通过threading.Thread创建一个线程对象,target是目标函数,name可以指定自己喜欢的名字,线程的启动需要借助start方法。线程执行函数,是因为线程中就是执行代码的,最简单的封装就是函数,所以本质还是函数调用。
线程退出
Python没有提供线程的退出方法,线程在下面的情况下时会退出
1. 线程函数内语句执行完毕
2. 线程函数中抛出未处理的异常
import threading
import time
def worker( ):
count=0
while True:
if(count>5):
raise RuntimeError(count)
time.sleep(1)
print("I'm working!")
count+=1
t=threading.Thread(target=worker,name="worker")
t.start( )
print("===End===")结果如图所示:
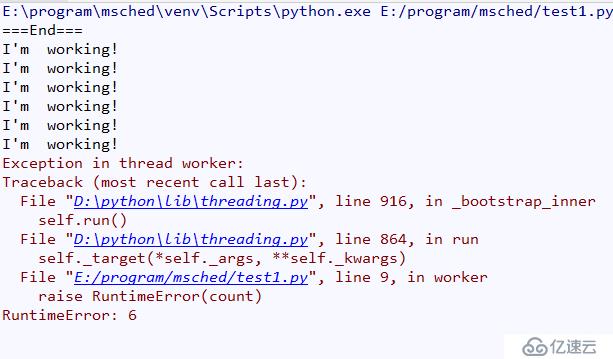
Python的线程没有优先级,没有线程组的概念。
线程的传参
import threading
import time
def add(x,y):
print("{} + {} = {}".format(x,y,x+y))
t1=threading.Thread(target=add,name="add",args(4,5))
t1.start()
time.sleep(2)
t2=threading.Thread(target=add,name="add",kwargs={"x":4;"y":5})
t2.start()
time.sleep(2)
t3=threading.Thread(target=add,name="add",args=(4,),kwargs={"y":5})
t3.start()线程传参和函数传参没什么区别,本质上就是函数传参。
threading的属性和方法
| 名称 | 含义 |
| current_thread( ) | 返回当前线程对象 |
| main_thread( ) | 返回主线程对象 |
| active_count( ) | 当前处于alive状态的线程个数 |
| enumerate( ) | 返回所有活着的线程的列表,不包括已经终止的线程和未开始的线程 |
| get_ident( ) | 返回当前线程的ID,非0整数 |
import threading
import time
def showthreadinfo():
print("currentthread = {}".format(threading.current_thread()))
print("main thread = {}".format(threading.main_thread()))
print("active count = {}".format(threading.active_count()))
def worker():
count=0
showthreadinfo()
while True:
if(count>5):
break
time.sleep(1)
count+=1
print("I'm working")
t=threading.Thread(target=worker,name='worker')
t.start()
print('===End===')结果如图所示:
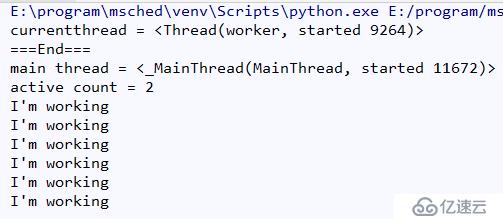
Thread实例的属性和方法
| 名称 | 含义 |
| name | 只是一个名字,可以重新命名。getName(),setName()获取,设置这个名词 |
| ident | 线程ID,它是非0整数,线程启动后才会有ID,线程退出,仍可以访问,可重复使用 |
| is_alive() | 返回线程是否存活 |
多线程
一个进程中如果有多个线程,就是多线程,实现一种并发
import threading
import time
def worker():
count=0
while True:
if(count>5):
break
time.sleep(0.5)
count+=1
print("worker running")
print(threading.current_thread().name,threading.current_thread().ident)
t1=threading.Thread(name="worker1",target=worker)
t2=threading.Thread(name="worker2",target=worker)
t1.start()
t2.start()结果如图所示:
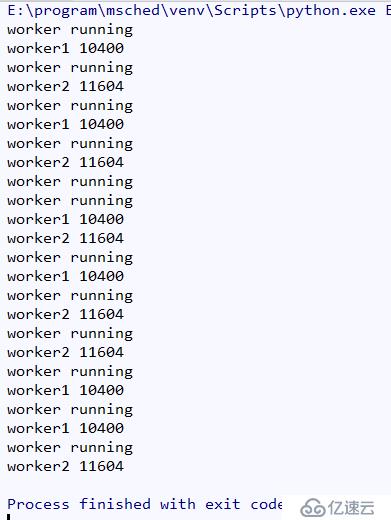
可以看到worker1和worker2交替执行
daemon线程和non-daemon线程
进程靠线程执行代码,至少有一个主线程,其它的线程都是工作线程。
父线程:如果线程A中启动了一个线程B,A就是B的父线程。
子线程:B就是A的子线程。
Python中,构造线程的时候,可以设置daemon属性,这个属性必须在start方法之前设置好。线程daemon属性,如果设定就是用户的设置,否则就取当前线程的daemon值,主线程是non-daemon线程,即daemon=False
import time
import threading
def foo():
time.sleep(3)
for i in range(10):
print(i)
t=threading.Thread(target=foo,daemon=False)
t.start()
print("Main Thread Exiting")运行结果如图所示:

主进程已经执行完毕,但是线程t依然在运行,主进程一直等待着线程t。当将Thread中daemon=False改为True时发现,主进程执行后立即会结束,根本不会等待t线程。
| 名称 | 含义 |
| daemon属性 | 表示线程是否是daemon线程,这个值必须在start之前设置,否则引发RuntimeError异常 |
| isDaemon | 是否是Daemon线程 |
| setDaemon | 设置为daemon线程,必须在start方法之前设置 |
总结:
线程具有一个daemon属性,可以设置主进程结束后是否等待其他的子线程,如果不设置,取默认值None。从主线程创建的所有线程的不设置daemon属性,则默认daemon=False。
join方法
import time import threading def foo(n): for i in range(10): print(i) time.sleep(1) t1=threading.Thread(target=foo,args=(10,),daemon=True) t1.start() t1.join()
执行结果如图所示:

根据上面讲述的daemon线程,主进程设置的dameon=True,按理说主线程执行是根本不会去等待其它的线程,也就是不会打印这些数字,但是这里却等待了子线程的运行打印出来了,这个就是join方法的作用。
join(timeout=None),是线程标准方法之一,一个线程中调用另一个线程的join方法,调用者将被阻塞,直到被调用的线程停止。一个线程可以被join多次,timeout是设置等待调用者多久,如果没有设置,就一直等待,直到被调用者线程结束。
threading.local类
Python提供了threading.local类,将这个类实例化得到一个全局对象,但是不同的线程使用这个对象存储的数据其他线程是不可见的。
import threading import time #全局对象 global_data=threading.local() def worker(): global_data=0 for i in range(100): time.sleep(0.001) global_data+=1 print(threading.current_thread(),global_data) for i in range(10): threading.Thread(target=worker).start()
运行结果如图所示:
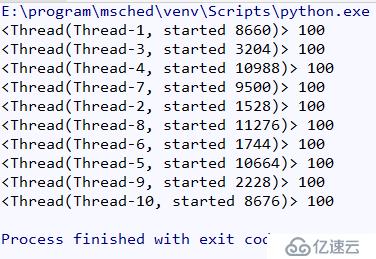
可以看到虽然是全局变量,但是这个变量在各个线程之间是独立的,每个的计算结果不会对其他线程造成干扰。
怎么证明这个是在各个线程之间独立的呢?
import threading
TestData="abc"
TestLocal=threading.local()
TestLocal.x=123
print(TestData,type(TestLocal),TestLocal.x)
def worker():
print(TestData)
print(TestLocal)
print(TestLocal.x)
worker()
print("=====")
threading.Thread(target=worker).start()可以看下运行结果
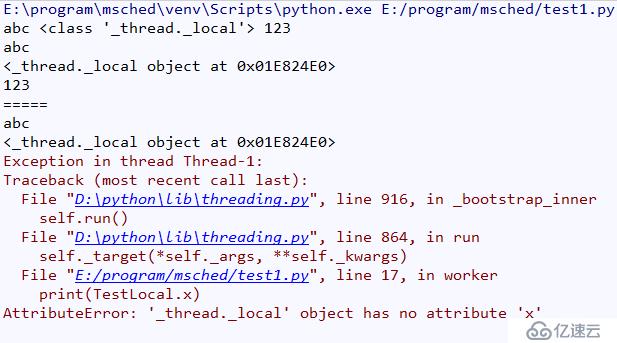
在子线程里面打印TestLocal.x时候出错,显示AttributeError: "_thread._local_" object has no attribute 'x',这是因为TestLocal.x我们是在主线程里面定义的,启动一个子线程我们并没有这个属性,所以报错,从而说明threading.local定义的变量,在各个线程之间是独立的,不能跨线程。
threading.local类构建了一个大字典,其元素是每一线程实例的地址为key和线程对象引用线程单独的字典的映射:
{id(Thread) -> (ref(Thread), thread-local dict)}
定时器Timer
threading.Timer继承自Thread,用来定义多久执行一个函数。
class threading.Timer(interval,function,args=None,kwargs=None)
start方法执行之后,Timer对象会等待interval时间,然后开始执行function函数,如果在等待阶段,使用了cancal方法,就会跳过执行而结束
import threading
import time
def worker():
print("in worker")
time.sleep(2)
t=threading.Timer(5,worker)
t.start()
print(threading.enumerate())
t.cancel()
time.sleep(1)
print(threading.enumerate())
可以看到,延迟5s执行worker线程,然后主线程继续执行,打印存活的线程,就是主线程和worker线程,然后执行cancel,子线程就会被取消执行,sleep 1s后打印存活的线程就只有主线程。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。