您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章给大家分享的是有关计算机中内存屏障由来及实现思路的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
如果你不了解讲内存屏障为什么要讲CPU缓存,接着往后看。
学过《计算机组成原理》的同学应该都听过一个词:时钟周期。什么是时钟周期呢?通俗点来讲就是CPU完成一个基本动作需要的时间周期。对硬件有点认识的同学都知道看CPU好不好一定要看的一个参数:多少多少GHZ。这个GHZ跟时钟周期之间是存在一定的换算关系的,感兴趣的同学可以去自行研究。说明一下:不了解这层换算关系不影响你看后面的内容,只要你对时钟周期有一个基本认知就可以了。
在很早以前,CPU里面是没有缓存这块区域的,就是CPU直接读写内存。那后面为什么在CPU中增加了缓存呢?因为CPU的运行效率与读写内存的效率存在着巨大的鸿沟,在读写内存过程中带来的等待浪费了很大的CPU算力。现在最新的内存是DDR4规格,但是向内存中写入数据,据权威资料,需要107个CPU时钟周期,即CPU的运行效率是写内存的107倍。如果CPU只执行写操作需要一个时钟周期,那CPU等待这个写完成需要等待106个时钟周期,是不是很浪费CPU算力?那如何解决呢?就跟我们工作中发现MySQL出现读写瓶颈如何解决是一样的思维:加缓存。
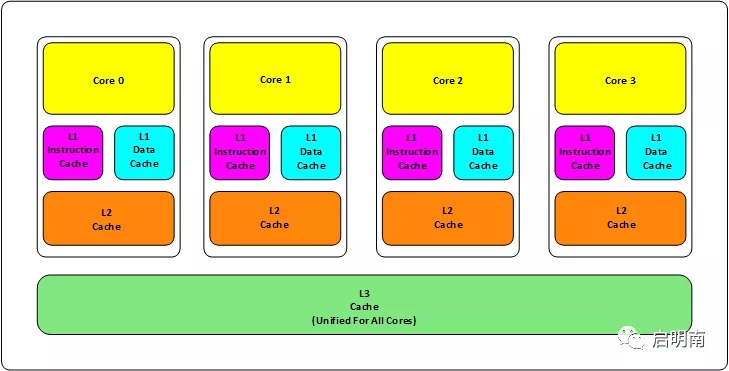
拿我们今天主流的CPU架构来说,现在的CPU主要采用三层缓存:
L1、L2缓存成为本地核心内缓存,即一个核一个。如果你的机器是4核,那就是有4个L1+4个L2
L3缓存是所有核共享的。即不管你的CPU是几核,这个CPU中只有一个L3
L1缓存的大小是64K,即32K指令缓存+32K数据缓存。L2是256K,L3是2M。这不是绝对的,目前Intel CPU基本是这样的设计
这里还补充一个知识点:缓存行(Cache-line)。缓存行是CPU缓存存储数据的最小单位,大小为64B。这块如果展开来讲要讲很久很久,本篇文章就不展开讲了,有兴趣的同学可以自行研究。如果你没有学习过计算机硬件相关知识,可能看不懂。
根据哲学的矛盾相对论:任何问题的解决方案都是一个利与弊共存的矛盾体。加缓存的确有效提升了CPU的执行效率,但是CPU缓存间的数据一致性、CPU缓存与内存间的数据一致性就是不得不去思考与解决的问题了。而且还得保证解决这两层数据一致性的效率要高于不加缓存前浪费的CPU算力,不然这个方案就是一套伪方案:听起来高大上,不解决问题。
MESI协议就是为了保证CPU各核的缓存、内存间的数据一致性而生的,没有了解过的可以百度普及一下,这个比较简单。这里拓展两点:
一、CPU运算单元与L1缓存间为什么要增加buffer?CPU实现各个核的缓存与内存间的数据一致性的思路有点像socket的三次握手:CPU0修改了某个数据,需要广播告诉其他CPU,这时候CPU0进入阻塞状态等待其他CPU修改其缓存中的状态,待其他CPU都修改完状态返回应答消息后才进入运行状态。虽然这个阻塞的时间很短,但是在CPU的世界里就很长了,为了保证这部分阻塞时间也能得到充分利用,于是加入了buffer。将预读信息存储进去,这样CPU解除阻塞后就可以直接从buffer拿出请求处理。
二、MESI协议的实现思路是:如果CPU0修改了某个数据,需要广播给其他CPU,缓存中没有这个数据的CPU丢弃这个广播消息,缓存中有这个数据的CPU监听到这个广播后会将相应的缓存行改为invalid状态,这样CPU在下次读取这个数据的时候发现缓存行失效,就去内存中读取。这里面童鞋们有没有发现一个问题:只要存在数据修改,CPU就需要去内存取数据,那为什么不实现CPU缓存能共享数据呢?这样CPU在下次读取的时候去CPU0的缓存行去读取就可以啦,而且性能更高。现在的CPU也的确实现了这个思路,对应的协议就是:AMD的MOESI、Intel的MESIF。感兴趣的童鞋自己去研究吧。
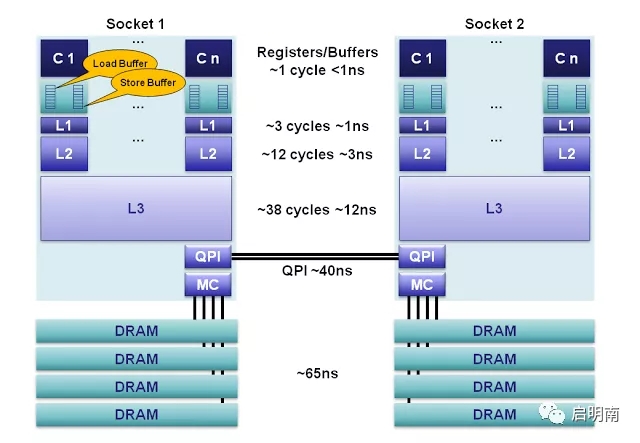
对于CPU的写,目前主流策略有两种:
1、write back:即CPU向内存写数据时,先把真实数据放入store buffer中,待到某个合适的时间点,CPU才会将store buffer中的数据刷到内存中,而且这两个操作是异步的。这在多线程环境中,有些情况下是可以接受的,但是有些情况是不可接受的,为了让程序员有能力根据业务需要达到同步完成,就设计了内存屏障。关于内存屏障,后面会细讲。
2、write through:即CPU向内存写数据时,同步完成写store buffer与内存。
当前CPU大多数采用的是write back策略。可能有童鞋要问了:为什么呢?因为大多数情况下,CPU异步完成写内存产生的部分延迟是可以接受的,而且这个延迟极短。只有在多线程环境下需要严格保证内存可见等极少数特殊情况下才需要保证CPU的写在外界看来是同步完成的,需要借助CPU提供的内存屏障实现。如果直接采用策略2:write through,那每次写内存都需要等待数据刷入内存,极大影响了CPU的执行效率。
为什么要插入屏障?本质是业务层面不能接受写store buffer与刷回内存这两个异步操作产生的哪怕是极少的延迟,即对内存可见性的要求极高。
内存屏障到底是什么?内存屏障什么都不是,它只是一个抽象概念,就像OOP。如果这样说你不理解,那你把他理解成一堵墙,这堵墙正面与反面的指令无法被CPU乱序执行及这堵墙正面与反面的读写操作需有序执行。
CPU提供了三个汇编指令串行化运行读写指令达到实现保证读写有序性的目的:
SFENCE:在该指令前的写操作必须在该指令后的写操作前完成
LFENCE:在该指令前的读操作必须在该指令后的读操作前完成
MFENCE:在该指令前的读写操作必须在该指令后的读写操作前完成
何谓串行化?你可以理解成CPU把读、写、读写请求放入了一个队列,按照先进先出的顺序执行下去;何谓读操作完成,即CPU执行一次读操作,把值读到了寄存器中;何谓写操作完成,即CPU执行一次写操作,数据刷到内存中了。
感谢各位的阅读!关于“计算机中内存屏障由来及实现思路”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。