жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮвҖңMatplotlibзҡ„binsе’ҢrwidthеҸӮж•°жҖҺд№Ҳе®һзҺ°вҖқж–Үз« зҡ„зҹҘиҜҶзӮ№еӨ§йғЁеҲҶдәәйғҪдёҚеӨӘзҗҶи§ЈпјҢжүҖд»Ҙе°Ҹзј–з»ҷеӨ§е®¶жҖ»з»“дәҶд»ҘдёӢеҶ…е®№пјҢеҶ…е®№иҜҰз»ҶпјҢжӯҘйӘӨжё…жҷ°пјҢе…·жңүдёҖе®ҡзҡ„еҖҹйүҙд»·еҖјпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« иғҪжңүжүҖ收иҺ·пјҢдёӢйқўжҲ‘们дёҖиө·жқҘзңӢзңӢиҝҷзҜҮвҖңMatplotlibзҡ„binsе’ҢrwidthеҸӮж•°жҖҺд№Ҳе®һзҺ°вҖқж–Үз« еҗ§гҖӮ
жҲ‘们еңЁеҒҡжңәеҷЁеӯҰд№ зӣёе…ійЎ№зӣ®ж—¶пјҢеёёеёёдјҡеҲҶжһҗж•°жҚ®йӣҶзҡ„ж ·жң¬еҲҶеёғпјҢиҖҢиҝҷе°ұйңҖиҰҒз”ЁеҲ°зӣҙж–№еӣҫзҡ„з»ҳеҲ¶гҖӮ
еңЁPythonдёӯеҸҜд»ҘеҫҲе®№жҳ“ең°и°ғз”Ёmatplotlib.pyplotзҡ„histеҮҪж•°жқҘз»ҳеҲ¶зӣҙж–№еӣҫгҖӮдёҚиҝҮпјҢиҜҘеҮҪж•°еҸӮж•°дёҚе°‘пјҢжңүеҮ дёӘз»ҳеӣҫзҡ„е°Ҹз»ҶиҠӮд№ҹйңҖиҰҒжіЁж„ҸгҖӮ
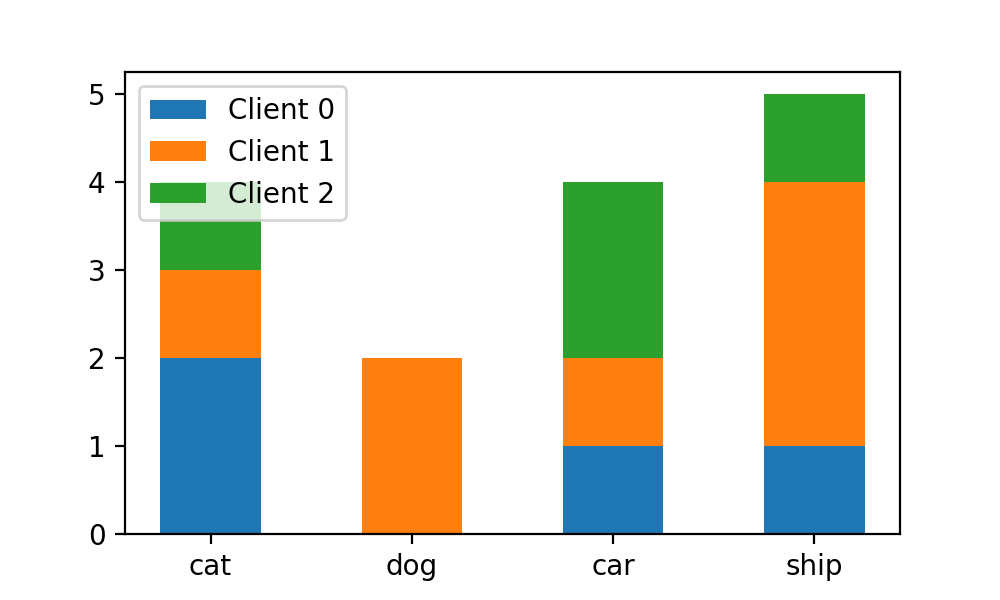
йҰ–е…ҲпјҢжҲ‘们еҒҮе®ҡзҺ°еңЁжңүдёӘиҒ”йӮҰеӯҰд№ зҡ„йЎ№зӣ®жғ…жҷҜгҖӮжҲ‘们жңүдёҖдёӘж ·жң¬дёӘж•°дёә15зҡ„еӣҫзүҮж•°жҚ®йӣҶпјҢж ·жң¬ж Үзӯҫжңү4дёӘпјҢеҲҶеҲ«дёәcat, dog, car, shipгҖӮиҝҷдёӘж•°жҚ®йӣҶе·Із»Ҹиў«дёҚеқҮиЎЎең°еҲ’еҲҶеҲ°4дёӘд»»еҠЎиҠӮзӮ№(client)дёҠгҖӮ жғ…еўғеј•е…Ҙ
жҲ‘们еңЁеҒҡжңәеҷЁеӯҰд№ зӣёе…ійЎ№зӣ®ж—¶пјҢеёёеёёдјҡеҲҶжһҗж•°жҚ®йӣҶзҡ„ж ·жң¬еҲҶеёғпјҢиҖҢиҝҷе°ұйңҖиҰҒз”ЁеҲ°зӣҙж–№еӣҫзҡ„з»ҳеҲ¶гҖӮ
еңЁPythonдёӯеҸҜд»ҘеҫҲе®№жҳ“ең°и°ғз”Ёmatplotlib.pyplotзҡ„histеҮҪж•°жқҘз»ҳеҲ¶зӣҙж–№еӣҫгҖӮдёҚиҝҮпјҢиҜҘеҮҪж•°еҸӮж•°дёҚе°‘пјҢжңүеҮ дёӘз»ҳеӣҫзҡ„е°Ҹз»ҶиҠӮд№ҹйңҖиҰҒжіЁж„ҸгҖӮ
йҰ–е…ҲпјҢжҲ‘们еҒҮе®ҡзҺ°еңЁжңүдёӘиҒ”йӮҰеӯҰд№ зҡ„йЎ№зӣ®жғ…жҷҜгҖӮжҲ‘们жңүдёҖдёӘж ·жң¬дёӘж•°дёә15зҡ„еӣҫзүҮж•°жҚ®йӣҶпјҢж ·жң¬ж Үзӯҫжңү4дёӘпјҢеҲҶеҲ«дёәcat, dog, car, shipгҖӮиҝҷдёӘж•°жҚ®йӣҶе·Із»Ҹиў«дёҚеқҮиЎЎең°еҲ’еҲҶеҲ°4дёӘд»»еҠЎиҠӮзӮ№(client)дёҠпјҢеҰӮеғҸдёӢйқўиЎЁзӨәпјҡ
N_CLIENTS = 3 num_cls, classes = 4, ['cat', 'dog', 'car', 'ship'] train_labels = [0, 3, 2, 0, 3, 2, 1, 0, 3, 3, 1, 0, 3, 2, 2] #ж•°жҚ®йӣҶзҡ„ж ҮзӯҫеҲ—иЎЁ client_idcs = [slice(0, 4), slice(4, 11), slice(11, 15)] # ж•°жҚ®йӣҶж ·жң¬еңЁclientдёҠзҡ„еҲ’еҲҶжғ…еҶө
жҲ‘们йңҖиҰҒеҸҜи§ҶеҢ–ж ·жң¬еңЁд»»еҠЎиҠӮзӮ№зҡ„еҲҶеёғжғ…еҶөгҖӮжҲ‘们第дёҖж¬ЎеҸҜиғҪдјҡеҶҷеҮәеҰӮдёӢд»Јз Ғпјҡ
import matplotlib.pyplot as plt
import numpy as np
plt.figure(figsize=(5,3))
plt.hist([train_labels[idc]for idc in client_idcs], stacked=False,
bins=num_cls,
label=["Client {}".format(i) for i in range(N_CLIENTS)])
plt.xticks(np.arange(num_cls), classes)
plt.legend()
plt.show()жӯӨж—¶зҡ„еҸҜи§ҶеҢ–з»“жһңеҰӮдёӢпјҡ
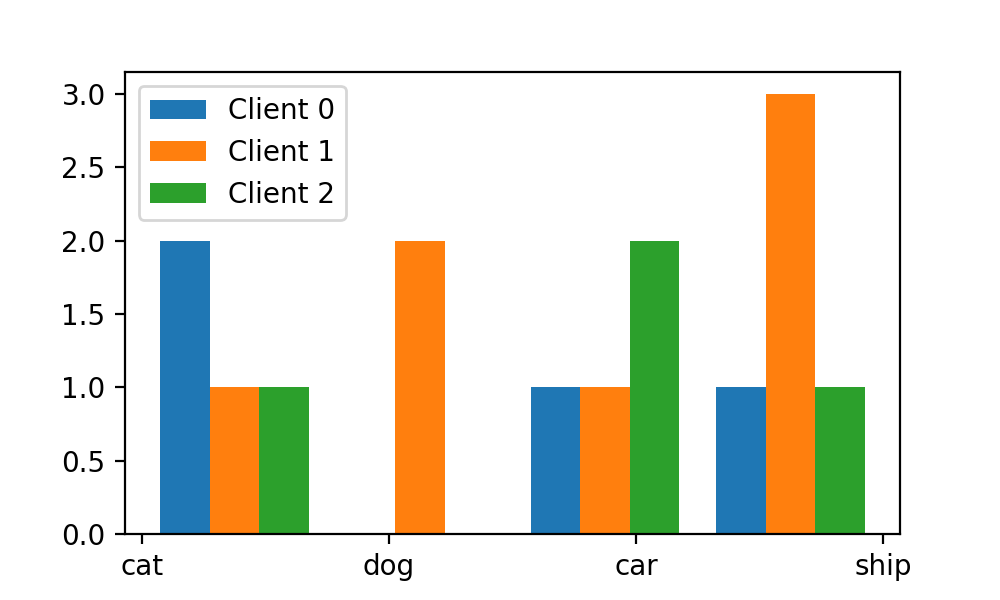
иҝҷж—¶жҲ‘们дјҡеҸ‘зҺ°пјҢжҲ‘们xиҪҙдёҠзҡ„ж Үзӯҫе’ҢдёҠж–№зҡ„barпјҲжҜҸдёӘеӣҫеғҸзұ»еҲ«еҜ№еә”зҡ„3дёӘbarеҗҲз§°дёә1дёӘbinпјү并没жңүеҜ№йҪҗпјҢиҖҢиҝҷж—¶еү§йңҖиҰҒжҲ‘们и°ғж•ҙbinsиҝҷдёӘеҸӮж•°гҖӮ
еңЁи®Іиҝ°binsеҸӮж•°д№ӢеүҚжҲ‘们е…ҲжқҘзҶҹжӮүдёҖдёӢhistз»ҳеӣҫдёӯbinе’Ңbarзҡ„еҗ«д№үгҖӮдёӢйқўжҳҜе®ғ们зҡ„иҜ йҮҠеӣҫпјҡ
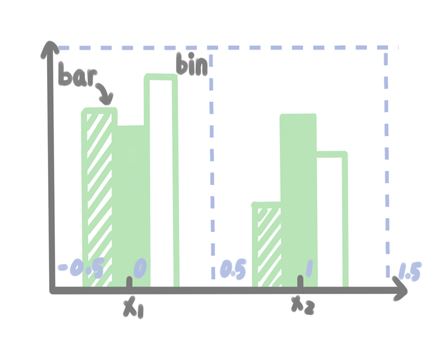
иҝҷйҮҢ\(x_1\)гҖҒ\(x_2\)жҳҜxиҪҙеҜ№иұЎпјҢеңЁhistдёӯпјҢй»ҳи®ӨxиҪҙ第дёҖдёӘеҜ№иұЎеҜ№еә”еҲ»еәҰдёә0пјҢ第2дёӘеҜ№иұЎеҲ»еәҰдёә1пјҢдҫқж¬Ўзұ»еӣҫгҖӮеңЁиҝҷдёӘиҜ йҮҠеӣҫдёҠпјҢbinпјҲеҺҹж„Ҹдёәеһғеңҫз®ұпјүе°ұжҳҜжҢҮжҜҸдёӘxиҪҙеҜ№иұЎжүҖеҚ дјҳзҡ„зҹ©еҪўз»ҳеӣҫеҢәеҹҹпјҢbar(еҺҹж„Ҹдёәеқ—)е°ұжҳҜжҢҮжҜҸдёӘзҹ©еҪўз»ҳеӣҫеҢәеҹҹдёӯзҡ„жқЎеҪўгҖӮ еҰӮдёҠеӣҫжүҖзӨәпјҢxиҪҙ第дёҖдёӘеҜ№иұЎеҜ№еә”зҡ„binеҢәй—ҙдёә[-0.5, 0.5)пјҢ第2дёӘеҜ№иұЎеҜ№еә”зҡ„binеҢәеҹҹдёә[0.5, 1)(жіЁж„ҸпјҢhist规е®ҡдёҖе®ҡжҳҜе·Ұй—ӯеҸҲејҖ)гҖӮжҜҸдёӘеҜ№иұЎзҡ„binеҢәеҹҹеҶ…йғҪжңү3дёӘbarгҖӮ
йҖҡиҝҮжҹҘйҳ…matplotlibж–ҮжЎЈпјҢжҲ‘们зҹҘйҒ“дәҶbinsеҸӮж•°зҡ„и§ЈйҮҠеҰӮдёӢпјҡ
bins: int or sequence or str, default: rcParams["hist.bins"] (default: 10)
If bins is an integer, it defines the number of equal-width bins in the range.
If bins is a sequence, it defines the bin edges, including the left edge of the first bin and the right edge of the last bin; in this case, bins may be unequally spaced. All but the last (righthand-most) bin is half-open. In other words, if bins is:
[1, 2, 3, 4]then the first bin is [1, 2) (including 1, but excluding 2) and the second [2, 3). The last bin, however, is [3, 4], which includes 4.
If bins is a string, it is one of the binning strategies supported by numpy.histogram_bin_edges: 'auto', 'fd', 'doane', 'scott', 'stone', 'rice', 'sturges', or 'sqrt'.
жҲ‘жқҘжҰӮжӢ¬дёҖдёӢпјҢд№ҹе°ұжҳҜиҜҙеҰӮжһңbinsжҳҜдёӘж•°еӯ—пјҢйӮЈд№Ҳе®ғи®ҫзҪ®зҡ„жҳҜbinзҡ„дёӘж•°пјҢд№ҹе°ұжҳҜжІҝзқҖxиҪҙеҲ’еҲҶеӨҡе°‘дёӘзӢ¬з«Ӣзҡ„з»ҳеӣҫеҢәеҹҹгҖӮжҲ‘们иҝҷйҮҢжңүеӣӣдёӘеӣҫеғҸзұ»еҲ«пјҢж•…йңҖиҰҒи®ҫзҪ®4дёӘз»ҳеӣҫеҢәеҹҹпјҢжҜҸдёӘеҢәеҹҹзӣёеҜ№дәҺxиҪҙеҲ»еәҰзҡ„еҒҸ移йҮҮеҸ–й»ҳи®Өи®ҫзҪ®гҖӮ
дёҚиҝҮпјҢеҰӮжһңжҲ‘们иҰҒи®ҫзҪ®жҜҸдёӘеҢәеҹҹзҡ„дҪҚзҪ®еҒҸ移пјҢжҲ‘们е°ұйңҖиҰҒе°Ҷbinsи®ҫзҪ®дёәдёҖдёӘеәҸеҲ—гҖӮ
binsеәҸеҲ—зҡ„еҲ»еәҰиҰҒеҸӮз…§histеҮҪж•°дёӯзҡ„xеқҗж ҮеҲ»еәҰжқҘи®ҫзҪ®пјҢжң¬д»»еҠЎдёӯ4дёӘеҲҶзұ»зұ»еҲ«еҜ№еә”зҡ„xиҪҙеҲ»еәҰеҲҶеҲ«дёә[0, 1, 2, 3] гҖӮеҰӮжһңжҲ‘们е°ҶеәҸеҲ—и®ҫзҪ®дёә[0, 1, 2, 3, 4]е°ұиЎЁзӨә第дёҖдёӘз»ҳеӣҫеҢәеҹҹеҜ№еә”зҡ„еҢәй—ҙжҳҜ[1, 2)пјҢ第2дёӘз»ҳеӣҫеҢәеҹҹеҜ№еә”зҡ„дҪҚзҪ®жҳҜ[1, 2),第дёүдёӘз»ҳеӣҫеҢәеҹҹеҜ№еә”зҡ„дҪҚзҪ®жҳҜ[2, 3)пјҢдҫқж¬Ўзұ»жҺЁгҖӮ
е°ұеӨ§дј—е®ЎзҫҺиҖҢиЁҖпјҢжҲ‘们жғіи®©жҜҸдёӘеҢәеҹҹзҡ„дёӯеҝғе’ҢеҜ№еә”xиҪҙеҲ»еәҰеҜ№йҪҗпјҢиҝҷ第дёҖдёӘеҢәеҹҹзҡ„еҢәй—ҙдёә[-0.5, 0.5)пјҢ第дәҢдёӘеҢәеҹҹзҡ„еҢәй—ҙдёә[0.5, 1.5)пјҢдҫқж¬Ўзұ»жҺЁгҖӮеҲҷжңҖз»Ҳзҡ„binsеәҸеҲ—дёә[-0.5, 0.5, 1.5, 2.5, 3.5]гҖӮдәҺжҳҜпјҢжҲ‘们е°ҶhistеҮҪж•°дҝ®ж”№еҰӮдёӢпјҡ
plt.hist([train_labels[idc]for idc in client_idcs], stacked=False,
bins=np.arange(-0.5, 4, 1),
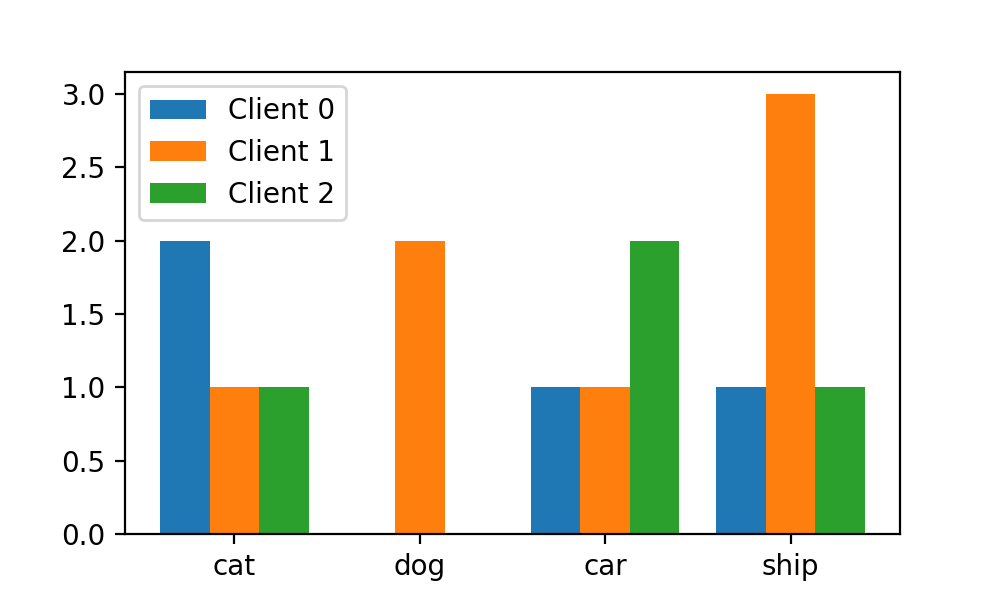
label=["Client {}".format(i) for i in range(N_CLIENTS)])иҝҷж ·пјҢжҜҸдёӘеҲ’еҲҶеҢәеҹҹе’ҢеҜ№еә”xиҪҙзҡ„еҲ»еәҰе°ұеҜ№йҪҗдәҶпјҡ
жңүж—¶xиҪҙзҡ„йЎ№зӣ®еӨҡдәҶпјҢжҜҸдёӘxиҪҙзҡ„еҜ№иұЎйғҪиҰҒи®ҫзҪ®3дёӘbarеҜ№з»ҳеӣҫз©әй—ҙж— з–‘жҳҜдёҖдёӘе·ЁеӨ§зҡ„еҚ з”ЁгҖӮеңЁиҝҷдёӘжғ…еҶөдёӢжҲ‘们еҰӮдҪ•еҺӢзј©з©әй—ҙзҡ„дҪҝз”Ёе‘ўпјҹиҝҷдёӘж—¶еҖҷеҸӮж•°stackedе°ұжҙҫдёҠдәҶз”ЁеңәпјҢжҲ‘们е°ҶеҸӮж•°stackedи®ҫзҪ®дёәTrue:
plt.hist([train_labels[idc]for idc in client_idcs],stacked=True
bins=np.arange(-0.5, 4, 1),
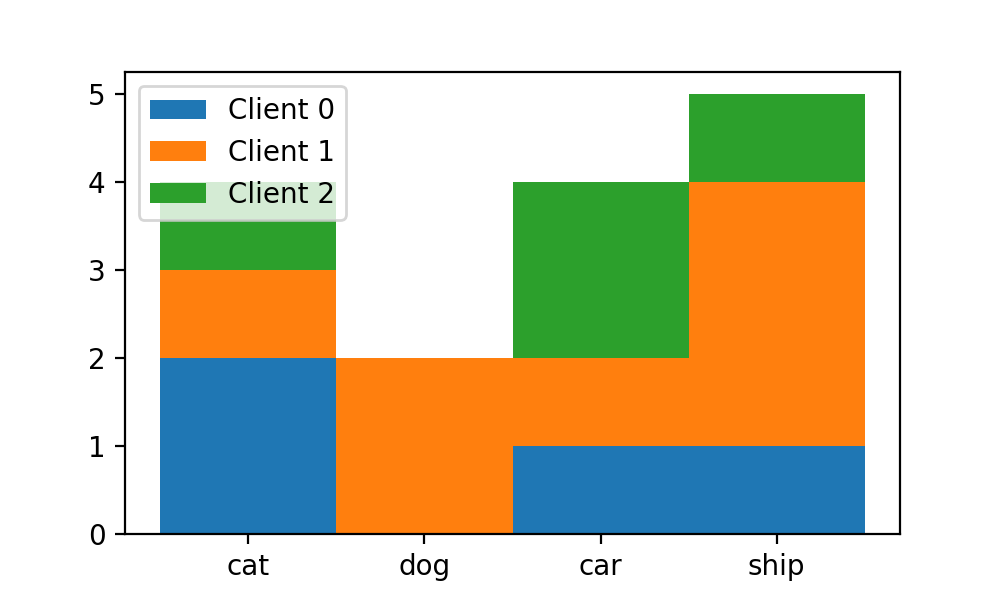
label=["Client {}".format(i) for i in range(N_CLIENTS)])еҸҜд»ҘзңӢеҲ°жҜҸдёӘxиҪҙеҜ№иұЎзҡ„barйғҪвҖңеҸ еҠ вҖқиө·жқҘдәҶпјҡ
дёҚиҝҮпјҢж–°зҡ„й—®йўҳеҸҲеҮәжқҘдәҶпјҢиҝҷж ·жҜҸxиҪҙеҜ№иұЎзҡ„barд№Ӣй—ҙе®Ңе…ЁжІЎжңүи·қзҰ»дәҶпјҢжҳҫеҫ—еҚҒеҲҶвҖңжӢҘжҢӨвҖқпјҢжҲ‘们еҸҜеҗҰдҝ®ж”№binsеҸӮж•°д»Ҙи®ҫзҪ®еҢәеҹҹbinд№Ӣй—ҙзҡ„й—ҙи·қе‘ўпјҹзӯ”жЎҲжҳҜдёҚиЎҢпјҢеӣ дёәжҲ‘们еүҚйқўжҸҗеҲ°иҝҮпјҢbinsеҸӮж•°дёӯеҸӘиғҪе°ҶеҢәеҹҹи®ҫзҪ®дёәиҝһз»ӯжҺ’еёғзҡ„гҖӮ
жҚўдёҖдёӘжҖқи·ҜпјҢжҲ‘们и®ҫзҪ®жҜҸдёӘbinеҶ…зҡ„barе’Ңbinиҫ№з•Ңд№Ӣй—ҙзҡ„й—ҙи·қгҖӮжӯӨж—¶пјҢжҲ‘们йңҖиҰҒдҝ®ж”№r_widthеҸӮж•°гҖӮ
жҲ‘们зңӢж–ҮжЎЈдёӯеҜ№rwidthеҸӮж•°зҡ„и§ЈйҮҠпјҡ
rwidth float or None, default: None
The relative width of the bars as a fraction of the bin width. If None, automatically compute the width.
Ignored if histtype is 'step' or 'stepfilled'.
зҝ»иҜ‘дёҖдёӢпјҢrwidthз”ЁдәҺи®ҫзҪ®жҜҸдёӘbinдёӯзҡ„barзӣёеҜ№binзҡ„еӨ§е°ҸгҖӮиҝҷйҮҢжҲ‘们дёҚеҰЁдҝ®ж”№дёә0.5пјҡ
plt.hist([train_labels[idc]for idc in client_idcs],stacked=True,
bins=np.arange(-0.5, 4, 1), rwidth=0.5,
label=["Client {}".format(i) for i in range(N_CLIENTS)])дҝ®ж”№д№ӢеҗҺзҡ„еӣҫиЎЁеҰӮдёӢпјҡ
еҸҜд»ҘзңӢеҲ°жҜҸдёӘxиҪҙе…ғзҙ еҶ…зҡ„barжӯЈеҘҪеҚ еҜ№еә”binзҡ„е®ҪеәҰзҡ„дәҢеҲҶд№ӢдёҖгҖӮ
д»ҘдёҠе°ұжҳҜе…ідәҺвҖңMatplotlibзҡ„binsе’ҢrwidthеҸӮж•°жҖҺд№Ҳе®һзҺ°вҖқиҝҷзҜҮж–Үз« зҡ„еҶ…е®№пјҢзӣёдҝЎеӨ§е®¶йғҪжңүдәҶдёҖе®ҡзҡ„дәҶи§ЈпјҢеёҢжңӣе°Ҹзј–еҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүеё®еҠ©пјҢиӢҘжғідәҶи§ЈжӣҙеӨҡзӣёе…ізҡ„зҹҘиҜҶеҶ…е®№пјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ