您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要介绍Python函数定义与使用的示例分析,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
什么是函数? — > 函数是具有某种特定功能的代码块,可以重复使用(在前面数据类型相关章节,其实已经出现了很多 Python 内置函数了)。它使得我们的程序更加模块化,不需要编写大量重复的代码。
函数可以提前保存起来,并给它起一个独一无二的名字,只要知道它的名字就能使用这段代码。函数还可以接收数据,并根据数据的不同做出不同的操作,最后再把处理结果反馈给我们。
由此我们得知:
将一件事情的步骤封装在一起并得到最终结果的步骤,就是函数的过程。
函数名代表了该函数要做的事情。
函数体是实现函数功能的流程。
在实际工作中,我们把实现一个函数也叫做 “实现一个方法或者实现一个功能”
函数可以帮助我们重复使用功能,通过函数名我们也可以知道函数的作用。
内置函数:在前面数据类型相关章节,其实已经出现了很多 Python 内置函数了。如 input、id、type、max、min、int、str等 ,这些都是 Python 的内置函数。也就是 Python 已经为我们定义好的函数,我们直接拿来使用即可。
自定义函数:由于每个业务的不同,需求也各不相同。Python无法提供给我们所有我们想要的功能,这时候我们就需要去开发,实现我们自己想要的功能。这部分函数,我们叫它 自定义函数 。
无论是内置函数,还是自定义函数,他们的书写方法都是一样的。
def 关键字的功能:实现 Python 函数的创建。
def 关键字定义函数:定义函数,也就是创建一个函数,可以理解为创建一个具有某些用途的工具。定义函数需要用 def 关键字实现,具体的语法格式如下:
def 函数名(参数列表): todo something # 实现特定功能的多行代码 [return [返回值]] # 用 [] 括起来的为可选择部分,即可以使用,也可以省略。 # >>> 各部分参数的含义如下: # >>> 函数名:其实就是一个符合 Python 语法的标识符,但不建议使用 a、b、c 这类简单的标识符作为函数名,函数名最好能够体现出该函数的功能(如user_info, user_mobile)。 # >>> 参数列表:设置该函数可以接收多少个参数,多个参数之间用逗号( , )分隔。 # >>> [return [返回值] ]:整体作为函数的可选参参数,用于设置该函数的返回值。也就是说,一个函数,可以用返回值,也可以没有返回值,是否需要根据实际情况而定。
注意,在创建函数时,即使函数不需要参数,也必须保留一对空的 “()” ,否则 Python 解释器将提示“invaild syntax”错误。另外,如果想定义一个没有任何功能的空函数,可以使用 pass 语句作为占位符。
示例如下:
def user_name():
print('这是一个 \'user_name\'函数 ')
user_name()
# >>> 执行结果如下
# >>> 这是一个 'user_name'函数return 的意思就是返回的意思,它是将函数的结果返回的关键字,所以函数的返回值也是通过 return 来实现的。
需要注意的是,return 只能在函数体内使用; return 支持返回所有的数据类型,当一个函数返回之后,我们可以給这个返回值赋予一个新的变量来使用。
由此我们总结出:
return 是将函数结果返回的关键字
return 只能在函数体内使用
return 支持返回所有的数据类型
有返回值的函数,可以直接赋值给一个变量
return 的用法,示例如下:
def add(a,b): c = a + b return c #函数赋值给变量 result = add(a=1,b=1) print(result) #函数返回值作为其他函数的实际参数 print(add(3,4))
需要注意的是,return 语句在同一函数中可以出现多次,但只要有一个得到执行,就会直接结束函数的执行。
现在我们利用 return 关键字 ,尝试自定义一个 capitalize 函数。示例如下:
def capitalize(data):
index = 0
temp = ''
for item in data:
if index == 0:
temp = item.upper()
else:
temp += item
index += 1
return temp
result = capitalize('hello , Jack')
print(result)
# >>> 执行结果如下
# >>> Hello , Jack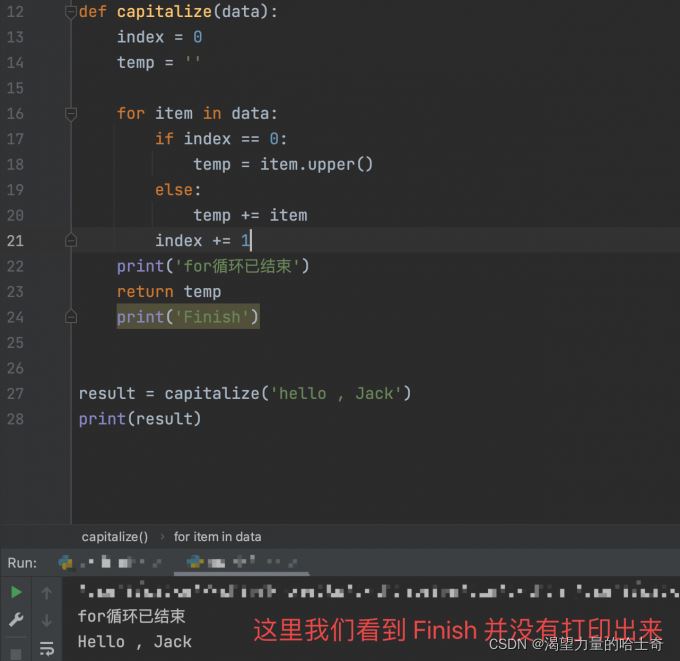
再一次注意到,只要有一个得到执行,就会直接结束函数的执行。
print 只是单纯的将对象打印输出,并不支持赋值语句。
return 是对函数执行结果的返回,且支持赋值语句;但是我们可以将含有 renturn 值的函数放在 print 里进行打印。
必传参数:平时最常用的,必传确定数量的参数
默认参数:在调用函数时可以传也可以不传,如果不传将使用默认值
不确定参数:可变长度参数(也叫可变参数)
关键字参数:长度可变,但是需要以 key-value 形式传参
什么是必传参数? —> 在定义函数的时候,没有默认值且必须在函数执行的时候传递进去的参数;且顺序与参数顺序相同,这就是必传参数。
函数中定义的参数没有默认值,在调用函数的时候,如果不传入参数,则会报错。
在定义函数的时候,参数后边没有等号与默认值。
错误的函数传参方式:def add(a=1, b=1)
错误示例如下:
def add(a, b): return a + b result = add() print(result) # >>> 执行结果如下 # >>> TypeError: add() missing 2 required positional arguments: 'a' and 'b'
正确的示例如下:
def add(a, b): return a + b result = add(1, 2) print(result) # >>> 执行结果如下 # >>> 3 # >>> add 函数有两个参数,第一个参数是 a,第二个参数是 b # >>> 传入的两个整数按照位置顺序依次赋给函数的参数 a 和 b,参数 a 和参数 b 被称为位置参数
传递的参数个数必须等于参数列表的数量
根据函数定义的参数位置来传递参数,要求传递的参数与函数定义的参数两者一一对应
如果 “传递的参数个数” 不等于 “函数定义的参数个数”,运行时会报错
错误传参数量示例如下:
def add(a, b): return a + b sum = add(1, 2, 3) # >>> 执行结果如下 # >>> sum = add(1, 2, 3) # >>> TypeError: add() takes 2 positional arguments but 3 were given
在定义函数的时候,定义的参数含有默认值,通过赋值语句给参数一个默认的值。
使用默认参数,可以简化函数的调用,尤其是在函数需要被频繁调用的情况下
如果默认参数在调用函数的时候被给予了新的值,函数将优先使用新传入的值进行工作
示例如下:
def add(a, b, c=3): return a + b + c result = add(1, 2) # 1 对应的 a ;2 对应的 b ; 没有传入 C 的值,使用 C 的默认值 3。 print(result) # >>> 执行结果如下 # >>> 6 def add(a, b, c=3): return a + b + c result = add(1, 2, 7) # 1 对应的 a ;2 对应的 b ; 传入 C 的值为 7,未使用 C 的默认值 3。 print(result) # >>> 执行结果如下 # >>> 10
这种参数没有固定的参数名和数量(不知道要传的参数名具体是什么)
不确定参数格式如下:
def add(*args, **kwargs): pass # *args :将无参数的值合并成元组 # **kwargs :将有参数与默认值的赋值语句合并成字典
*args 代表:将无参数的值合并成元组
**kwargs 代表:将有参数与默认值的赋值语句合并成字典
从定义与概念上似乎难以理解,现在我们通过示例来看一下:
def test_args(*args, **kwargs):
print(args, type(args))
print(kwargs, type(kwargs))
test_args(1, 2, 3, name='Neo', age=18)
# >>> 执行结果如下
# >>> (1, 2, 3) <class 'tuple'>
# >>> {'name': 'Neo', 'age': 18} <class 'dict'>
# >>> args 将输入的参数转成了一个元组
# >>> kwargs 将输入的赋值语句转成了一个字典
# >>> 在使用的时候,我们还可以根据元组与字典的特性,对这些参数进行使用;示例如下:
def test_args(*args, **kwargs):
if len(args) >= 1:
print(args[2])
if 'name' in kwargs:
print(kwargs['name'])
test_args(1, 2, 3, name='Neo', age=18)
# >>> 执行结果如下
# >>> 3 根据元组特性,打印输出 args 索引为 2 的值
# >>> Neo 根据字典特性,打印输出 kwargs 的 key 为 name 的 value
def test_args(*args, **kwargs):
if len(args) >= 1:
print(args[2])
else:
print('当前 args 的长度小于1')
if 'name' in kwargs:
print(kwargs['name'])
else:
print('当前 kwargs 没有 key为 name 的元素')
test_args(1, 2, 3, name1='Neo', age=18)
# >>> 执行结果如下
# >>> 3 根据元组特性,打印输出 args 索引为 2 的值3
# >>> 当前 kwargs 没有 key为 name 的元素(传入的 kwargs 为 name1='Neo', age=18;没有 name)def add(a, b=1, *args, **kwargs)
参数的定义从左到右依次是 a - 必传参数 、b - 默认参数 、可变的 *args 参数 、可变的 **kwargs 参数
函数的参数传递非常有灵活性
必传参数与默认参数的传参也非常具有多样化
示例如下:
def add(a, b=2): print(a + b) # 我们来看一下该函数可以通过哪些方式传递参数来执行 add(1, 2) # 执行结果为 : 3 add(1) # 执行结果为 : 3 add(a=1, b=2) # 执行结果为 : 3 add(a=1) # 执行结果为 : 3 add(b=2, a=1) # 执行结果为 : 3 add(b=2) # 执行结果为 : TypeError: add() missing 1 required positional argument: 'a' 。 # (因为 a 是必传参数,这里只传入 b 的参数是不行的)
def test(a, b, *args): print(a, b, args) int_tuple = (1, 2) test(1, 2, *int_tuple) # >>> 执行结果如下 # >>> 1 2 (1, 2) # *********************************************************** def test(a, b, *args): print(a, b, args) int_tuple = (1, 2) test(a=1, b=2, *int_tuple) # >>> 执行结果如下 # >>> TypeError: test() got multiple values for argument 'a' # >>> 提示我们参数重复,这是因为 必传参数、默认参数、可变参数在一起时。如果需要赋值进行传参,需要将可变参数放在第一位,然后才是 必传参数、默认参数。(这是一个特例) # ************************************************************ def test(*args, a, b): print(a, b, args) int_tuple = (1, 2) test(a=1, b=2, *int_tuple) # >>> 执行结果如下 # >>> 1 2 (1, 2) # >>> 这种改变 必传参数、默认参数、可变参数 的方式,一般我们是不推荐使用的
def test(a, b=1, **kwargs):
print(a, b, kwargs)
test(1, 2, name='Neo')
test(a=1, b=2, name='Jack')
test(name='Jack', age=18, a=1, b=2)
# >>> 执行结果如下
# >>> 1 2 {'name': 'Neo'}
# >>> 1 2 {'name': 'Jack'}
# >>> 1 2 {'name': 'Jack', 'age': 18}注意:如果传参的顺序发生变化,一定要使用赋值语句进行传参。
需求:定义一个 login 函数,向函数内传入形参 username,password,当 username 值为 admin 且password值为字符串 123456 时,返回“登录成功”;否则返回“请重新登录”
def login(username, password):
# 定义一个登录函数,传入 username, password 必填参数
if username == "admin" and password == "123456":
# 使用if语句,判断用户名和密码为“admin”和“123456”
print("登录成功") # 返回登录成功
else:
# 使用else子句处理用户名和密码非“admin”和“123456”的情况
print("请重新登录") # 返回请重新登录
# 调用函数,向函数内传入'admin','123456'和'test','123456'两组数据测试结果
login(username="admin", password="123456") # 打印函数测试结果
login(username="test", password="123456") # 打印函数测试结果前文我们学习了函数的定义方法与使用方法,在定义参数的时候我们并不知道参数对应的数据类型是什么。都是通过函数体内根据业务调用场景去判断的,如果传入的类型与也无偿性不符,就会产生报错。现在我们学习一种方法,可以在定义函数的时候,将参数类型与参数一同定义,方便我们知道每一个参数需要传入的数据类型。
我们来看一个例子:
def person(name:str, age:int=18): print(name, age)
必传参数:参数名 + 冒号 + 数据类型函数 ,为声明必传参数的数据类型
默认参数:参数名 + 冒号 + 数据类型函数 + 等号 + 默认值,为声明默认参数的数据类型
需要注意的是,对函数的定义数据类型在 python 3.7 之后的版本才有这个功能
虽然我们给函数参数定义了数据类型,但是在函数执行的时候仍然不会对参数类型进行校验,依然是通过函数体内根据业务调用场景去判断的。这个定义方法只是单纯的肉眼上的查看。
示例如下:
def add(a: int, b: int = 3):
print(a + b)
add(1, 2)
add('Hello', 'World')
# >>> 执行结果如下:
# >>> 3
# >>> HelloWorld
def add(a: int, b: int = 3, *args:int, **kwargs:str):
print(a, b, args, kwargs)
add(1, 2, 3, '4', name='Neo')
# >>> 执行结果如下:
# >>> 1 2 (3, '4') {'name': 'Neo'}我们发现执行的函数并没有报错,add(‘Hello’, ‘World’) 也通过累加的方式拼接在了一起
所以说,虽然我们定义了 int 类型,但是并没有做校验,只是单纯的通过肉眼告知我们参数是 int 类型,后续我们进入python高级进阶阶段可以自己编写代码进行校验。
全局变量:在当前 py 文件都生效的变量
在 python 脚本最上层代码块的变量
全局变量可以在函数内被读取使用
局部变量:在函数内部,类内部,lamda.的变量,它的作用域仅在函数、类、lamda 里面
在函数体内定义的变量
局部变量无法在自身函数以外使用
示例如下:
# coding:utf-8 name = 'Neo' age = 18 def test01(): print(name) def test02(): print(age) def test03(): print(name, age) test01() test02() test03() # >>> 执行结果如下: # >>> Neo # >>> 18 # >>> Neo 18 # >>> 这里我们可以看到声明的 全局变量 在多个函数体内都可以被使用
示例如下:
# coding:utf-8
name = 'Neo'
age = 18
def test01():
name = 'Jack'
age = 17
print('这是函数体内的局部变量', name, age)
test01()
print('这是函数体外的全局变量', name, age)
# >>> 执行结果如下:
# >>> 这是函数体内的局部变量 Jack 17
# >>> 这是函数体外的全局变量 Neo 18
# >>> 这里我们既声明声明了全局变量,同时还在函数体内变更了变量的值使其成为了局部变量。
# >>> 同时,根据打印输出的结果我们可以看出局部变量仅仅作用于函数体内。全局变量 在 函数体内真的就不能被修改么?当然是可以的,借助关键字 global 就可以实现。
global 关键字的功能:将全局变量可以在函数体内进行修改
global 关键字的用法:示例如下
# coding:utf-8
name = 'Neo'
def test():
global name
name = 'Jack'
print('函数体内 \'name\' 的值为:', name)
print('函数体外 \'name\' 的值为:', name)
# >>> 执行结果如下:
# >>> 函数体内 'name' 的值为: Jack
# >>> 函数体外 'name' 的值为: Jack注意:日常开发工作中,不建议使用 global 对 全局变量进行修改
再来看一个案例:
test_dict = {'name': 'Neo', 'age': '18'}
def test():
test_dict['sex'] = 'man'
test_dict.pop('age')
print('函数体内 \'test_dict\' 的值为:', test_dict)
test()
print('函数体外 \'test_dict\' 的值为:', test_dict)
# >>> 执行结果如下:
# >>> 函数体内 'test_dict' 的值为: {'name': 'Neo', 'sex': 'man'}
# >>> 函数体外 'test_dict' 的值为: {'name': 'Neo', 'sex': 'man'}前面我们是通过 global 关键字修改了函数体内的变量的值,为什么在这里没有使用 global 关键字,在函数体内修改了 test_dict 的值却影响到了函数体外的变量值呢?
其实,通过 global 关键字修改的全局变量仅支持数字、字符串、空类型、布尔类型,如果在局部变量想要使用全局变量的字典、列表类型,是不需要通过 global 关键字指引的。
什么是递归函数? —> 通俗的来说,一个函数不停的将自己反复执行,这就是递归函数。(通常是由于函数对自己的执行结果不满意,才需要这样反复的执行。)
示例如下:
def test(a): print(a) return test(a) # 通过返回值,直接执行自身的函数 test(1) # >>> 执行结果如下: # >>> 1 # >>> 1.... 会一直执行下去,有可能会造成死机,不要尝试。
count = 0
def test():
global count
count += 1
if count != 5:
print('\'count\'的条件不满足,需要重新执行。当前\'count\'的值为%s' % count)
return test()
else:
print('当前\'count\'的值为%s' % count)
test()
# >>> 执行结果如下:
# >>> 'count'的条件不满足,需要重新执行。当前'count'的值为1
# >>> 'count'的条件不满足,需要重新执行。当前'count'的值为2
# >>> 'count'的条件不满足,需要重新执行。当前'count'的值为3
# >>> 'count'的条件不满足,需要重新执行。当前'count'的值为4
# >>> 当前'count'的值为5首先我们要知道 递归函数 会造成的影响,递归函数 是不停的重复调用自身函数行程一个无限循环,就会造成内存溢出的情况,我们的电脑可能就要死机了。
递归函数虽然方便了我们用一段短小精悍的代码便描述了一个复杂的算法(处理过程),但一定要谨慎使用。(使用循环来处理,不失为一个稳妥的方案。)
所以我们要尽量的避免使用 递归函数 ,如果真的要使用递归,一定要给予退出递归的方案。
lambda 函数的功能:定义一个轻量化的函数;所谓轻量化就是即用即删除,很适合需要完成一项功能,但是此功能只在此一处使用。也就是说不会重复使用的函数,并且业务简单的场景,我们就可以通过 lambda 来定义函数
lambda 函数的用法示例如下
# 定义匿名函数的两种方法 # 方法1:无参数的匿名函数 test = lambda: value # lambda + 冒号 + value 值 , 赋值给一个变量 test() # 变量名 + 小括号 ,至此 lambda 匿名函数就定义完了。(value实际上是具有 return 效果的) # 方法2:有参数的匿名函数 test = lambda value,value:value*value # lambda + 两个参数 + 冒号 + 两个value简单的处理 , 赋值给一个变量 test(3, 5)
# 无参数的匿名函数 test = lambda:1 result = test() print(result) # >>> 执行结果如下: # >>> 1 # ********************* # 有参数的匿名函数 test = lambda a, b: a+b result = test(1, 3) print(result) # >>> 执行结果如下: # >>> 4 # ********************* test = lambda a, b: a>b result = test(1, 3) print(result) # >>> 执行结果如下: # >>> False
再来看一个示例,加深对 lambda 匿名函数的理解
users = [{'name': 'Neo'}, {'name': 'Jack'}, {'name': 'Lily'}]
users.sort(key=lambda user_sort: user_sort['name'])
print(users)
# >>> 执行结果如下:
# >>> [{'name': 'Jack'}, {'name': 'Lily'}, {'name': 'Neo'}]
# >>> 我们看到 {'name': 'Jack'} 被排到了最前面,通过 lambda 将列表中的每个成员作为参数传入,
# >>> 并将元素中指定 key 为 name 的 value 作为了排序对象进行排序。关于 lambda 的简单使用,就介绍到这里。后续高级语法进阶章节会对 lambda 匿名函数 的高级用法进行详细的讲解。
利用函数实现学生信息库
现在我们学习完了 函数的基本知识 ,接下来我们进行一个总结和联系。练习一个学生信息库的案例,并且随着之后的章节学习我们还会不端升级、优化这个信息库,达到真正可以使用的功能。
接下来我们先定义出学生信息库的基本结构,之后开发这个信息库的增、删、改、查功能。
# coding:utf-8
"""
@Author:Neo
@Date:2020/1/14
@Filename:students_info.py
@Software:Pycharm
"""
students = { # 定义一个学生字典,key 为 id,value 为 学生信息(name、age、class_number、sex)
1: {
'name': 'Neo',
'age': 18,
'class_number': 'A',
'sex': 'boy'
},
2: {
'name': 'Jack',
'age': 16,
'class_number': 'B',
'sex': 'boy'
},
3: {
'name': 'Lily',
'age': 18,
'class_number': 'A',
'sex': 'girl'
},
4: {
'name': 'Adem',
'age': 18,
'class_number': 'C',
'sex': 'boy'
},
5: {
'name': 'HanMeiMei',
'age': 18,
'class_number': 'B',
'sex': 'girl'
}
}
def check_user_info(**kwargs): # 定义一个 check_user_info 函数,检查学生信息传入食肉缺失
if 'name' not in kwargs:
return '没有发现学生姓名'
if 'age' not in kwargs:
return '缺少学生年龄'
if 'sex' not in kwargs:
return '缺少学生性别'
if 'class_number' not in kwargs:
return '缺少学生班级'
return True
def get_all_students(): # 定义一个 get_all_students 函数,获取所有学生信息并返回
for id_, value in students.items():
print('学号:{}, 姓名:{}, 年龄:{}, 性别:{}, 班级:{}'.format(
id_, value['name'], value['age'], value['sex'], value['class_number']
))
return students
def add_student(**kwargs): # 定义一个 add_student 函数,执行添加学生信息的操作并进行校验,学生id 递增
check = check_user_info(**kwargs)
if check != True:
print(check)
return
id_ = max(students) + 1
students[id_] = {
'name': kwargs['name'],
'age': kwargs['age'],
'sex': kwargs['sex'],
'class_number': kwargs['class_number']
}
def delete_student(student_id): # 定义一个 delete_student 函数,执行删除学生信息操作,并进行是否存在判断
if student_id not in students:
print('{} 并不存在'.format(student_id))
else:
user_info = students.pop(student_id)
print('学号是{}, {}同学的信息已经被删除了'.format(student_id, user_info['name']))
def update_student(student_id, **kwargs): # 定义一个 update_student 函数,执行更新学生信息操作,并进行校验
if student_id not in students:
print('并不存在这个学号:{}'.format(student_id))
check = check_user_info(**kwargs)
if check != True:
print(check)
return
students[student_id] = kwargs
print('同学信息更新完毕')
# update_student(1, name='Atom', age=16, class_number='A', sex='boy') # 执行 更新学生信息函数,并查看结果
# get_all_students()
def get_user_by_id(student_id): # 定义一个 get_user_by_id 函数,可以通过学生 id 查询学生信息
return students.get(student_id)
# print(get_user_by_id(3))
def search_users(**kwargs): # 定义一个 search_users 函数,可以通过 学生关键信息进行模糊查询
values = list(students.values())
key = None
value = None
result = []
if 'name' in kwargs:
key = 'name'
value = kwargs[key]
elif 'sex' in kwargs:
key = 'sex'
value = kwargs['sex']
elif 'class_number' in kwargs:
key = 'class_number'
value = kwargs[key]
elif 'age' in kwargs:
key = 'age'
value = kwargs[key]
else:
print('没有发现搜索的关键字')
return
for user in values:
if user[key] == value:
result.append(user)
return result
users = search_users(sex='girl')
print(users)
# >>> 执行结果如下:
# >>> [{'name': 'Lily', 'age': 18, 'class_number': 'A', 'sex': 'girl'}, {'name': 'HanMeiMei', 'age': 18, 'class_number': 'B', 'sex': 'girl'}]以上是“Python函数定义与使用的示例分析”这篇文章的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。