您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要介绍了Pythonr基于selenium怎么实现不同商城的商品价格差异分析系统的相关知识,内容详细易懂,操作简单快捷,具有一定借鉴价值,相信大家阅读完这篇Pythonr基于selenium怎么实现不同商城的商品价格差异分析系统文章都会有所收获,下面我们一起来看看吧。
selenium 原本是一款自动化测试工具,因其出色的页面数据解析和用户行为模拟能力而常用于爬虫程序中,致使爬虫程序的爬取过程更简单、快捷。
爬虫程序与其它类型程序相比较,本质一样,为数据提供处理逻辑,只是爬虫程序的数据来源于 HTML 代码片段中。
怎样准确查找到页面中数据所在的标签(或叫节点、元素、组件)就成了爬虫程序的关键,只有这一步成立,后续的数据提取、清洗、汇总才有可能。
相比较于 Beaufulsoup 模块, selenium 底层依靠的是强大的浏览器引擎,在页面解析能力上颇有王者的从容和决绝。
本文将使用 selenium 自动摸拟用户的搜索行为,获取不同商城上同类型商品的价格信息,最终生成商品在不同商城上的价格差对比表。
本程序实现了用户不打开浏览器、只需要输入一个商品关键字,便能全自动化的实现在不同商城中查找商品价格,并汇总出价格一些差异信息。
1、程序运行时,提示使用者输入需要搜索的商品关键字。
本程序仅为探研 selenium 的奇妙之处,感受其王者风范,没有在程序结构和界面上费心力。
2、使用 selenium 摸拟用户打开京东和苏宁易购首页。
为什么选择京东和苏宁易,而不选择淘宝?
因为这 2 个网站使用搜索功能时没有登录验证需要,可简化本程序代码。
3、使用 selenium 在首页的文本搜索框中自动输入商品关键字,然后自动触发搜索按钮的点击事件,进入商品列表页面。
4、使用 selenium 分析、爬取不同商城中商品列表页面中的商品名称和价格数据。
5、对商品的价格数据做简单分析后,使用 CSV 模块以文件方式保存。
主要分析商品在不同商城上的平均价格、最低价格、最高体系的差异。
当然,如果有需要,可以借助其它的模块或分析逻辑,得到更多的数据分析结论。
虽然本文不深究 selenium API 的细节,但是,既然要用它,其使用流程还是要面面俱到。
1、安装:
selenium 是 python 第三库,使用前要安装,安装细节就没必要在此多费笔墨。
pip3 install selenium
除了安装 selenium 模块,还需要为它下载一个浏览器驱动程序,否则它无法工作。
什么是浏览器驱动程序?为什么需要它?
解释这个问题,需要从 selenium 的工作原理说起。
2、浅淡 selenium 的工作原理:
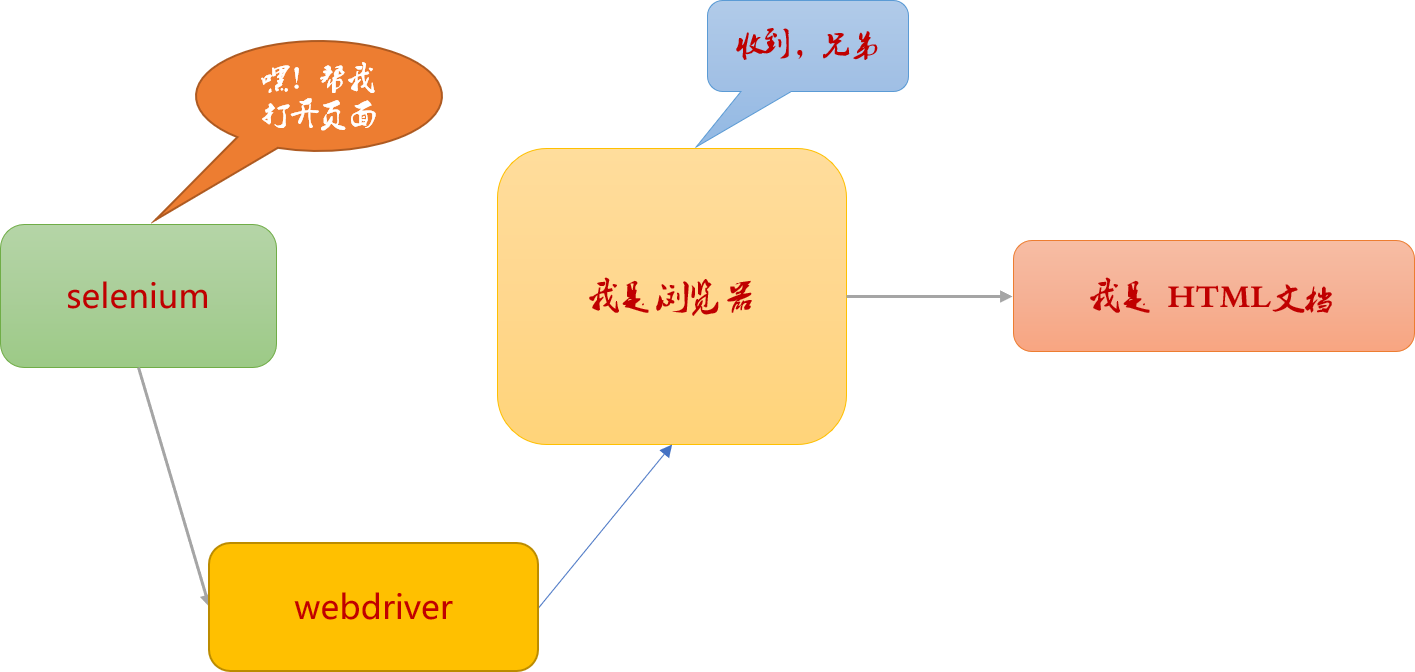
Beautiful soup 使用特定的解析器程序解析 HTML 页面。selenium 更干脆、直接借助浏览器的解析能力。通过调用浏览器的底层 API 完成页面数据查找,也是跪服了,不仅爬取,还可以向浏览器模拟用户行为发送操作指令。
有没有感觉浏览器就是 selenium 手中的牵线木偶(玩弄浏览器于股掌之中)。 selenium 的工作就是驱动浏览器,向浏览器发送指令或接收浏览的反馈,此过程中,浏览器驱动程序(webdriver)就起到了上传下达的作用。
典型的组件开发模式。
很显然,因不同浏览器的内核存在差异性,驱动程序必然也不相同,所以,下载驱动程序之前,请确定你使用的浏览器类型和版本。
本文使用谷歌浏览器,需要下载与谷歌浏览器对应的 webdriver 驱动程序。
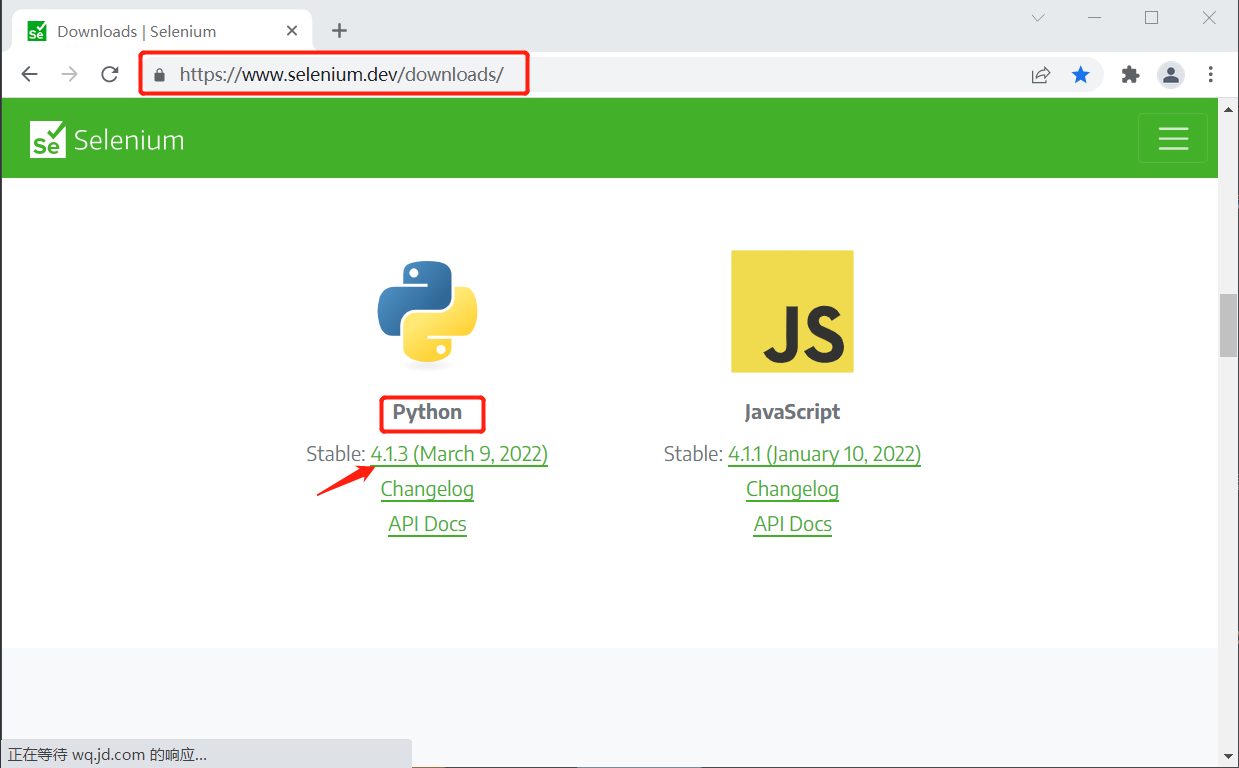
进入 https://www.selenium.dev/downloads/ 网站,选择 python 语言,选择最新稳定版本。
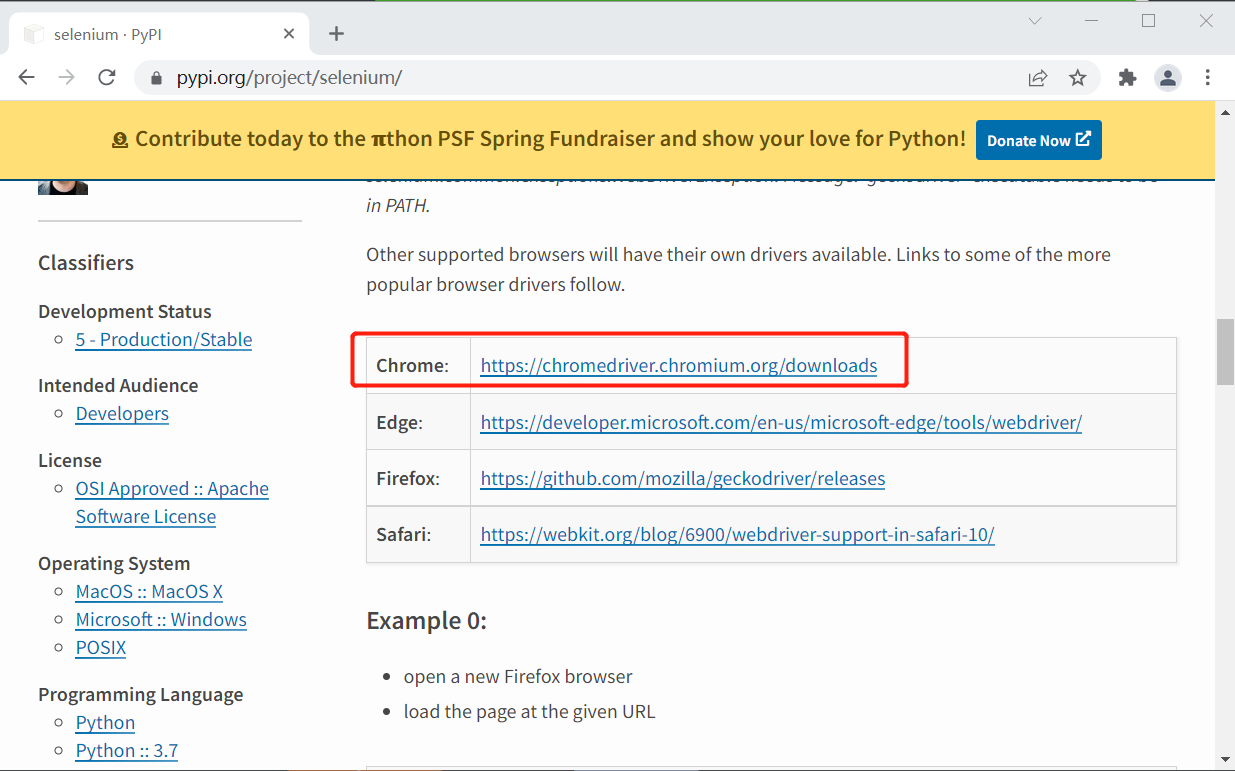
请选择与正使用的浏览版本一致的驱动程序。
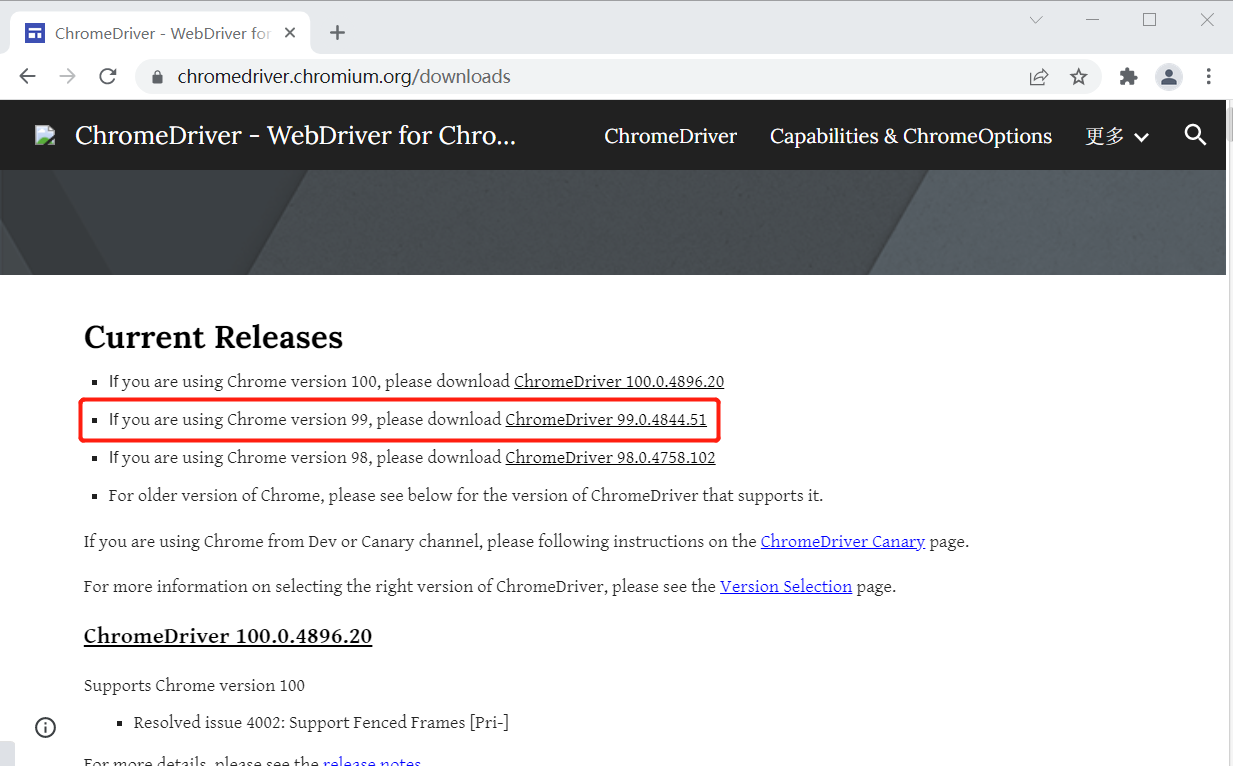
下载完毕后,指定一个驱动程序的存放目录,本文存放在 D:\chromedriver\chromedriver.exe 。也可存放在浏览器的安装目录。
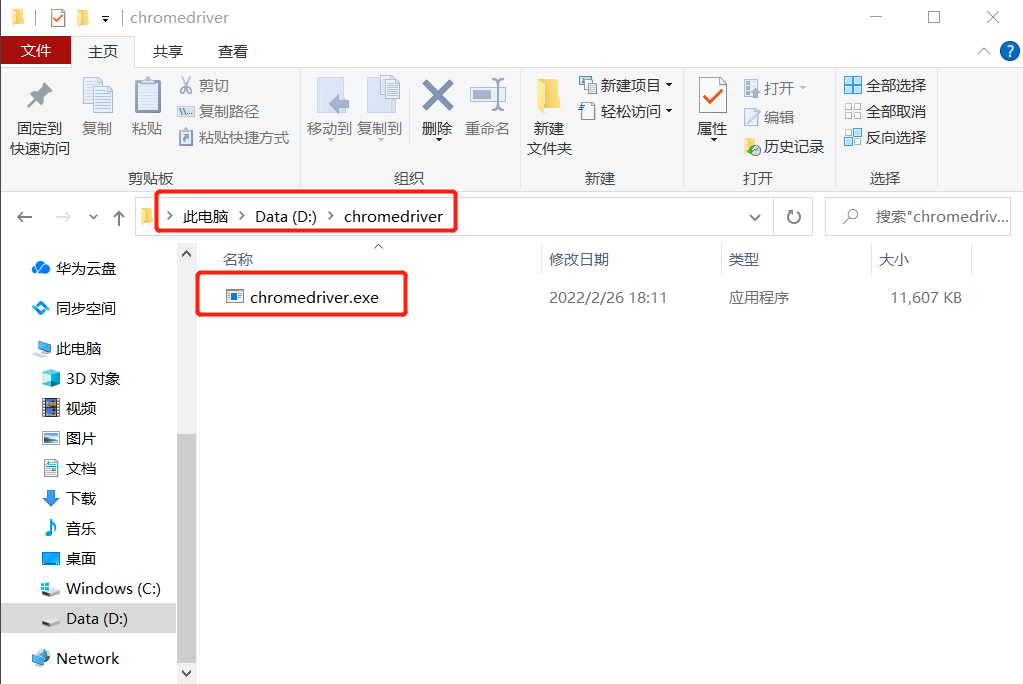
准备工作就绪后,开始编码:
导入程序所需要的模块,定义程序所需要的变量。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import csv
import time
import math
# 浏览器对象
chrome_browser = None
# 商品关键字
search_keyword = None
# 保存在京东商城搜索到的商品数据,格式{商品名:价格}
jd_data = {}
# 保存在苏宁商城搜索到的商品数据,格式{商品名:价格}
sn_data = {}webdriver: 用来构建浏览器对象,从底层设计角度讲,是 selenium 和浏览器之间的接口层。selenium 向上为用户提供高级应用接口,向下通过 webdriver 和浏览器无障碍沟通。
Service: webdriver 构建浏览器对象时的参数类型。
By: ** 封装了查找页面组件的各种方式。selenium** 向开者提供了很多高级方法用来查询 HTML 页面组件,如通过元素 ID、样式、样式选择器、XPATH……By 封装了这些方案。
诸如:find_element_by_class_name( )、 find_element_by_id()、find_element_by_()、find_element_by_tag_name()、find_element_by_class_name()、find_element_by_xpath()、find_element_by_css_selector()
以上方法已经被标注为过时,请使用 find_element( ) 方法,配合 By 对象切换方式。
csv: 用来把获取到的数据以 csv 格式保存。
time: 时间模块,用来模拟网络延迟。
math: 数学模块,辅助数据分析。
初始化函数:初始化浏览器对象和用户输入数据
'''
初始浏览器对象
'''
def init_data():
# 驱动程序存放路径
webdriver_path = r"D:\chromedriver\chromedriver.exe"
service = Service(webdriver_path)
# 构建浏览器对象
browser = webdriver.Chrome(service=service)
# 等待浏览器就绪
browser.implicitly_wait(10)
return browser
'''
初始用户输入的商品名称关键字
'''
def input_search_key():
info = input("请输入商品关键字:")
return info查询京东商品信息。在京东商城查询商品,分两个步骤,在首页输入商品关键字,点击搜索后,在结果页面查询价格信息。完整代码如下:
'''
进入京东商城查询商品信息
'''
def search_jd():
global jd_data
products_names = []
products_prices = []
# 京东首页
jd_index_url = r"https://www.jd.com/"
# 打开京东首面
try:
if chrome_browser is None:
raise Exception()
else:
# 打开京东首页
chrome_browser.get(jd_index_url)
# 模拟网络延迟
chrome_browser.implicitly_wait(10)
# 找到文本输入组件
search_input = chrome_browser.find_element(By.ID, "key")
# 在文本框中输入商品关键字
search_input.send_keys(search_keyword)
chrome_browser.implicitly_wait(5)
# 找到搜索按钮 这里使用 CSS 选择器方案
search_button = chrome_browser.find_element(By.CSS_SELECTOR, "#search > div > div.form > button")
# 触发按钮事件
search_button.click()
chrome_browser.implicitly_wait(5)
# 获取所有打开的窗口(当点击按钮后应该有 2 个)
windows = chrome_browser.window_handles
# 切换新打开的窗口,使用负索引找到最后打开的窗口
chrome_browser.switch_to.window(windows[-1])
chrome_browser.implicitly_wait(5)
# 获取商品价格
product_price_divs = chrome_browser.find_elements(By.CLASS_NAME, "p-price")
for i in range(5):
div = product_price_divs[i]
if len(div.text) != 0:
# 删除价格前面的美元符号
products_prices.append(float(div.text[1:]))
# 获取商品名称
product_name_divs = chrome_browser.find_elements(By.CLASS_NAME, "p-name")
chrome_browser.implicitly_wait(10)
for i in range(5):
div = product_name_divs[i]
if len(div.text) != 0:
products_names.append(div.text)
jd_data = dict(zip(products_names, products_prices))
jd_data["平均价格"] = sum(products_prices) / len(products_prices)
jd_data["最低价格"] = min(products_prices)
jd_data["最高价格"] = max(products_prices)
# 使用 CSV 模块写入文档
csv_save("京东商城", jd_data)
except Exception as e:
print(e)chrome_browser: 由 webdriver 构建出来的对浏览器映射的对象,selenium 通过此对象控制对浏览器的所有操作。
此对象有一个 find_element( ) 核心方法,用来查找(定位)HTML 页面元素。查找时,可以通过 By 对象指定查找的方式(这里使用了工厂设计模式), By 的取值可以是 ID、CSS_SELECTOR、XPATH、CLASS_NAME、CSS_SELECTOR、TAG_NAME、LINK_TEX、PARTIAL_LINK_TEXT。
打开京东首页后,先定位定位文本搜索框和搜索按钮。
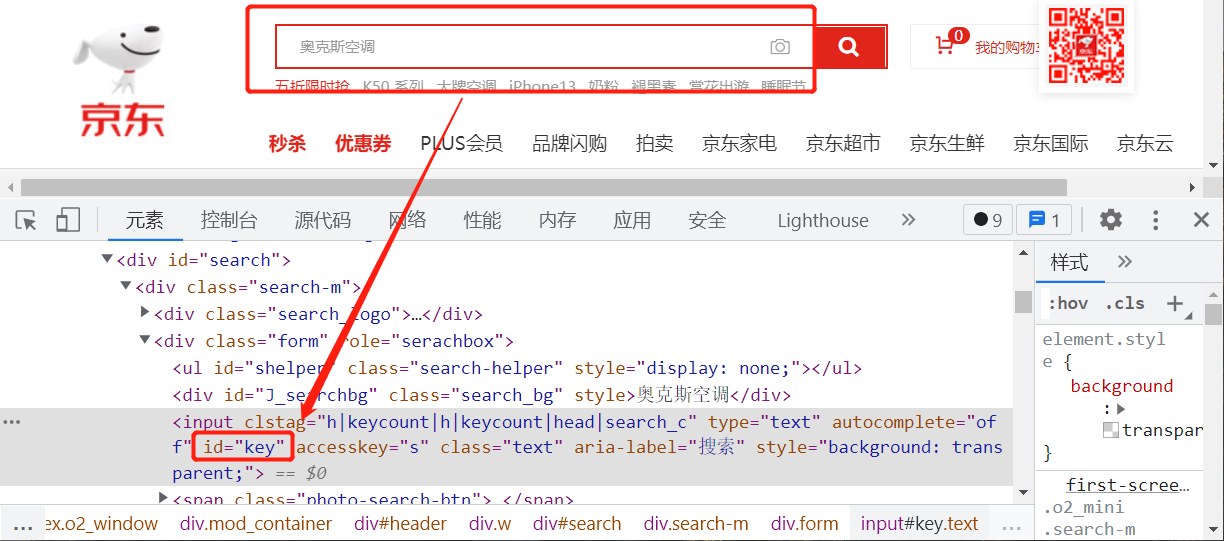
使用浏览器的开发者工具,检查到文本框的源代码是一段 input html 片段,为了精确地定位到此组件,一般先试着分析此组件有没有独有的属性或特征值,id 是一个不错的选择。html 语法规范 id 值应该是一个唯一值。
search_input = chrome_browser.find_element(By.ID, "key")
找到组件后,可以对此组件进行一系列操作,常用的操作:
text 属性: 获取组件的文本内容。
send_keys( ) 方法:为此组件赋值。
get_attribute( ) 方法:获取组件的属性值。
这里使用 send_keys 给文本组件赋予用户输入商品关键字。
search_input.send_keys(search_keyword)
再查找搜索按钮组件:
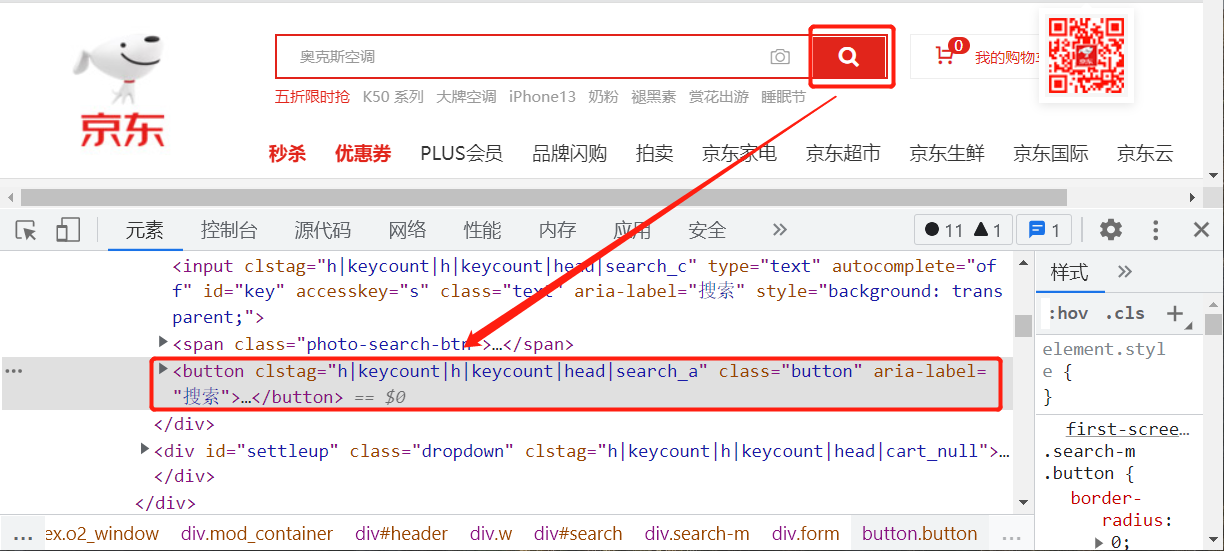
按钮组件是一段 button html 代码,没有过于显著的特性属性值,为了找到这个唯一组件,可以使用 XPATH 或 CSS 选择器方式。右击此代码片段,在弹出的快捷菜单中找到“复制”命令,再找到此组件的 CSS选择器值。
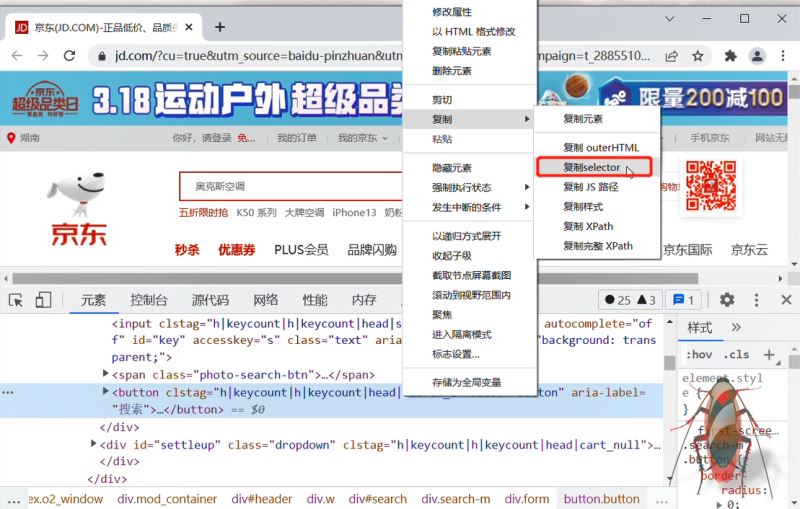
search_button = chrome_browser.find_element(By.CSS_SELECTOR, "#search > div > div.form > button")
调用按钮组件的 click() 方法,模拟用户点击操作,此操作会打开新窗口,并以列表方式显示搜索出来的商品数据。
search_button.click()
selenium 接收到浏览器打开新窗后的反馈后,可以使用 window_handles 属性获取浏览器中已经打开的所有窗口,并以列表的方式存储每一个窗口的操作引用。
windows = chrome_browser.window_handles
对页面元素进行定位查找时,有一个当前窗口(当前可以、正在操作的窗口)的概念。刚开始是在首页窗口操作,现在要在搜索结果窗口中进行操作,所以要切换到刚打开的新窗口。使用负索引得到刚打开的窗口(刚打开的窗口一定是最后一个窗口)。
chrome_browser.switch_to.window(windows[-1])
注意,这时切换到了搜索结果窗口,便可以在这个窗口中搜索所需要组件。

在这个页面中,只需要获取前 5 名的商品具体信息,包括商品名、商品价格。至于具体要获取什么数据,可以根据自己的需要定夺。本程序只需要商品的价格和名称,则检查页面,找到对应的 html 片段。
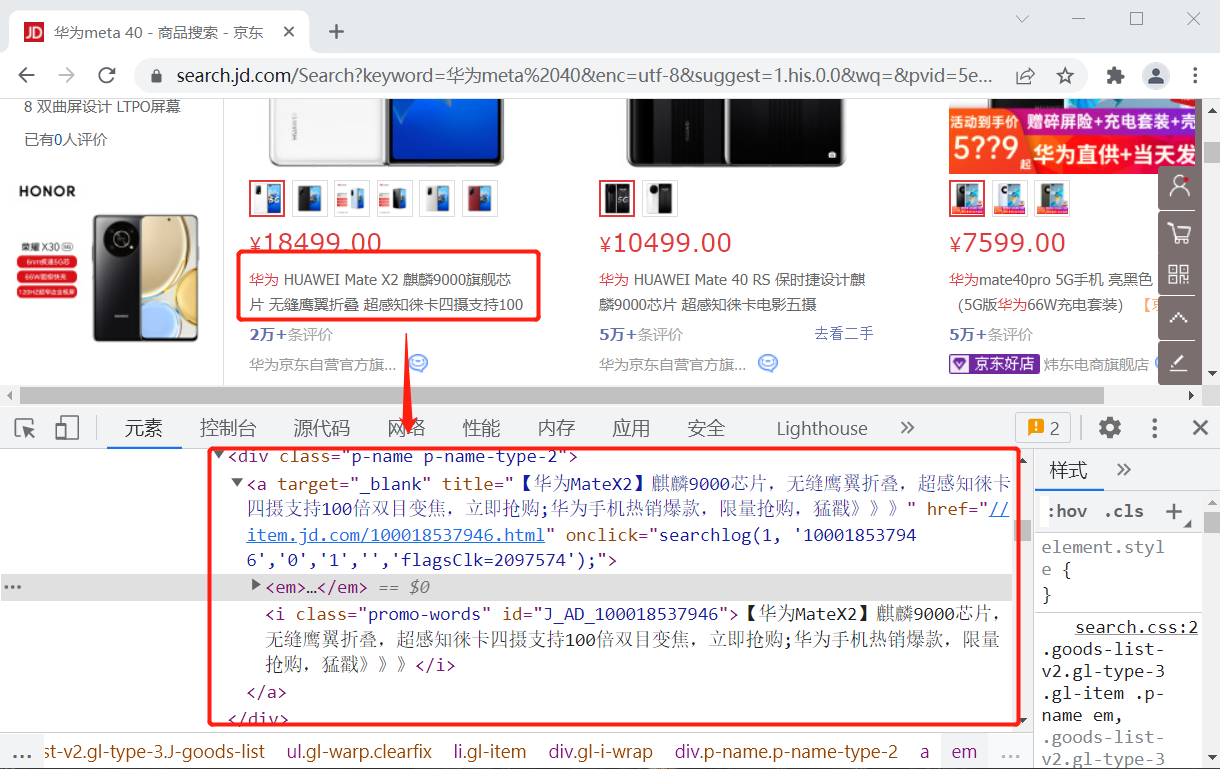
商品名信息存放在一个 div 片段中,此 div 有一个值为 p-name 的 class 属性。可以使用 CSS-NAME 方式获取,因为所有的商品采用相同片段模板,这里使用 find_elements( ) 方法即可。
product_name_divs = chrome_browser.find_elements(By.CLASS_NAME, "p-name")
find_elements 方法返回具有相同 CSS-NAME 的组件列表,编写代码迭代出每一个组件,并获取数据,然后存储在商品名称列表中。
for i in range(5): div = product_name_divs[i] if len(div.text) != 0: products_names.append(div.text)
以同样的方式,获取到价格数据。再把商品名称和价格数据制成字典,并对价格数据做简单分析。
jd_data = dict(zip(products_names, products_prices))
jd_data["平均价格"] = sum(products_prices) / len(products_prices)
jd_data["最低价格"] = min(products_prices)
jd_data["最高价格"] = max(products_prices)
csv_save("京东商城", jd_data)以 CSV 格式存储从京东商城上爬取下来的数据。

获取苏宁易购上的商品数据。与从京东上获取数据的逻辑一样(两段代码可以整合到一个函数中,为了便于理解,本文分开编写)。两者的区别在于页面结构、承载数据的页面组件不一样或组件的属性设置不一样。
def search_sn():
global sn_data
# 保存商品名称
products_names = []
# 保存商品价格
products_prices = []
# 苏宁首页
sn_index_url = r"https://www.suning.com/"
try:
if chrome_browser is None:
raise Exception()
else:
# 打开首页
chrome_browser.get(sn_index_url)
# 摸拟网络延迟
chrome_browser.implicitly_wait(10)
# 查找文本输入组件
search_input = chrome_browser.find_element(By.ID, "searchKeywords")
# 在文本框中输入商品关键字
search_input.send_keys(search_keyword)
time.sleep(2)
# 找到搜索按钮 这里使用 CSS 选择器方案
search_button = chrome_browser.find_element(By.ID, "searchSubmit")
# 触发按钮事件
search_button.click()
time.sleep(3)
# 获取所有打开的窗口(当点击按钮后应该有 2 个)
windows = chrome_browser.window_handles
# 切换新打开的窗口,使用负索引找到最后打开的窗口
chrome_browser.switch_to.window(windows[-1])
chrome_browser.implicitly_wait(20)
# 获取商品价格所在标签
product_price_divs = chrome_browser.find_elements(By.CLASS_NAME, "def-price")
# 仅查看前 5 个商品信息
for i in range(5):
div = product_price_divs[i]
# 删除价格前面的美元符号
if len(div.text) != 0:
products_prices.append(float(div.text[1:]))
chrome_browser.implicitly_wait(10)
# 获取商品名称
product_name_divs = chrome_browser.find_elements(By.CLASS_NAME, "title-selling-point")
for i in range(5):
products_names.append(product_name_divs[i].text)
#
sn_data = dict(zip(products_names, products_prices))
sn_data["平均价格"] = sum(products_prices) / len(products_prices)
sn_data["最低价格"] = min(products_prices)
sn_data["最高价格"] = max(products_prices)
# 使用 CSV 模块写入文档
csv_save("苏宁商城", sn_data)
except Exception as e:
print(e)获取到苏宁易购上的商品数据后,同样以 CSV 格式存储。
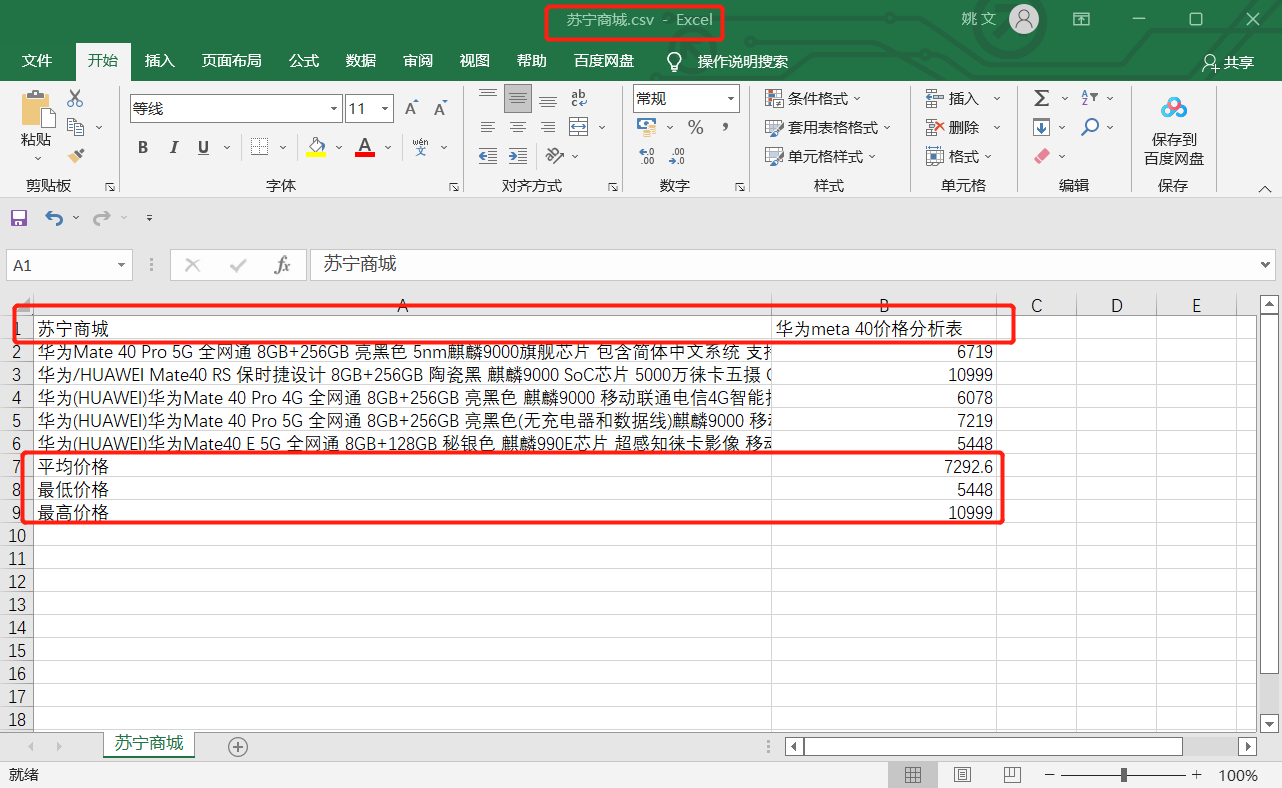
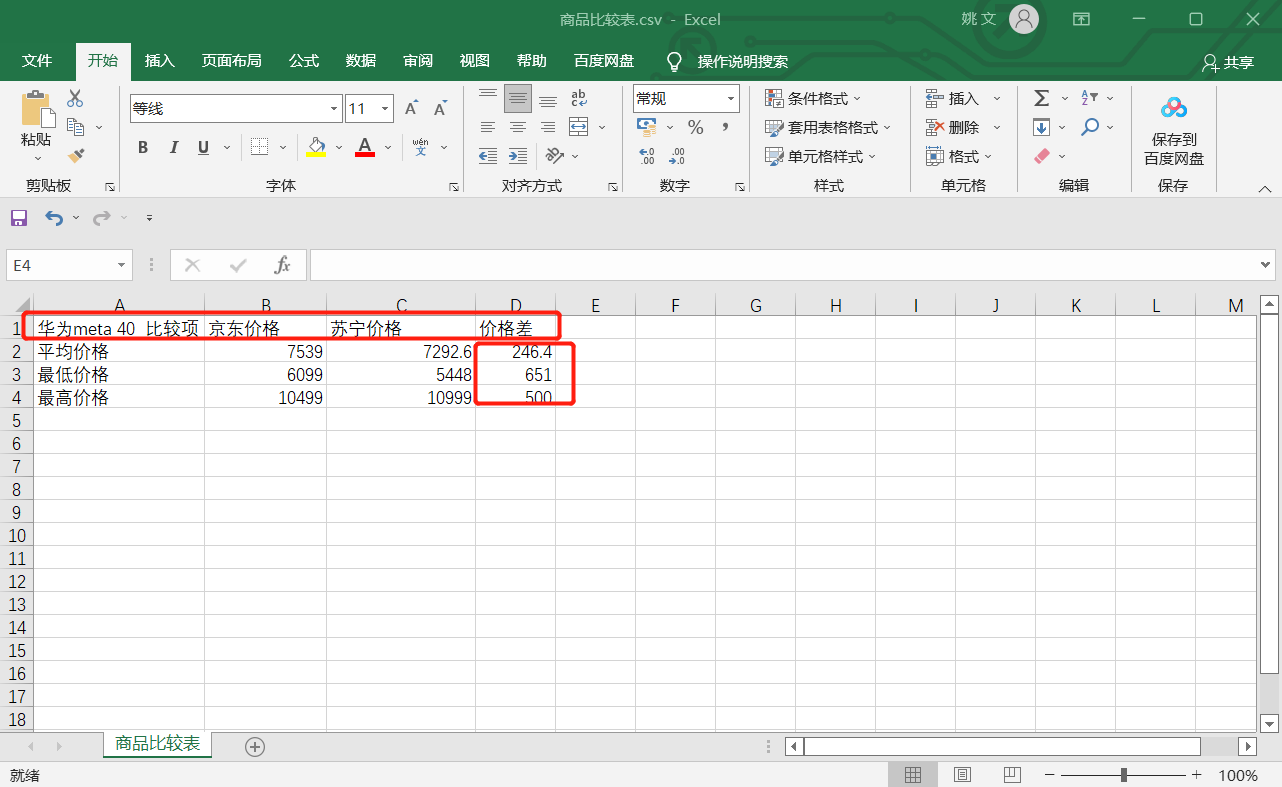
存储最终的分析结果。这里仅分析了两个商城上同类型商品的平均价格、最低价、最高价的差异性。
def price_result():
if len(jd_data) != 0 and len(sn_data) != 0:
with open("d:/商品比较表.csv", "w", newline='') as f:
csv_writer = csv.writer(f)
jd_name = list(jd_data.keys())
jd_price = list(jd_data.values())
sn_price = list(sn_data.values())
csv_writer.writerow(["比较项", "京东价格", "苏宁价格", "价格差"])
for i in range(5, len(jd_price)):
csv_writer.writerow([jd_name[i], jd_price[i], sn_price[i], math.fabs(jd_price[i] - sn_price[i])])保存了两个商城上商品价格的平均值、最小值、最大值以及绝对差。
最终测试代码
if __name__ == '__main__': search_keyword = input_search_key() chrome_browser = init_data() search_jd() time.sleep(2) search_sn() price_result()
请输入商品关键字:华为meta 40
关于“Pythonr基于selenium怎么实现不同商城的商品价格差异分析系统”这篇文章的内容就介绍到这里,感谢各位的阅读!相信大家对“Pythonr基于selenium怎么实现不同商城的商品价格差异分析系统”知识都有一定的了解,大家如果还想学习更多知识,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。