您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章将为大家详细讲解有关pandas如何进行数据输入和输出,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
read_csv():从文件、URL或文件型对象读取分隔好的数据,逗号是默认分隔符
read_table():从文件、URL或文件型对象读取分隔好的数据,制表符('\t')是默认分隔符
Windows用户打印文件的原始内容
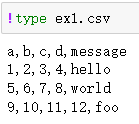
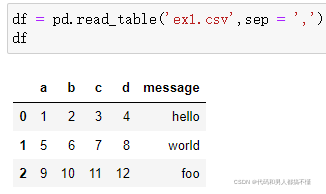
因为这个文件是逗号分隔的,我们可以使用read_csv将它读入一个DataFrame:

也可以用read_table,并指定分隔符
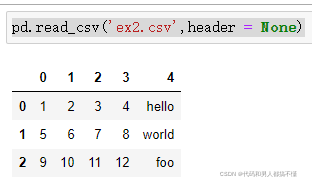
刚刚是文件包含表头行的情况,但有的文件并不包含表头行,比如
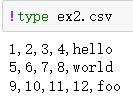
如果直接读取的话,默认将第一行作为表头了,也就是默认header=0,表示第一行为标题行。
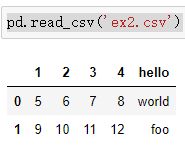
有两种方法改,
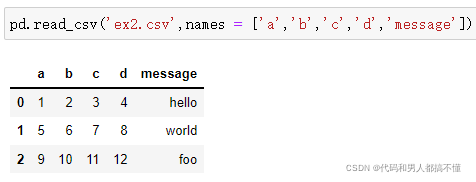
一是允许pandas自动分配默认列名,
二是自己指定列名。
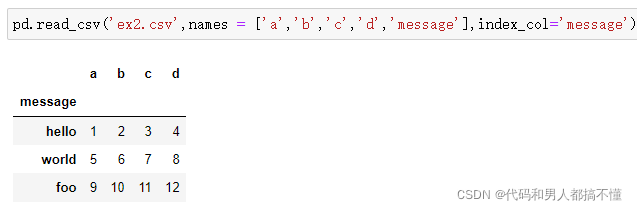
假设想要message列成为返回DataFrame的索引,可以指定位置4的列为索引,或将'message'传给参数index_col:
从多个列中形成一个分层索引

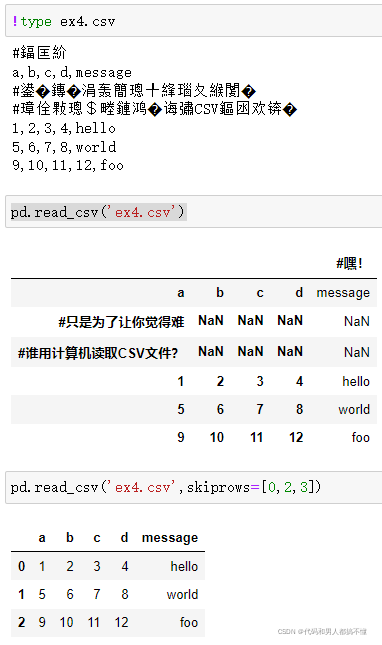
解析函数有很多附加参数处理各种发生异常的文件格式,例如,可以使用skiprows来跳过第一行,第三行,第四行。
处理缺失值
通常情况下,缺失值要么不显示(空字符串,要么用一些标识值)
默认情况下,pandas用一些常见的标识,如NaN和NULL
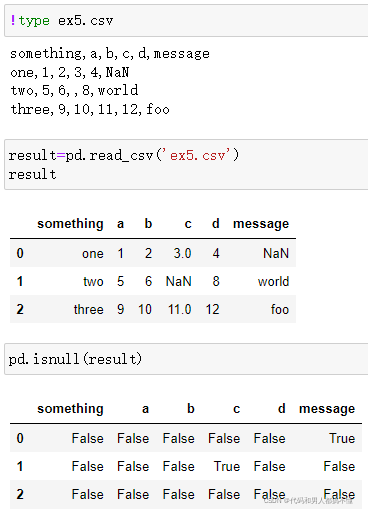
na_values选项可以传入一个列表或一组字符串来处理缺失值
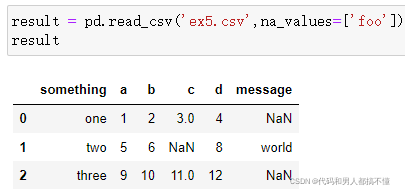
在字典中,每列可以指定不同的缺失值标识
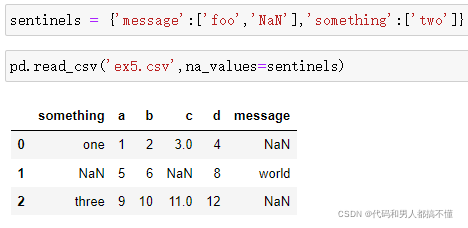
如果只想读取一小部分(避免读取整个文件),可以指明nrows

为了分块读入文件,可以指定chunksize作为每一块的行数
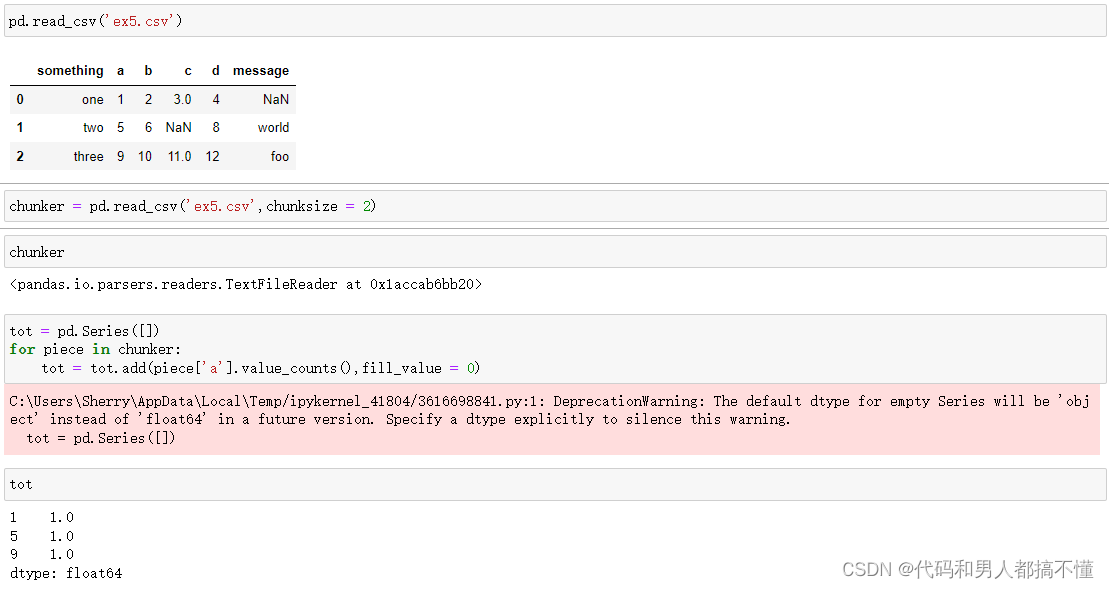
read_csv返回的TextParser对象允许根据chunksize遍历文件,并对'a'列聚合获得计数值
使用DataFrame的to_csv方法,可将数据导出为逗号分隔的文件
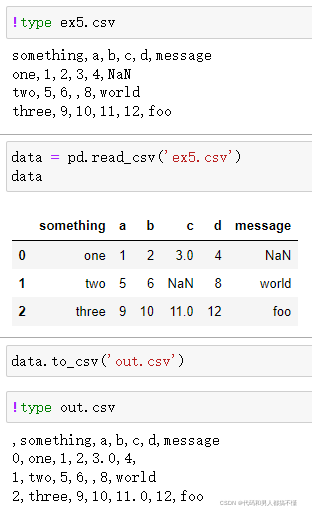
默认若是没有其他选项被指定的话,行和列的标签都会被写入,不过二者也都可以禁止写入
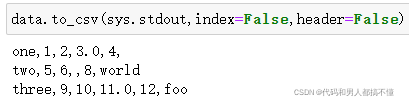
也可以仅仅写入列的子集,并且按照选择的顺序写入
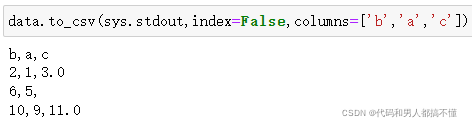
默认缺失值在输出时以空字符串出现,可以用其他标识值对缺失值进行标注
(写入到sys.stdout时,控制台中打印的文本结果)

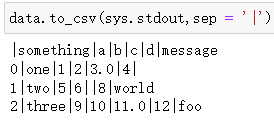
默认分隔符是逗号,可以用sep选项选择分隔符
Series也有to_csv方法
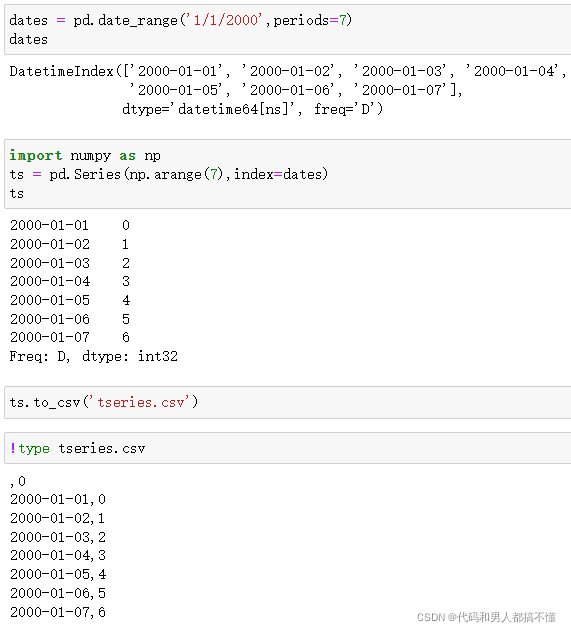
不知道为啥最后写入有,0这行????
关于“pandas如何进行数据输入和输出”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。