жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮвҖңSQL Serverдёӯзҡ„иҒҡеҗҲеҮҪж•°жҖҺд№ҲдҪҝз”ЁвҖқж–Үз« зҡ„зҹҘиҜҶзӮ№еӨ§йғЁеҲҶдәәйғҪдёҚеӨӘзҗҶи§ЈпјҢжүҖд»Ҙе°Ҹзј–з»ҷеӨ§е®¶жҖ»з»“дәҶд»ҘдёӢеҶ…е®№пјҢеҶ…е®№иҜҰз»ҶпјҢжӯҘйӘӨжё…жҷ°пјҢе…·жңүдёҖе®ҡзҡ„еҖҹйүҙд»·еҖјпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« иғҪжңүжүҖ收иҺ·пјҢдёӢйқўжҲ‘们дёҖиө·жқҘзңӢзңӢиҝҷзҜҮвҖңSQL Serverдёӯзҡ„иҒҡеҗҲеҮҪж•°жҖҺд№ҲдҪҝз”ЁвҖқж–Үз« еҗ§гҖӮ
п»ҝиҒҡеҗҲеҮҪж•°еҜ№дёҖз»„еҖјжү§иЎҢи®Ўз®—пјҢ并иҝ”еӣһеҚ•дёӘеҖјгҖӮ
йҷӨдәҶ COUNT еӨ–пјҢиҒҡеҗҲеҮҪж•°йғҪдјҡеҝҪз•Ҙ Null еҖјгҖӮ иҒҡеҗҲеҮҪж•°з»ҸеёёдёҺ SELECT иҜӯеҸҘзҡ„ GROUP BY еӯҗеҸҘдёҖиө·дҪҝз”ЁгҖӮ
OVER еӯҗеҸҘеҸҜд»Ҙи·ҹеңЁйҷӨ STRING_AGGгҖҒGROUPING жҲ– GROUPING_ID еҮҪж•°д»ҘеӨ–зҡ„жүҖжңүиҒҡеҗҲеҮҪж•°еҗҺйқўгҖӮ
еҸӘиғҪеңЁд»ҘдёӢдҪҚзҪ®е°ҶиҒҡеҗҲеҮҪж•°дҪңдёәиЎЁиҫҫејҸдҪҝз”Ёпјҡ
SELECT иҜӯеҸҘзҡ„йҖүжӢ©еҲ—иЎЁпјҲеӯҗжҹҘиҜўжҲ–еӨ–йғЁжҹҘиҜўпјүгҖӮ
HAVING еӯҗеҸҘгҖӮ
T-SQLжҸҗдҫӣзҡ„иҒҡеҗҲеҮҪж•°дёҖе…ұжңү13дёӘд№ӢеӨҡгҖӮ
avg( [ all | distinct ] expression )
AVGеҮҪж•°з”ЁдәҺи®Ўз®—зІҫзЎ®еһӢжҲ–иҝ‘дјјеһӢж•°жҚ®зұ»еһӢзҡ„е№іеқҮеҖјпјҢbitзұ»еһӢйҷӨеӨ–пјҢеҝҪз•ҘnullеҖјгҖӮAVGеҮҪж•°и®Ўз®—ж—¶е°Ҷи®Ўз®—дёҖз»„ж•°зҡ„жҖ»е’ҢпјҢ然еҗҺйҷӨд»Ҙдёәnullзҡ„дёӘж•°пјҢеҫ—еҲ°е№іеқҮеҖј
select avg(distinct age) from person -- жҹҘиҜўpersonиЎЁйҮҢзҡ„е№ҙйҫ„зҡ„е№іеқҮеҖјпјҢзӣёеҗҢеҖјеҸӘи®Ўз®—дёҖж¬Ў
MINеҮҪж•°з”ЁдәҺи®Ўз®—жңҖе°ҸеҖјпјҢMINеҮҪж•°еҸҜд»ҘйҖӮз”ЁдәҺnumericгҖҒcharгҖҒvarcharжҲ–datetimeгҖҒmoneyжҲ–smallmoneyеҲ—пјҢдҪҶдёҚиғҪз”ЁдәҺbitеҲ—гҖӮдёҚе…Ғи®ёдҪҝз”ЁиҒҡеҗҲеҮҪж•°е’ҢеӯҗжҹҘиҜўпјҢеҝҪз•ҘnullеҖјгҖӮ
MAXеҮҪж•°з”ЁдәҺи®Ўз®—жңҖеӨ§еҖјпјҢеҝҪз•ҘnullеҖјгҖӮmaxеҮҪж•°еҸҜд»ҘдҪҝз”ЁдәҺnumericгҖҒcharгҖҒvarcharгҖҒmoneyгҖҒsmallmoneyгҖҒжҲ–datetimeеҲ—пјҢдҪҶдёҚиғҪз”ЁдәҺbitеҲ—гҖӮдёҚе…Ғи®ёдҪҝз”ЁиҒҡеҗҲеҮҪж•°е’ҢеӯҗжҹҘиҜўгҖӮ
SUMеҮҪж•°з”ЁдәҺжұӮе’ҢпјҢеҸӘиғҪз”ЁдәҺзІҫзЎ®жҲ–иҝ‘дјјж•°еӯ—зұ»еһӢеҲ—(bitзұ»еһӢйҷӨеӨ–)пјҢеҝҪз•ҘnullеҖјпјҢдёҚе…Ғи®ёдҪҝз”ЁиҒҡеҗҲеҮҪж•°е’ҢеӯҗжҹҘиҜўгҖӮ
countеҮҪж•°з”ЁдәҺи®Ўз®—ж»Ўи¶іжқЎд»¶зҡ„ж•°жҚ®йЎ№ж•°пјҢиҝ”еӣһintж•°жҚ®зұ»еһӢзҡ„еҖјгҖӮиҝҷйҮҢзҡ„иЎЁиҫҫејҸжҳҜйҷӨtextгҖҒimageжҲ–ntextд»ҘеӨ–д»»дҪ•ж•°жҚ®зұ»еһӢзҡ„иЎЁиҫҫејҸгҖӮдҪҶдёҚе…Ғи®ёдҪҝз”ЁиҒҡеҗҲеҮҪж•°е’ҢеӯҗжҹҘиҜўгҖӮ
count(*) пјҡ иҝ”еӣһжүҖжңүзҡ„йЎ№ж•°пјҢеҢ…жӢ¬nullеҖје’ҢйҮҚеӨҚйЎ№гҖӮиҖҢйҷӨдәҶcount(*)еӨ–пјҢе…¶д»–д»»дҪ•еҪўејҸзҡ„count()еҮҪж•°йғҪдјҡеҝҪз•ҘNullиЎҢгҖӮ
count(all иЎЁиҫҫејҸ)пјҡиҝ”еӣһйқһз©әзҡ„йЎ№ж•°гҖӮ
count(distinct иЎЁиҫҫејҸ)пјҡиҝ”еӣһе”ҜдёҖйқһз©әзҡ„йЎ№ж•°
жіЁж„Ҹпјҡcount(еӯ—ж®өеҗҚ)пјҢеҰӮжһңеӯ—ж®өеҗҚдёәNULLпјҢеҲҷcountеҮҪж•°дёҚдјҡз»ҹи®ЎгҖӮдҫӢеҰӮcount(name)пјҢеҰӮжһңnameдёәз©әпјҢеҲҷдёҚдјҡз»ҹи®ЎеҲ°з»“жһң
select count(distinct age) from person -- жҹҘиҜўpersonиЎЁйҮҢзҡ„е№ҙйҫ„е”ҜдёҖдё”йқһз©әзҡ„йЎ№ж•°
иҝ”еӣһз»„дёӯзҡ„йЎ№ж•°гҖӮ COUNT_BIG зҡ„з”Ёжі•дёҺ COUNT еҮҪж•°зұ»дјјгҖӮ дёӨдёӘеҮҪж•°е”ҜдёҖзҡ„е·®еҲ«жҳҜе®ғ们зҡ„иҝ”еӣһеҖјгҖӮ COUNT_BIG е§Ӣз»Ҳиҝ”еӣһ bigint ж•°жҚ®зұ»еһӢеҖјгҖӮ COUNT е§Ӣз»Ҳиҝ”еӣһ int ж•°жҚ®зұ»еһӢеҖјгҖӮ
иҝҷйҮҢзҡ„expressionеҝ…йЎ»жҳҜдёҖдёӘж•°еҖјиЎЁиҫҫејҸпјҢдёҚе…Ғи®ёдҪҝз”ЁиҒҡеҗҲеҮҪж•°е’ҢеӯҗжҹҘиҜўгҖӮиЎЁиҫҫејҸзҡ„еҖјжҳҜзІҫзЎ®жҲ–иҝ‘дјјж•°еҖјзұ»еһӢпјҢдҪҶдёҚеҢ…жӢ¬bitж•°жҚ®зұ»еһӢгҖӮе°ҶеҝҪз•ҘnullеҖјгҖӮ
иҝ”еӣһжҢҮе®ҡиЎЁиҫҫејҸдёӯжүҖжңүеҖјзҡ„жҖ»дҪ“ж ҮеҮҶеҒҸе·®гҖӮ
VARеҮҪж•°з”ЁдәҺи®Ўз®—жҢҮе®ҡиЎЁиҫҫејҸдёӯжүҖжңүеҖјзҡ„ж–№е·®гҖӮгҖҖиҝҷйҮҢзҡ„expressionиЎЁиҫҫејҸеҝ…йЎ»жҳҜдёҖдёӘж•°еҖјиЎЁиҫҫејҸпјҢдёҚе…Ғи®ёдҪҝз”ЁиҒҡеҗҲеҮҪж•°е’ҢеӯҗжҹҘиҜўгҖӮиЎЁиҫҫејҸзҡ„еҖјжҳҜзІҫзЎ®жҲ–иҝ‘дјјж•°еҖјзұ»еһӢпјҢдҪҶдёҚеҢ…жӢ¬bitж•°жҚ®зұ»еһӢпјҢе°ҶеҝҪз•ҘnullеҖјгҖӮ
иҝ”еӣһжҢҮе®ҡиЎЁиҫҫејҸдёӯжүҖжңүеҖјзҡ„жҖ»дҪ“з»ҹи®Ўж–№е·®гҖӮ
иҝ”еӣһз»„дёӯеҗ„еҖјзҡ„ж ЎйӘҢе’ҢгҖӮ е°ҶеҝҪз•Ҙ Null еҖјгҖӮCHECKSUM_AGG еҸҜз”ЁдәҺжЈҖжөӢиЎЁдёӯзҡ„жӣҙж”№гҖӮиЎЁдёӯиЎҢзҡ„йЎәеәҸдёҚеҪұе“Қ CHECKSUM_AGG зҡ„з»“жһңгҖӮжӯӨеӨ–пјҢCHECKSUM_AGG еҮҪж•°иҝҳеҸҜдёҺ DISTINCT е…ій”®еӯ—е’Ң GROUP BY еӯҗеҸҘдёҖиө·дҪҝз”ЁгҖӮеҰӮжһңиЎЁиҫҫејҸеҲ—иЎЁдёӯзҡ„жҹҗдёӘеҖјеҸ‘з”ҹжӣҙж”№пјҢеҲҷеҲ—иЎЁзҡ„ж ЎйӘҢе’ҢйҖҡеёёд№ҹдјҡжӣҙж”№гҖӮдҪҶеҸӘеңЁжһҒе°‘ж•°жғ…еҶөдёӢпјҢж ЎйӘҢеҖјдјҡдҝқжҢҒдёҚеҸҳгҖӮ
CHECKSUM_AGG ( [ ALL | DISTINCT ] expression )
еҸӮж•°иҜҙжҳҺпјҡгҖҖ
ALLпјҡеҜ№жүҖжңүзҡ„еҖјиҝӣиЎҢиҒҡеҗҲеҮҪж•°иҝҗз®—гҖӮ ALL дёәй»ҳи®ӨеҖјгҖӮ
DISTINCT пјҡжҢҮе®ҡ CHECKSUM_AGG иҝ”еӣһе”ҜдёҖж ЎйӘҢеҖјгҖӮ
expression пјҡдёҖдёӘж•ҙж•°иЎЁиҫҫејҸгҖӮ дёҚе…Ғи®ёдҪҝз”ЁиҒҡеҗҲеҮҪж•°е’ҢеӯҗжҹҘиҜўгҖӮ
SELECT CHECKSUM_AGG(Account_Age) FROM Account GO UPDATE Account SET Account_Age = 30 WHERE Account_Id = 6 GO SELECT CHECKSUM_AGG(Account_Age) FROM Account
жҳҫзӨәз»“жһңеҰӮдёӢпјҡ
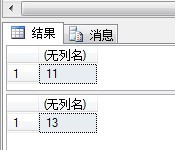
еҸҜи§ҒйҡҸзқҖиЎЁзҡ„жӣҙж”№пјҢиҜҘзі»з»ҹеҮҪж•°иҝ”еӣһзҡ„еҖјд№ҹеҸҳдәҶгҖӮжӯӨеҮҪж•°зҡ„дҪңз”ЁжӯЈеңЁдәҺжӯӨпјҢжЈҖжөӢиЎЁзҡ„жӣҙж”№гҖӮ
MS SQL Serverзҡ„2017ж–°еўһдәҶSTRING_AGG()жҳҜдёҖдёӘиҒҡеҗҲеҮҪж•°пјҢе®ғе°Ҷз”ұжҢҮе®ҡзҡ„еҲҶйҡ”з¬ҰеҲҶйҡ”е°Ҷеӯ—з¬ҰдёІиЎҢиҝһжҺҘжҲҗдёҖдёӘеӯ—з¬ҰдёІгҖӮ е®ғдёҚдјҡеңЁз»“жһңеӯ—з¬ҰдёІзҡ„жң«е°ҫж·»еҠ еҲҶйҡ”з¬ҰгҖӮ
д»ҘдёӢжҳҜSTRING_AGG()еҮҪж•°зҡ„иҜӯжі•пјҡ
STRING_AGG ( input_string, separator ) [ order_clause ]
еңЁиҝҷдёӘиҜӯжі•дёӯпјҡ
input_stringжҳҜдёІиҒ”ж—¶еҸҜд»ҘиҪ¬жҚўдёәVARCHARе’ҢNVARCHARзҡ„зұ»еһӢгҖӮ
separatorжҳҜз»“жһңеӯ—з¬ҰдёІзҡ„еҲҶйҡ”з¬ҰгҖӮе®ғеҸҜд»ҘжҳҜж–Үеӯ—жҲ–еҸҳйҮҸгҖӮ
order_clauseдҪҝз”ЁWITHIN GROUPеӯҗеҸҘжҢҮе®ҡиҝһжҺҘз»“жһңзҡ„жҺ’еәҸйЎәеәҸпјҡ
WITHIN GROUP ( ORDER BY expression [ ASC | DESC ] )
STRING_AGG()еҝҪз•ҘNULLпјҢ并且еңЁжү§иЎҢиҝһжҺҘж—¶дёҚдјҡдёәNULLж·»еҠ еҲҶйҡ”з¬ҰгҖӮ
дёӢйқўе°ҶдҪҝз”ЁзӨәдҫӢж•°жҚ®еә“дёӯзҡ„sales.customersиЎЁиҝӣиЎҢжј”зӨәпјҡ
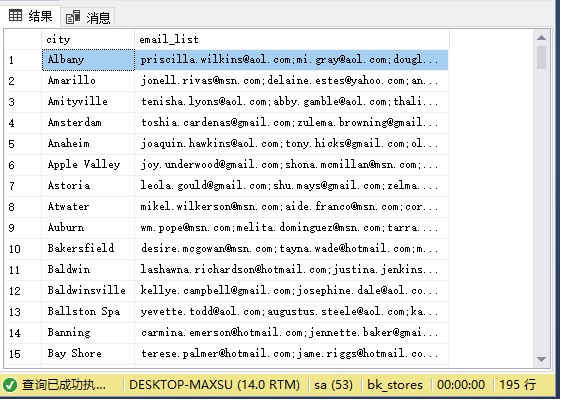
жӯӨзӨәдҫӢдҪҝз”ЁSTRING_AGG()еҮҪж•°з”ҹжҲҗеҹҺеёӮе®ўжҲ·зҡ„з”өеӯҗйӮ®д»¶еҲ—иЎЁпјҡ
SELECT city, STRING_AGG(email,';') email_list FROM sales.customers GROUP BY city;
жү§иЎҢдёҠйқўжҹҘиҜўиҜӯеҸҘпјҢеҫ—еҲ°д»ҘдёӢз»“жһңпјҡ
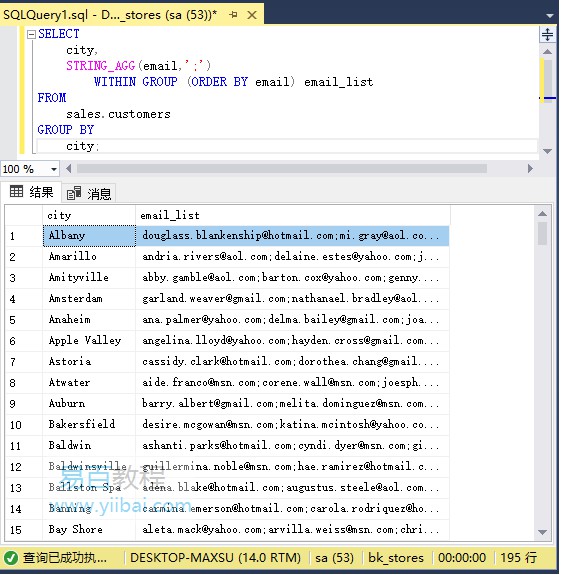
иҰҒеҜ№emailеҲ—иЎЁиҝӣиЎҢжҺ’еәҸпјҢиҜ·дҪҝз”ЁWITHIN GROUPеӯҗеҸҘпјҡ
SELECT city, STRING_AGG(email,';') WITHIN GROUP (ORDER BY email) email_list FROM sales.customers GROUP BY city;
жү§иЎҢдёҠйқўжҹҘиҜўиҜӯеҸҘпјҢеҫ—еҲ°д»ҘдёӢз»“жһңпјҡ
жіЁж„ҸпјҡSTRING_SPLITпјҲпјүеҮҪж•°пјҡдёҖдёӘиЎЁеҖјеҮҪж•°пјҢе®ғж №жҚ®жҢҮе®ҡзҡ„еҲҶйҡ”з¬Ұе°Ҷеӯ—з¬ҰдёІжӢҶеҲҶдёәеӯҗеӯ—з¬ҰдёІиЎҢгҖӮ
SELECT value FROM STRING_SPLIT('Lorem ipsum dolor sit amet.', ' ');SQL Server 2019еј•е…ҘдәҶж–°еҮҪж•°Approx_Count_distinctд»ҘжҸҗдҫӣиЎҢзҡ„иҝ‘дјји®Ўж•°гҖӮCountпјҲdistinctпјҲпјүпјүеҮҪж•°жҸҗдҫӣе®һйҷ…зҡ„иЎҢж•°гҖӮ
иҜҘеҮҪж•°APPROX_COUNT_DISTINCTеә”иҜҘдҪҝз”Ёиҫғе°‘зҡ„еҶ…еӯҳе’ҢCPUиө„жәҗпјҢд»ҘдҫҝеҸҜд»ҘиҺ·еҸ–ж•°жҚ®з»“жһңиҖҢдёҚдјҡеҮәзҺ°д»»дҪ•й—®йўҳпјҢдҫӢеҰӮжәўеҮәеҲ°зЈҒзӣҳжҲ–CPUеі°еҖјгҖӮиҝҷеҜ№дәҺж•°еҚҒдәҝиЎҢзҡ„йңҖжұӮеҫҲжңүз”ЁгҖӮ
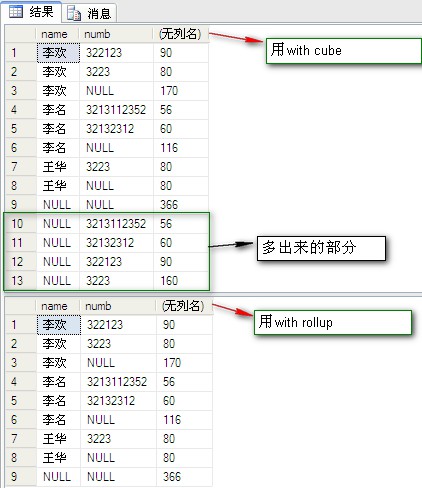
CUBE з”ҹжҲҗзҡ„з»“жһңйӣҶжҳҫзӨәдәҶжүҖйҖүеҲ—дёӯеҖјзҡ„жүҖжңүз»„еҗҲзҡ„иҒҡеҗҲгҖӮ
ROLLUP з”ҹжҲҗзҡ„з»“жһңйӣҶжҳҫзӨәдәҶжүҖйҖүеҲ—дёӯеҖјзҡ„жҹҗдёҖеұӮж¬Ўз»“жһ„зҡ„иҒҡеҗҲгҖӮ
жҹҘиҜўеҮәжҸ’е…Ҙзҡ„е…ЁйғЁж•°жҚ®пјҡ
select * from dbo.PeopleInfo
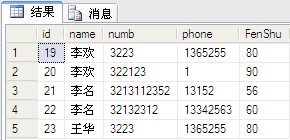
select [name],numb,sum(fenshu) from dbo.PeopleInfo group by [name],numb //з”Ёgroup by select [name],numb,sum(fenshu) from dbo.PeopleInfo group by [name],numb with cube; //з”Ёwith cube select [name],numb,sum(fenshu) from dbo.PeopleInfo group by [name],numb with rollup //з”Ёwith rollup
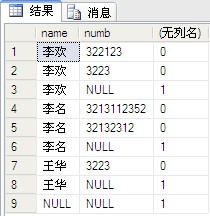
еҪ“иЎҢз”ұ CUBE жҲ– ROLLUP иҝҗз®—з¬Ұж·»еҠ ж—¶пјҢиҜҘеҮҪж•°е°ҶеҜјиҮҙйҷ„еҠ еҲ—зҡ„иҫ“еҮәеҖјдёә 1пјӣеҪ“иЎҢдёҚз”ұ CUBE жҲ– ROLLUP иҝҗз®—з¬Ұж·»еҠ ж—¶пјҢиҜҘеҮҪж•°е°ҶеҜјиҮҙйҷ„еҠ еҲ—зҡ„иҫ“еҮәеҖјдёә 0гҖӮ
д»…еңЁдёҺеҢ…еҗ« CUBE жҲ– ROLLUP иҝҗз®—з¬Ұзҡ„ GROUP BY еӯҗеҸҘзӣёе…іиҒ”зҡ„йҖүжӢ©еҲ—иЎЁдёӯжүҚе…Ғи®ёеҲҶз»„гҖӮ
select [name],numb,grouping(numb) from dbo.PeopleInfo group by [name],numb with rollup
д»…еҪ“жҢҮе®ҡдәҶ GROUP BY ж—¶пјҢGROUPING_ID жүҚиғҪеңЁ SELECT еҲ—иЎЁгҖҒHAVING жҲ– ORDER BY еӯҗеҸҘдёӯдҪҝз”ЁгҖӮ дҪҝз”Ё GROUPING_ID ж ҮиҜҶеҲҶз»„зә§еҲ«дёӢйқўзҡ„зӨәдҫӢиҝ”еӣһжҢү AdventureWorks2012 ж•°жҚ®еә“зҡ„ Name е’Ң Title жұҮжҖ»зҡ„йӣҮе‘ҳи®Ўж•°д»ҘеҸҠ Name, е’Ңе…¬еҸёжҖ»и®ЎгҖӮ GROUPING_ID() з”ЁдәҺдёә Title еҲ—дёӯзҡ„жҜҸиЎҢеҲӣе»әдёҖдёӘеҖјд»Ҙж ҮиҜҶиҒҡеҗҲзә§еҲ«гҖӮ
SELECT D.Name ,CASE WHEN GROUPING_ID(D.Name, E.JobTitle) = 0 THEN E.JobTitle WHEN GROUPING_ID(D.Name, E.JobTitle) = 1 THEN N'Total: ' + D.Name WHEN GROUPING_ID(D.Name, E.JobTitle) = 3 THEN N'Company Total:' ELSE N'Unknown' END AS N'Job Title' ,COUNT(E.BusinessEntityID) AS N'Employee Count' FROM HumanResources.Employee E INNER JOIN HumanResources.EmployeeDepartmentHistory DH ON E.BusinessEntityID = DH.BusinessEntityID INNER JOIN HumanResources.Department D ON D.DepartmentID = DH.DepartmentID WHERE DH.EndDate IS NULL AND D.DepartmentID IN (12,14) GROUP BY ROLLUP(D.Name, E.JobTitle);
еҫҲеӨҡиҒҡеҗҲеҮҪж•°йғҪеҸҜд»Ҙз”ЁдҪңзӘ—еҸЈеҮҪж•°зҡ„иҝҗз®—пјҢеҰӮSUM,AVG,MAX,MINгҖӮиҒҡеҗҲејҖзӘ—еҮҪж•°еҸӘиғҪдҪҝз”ЁPARTITION BYеӯҗеҸҘжҲ–йғҪдёҚеёҰд»»дҪ•иҜӯеҸҘпјҢORDER BYдёҚиғҪдёҺиҒҡеҗҲејҖзӘ—еҮҪж•°дёҖеҗҢдҪҝз”ЁгҖӮдҫӢеҰӮпјҢжҹҘиҜўйӣҮе‘ҳзҡ„е®ҡеҚ•жҖ»ж•°еҸҠе®ҡеҚ•дҝЎжҒҜгҖӮ
WITH OrderInfo AS ( SELECT COUNT(OrderID) OVER(PARTITION BY EmployeeID) AS TotalCount,OrderID,CustomerID, EmployeeID,OrderDate FROM Orders (NOLOCK) ) SELECT OrderID,CustomerID, EmployeeID ,OrderDate,TotalCount From OrderInfo ORDER BY EmployeeID
еҰӮжһңзӘ—еҸЈеҮҪж•°дёҚдҪҝз”ЁPARTITION BY иҜӯеҸҘзҡ„иҜқпјҢйӮЈд№Ҳе°ұжҳҜдёҚеҜ№ж•°жҚ®иҝӣиЎҢеҲҶз»„пјҢиҒҡеҗҲеҮҪж•°и®Ўз®—жүҖжңүзҡ„иЎҢзҡ„еҖјгҖӮ
WITH OrderInfo AS ( SELECT COUNT(OrderID) OVER() AS Count,OrderID,CustomerID, EmployeeID,OrderDate FROM Orders (NOLOCK) )
д»ҘдёҠе°ұжҳҜе…ідәҺвҖңSQL Serverдёӯзҡ„иҒҡеҗҲеҮҪж•°жҖҺд№ҲдҪҝз”ЁвҖқиҝҷзҜҮж–Үз« зҡ„еҶ…е®№пјҢзӣёдҝЎеӨ§е®¶йғҪжңүдәҶдёҖе®ҡзҡ„дәҶи§ЈпјҢеёҢжңӣе°Ҹзј–еҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүеё®еҠ©пјҢиӢҘжғідәҶи§ЈжӣҙеӨҡзӣёе…ізҡ„зҹҘиҜҶеҶ…е®№пјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ