您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本文小编为大家详细介绍“如何利用Python实现模拟登录知乎”,内容详细,步骤清晰,细节处理妥当,希望这篇“如何利用Python实现模拟登录知乎”文章能帮助大家解决疑惑,下面跟着小编的思路慢慢深入,一起来学习新知识吧。
在抓包的时候,开始使用的是Chrome开发工具中的Network,结果没有抓到,后来使用Fiddler成功抓取数据。下面逐步来细化上述过程。
模拟知乎登录前,先看看本次案例使用的环境及其工具:
Windows 7 + Python 2.75
Chrome + Fiddler: 用来监控客户端与服务器的通讯情况,以及查找相关参数的位置。
使用Google浏览器结合Fiddler来监控客户端与服务端的通讯过程;
根据监控结果,构造请求服务器过程中传递的参数;
使用Python模拟参数传递过程。
客户端与服务端通信过程的几个关键点:
登录时的url地址。
登录时提交的参数【params】,获取方式主要有两种:第一、分析页面源代码,找到表单标签及属性。适应比较简单的页面。第二、使用抓包工具,查看提交的url和参数,通常使用的是Chrome的开发者工具中的Network, Fiddler等。
登录后跳转的url。
首先看看这个登录页面,也就是我们登录时的url地址。
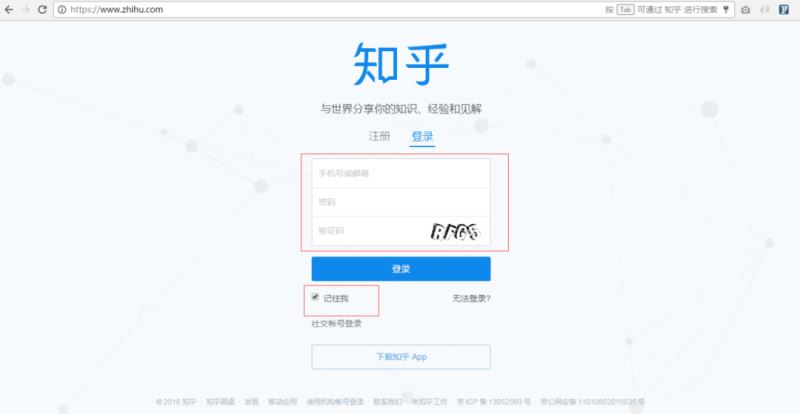
看到这个页面,我们也可以大概猜测下请求服务器时传递了几个字段,很明显有:用户名、密码、验证码以及“记住我”这几个值。那么实际上有哪些呢?下面来分分析下。
首先查看一下HTML源码,Google里可以使用CTRL+U查看,然后使用CTRL+F输入input看看有哪些字段值,详情如下:
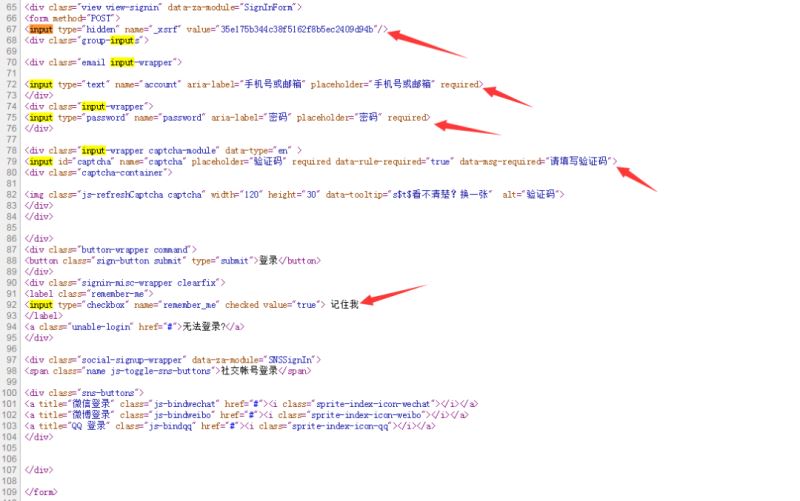
通过源码,我们可以看到,在请求服务器的过程中还携带了一个隐藏字段”_xsrf”。那么现在的问题是:这些参数在传递时是以什么名字传递的呢?这就需要借用其他工具抓包进行分析了。笔者是Windows系统,这里使用的是Fiddler(当然,你也可以使用其他的)。
抓包过程比较繁琐,因为抓到的东西比较多,很难快速的找到需要的信息。关于fiddler,很容易使用,有过不会,可以去百度搜一下。为了防止其他信息干扰,我们先将fiddler中的记录清除,然后输入用户名(笔者使用的是邮箱登录)、密码等信息登录,相应的在fiddler中会有如下结果:
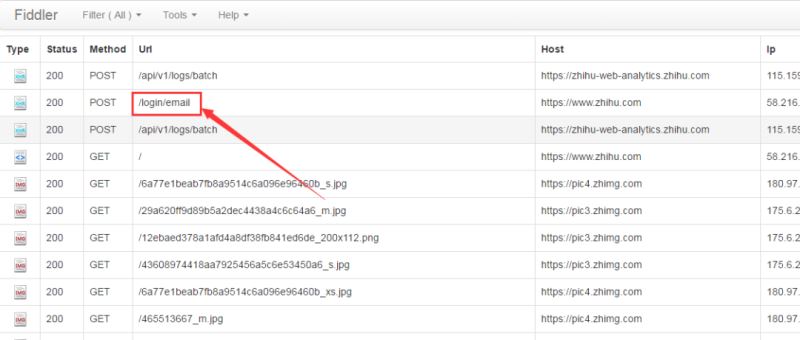
备注:如果是使用手机登录,则对应fiddler中的url是“/login/phone_num”。
为了查看详细的请求参数,我们左键单机“/login/email”,可以看到下列信息:
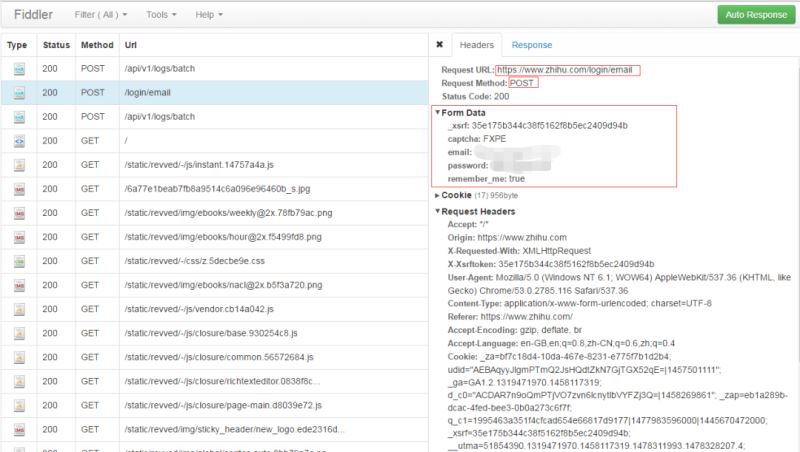
请求方式为POST,请求的url为https://www.zhihu.com/login/email。而从From Data可以看出,相应的字段名称如下:
_xsrf
captcha
password
remember
对于这五个字段,代码中email、password以及captcha都是手动输入的,remember初始化为true。剩下的_xsrf则可以根据登录页面的源文件,取input为_xsrf的value值即可。
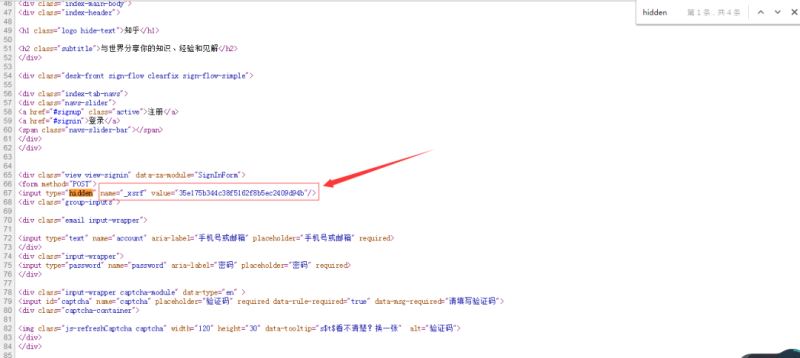
对于验证码,则需要通过额外的请求,该链接可以通过定点查看源码看出:
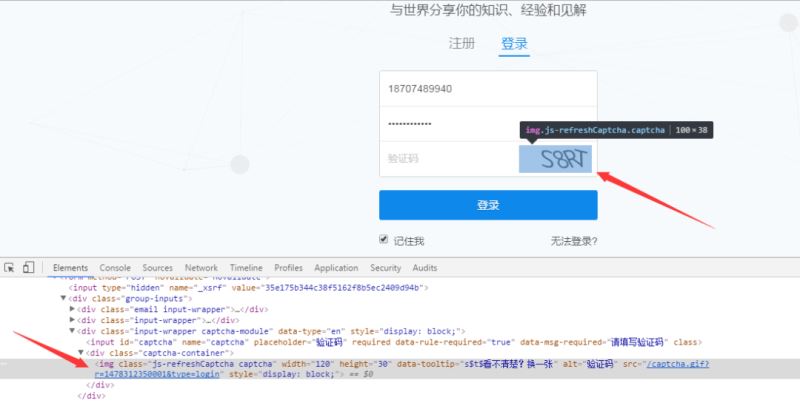
链接为https://www.zhihu.com/captcha.gif?type=login,这里省略了ts(经测试,可省略掉)。现在,可以使用代码进行模拟登录。
温馨提示:如果使用的是手机号码进行登录,则请求的url为https://www.zhihu.com/login/phone_num,同时email字段名称将变成“phone_num”。
在编写代码实现知乎登录的过程中,笔者将一些功能封装成了一个简单的类WSpider,以便复用,文件名称为WSpider.py。
# -*- coding: utf-8 -*-
"""
Created on Thu Nov 02 14:01:17 2016
@author: liudiwei
"""
import urllib
import urllib2
import cookielib
import logging
class WSpider(object):
def __init__(self):
#init params
self.url_path = None
self.post_data = None
self.header = None
self.domain = None
self.operate = None
#init cookie
self.cookiejar = cookielib.LWPCookieJar()
self.opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(self.cookiejar))
urllib2.install_opener(self.opener)
def setRequestData(self, url_path=None, post_data=None, header=None):
self.url_path = url_path
self.post_data = post_data
self.header = header
def getHtmlText(self, is_cookie=False):
if self.post_data == None and self.header == None:
request = urllib2.Request(self.url_path)
else:
request = urllib2.Request(self.url_path, urllib.urlencode(self.post_data), self.header)
response = urllib2.urlopen(request)
if is_cookie:
self.operate = self.opener.open(request)
resText = response.read()
return resText
"""
Save captcha to local
"""
def saveCaptcha(self, captcha_url, outpath, save_mode='wb'):
picture = self.opener.open(captcha_url).read() #用openr访问验证码地址,获取cookie
local = open(outpath, save_mode)
local.write(picture)
local.close()
def getHtml(self, url):
page = urllib.urlopen(url)
html = page.read()
return html
"""
功能:将文本内容输出至本地
@params
content:文本内容
out_path: 输出路径
"""
def output(self, content, out_path, save_mode="w"):
fw = open(out_path, save_mode)
fw.write(content)
fw.close()
"""#EXAMPLE
logger = createLogger('mylogger', 'temp/logger.log')
logger.debug('logger debug message')
logger.info('logger info message')
logger.warning('logger warning message')
logger.error('logger error message')
logger.critical('logger critical message')
"""
def createLogger(self, logger_name, log_file):
# 创建一个logger
logger = logging.getLogger(logger_name)
logger.setLevel(logging.INFO)
# 创建一个handler,用于写入日志文件
fh = logging.FileHandler(log_file)
# 再创建一个handler,用于输出到控制台
ch = logging.StreamHandler()
# 定义handler的输出格式formatter
formatter = logging.Formatter('%(asctime)s | %(name)s | %(levelname)s | %(message)s')
fh.setFormatter(formatter)
ch.setFormatter(formatter)
# 给logger添加handler
logger.addHandler(fh)
logger.addHandler(ch)
return logger关于模拟登录知乎的源码,保存在zhiHuLogin.py文件,内容如下:
# -*- coding: utf-8 -*-
"""
Created on Thu Nov 02 17:07:17 2016
@author: liudiwei
"""
import urllib
from WSpider import WSpider
from bs4 import BeautifulSoup as BS
import getpass
import json
import WLogger as WLog
"""
2016.11.03 由于验证码问题暂时无法正常登陆
2016.11.04 成功登录,期间出现下列问题
验证码错误返回:{ "r": 1, "errcode": 1991829, "data": {"captcha":"验证码错误"}, "msg": "验证码错误" }
验证码过期:{ "r": 1, "errcode": 1991829, "data": {"captcha":"验证码回话无效 :(","name":"ERR_VERIFY_CAPTCHA_SESSION_INVALID"}, "msg": "验证码回话无效 :(" }
登录:{"r":0, "msg": "登录成功"}
"""
def zhiHuLogin():
spy = WSpider()
logger = spy.createLogger('mylogger', 'temp/logger.log')
homepage = r"https://www.zhihu.com/"
html = spy.opener.open(homepage).read()
soup = BS(html, "html.parser")
_xsrf = soup.find("input", {'type':'hidden'}).get("value")
#根据email和手机登陆得到的参数名不一样,email登陆传递的参数是‘email',手机登陆传递的是‘phone_num'
username = raw_input("Please input username: ")
password = getpass.getpass("Please input your password: ")
account_name = None
if "@" in username:
account_name = 'email'
else:
account_name = 'phone_num'
#保存验证码
logger.info("save captcha to local machine.")
captchaURL = r"https://www.zhihu.com/captcha.gif?type=login" #验证码url
spy.saveCaptcha(captcha_url=captchaURL, outpath="temp/captcha.jpg") #temp目录需手动创建
#请求的参数列表
post_data = {
'_xsrf': _xsrf,
account_name: username,
'password': password,
'remember_me': 'true',
'captcha':raw_input("Please input captcha: ")
}
#请求的头内容
header ={
'Accept':'*/*' ,
'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',
'X-Requested-With':'XMLHttpRequest',
'Referer':'https://www.zhihu.com/',
'Accept-Language':'en-GB,en;q=0.8,zh-CN;q=0.6,zh;q=0.4',
'Accept-Encoding':'gzip, deflate, br',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36',
'Host':'www.zhihu.com'
}
url = r"https://www.zhihu.com/login/" + account_name
spy.setRequestData(url, post_data, header)
resText = spy.getHtmlText()
jsonText = json.loads(resText)
if jsonText["r"] == 0:
logger.info("Login success!")
else:
logger.error("Login Failed!")
logger.error("Error info ---> " + jsonText["msg"])
text = spy.opener.open(homepage).read() #重新打开主页,查看源码可知此时已经处于登录状态
spy.output(text, "out/home.html") #out目录需手动创建
if __name__ == '__main__':
zhiHuLogin()关于源码的分析,可以参考代码中的注解。
在控制台中运行python zhiHuLogin.py,然后按提示输入相应的内容,最后可得到以下不同的结果(举了三个实例):



读到这里,这篇“如何利用Python实现模拟登录知乎”文章已经介绍完毕,想要掌握这篇文章的知识点还需要大家自己动手实践使用过才能领会,如果想了解更多相关内容的文章,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。