您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本篇内容介绍了“python中怎么使用tensorflow实现数据下载与读取”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
深度学习的入门实例,一般就是mnist手写数字分类识别,因此我们应该先下载这个数据集。
tensorflow提供一个input_data.py文件,专门用于下载mnist数据,我们直接调用就可以了,代码如下:
import tensorflow.examples.tutorials.mnist.input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)执行完成后,会在当前目录下新建一个文件夹MNIST_data, 下载的数据将放入这个文件夹内。下载的四个文件为:
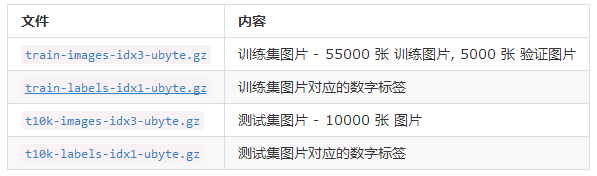
input_data文件会调用一个maybe_download函数,确保数据下载成功。这个函数还会判断数据是否已经下载,如果已经下载好了,就不再重复下载。
下载下来的数据集被分三个子集:5.5W行的训练数据集(mnist.train),5千行的验证数据集(mnist.validation)和1W行的测试数据集(mnist.test)。因为每张图片为28x28的黑白图片,所以每行为784维的向量。
每个子集都由两部分组成:图片部分(images)和标签部分(labels), 我们可以用下面的代码来查看 :
print mnist.train.images.shape print mnist.train.labels.shape print mnist.validation.images.shape print mnist.validation.labels.shape print mnist.test.images.shape print mnist.test.labels.shape
如果想在spyder编辑器中查看具体数值,可以将这些数据提取为变量来查看,如:
val_data=mnist.validation.images val_label=mnist.validation.labels
除了mnist手写字体图片数据,tf还提供了几个csv的数据供大家练习,存放路径为:
/home/xxx/anaconda3/lib/python3.5/site-packages/tensorflow/contrib/learn/python/learn/datasets/data/text_train.csv
如果要将这些数据读出来,可用代码:
import tensorflow.contrib.learn.python.learn.datasets.base as base iris_data,iris_label=base.load_iris() house_data,house_label=base.load_boston()
前者为iris鸢尾花卉数据集,后者为波士顿房价数据。
tf提供了cifar10数据的下载和读取的函数,我们直接调用就可以了。执行下列代码:
import tensorflow.models.image.cifar10.cifar10 as cifar10 cifar10.maybe_download_and_extract() images, labels = cifar10.distorted_inputs() print images print labels
就可以将cifar10下载并读取出来。
“python中怎么使用tensorflow实现数据下载与读取”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。