您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要讲解了“Python疫情数据可视化分析怎么实现”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Python疫情数据可视化分析怎么实现”吧!
本项目主要通过python的matplotlib pandas pyecharts等库对疫情数据进行可视化分析
数据来源:
本数据集来源于kaggle竞赛的开源数据集,数据集地址
本数据集主要涉及到全球疫情统计,包括确诊、治愈、死亡、时间、国家、地区等信息
df = pd.read_csv(r'C:\Users\Hasee\Desktop/covid_19_data.csv') df.head()
cols= ['序号','日期','省/州','国家','最近更新','确诊','死亡','治愈'] df.columns = cols df.日期 = pd.to_datetime(df.日期) df
## 利用groupby按照日期统计确诊死亡治愈病例的总和
#合并同一天同国家日期
global_confirm = df.groupby('日期')[['确诊', '死亡', '治愈']].sum()
global_confirm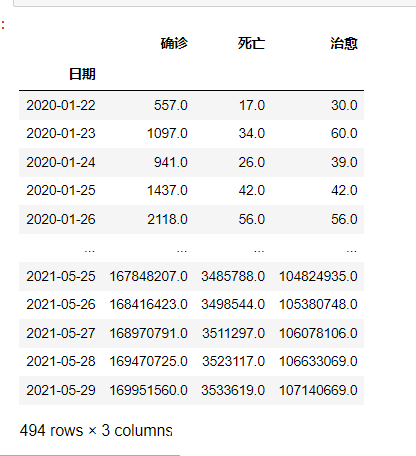
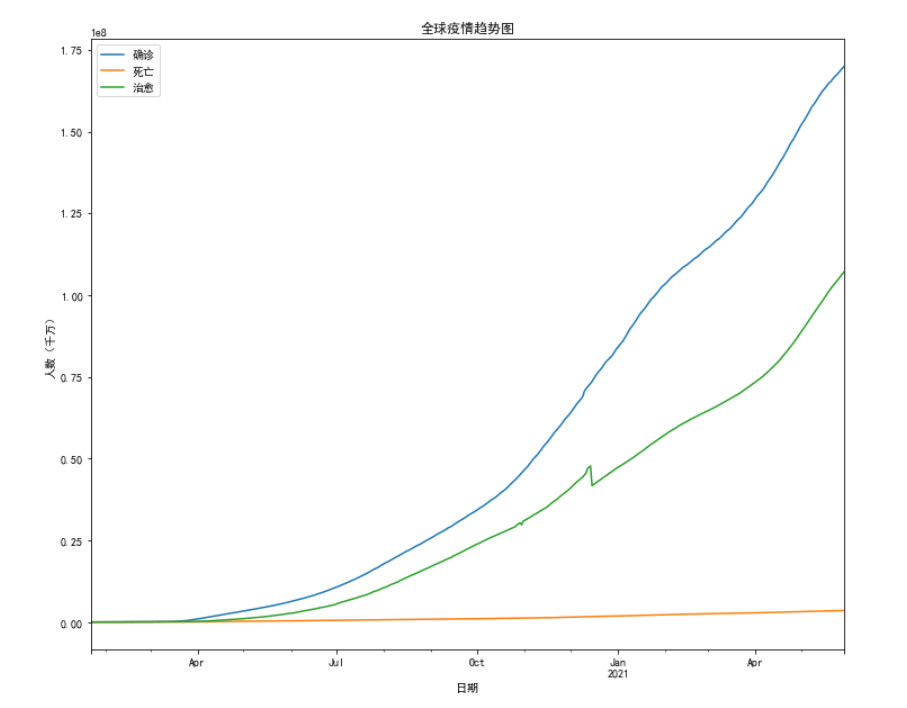
ax = global_confirm.plot(figsize = (12,10), title = '全球疫情趋势图')
利用groupby按照日期统计确诊死亡治愈病例的总和
global_china = df[df['国家'] == 'Mainland China'].reset_index()
global_china_confirm = global_china.groupby('日期')[['确诊', '死亡', '治愈']].sum().reset_index()画图,三条线组合到一个图
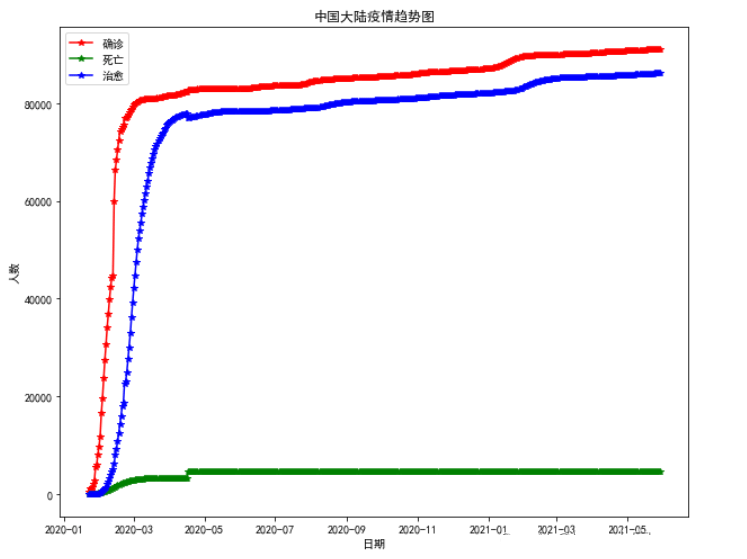
global_china = df[df['国家'] == 'Mainland China'].reset_index()
global_china_province_confirm = global_china.groupby('省/州')[['确诊', '死亡', '治愈']].sum().reset_index()
recovercent = 100.*global_china_province_confirm['治愈'] / global_china_province_confirm['治愈'].sum()
labels = ['{0}-{1:1.2f}%-{2}'.format(i,j,k) for i,j,k in zip(list(global_china_province_confirm['省/州']), recovercent, list(global_china_province_confirm['治愈']))]
plt.figure(figsize=(10,10))
plt.pie(global_china_province_confirm['治愈'],radius = 0.3)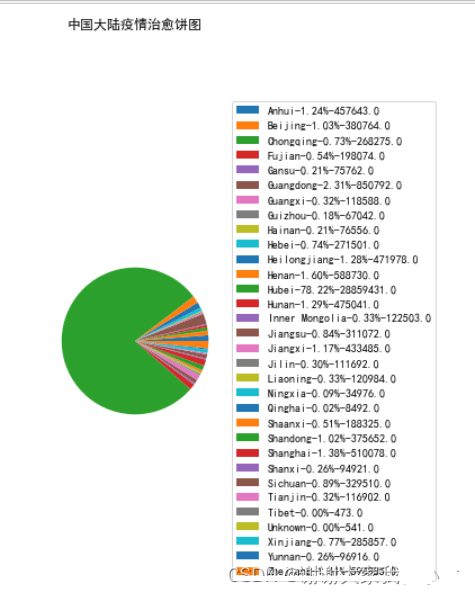
plt.figure(figsize=(16,16))
plt.barh(list(global_country_confirm_rank.国家)[::-1], list(global_country_confirm_rank.确诊)[::-1])
plt.title('确诊人数排名前15的国家')
plt.xlabel('人数(千万)')
plt.ylabel('国家')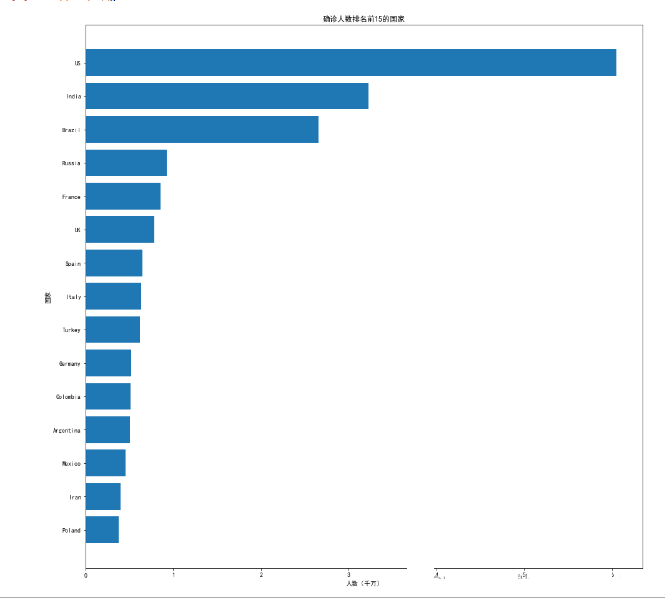
set_global_opts是设置格式:
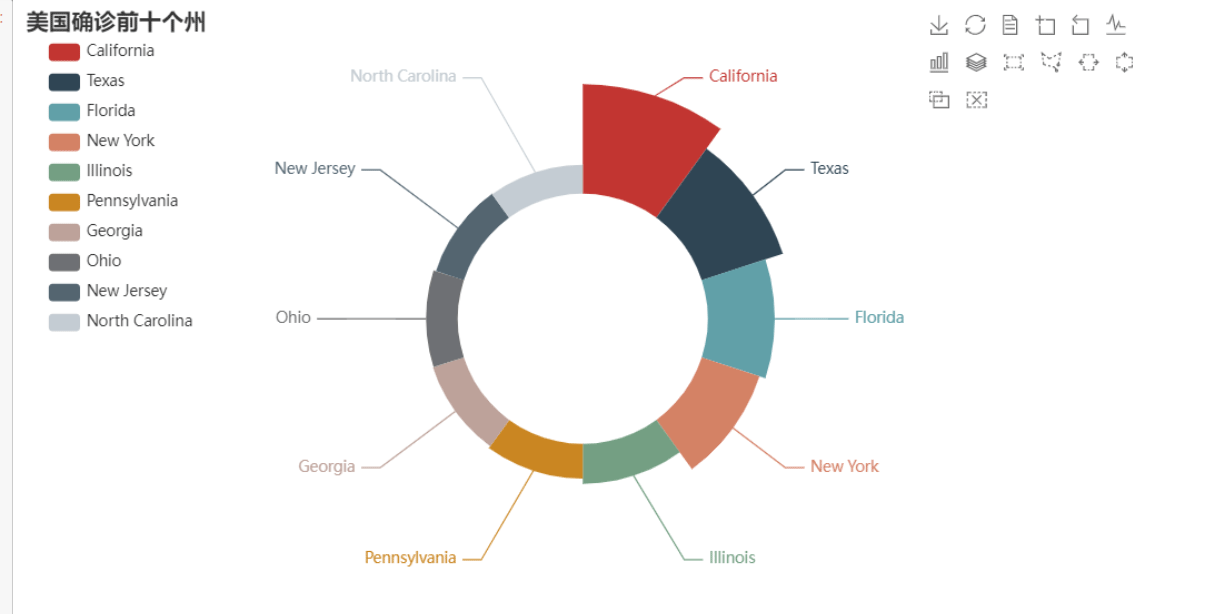
china_confirm = df[df['国家'] == "Mainland China"]
china_latest = china_confirm[china_confirm['日期'] == max(china_confirm['日期'])]
words = WordCloud()
words.add('确诊人数', [tuple(dic) for dic in zip(list(china_latest['省/州']),list(china_latest['确诊']))], word_size_range=[20,100])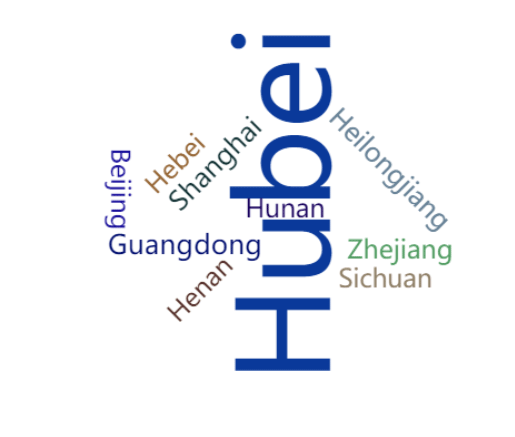
china_death = df[df['国家'] == "Mainland China"]
china_death_latest = china_death[china_death['日期'] == max(china_death['日期'])]
china_death_latest = china_death_latest.groupby('省/州')[['确诊', '死亡']].max().reset_index()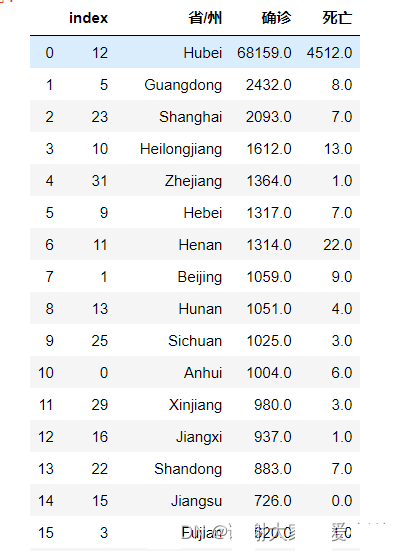
geo = Map()
geo.add("中国死亡病例分布", [list(z) for z in zip(china_death_prodic,list(china_death_latest['死亡']))], "china")
geo.set_global_opts(title_opts=opts.TitleOpts(title="全国各省死亡病例数据分布"),visualmap_opts=opts.VisualMapOpts(is_piecewise=True,
pieces=[
{"min": 1500, "label": '>10000人', "color": "#6F171F"},
{"min": 500, "max": 15000, "label": '500-1000人', "color": "#C92C34"},
{"min": 100, "max": 499, "label": '100-499人', "color": "#E35B52"},
{"min": 10, "max": 99, "label": '10-99人', "color": "#F39E86"},
{"min": 1, "max": 9, "label": '1-9人', "color": "#FDEBD0"}]))
geo.render_notebook()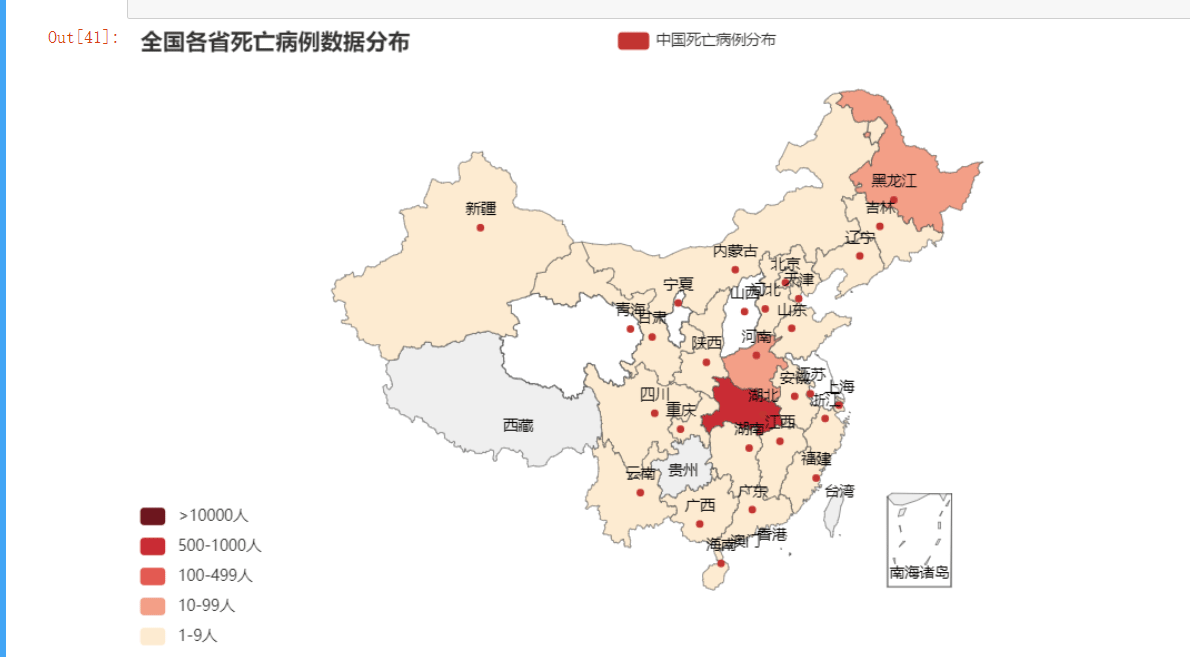
geo = Geo()
geo.add_schema(maptype="china")
geo.add("中国死亡病例分布", [list(dic) for dic in zip(china_death_prodic,list(china_death_latest['死亡']))],type_=GeoType.EFFECT_SCATTER)
geo.set_global_opts(visualmap_opts=opts.VisualMapOpts(),title_opts=opts.TitleOpts(title="全国各省死亡病例数据分布"))
geo.render_notebook()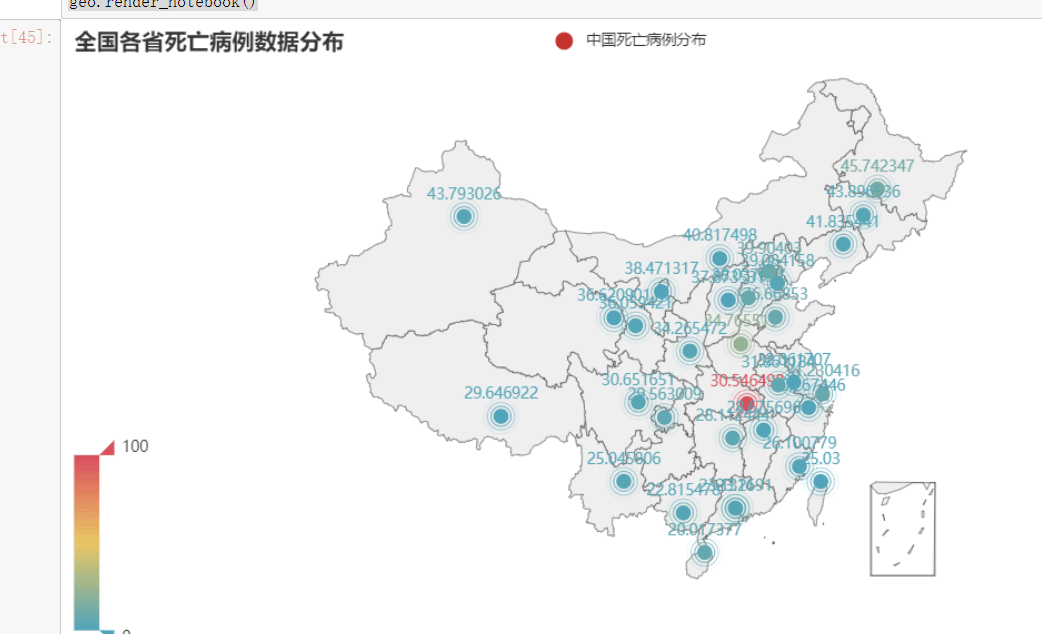
map = Map()
map.set_global_opts(title_opts=opts.TitleOpts(title="全球死亡人数地理分布情况"),visualmap_opts=opts.VisualMapOpts(is_piecewise=True,
pieces=[
{"min": 100001, "label": '>100001人', "color": "#6F171F"},
{"min": 10001, "max": 100000, "label": '10001-100000人', "color": "#C92C34"},
{"min": 1001, "max": 10000, "label": '1001-10000人', "color": "#E35B52"},
{"min": 101, "max": 10000, "label": '101-10000人', "color": "#F39E86"},
{"min": 1, "max": 100, "label": '1-100人', "color": "#FDEBD0"}]))
map.add("全球死亡人数地理分布情况", [list(z) for z in zip(global_death_n,list(global_death['死亡']))], "world")
map.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
map.render_notebook()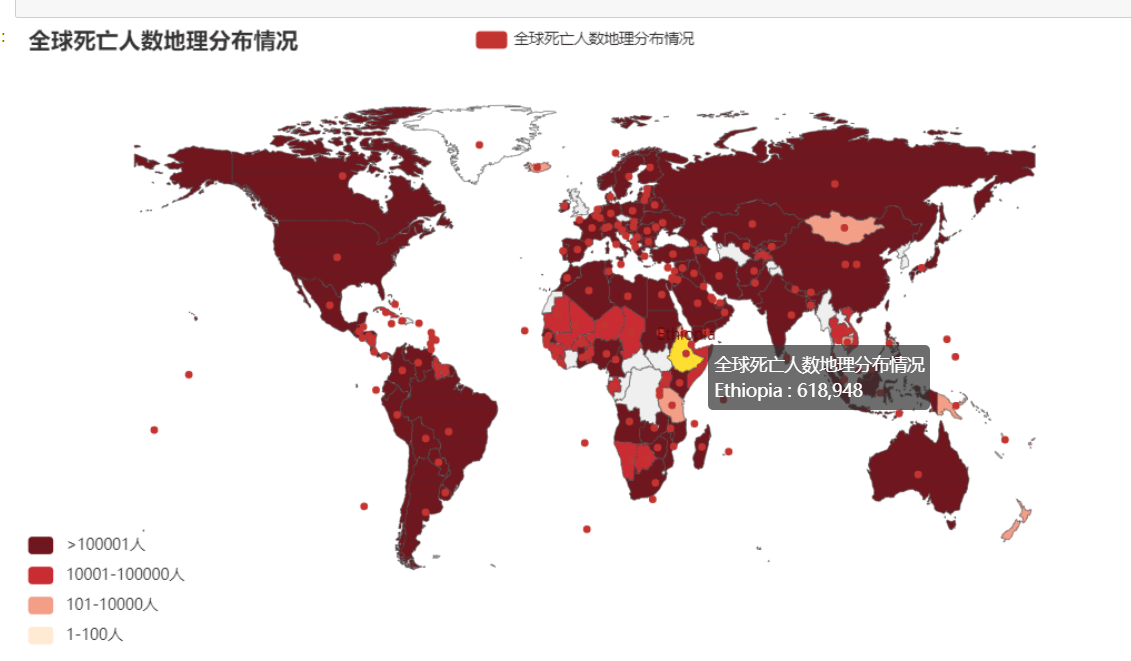
global_confirm.plot.hist(alpha=0.5)
plt.xlabel('人数(千万)')
plt.ylabel('出现频率')
plt.title('全球疫情频率直方图')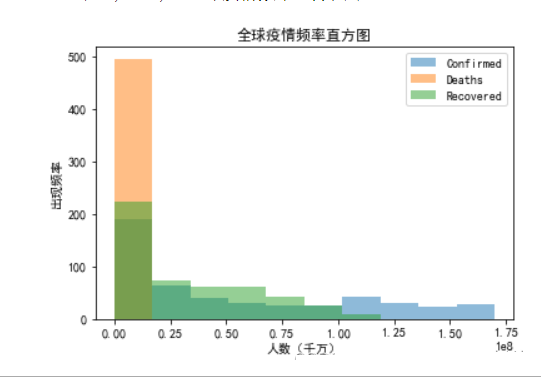

感谢各位的阅读,以上就是“Python疫情数据可视化分析怎么实现”的内容了,经过本文的学习后,相信大家对Python疫情数据可视化分析怎么实现这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。