жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮеҶ…е®№д»Ӣз»ҚдәҶвҖңNumPyдёҺPythonеҶ…зҪ®еҲ—иЎЁи®Ўз®—ж ҮеҮҶе·®еҢәеҲ«жҳҜд»Җд№ҲвҖқзҡ„жңүе…ізҹҘиҜҶпјҢеңЁе®һйҷ…жЎҲдҫӢзҡ„ж“ҚдҪңиҝҮзЁӢдёӯпјҢдёҚе°‘дәәйғҪдјҡйҒҮеҲ°иҝҷж ·зҡ„еӣ°еўғпјҢжҺҘдёӢжқҘе°ұи®©е°Ҹзј–еёҰйўҶеӨ§е®¶еӯҰд№ дёҖдёӢеҰӮдҪ•еӨ„зҗҶиҝҷдәӣжғ…еҶөеҗ§пјҒеёҢжңӣеӨ§е®¶д»”з»Ҷйҳ…иҜ»пјҢиғҪеӨҹеӯҰжңүжүҖжҲҗпјҒ
NumPyпјҢжҳҜ Numerical Python зҡ„з®Җз§°пјҢз”ЁдәҺй«ҳжҖ§иғҪ科еӯҰи®Ўз®—е’Ңж•°жҚ®еҲҶжһҗзҡ„еҹәзЎҖеҢ…пјҢеғҸж•°еӯҰ科еӯҰе·Ҙе…·пјҲpandasпјүе’ҢжЎҶжһ¶пјҲScikit-learnпјүдёӯйғҪдҪҝз”ЁеҲ°дәҶ NumPy иҝҷдёӘеҢ…гҖӮ
NumPy дёӯзҡ„еҹәжң¬ж•°жҚ®з»“жһ„жҳҜndarrayжҲ–иҖ… N з»ҙж•°еҖјж•°з»„пјҢеңЁеҪўејҸдёҠжқҘиҜҙпјҢе®ғзҡ„з»“жһ„жңүзӮ№еғҸ Python зҡ„еҹәзЎҖзұ»еһӢ——PythonеҲ—иЎЁгҖӮ
дҪҶжң¬иҙЁдёҠпјҢиҝҷдёӨиҖ…并дёҚеҗҢпјҢеҸҜд»ҘзңӢеҲ°дёҖдёӘз®ҖеҚ•зҡ„еҜ№жҜ”гҖӮ
жҲ‘们еҲӣе»әдёӨдёӘеҲ—иЎЁпјҢеҪ“жҲ‘们еҲӣе»әеҘҪдәҶд№ӢеҗҺпјҢеҸҜд»ҘдҪҝз”Ё +иҝҗз®—з¬ҰиҝӣиЎҢиҝһжҺҘ:
list1 = [i for i in range(1,11)] list2 = [i**2 for i in range(1,11)] print(list1+list2) # [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
еҲ—иЎЁдёӯе…ғзҙ зҡ„еӨ„зҗҶж„ҹи§үеғҸеҜ№иұЎпјҢдёҚжҳҜеҫҲж•°еӯ—пјҢдёҚжҳҜеҗ—пјҹ еҰӮжһңиҝҷдәӣжҳҜж•°еӯ—еҗ‘йҮҸиҖҢдёҚжҳҜз®ҖеҚ•зҡ„ж•°еӯ—еҲ—иЎЁпјҢжӮЁдјҡжңҹжңӣ + иҝҗз®—з¬Ұзҡ„иЎҢдёәз•ҘжңүдёҚеҗҢпјҢ并е°Ҷ第дёҖдёӘеҲ—иЎЁдёӯзҡ„ж•°еӯ—жҢүе…ғзҙ ж·»еҠ еҲ°з¬¬дәҢдёӘеҲ—иЎЁдёӯзҡ„зӣёеә”ж•°еӯ—дёӯгҖӮ
жҺҘдёӢжқҘзңӢдёҖдёӢ Nympy зҡ„ж•°з»„зүҲжң¬пјҡ
import numpy as np arr1 = np.array(list1) arr2 = np.array(list2) arr1 + arr2 # array([ 2, 6, 12, 20, 30, 42, 56, 72, 90, 110])
йҖҡиҝҮ numpy зҡ„np.arrayж•°з»„ж–№жі•е®һзҺ°дәҶдёӨдёӘеҲ—иЎЁеҶ…зҡ„йҖҗдёӘеҖјиҝӣиЎҢзӣёеҠ гҖӮ
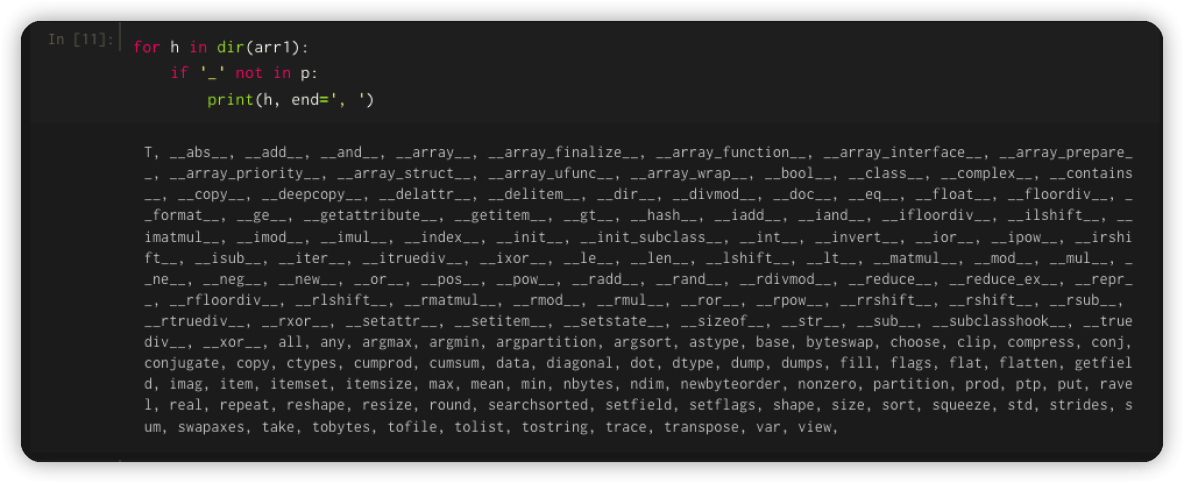
жҲ‘们йҖҡиҝҮdir еҮҪж•°жқҘзңӢдёӨиҖ…зҡ„еҢәеҲ«пјҢе…ҲзңӢ Python еҶ…зҪ®еҲ—иЎЁ list1зҡ„еҶ…зҪ®ж–№жі•пјҡ

еҶҚз”ЁеҗҢж ·зҡ„ж–№жі•зңӢдёҖдёӢ arr1дёӯзҡ„ж–№жі•пјҡ
NumPy ж•°з»„еҜ№иұЎиҝҳжңүжӣҙеӨҡеҸҜз”Ёзҡ„еҮҪж•°е’ҢеұһжҖ§гҖӮ зү№еҲ«иҰҒжіЁж„ҸиҜёеҰӮmeanгҖҒstdе’Ңsumд№Ӣзұ»зҡ„ж–№жі•пјҢеӣ дёәе®ғ们清жҘҡең°иЎЁжҳҺйҮҚзӮ№е…іжіЁдҪҝз”Ёиҝҷз§Қж•°з»„еҜ№иұЎзҡ„ж•°еҖј/з»ҹи®Ўи®Ўз®—гҖӮ иҖҢдё”иҝҷдәӣж“ҚдҪңд№ҹеҫҲеҝ«гҖӮ
NumPy зҡ„йҖҹеәҰиҰҒеҝ«еҫ—еӨҡпјҢеӣ дёәе®ғзҡ„зҹўйҮҸеҢ–е®һзҺ°д»ҘеҸҠе®ғзҡ„и®ёеӨҡж ёеҝғдҫӢзЁӢжңҖеҲқжҳҜз”Ё C иҜӯиЁҖпјҲеҹәдәҺ CPython жЎҶжһ¶пјүзј–еҶҷзҡ„гҖӮ NumPy ж•°з»„жҳҜеҗҢжһ„зұ»еһӢзҡ„еҜҶйӣҶжҺ’еҲ—зҡ„ж•°з»„гҖӮ зӣёжҜ”д№ӢдёӢпјҢPython еҲ—иЎЁжҳҜжҢҮеҗ‘еҜ№иұЎзҡ„жҢҮй’Ҳж•°з»„пјҢеҚідҪҝе®ғ们йғҪеұһдәҺеҗҢдёҖзұ»еһӢгҖӮ еӣ жӯӨпјҢжҲ‘们еҫ—еҲ°дәҶеҸӮиҖғеұҖйғЁжҖ§зҡ„еҘҪеӨ„гҖӮ
и®ёеӨҡ NumPy ж“ҚдҪңжҳҜз”Ё C иҜӯиЁҖе®һзҺ°зҡ„пјҢйҒҝе…ҚдәҶ Python дёӯзҡ„еҫӘзҺҜгҖҒжҢҮй’Ҳй—ҙжҺҘе’ҢйҖҗе…ғзҙ еҠЁжҖҒзұ»еһӢжЈҖжҹҘзҡ„дёҖиҲ¬жҲҗжң¬гҖӮ зү№еҲ«жҳҜпјҢйҖҹеәҰзҡ„жҸҗеҚҮеҸ–еҶідәҺжӮЁжӯЈеңЁжү§иЎҢзҡ„ж“ҚдҪңгҖӮ еҜ№дәҺж•°жҚ®з§‘еӯҰе’Ң ML д»»еҠЎпјҢиҝҷжҳҜдёҖдёӘж— д»·зҡ„дјҳеҠҝпјҢеӣ дёәе®ғйҒҝе…ҚдәҶй•ҝе’ҢеӨҡз»ҙж•°з»„дёӯзҡ„еҫӘзҺҜгҖӮ
и®©жҲ‘们дҪҝз”Ё @timingи®Ўж—¶иЈ…йҘ°еҷЁжқҘиҜҙжҳҺиҝҷдёҖзӮ№гҖӮ иҝҷжҳҜдёҖдёӘеӣҙз»•дёӨдёӘеҮҪж•° std_devе’Ңstd_dev_pythonеҢ…иЈ…иЈ…йҘ°еҷЁзҡ„д»Јз ҒпјҢеҲҶеҲ«дҪҝз”Ё NumPy е’Ңжң¬жңә Python д»Јз Ғе®һзҺ°еҲ—иЎЁ/ж•°з»„зҡ„ж ҮеҮҶе·®и®Ўз®—гҖӮ
жҲ‘们еҸҜд»ҘдҪҝз”Ё Python иЈ…йҘ°еҷЁе’ҢfunctoolsжЁЎеқ—зҡ„wrappingжқҘеҶҷдёҖдёӘ ж—¶й—ҙиЈ…йҘ°еҷЁtiming:
def timing(func):
@wraps(func)
def wrap(*args, **kw):
begin_time = time()
result = func(*args, **kw)
end_time = time()
print(f"Function '{func.__name__}' took {end_time-begin_time} seconds to run")
return result
return wrap然еҗҺеҲ©з”ЁиҝҷдёӘж—¶й—ҙиЈ…йҘ°еҷЁжқҘзңӢ Numpy ж•°з»„е’Ң Python еҶ…зҪ®зҡ„еҲ—иЎЁпјҢ然еҗҺ计算他们зҡ„ж ҮеҮҶе·®пјҢ
е…¬ејҸеҰӮеӣҫпјҡ
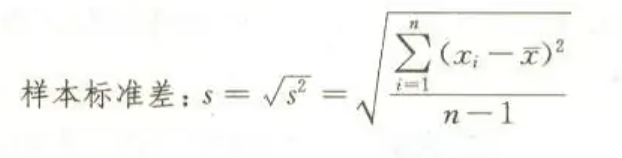
е®ҡд№ү Numpy и®Ўз®—ж ҮеҮҶе·®зҡ„еҮҪж•°std_dev()пјҢnumpy жЁЎеқ—дёӯеҶ…зҪ®дәҶж ҮеҮҶе·®е…¬ејҸзҡ„еҮҪж•° a.std()пјҢжҲ‘们еҸҜд»ҘзӣҙжҺҘи°ғз”Ё
еҲ—иЎЁи®Ўз®—е…¬ејҸж–№жі•йңҖиҰҒжҢүз…§е…¬ејҸдёҖжӯҘдёҖжӯҘи®Ўз®—пјҡ
е…ҲжұӮжұӮеҮәе®—е’Ңs
然еҗҺжұӮеҮәе№іеқҮеҖјaverage
и®Ўз®—жҜҸдёӘж•°еҖјдёҺе№іеқҮеҖјзҡ„е·®зҡ„е№іж–№пјҢеҶҚжұӮе’Ңsumsq
еҶҚжұӮеҮәsumsq зҡ„е№іеқҮеҖј sumsq_average
еҫ—еҲ°жңҖз»Ҳзҡ„ж ҮеҮҶе·®з»“жһңresult
д»Јз ҒеҰӮдёӢпјҡ
from functools import wraps
from time import time
import numpy as np
from math import sqrt
def timing(func):
@wraps(func)
def wrap(*args, **kw):
begin_time = time()
result = func(*args, **kw)
end_time = time()
# print(f"Function '{func.__name__}' with arguments {args},keywords {kw} took {end_time-begin_time} seconds to run")
print(f"Function '{func.__name__}' took {end_time-begin_time} seconds to run")
return result
return wrap
@timing
def std_dev(a):
if isinstance(a, list):
a = np.array(a)
s = a.std()
return s
@timing
def std_dev_python(lst):
length = len(lst)
s = sum(lst)
average = s / length
sumsq = 0
for i in lst:
sumsq += (i-average)**2
sumsq_average = sumsq/length
result = sqrt(sumsq_average)
return resultиҝҗиЎҢз»“жһңпјҢжңҖз»ҲеҸҜд»ҘзңӢеҲ° 1000000 дёӘеҖјеҫ—ж ҮеҮҶе·®зҡ„еҖјдёә 288675.13459пјҢиҖҢ Numpy и®Ўз®—ж—¶й—ҙдёә 0.0080 sпјҢиҖҢ Python еҺҹз”ҹи®Ўз®—ж–№ејҸдёә 0.2499 sпјҡ
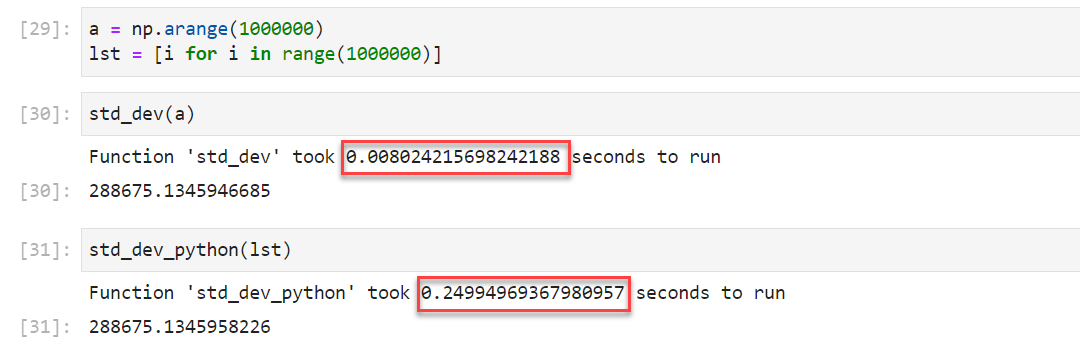
з”ұжӯӨеҸҜи§ҒпјҢNumpy зҡ„ж–№ејҸжҳҺжҳҫжӣҙеҝ«гҖӮ
вҖңNumPyдёҺPythonеҶ…зҪ®еҲ—иЎЁи®Ўз®—ж ҮеҮҶе·®еҢәеҲ«жҳҜд»Җд№ҲвҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–е°ҶдёәеӨ§е®¶иҫ“еҮәжӣҙеӨҡй«ҳиҙЁйҮҸзҡ„е®һз”Ёж–Үз« пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ