жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
д»ҠеӨ©е°Ҹзј–з»ҷеӨ§е®¶еҲҶдә«дёҖдёӢPythonеҰӮдҪ•е®һзҺ°иҒҡзұ»K-meansз®—жі•зҡ„зӣёе…ізҹҘиҜҶзӮ№пјҢеҶ…е®№иҜҰз»ҶпјҢйҖ»иҫ‘жё…жҷ°пјҢзӣёдҝЎеӨ§йғЁеҲҶдәәйғҪиҝҳеӨӘдәҶи§Јиҝҷж–№йқўзҡ„зҹҘиҜҶпјҢжүҖд»ҘеҲҶдә«иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶еҸӮиҖғдёҖдёӢпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺжңүжүҖ收иҺ·пјҢдёӢйқўжҲ‘们дёҖиө·жқҘдәҶи§ЈдёҖдёӢеҗ§гҖӮ
K-meansпјҲKеқҮеҖјпјүз®—жі•жҳҜжңҖз®ҖеҚ•зҡ„дёҖз§ҚиҒҡзұ»з®—жі•пјҢе®ғжңҹжңӣжңҖе°ҸеҢ–е№іж–№иҜҜе·®

жіЁпјҡдёәйҒҝе…ҚиҝҗиЎҢж—¶й—ҙиҝҮй•ҝпјҢйҖҡеёёи®ҫзҪ®дёҖдёӘжңҖеӨ§иҝҗиЎҢиҪ®ж•°жҲ–жңҖе°Ҹи°ғж•ҙе№…еәҰйҳҲеҖјпјҢиӢҘеҲ°иҫҫжңҖеӨ§иҪ®ж•°жҲ–и°ғж•ҙе№…еәҰе°ҸдәҺйҳҲеҖјпјҢеҲҷеҒңжӯўиҝҗиЎҢгҖӮ
дёӢйқўжҲ‘们用pythonжқҘе®һзҺ°дёҖдёӢK-meansз®—жі•пјҡжҲ‘们е…Ҳе°қиҜ•жүӢеҠЁе®һзҺ°иҝҷдёӘз®—жі•пјҢеҶҚз”Ёsklearnеә“дёӯзҡ„KMeansзұ»жқҘе®һзҺ°гҖӮж•°жҚ®жҲ‘们йҮҮз”ЁгҖҠжңәеҷЁеӯҰд№ гҖӢзҡ„иҘҝз“ңж•°жҚ®(P202иЎЁ9.1):
# дёӢйқўзҡ„еҶ…е®№дҝқеӯҳеңЁ melons.txt дёӯ # 第дёҖеҲ—дёәиҘҝз“ңзҡ„еҜҶеәҰпјӣ第дәҢеҲ—дёәиҘҝз“ңзҡ„еҗ«зі–зҺҮгҖӮжҲ‘们иҰҒжҠҠиҝҷ30дёӘиҘҝз“ңеҲҶдёә3зұ» 0.697 0.460 0.774 0.376 0.634 0.264 0.608 0.318 0.556 0.215 0.403 0.237 0.481 0.149 0.437 0.211 0.666 0.091 0.243 0.267 0.245 0.057 0.343 0.099 0.639 0.161 0.657 0.198 0.360 0.370 0.593 0.042 0.719 0.103 0.359 0.188 0.339 0.241 0.282 0.257 0.748 0.232 0.714 0.346 0.483 0.312 0.478 0.437 0.525 0.369 0.751 0.489 0.532 0.472 0.473 0.376 0.725 0.445 0.446 0.459
жҲ‘们用еҲ°зҡ„еә“жңүmatplotlibе’ҢnumpyпјҢеҰӮжһңжІЎжңүйңҖиҰҒе…Ҳз”Ёpipе®үиЈ…дёҖдёӢгҖӮ
import random import numpy as np import matplotlib.pyplot as plt
дёӢйқўе®ҡд№үдёҖдәӣж•°жҚ®пјҡ
k = 3 # иҰҒеҲҶзҡ„з°Үж•° rnd = 0 # иҪ®ж¬ЎпјҢз”ЁдәҺжҺ§еҲ¶иҝӯд»Јж¬Ўж•°пјҲи§ҒдёҠж–Үпјү ROUND_LIMIT = 100 # иҪ®ж¬Ўзҡ„дёҠйҷҗ THRESHOLD = 1e-10 # еҚ•иҪ®ж”№еҸҳи·қзҰ»зҡ„йҳҲеҖјпјҢиӢҘж”№еҸҳе№…еәҰе°ҸдәҺиҜҘйҳҲеҖјпјҢз®—жі•з»Ҳжӯў melons = [] # иҘҝз“ңзҡ„еҲ—иЎЁ clusters = [] # з°Үзҡ„еҲ—иЎЁпјҢclusters[i]иЎЁзӨә第iз°ҮеҢ…еҗ«зҡ„иҘҝз“ң
д»Һmelons.txtиҜ»еҸ–ж•°жҚ®пјҢдҝқеӯҳеңЁеҲ—иЎЁдёӯпјҡ
f = open('melons.txt', 'r')
for line in f:
# жҠҠеӯ—з¬ҰдёІиҪ¬еҢ–дёәnumpyдёӯзҡ„float64зұ»еһӢ
melons.append(np.array(line.split(' '), dtype = np.string_).astype(np.float64))д»Һ m m mдёӘж•°жҚ®дёӯйҡҸжңәжҢ‘йҖүеҮә k k kдёӘпјҢеҜ№еә”дёҠйқўз®—жі•зҡ„第 1 1 1иЎҢпјҡ
# randomзҡ„sampleеҮҪж•°д»ҺеҲ—иЎЁдёӯйҡҸжңәжҢ‘йҖүеҮәkдёӘж ·жң¬пјҲдёҚйҮҚеӨҚпјүгҖӮжҲ‘们еңЁиҝҷйҮҢжҠҠиҝҷдәӣж ·жң¬дҪңдёәеқҮеҖјеҗ‘йҮҸ mean_vectors = random.sample(melons, k)
дёӢйқўжҳҜз®—жі•зҡ„дё»иҰҒйғЁеҲҶгҖӮ
# иҝҷдёӘwhileеҜ№еә”дёҠйқўз®—жі•зҡ„2-17иЎҢ
while True:
rnd += 1 # иҪ®ж¬ЎеўһеҠ
change = 0 # жҠҠж”№еҸҳе№…еәҰйҮҚзҪ®дёә0
# жё…з©әеҜ№з°Үзҡ„еҲ’еҲҶпјҢеҜ№еә”дёҠйқўз®—жі•зҡ„第3иЎҢ
clusters = []
for i in range(k):
clusters.append([])
# иҝҷдёӘforеҜ№еә”дёҠйқўз®—жі•зҡ„4-8иЎҢ
for melon in melons:
'''
argmin еҮҪж•°жүҫеҮәе®№еҷЁдёӯжңҖе°Ҹзҡ„дёӢж ҮпјҢеңЁиҝҷйҮҢиҝҷдёӘзӣ®ж Үе®№еҷЁжҳҜ
list(map(lambda vec: np.linalg.norm(melon - vec, ord = 2), mean_vectors)),
е®ғиЎЁзӨәmelonдёҺmean_vectorsдёӯжүҖжңүеҗ‘йҮҸзҡ„и·қзҰ»еҲ—иЎЁгҖӮ
(numpy.linalg.normи®Ўз®—еҗ‘йҮҸзҡ„иҢғж•°,ord = 2еҚіж¬§еҮ йҮҢеҫ—иҢғж•°пјҢжҲ–жЁЎй•ҝ)
'''
c = np.argmin(
list(map( lambda vec: np.linalg.norm(melon - vec, ord = 2), mean_vectors))
)
clusters[c].append(melon)
# иҝҷдёӘforеҜ№еә”дёҠйқўз®—жі•зҡ„9-16иЎҢ
for i in range(k):
# жұӮжҜҸдёӘз°Үзҡ„ж–°еқҮеҖјеҗ‘йҮҸ
new_vector = np.zeros((1,2))
for melon in clusters[i]:
new_vector += melon
new_vector /= len(clusters[i])
# зҙҜеҠ ж”№еҸҳе№…еәҰ并жӣҙж–°еқҮеҖјеҗ‘йҮҸ
change += np.linalg.norm(mean_vectors[i] - new_vector, ord = 2)
mean_vectors[i] = new_vector
# иӢҘи¶…иҝҮи®ҫе®ҡзҡ„иҪ®ж¬ЎжҲ–иҖ…еҸҳеҢ–е№…еәҰ<йў„е…Ҳи®ҫе®ҡзҡ„йҳҲеҖјпјҢз»“жқҹз®—жі•
if rnd > ROUND_LIMIT or change < THRESHOLD:
break
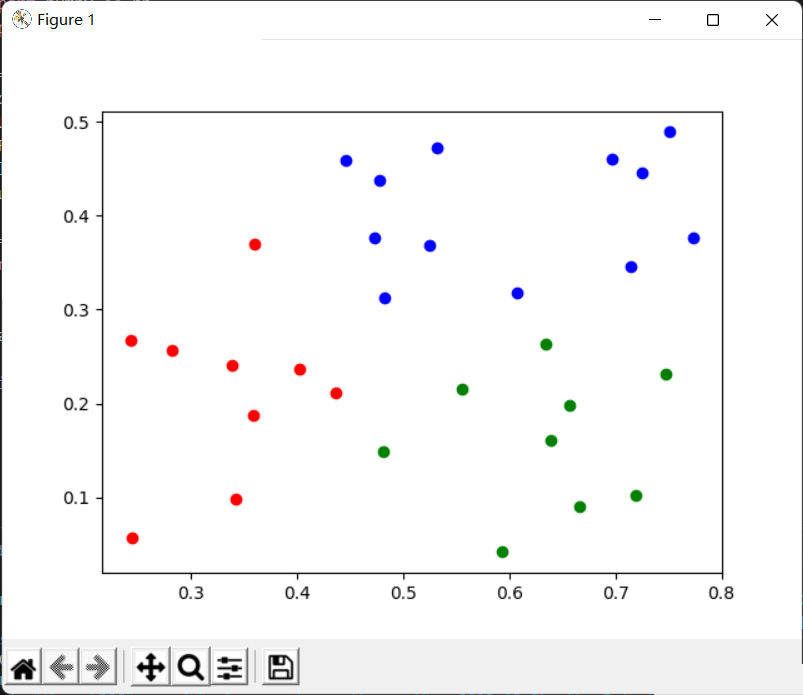
print('жңҖз»Ҳиҝӯд»Ј%dиҪ®'%rnd)жңҖеҗҺжҲ‘们з»ҳеӣҫжқҘи§ӮеҜҹдёҖдёӢеҲ’еҲҶзҡ„з»“жһңпјҡ
colors = ['red', 'green', 'blue'] # жҜҸдёӘз°ҮжҚўдёҖдёӢйўңиүІпјҢеҗҢж—¶иҝӯд»Јз°Үе’ҢйўңиүІдёӨдёӘеҲ—иЎЁ for i, col in zip(range(k), colors): for melon in clusters[i]: # з»ҳеҲ¶ж•ЈзӮ№еӣҫ plt.scatter(melon[0], melon[1], color = col) plt.show()
еҲ’еҲҶз»“жһңпјҲз”ұдәҺжңҖејҖе§Ӣзҡ„ k k kдёӘеқҮеҖјеҗ‘йҮҸйҡҸжңәйҖүеҸ–пјҢжҜҸж¬ЎеҲ’еҲҶзҡ„з»“жһңеҸҜиғҪдјҡдёҚеҗҢпјү:
е®Ңж•ҙд»Јз Ғпјҡ
import random
import numpy as np
import matplotlib.pyplot as plt
k = 3
rnd = 0
ROUND_LIMIT = 10
THRESHOLD = 1e-10
melons = []
clusters = []
f = open('melons.txt', 'r')
for line in f:
melons.append(np.array(line.split(' '), dtype = np.string_).astype(np.float64))
mean_vectors = random.sample(melons, k)
while True:
rnd += 1
change = 0
clusters = []
for i in range(k):
clusters.append([])
for melon in melons:
c = np.argmin(
list(map( lambda vec: np.linalg.norm(melon - vec, ord = 2), mean_vectors))
)
clusters[c].append(melon)
for i in range(k):
new_vector = np.zeros((1,2))
for melon in clusters[i]:
new_vector += melon
new_vector /= len(clusters[i])
change += np.linalg.norm(mean_vectors[i] - new_vector, ord = 2)
mean_vectors[i] = new_vector
if rnd > ROUND_LIMIT or change < THRESHOLD:
break
print('жңҖз»Ҳиҝӯд»Ј%dиҪ®'%rnd)
colors = ['red', 'green', 'blue']
for i, col in zip(range(k), colors):
for melon in clusters[i]:
plt.scatter(melon[0], melon[1], color = col)
plt.show()иҝҷз§Қз»Ҹе…ёз®—жі•жҳҫ然дёҚйңҖиҰҒжҲ‘们еҸҚеӨҚең°йҖ иҪ®еӯҗпјҢиў«е№ҝжіӣдҪҝз”Ёзҡ„pythonжңәеҷЁеӯҰд№ еә“sklearnе·Із»ҸжҸҗдҫӣдәҶиҜҘз®—жі•зҡ„е®һзҺ°гҖӮsklearnзҡ„е®ҳж–№ж–ҮжЎЈдёӯз»ҷдәҶжҲ‘们дёҖдёӘзӨәдҫӢпјҡ
>>> from sklearn.cluster import KMeans >>> import numpy as np >>> X = np.array([[1, 2], [1, 4], [1, 0], ... [10, 2], [10, 4], [10, 0]]) >>> kmeans = KMeans(n_clusters=2, random_state=0).fit(X) >>> kmeans.labels_ array([1, 1, 1, 0, 0, 0], dtype=int32) >>> kmeans.predict([[0, 0], [12, 3]]) array([1, 0], dtype=int32) >>> kmeans.cluster_centers_ array([[10., 2.], [ 1., 2.]])
еҸҜд»ҘзңӢеҮәпјҢXеҚіиҰҒиҒҡзұ»зҡ„ж•°жҚ®(1,2),(1,4),(1,0)зӯүгҖӮKMeansзұ»зҡ„еҲқе§ӢеҢ–еҸӮж•°n_clustersеҚіз°Үж•° k k k;random_stateжҳҜз”ЁдәҺеҲқе§ӢеҢ–йҖүеҸ– k k kдёӘеҗ‘йҮҸзҡ„йҡҸжңәж•°з§Қеӯҗ;kmeans.labels_еҚіжҜҸдёӘзӮ№жүҖеұһзҡ„з°Үпјӣkmeans.predictж–№жі•йў„жөӢж–°зҡ„ж•°жҚ®еұһдәҺе“ӘдёӘз°Ү;kmeans.cluster_centers_иҝ”еӣһжҜҸдёӘз°Үзҡ„дёӯеҝғгҖӮ
жҲ‘们е°ұж”№йҖ дёҖдёӢиҝҷдёӘз®ҖеҚ•зҡ„зӨәдҫӢпјҢе®ҢжҲҗеҜ№дёҠйқўиҘҝз“ңзҡ„иҒҡзұ»гҖӮ
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
X = []
f = open('melons.txt', 'r')
for line in f:
X.append(np.array(line.split(' '), dtype = np.string_).astype(np.float64))
kmeans = KMeans(n_clusters = 3, random_state = 0).fit(X)
colors = ['red', 'green', 'blue']
for i, cluster in enumerate(kmeans.labels_):
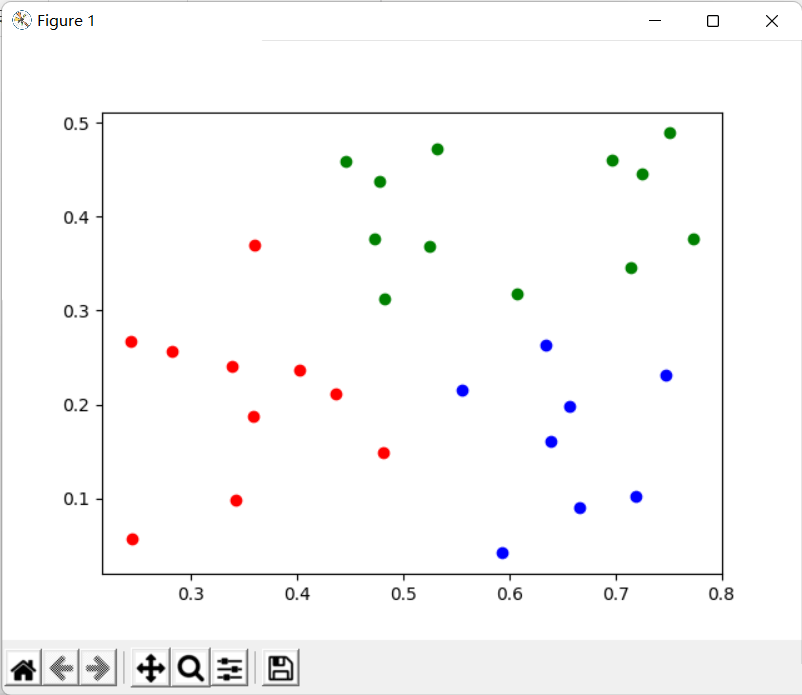
plt.scatter(X[i][0], X[i][1], color = colors[cluster])
plt.show()иҝҗиЎҢз»“жһңеҰӮдёӢпјҢеҸҜд»ҘзңӢеҲ°е’ҢжҲ‘们жүӢеҶҷзҡ„иҒҡзұ»з»“жһңеҹәжң¬дёҖиҮҙпјҡ
д»ҘдёҠе°ұжҳҜвҖңPythonеҰӮдҪ•е®һзҺ°иҒҡзұ»K-meansз®—жі•вҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒзӣёдҝЎеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« йғҪжңүеҫҲеӨ§зҡ„收иҺ·пјҢе°Ҹзј–жҜҸеӨ©йғҪдјҡдёәеӨ§е®¶жӣҙж–°дёҚеҗҢзҡ„зҹҘиҜҶпјҢеҰӮжһңиҝҳжғіеӯҰд№ жӣҙеӨҡзҡ„зҹҘиҜҶпјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ