жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒи®Іи§ЈдәҶвҖңPythonж“ҚдҪңpdf pdfplumberиҜ»еҸ–PDFеҶҷе…ҘExceвҖқпјҢж–Үдёӯзҡ„и®Іи§ЈеҶ…е®№з®ҖеҚ•жё…жҷ°пјҢжҳ“дәҺеӯҰд№ дёҺзҗҶи§ЈпјҢдёӢйқўиҜ·еӨ§е®¶и·ҹзқҖе°Ҹзј–зҡ„жҖқи·Ҝж…ўж…ўж·ұе…ҘпјҢдёҖиө·жқҘз ”з©¶е’ҢеӯҰд№ вҖңPythonж“ҚдҪңpdf pdfplumberиҜ»еҸ–PDFеҶҷе…ҘExceвҖқеҗ§пјҒ
е®үиЈ…pdfplumber:
pip install pdfplumber
pdfplumber.PDFзұ»
pdfplumber.PDFзұ»иЎЁзӨәеҚ•дёӘPDF ,并具жңүдёӨдёӘдё»иҰҒеұһжҖ§:
| еұһжҖ§ | иҜҙжҳҺ |
|---|---|
| pdf.metadata | д»ҺPDFзҡ„InfoдёӯиҺ·еҸ–е…ғж•°жҚ®й”®/еҖјеҜ№еӯ—е…ёгҖӮйҖҡеёёеҢ…жӢ¬"CreationDateпјҢвҖңModDater"пјҢ"Producer"зӯү |
| pdf.pages | иҝ”еӣһдёҖдёӘеҢ…еҗ«pdfplumber. Pageе®һдҫӢзҡ„еҲ—иЎЁ,жҜҸдёҖдёҖдёӘе®һдҫӢд»ЈиЎЁPDFжҜҸдёҖйЎөзҡ„дҝЎжҒҜ |
pdfplumber.Pageзұ»
pdfplumber.Pageзұ»еёёз”ЁеұһжҖ§
| еұһжҖ§page_ number | иҜҙжҳҺ |
|---|---|
| .page_ number | йЎәеәҸйЎөз Ғ,д»Һ1第дёҖйЎөејҖе§Ӣ,д»Һ第дәҢйЎөејҖе§Ӣ2 ,дҫқжӯӨзұ»жҺЁ |
| .width | йЎөйқўзҡ„е®ҪеәҰ |
| .height | йЎөйқўзҡ„й«ҳеәҰ |
| .objects/ . chars/ .lines/ .rects/ . curves/ .figures/ . images | иҝҷдәӣеұһжҖ§дёӯзҡ„жҜҸдёҖдёӘйғҪжҳҜдёҖ дёӘеҲ—иЎЁпјҢ жҜҸдёӘеҲ—иЎЁеҢ…еҗ«дёҖдёӘеӯ—е…ё пјҢз”ЁдәҺеөҢе…ҘйЎөйқўдёҠзҡ„жҜҸдёӘжӯӨзұ»еҜ№иұЎпјҢжңүе…іиҜҰз»ҶдҝЎжҒҜпјҢиҜ·еҸӮйҳ…дёӢйқўзҡ„вҖңеҜ№иұЎвҖқгҖӮ |
еёёз”Ёж–№жі•пјҡ
| ж–№жі•еҗҚ | иҜҙжҳҺ |
|---|---|
| .extract_ text( ) | з”ЁжқҘжҸҗйЎөйқўдёӯзҡ„ж–Үжң¬,е°ҶйЎөйқўзҡ„жүҖжңүеӯ—з¬ҰеҜ№иұЎж•ҙзҗҶдёәзҡ„йӮЈдёӘеӯ—з¬ҰдёІ |
| .extract_ words( ) | иҝ”еӣһзҡ„жҳҜжүҖжңүзҡ„еҚ•иҜҚеҸҠе…¶зӣёе…ідҝЎжҒҜ |
| . extract_ tables() | жҸҗеҸ–йЎөйқўзҡ„иЎЁж ј |
| .to_ _image() | з”ЁдәҺеҸҜи§ҶеҢ–и°ғиҜ•ж—¶пјҢиҝ”еӣһPagelmageзұ»зҡ„дёҖдёӘе®һдҫӢ |
| .close() | й»ҳи®Өжғ…еҶөдёӢ, PageеҜ№иұЎзј“еӯҳе…¶еёғеұҖе’ҢеҜ№иұЎдҝЎжҒҜ,д»ҘйҒҝе…ҚйҮҚж–°еӨ„зҗҶе®ғ, дҪҶжҳҜеңЁи§ЈжһҗеӨ§еһӢPDFж—¶,иҝҷдәӣзј“еӯҳзҡ„еұһжҖ§еҸҜиғҪйңҖиҰҒеӨ§йҮҸеҶ…еӯҳгҖӮжӮЁеҸҜд»ҘдҪҝз”ЁжӯӨж–№жі•еҲ·ж–°зј“еӯҳ并йҮҠж”ҫеҶ…еӯҳгҖӮ |
PDFжҳҜPortable Document Formatзҡ„зј©еҶҷпјҢиҝҷзұ»ж–Ү件йҖҡеёёдҪҝз”Ё.pdfдҪңдёәе…¶жү©еұ•еҗҚгҖӮеңЁж—ҘеёёејҖеҸ‘е·ҘдҪңдёӯпјҢжңҖе®№жҳ“йҒҮеҲ°зҡ„е°ұжҳҜд»ҺPDFдёӯиҜ»еҸ–ж–Үжң¬еҶ…е®№д»ҘеҸҠз”Ёе·Іжңүзҡ„еҶ…е®№з”ҹжҲҗPDFж–ҮжЎЈиҝҷдёӨдёӘд»»еҠЎгҖӮ
1.иҜ»еҸ–pdfж–ҮжЎЈдҝЎжҒҜ
2.иҫ“еҮәжҖ»йЎөж•°
3.иҜ»еҸ–第дёҖйЎөе®ҪеәҰгҖҒй«ҳеәҰзӯүдҝЎжҒҜ
4.иҜ»еҸ–ж–Үжң¬з¬¬дёҖйЎө
еҠ иҪҪpdfпјҡ
pdfplumber.open( "и·Ҝеҫ„/ж–Ү件еҗҚ. pdf".pas sword="test "laparams={ "line_ _overlap'вҖқ0.7 })
password : иҰҒеҠ иҪҪеҸ—еҜҶз ҒдҝқжҠӨзҡ„PDF ,иҜ·дј йҖ’passwordе…ій”®еӯ—еҸӮж•°
laparams :иҰҒе°ҶеёғеұҖеҲҶжһҗеҸӮж•°и®ҫзҪ®дёәpdfminer. sixзҡ„еёғеұҖеј•ж“Һ,иҜ·дј йҖ’laparamsе…ій”®еӯ—еҸӮж•°
pdfж–Ү件еҰӮдёӢпјҡ
import pdfplumber
# еҠ иҪҪpdf
path = "C:/Users/Administrator/Desktop/test08/test11 - еӨҡйЎө.pdf"
with pdfplumber.open(path) as pdf:
print(pdf)
print(type(pdf))
# иҜ»еҸ–pdfж–ҮжЎЈдҝЎжҒҜ
print("pdfж–ҮжЎЈдҝЎжҒҜ:", pdf.metadata)
# иҫ“еҮәжҖ»йЎөж•°
print("pdfж–ҮжЎЈжҖ»йЎөж•°:", len(pdf.pages))
# 1.иҜ»еҸ–第дёҖйЎөе®ҪеәҰгҖҒй«ҳеәҰзӯүдҝЎжҒҜ
first_page = pdf.pages[0] # pdfplumber.PageеҜ№иұЎз¬¬дёҖйЎө
# жҹҘзңӢйЎөз Ғ
print('pdfйЎөз Ғ:', first_page.page_number)
# жҹҘзңӢйЎөе®Ҫ
print('pdfйЎөе®Ҫ:', first_page.width)
# жҹҘзңӢйЎөй«ҳ
print('pdfйЎөй«ҳ:', first_page.height)
# 2.иҜ»еҸ–ж–Үжң¬з¬¬дёҖйЎө
first_page = pdf.pages[0] # pdfplumber.PageеҜ№иұЎз¬¬дёҖйЎө
text = first_page.extract_text()
print(text)жү§иЎҢз»“жһңпјҡ
"D:\Program Files1\Python\python.exe" D:/Pycharm-work/pythonTest/жү“еҚЎ/0811иҜ»еҸ–pdf.py
<pdfplumber.pdf.PDF object at 0x0000000002846278>
<class 'pdfplumber.pdf.PDF'>
pdfж–ҮжЎЈдҝЎжҒҜ: {'Author': '', 'Comments': '', 'Company': '', 'CreationDate': "D:20220812102327+02'23'", 'Creator': 'WPS иЎЁж ј', 'Keywords': '', 'ModDate': "D:20220812102327+02'23'", 'Producer': '', 'SourceModified': "D:20220812102327+02'23'", 'Subject': '', 'Title': '', 'Trapped': 'False'}
pdfж–ҮжЎЈжҖ»йЎөж•°: 2
pdfйЎөз Ғ: 1
pdfйЎөе®Ҫ: 595.25
pdfйЎөй«ҳ: 841.85
姓еҗҚ е№ҙйҫ„ жҖ§еҲ« ең°еқҖ еӯҰд№ жҠҖиғҪ
еј дёү 20 еҘі еҢ—дә¬ python
жқҺеӣӣ 25 з”· ж·ұеңі java
иөөдә” 28 з”· дёҠжө· C++
еӯҷе…ӯ 23 еҘі е№ҝе·һ python
й’ұдёғ 27 з”· зҸ жө· python
еј 101 20 еҘі еҢ—дә¬ python
.......
.......
еј 150 27 з”· зҸ жө· python
еј 151 20 еҘі еҢ—дә¬ python
еј 152 25 з”· ж·ұеңі javaProcess finished with exit code 0
import pdfplumber
import xlwt
# еҠ иҪҪpdf
path = "C:/Users/Administrator/Desktop/test08/test11 - еӨҡйЎө.pdf"
with pdfplumber.open(path) as pdf:
page_1 = pdf.pages[0] # pdf第дёҖйЎө
table_1 = page_1.extract_table() # иҜ»еҸ–иЎЁж јж•°жҚ®
print(table_1)
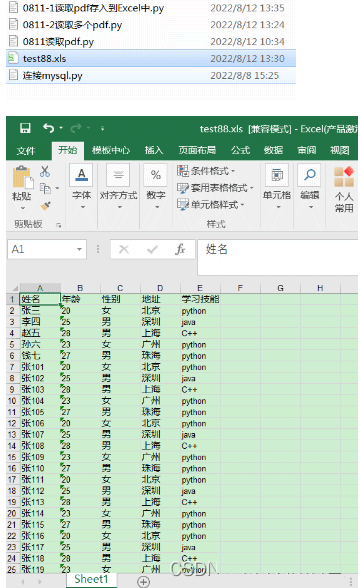
# 1.еҲӣе»әExcelеҜ№иұЎ
workbook = xlwt.Workbook(encoding='utf8')
# 2.ж–°е»әsheetиЎЁ
worksheet = workbook.add_sheet('Sheet1')
# 3.иҮӘе®ҡд№үеҲ—еҗҚ
clo1 = table_1[0]
# 4.е°ҶеҲ—иЎЁе…ғз»„clo1еҶҷе…ҘsheetиЎЁеҚ•дёӯзҡ„第дёҖиЎҢ
for i in range(0, len(clo1)):
worksheet.write(0, i, clo1[i])
# 5.е°Ҷж•°жҚ®еҶҷиҝӣsheetиЎЁеҚ•дёӯ
for i in range(0, len(table_1[1:])):
data = table_1[1:][i]
for j in range(0, len(clo1)):
worksheet.write(i + 1, j, data[j])
# дҝқеӯҳExcelж–Ү件еҲҶдёӨз§Қ
workbook.save('test88.xls')жү§иЎҢз»“жһңпјҡ
ж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҢд»ҘдёҠе°ұжҳҜвҖңPythonж“ҚдҪңpdf pdfplumberиҜ»еҸ–PDFеҶҷе…ҘExceвҖқзҡ„еҶ…е®№дәҶпјҢз»ҸиҝҮжң¬ж–Үзҡ„еӯҰд№ еҗҺпјҢзӣёдҝЎеӨ§е®¶еҜ№Pythonж“ҚдҪңpdf pdfplumberиҜ»еҸ–PDFеҶҷе…ҘExceиҝҷдёҖй—®йўҳжңүдәҶжӣҙж·ұеҲ»зҡ„дҪ“дјҡпјҢе…·дҪ“дҪҝз”Ёжғ…еҶөиҝҳйңҖиҰҒеӨ§е®¶е®һи·өйӘҢиҜҒгҖӮиҝҷйҮҢжҳҜдәҝйҖҹдә‘пјҢе°Ҹзј–е°ҶдёәеӨ§е®¶жҺЁйҖҒжӣҙеӨҡзӣёе…ізҹҘиҜҶзӮ№зҡ„ж–Үз« пјҢж¬ўиҝҺе…іжіЁпјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ