您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
在向Hbase中写入数据时,常见的写入方法有使用HBase API,Mapreduce批量导入数据,使用这些方式带入数据时,一条数据写入到HBase数据库中的大致流程如图。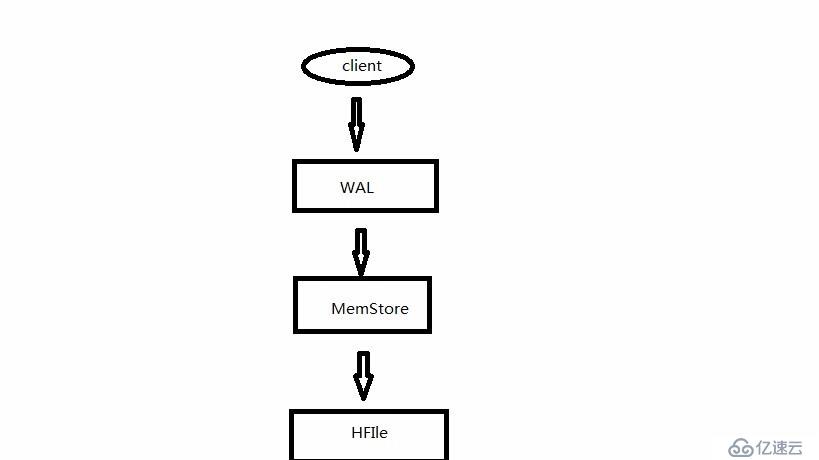
数据发出后首先写入到雨鞋日志WAl中,写入到预写日志中之后,随后写入到内存MemStore中,最后在Flush到Hfile中。这样写数据的方式不会导致数据的丢失,并且道正数据的有序性,但是当遇到大量的数据写入时,写入的速度就难以保证。所以,介绍一种性能更高的写入方式BulkLoad。
使用BulkLoad批量写入数据主要分为两部分:
一、使用HFileOutputFormat2通过自己编写的MapReduce作业将HFile写入到HDFS目录,由于写入到HBase中的数据是按照顺序排序的,HFileOutputFormat2中的configureIncrementalLoad()可以完成所需的配置。
二、将Hfile从HDFS移动到HBase表中,大致过程如图
实例代码pom依赖:
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.4.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.4</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>0.99.2</version>
</dependency>package com.yangshou;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class BulkLoadMapper extends Mapper<LongWritable, Text, ImmutableBytesWritable, Put> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//读取文件中的每一条数据,以序号作为行键
String line = value.toString();
//将数据进行切分
//切分后数组中的元素分别为:序号,用户id,商品id,用户行为,商品分类,时间,地址
String[] str = line.split(" ");
String id = str[0];
String user_id = str[1];
String item_id = str[2];
String behavior = str[3];
String item_type = str[4];
String time = str[5];
String address = "156";
//拼接rowkey和put
ImmutableBytesWritable rowkry = new ImmutableBytesWritable(id.getBytes());
Put put = new Put(id.getBytes());
put.add("info".getBytes(),"user_id".getBytes(),user_id.getBytes());
put.add("info".getBytes(),"item_id".getBytes(),item_id.getBytes());
put.add("info".getBytes(),"behavior".getBytes(),behavior.getBytes());
put.add("info".getBytes(),"item_type".getBytes(),item_type.getBytes());
put.add("info".getBytes(),"time".getBytes(),time.getBytes());
put.add("info".getBytes(),"address".getBytes(),address.getBytes());
//将数据写出
context.write(rowkry,put);
}
}
package com.yangshou;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.HFileOutputFormat2;
import org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class BulkLoadDriver {
public static void main(String[] args) throws Exception {
//获取Hbase配置
Configuration conf = HBaseConfiguration.create();
Connection conn = ConnectionFactory.createConnection(conf);
Table table = conn.getTable(TableName.valueOf("BulkLoadDemo"));
Admin admin = conn.getAdmin();
//设置job
Job job = Job.getInstance(conf,"BulkLoad");
job.setJarByClass(BulkLoadDriver.class);
job.setMapperClass(BulkLoadMapper.class);
job.setMapOutputKeyClass(ImmutableBytesWritable.class);
job.setMapOutputValueClass(Put.class);
//设置文件的输入输出路径
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(HFileOutputFormat2.class);
FileInputFormat.setInputPaths(job,new Path("hdfs://hadoopalone:9000/tmp/000000_0"));
FileOutputFormat.setOutputPath(job,new Path("hdfs://hadoopalone:9000/demo1"));
//将数据加载到Hbase表中
HFileOutputFormat2.configureIncrementalLoad(job,table,conn.getRegionLocator(TableName.valueOf("BulkLoadDemo")));
if(job.waitForCompletion(true)){
LoadIncrementalHFiles load = new LoadIncrementalHFiles(conf);
load.doBulkLoad(new Path("hdfs://hadoopalone:9000/demo1"),admin,table,conn.getRegionLocator(TableName.valueOf("BulkLoadDemo")));
}
}
}
实例数据
44979 100640791 134060896 1 5271 2014-12-09 天津市
44980 100640791 96243605 1 13729 2014-12-02 新疆
在Hbase shell 中创建表
create 'BulkLoadDemo','info'打包后执行
```hadoop jar BulkLoadDemo-1.0-SNAPSHOT.jar com.yangshou.BulkLoadDriver
注意:在执行hadoop jar之前应该先将Hbase中的相关包加载过来export HADOOP_CLASSPATH=$HBASE_HOME/lib/*
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。