您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
甲方和乙方的数据科学家都要用各种界面化工具来做数据科学家的工作,所以,我们从zeppelin搞到了jupyterlab,再从lab整到了hub。
对于甲方数据科学家的编程水平,实在是无法恭维却还要硬着头皮恭维。这辈子能看到把python写成pig的机会不多。数据科学家的脑回路那是相当的PigLatinic的。这个,写过pig的人应该能明白。
不过,我只想记录一下工作过程,以后其他甲方要用的时候,我自己能用得上。
环境 Anaconda3 + Jupyterhub + Spark2.1 + CDH 5.14 + Kerberos
一、Hub与Spark的集成
anaconda怎么装jupyterhub和生成配置文件就不说了,网上一大堆。
鉴于数据科学家只会用python,所以基于toree的各种其他语言解释器就先不记录了。只有spark的话,还是挺简单的。我是创建了一个文件
/usr/share/jupyter/kernels/pyspark2/kernel.json 路径不存在的话就自己创建一个,文件不存在的话就自己vi一个。内容如下
{
"argv": [
"python3.6",
"-m",
"ipykernel_launcher",
"-f",
"{connection_file}"
],
"display_name": "Python3.6+PySpark2.1",
"language": "python",
"env": {
"PYSPARK_PYTHON": "/opt/anaconda3/bin/python",
"SPARK_HOME": "/opt/spark-2.1.3-bin-hadoop2.6",
"HADOOP_CONF_DIR": "/etc/hadoop/conf",
"HADOOP_CLIENT_OPTS": "-Xmx2147483648 -XX:MaxPermSize=512M -Djava.net.preferIPv4Stack=true",
"PYTHONPATH": "/opt/spark-2.1.3-bin-hadoop2.6/python/lib/py4j-0.10.7-src.zip:/opt/spark-2.1.3-bin-hadoop2.6/python/",
"PYTHONSTARTUP": "/opt/spark-2.1.3-bin-hadoop2.6/python/pyspark/shell.py",
"PYSPARK_SUBMIT_ARGS": " --master yarn --deploy-mode client --name JuPysparkHub测试 pyspark-shell"
}
}然后就没有然后了。
二、Jupyterhub + 无LDAP的独立Kerberos集成
由于集群是独立的Kerberos体系,并没有与系统的PAM和LDAP结合起来,所以,这里需要修改Jupyter代码。
如果集群是KRB5与LDAP结合的系统,可以忽略改代码,Jupyterhub本身官方就有LDAP认证的插件。
基于我对Jupyterhub源码的理解,Hub本身启动时是启动了一个多用户认证的外壳程序,这个外壳程序会基于对每个用户的认证,使用该用户的linux账号去启动notebook。
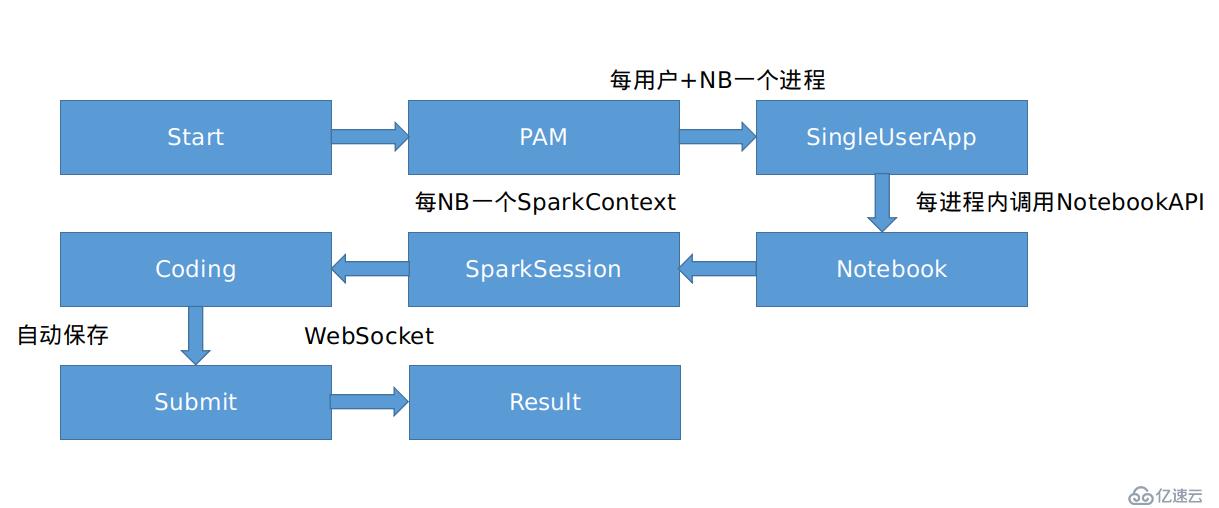
这是我阅读Hub源码总结的架构流程,不一定准确,大概是个意思吧。NB就是NoteBook,不是牛逼的意思。
所以Hub其实最终启动Notebook启动的是一个新的jupyter-notebook的进程,而且是以登录用户的环境变量启动的。那么就有两种思路来初始化kerberos principal。
思路一:
使用系统用户的环境变量来做kinit,好处是kinit写在用户的.bash_profile或.bashrc文件里,只要调用这个用户的环境变量就可以直接kinit,无需修改任何代码。坏处是,要是kinit过期了,就得重新打开notebook,存在可能会导致编辑内容丢失的风险。
思路二:
修改hub相关代码,将kinit做到nb里面去,这样就无所谓系统环境变量,尤其hub有个自动保存的机制,前端会定期发送保存笔记的请求给后端api,如果找到api就可以完成这个功能,这样kinit就是定期刷新的,只要开着nb,kerberos的ticket就永不过期。
考虑到甲方数据科学家是一群除了会写pyspparksql而其他方面是毫无自理能力和学习能力的唐氏综合征,我决定采用第二种方案。给唐爸爸省事,也是给自己省事,一劳永逸。
那么根据hub的流程架构和思路二,我只需要修改notebook本身的kinit认证即可。不过为了保险,我把hub的登录验证外壳也一起改了。
由于hub和nb系列都是tornado写的,改起来倒也容易。
首先是要写一段简单粗暴的python代码来做kinit验证。
def kinit(self, username):
"""
add by xianglei
"""
import os
from subprocess import Popen, PIPE
uid_args = ['id', '-u', username]
uid = Popen(uid_args, stdin=PIPE, stdout=PIPE, stderr=PIPE)
uid = uid.communicate()[0].decode().strip()
gid_args = ['id', '-g', username]
gid = Popen(gid_args, stdin=PIPE, stdout=PIPE, stderr=PIPE)
gid = gid.communicate()[0].decode().strip()
self.log.info('UID: ' + uid + ' GID: ' + gid)
self.log.info('Authenticating: ' + username)
realm = 'XX.COM'
kinit = '/usr/bin/kinit'
krb5cc = '/tmp/krb5cc_%s' % (uid,)
keytab = '/home/%s/%s.wb1.keytab' % (username, username)
principal = '%s/pg-dmp-workbench2@%s' % (username, realm,)
kinit_args = ['kinit', '-kt', keytab, '-c', krb5cc, principal]
self.log.info('Running: ' + ' '.join(kinit_args))
kinit = Popen(kinit_args, stdin=PIPE, stdout=PIPE, stderr=PIPE)
self.log.info(kinit.communicate())
ans = None
import os
if os.path.isfile(krb5cc):
os.chmod(krb5cc, 0o600)
os.chown(krb5cc, int(uid), int(gid))
ans = username
return ans都是直接调用操作系统命令,可以说是相当粗暴了。
然后找到 jupyterhub源码包里面的 auth.py,不要问我源码在哪里,如果找不到python第三方module的安装位置,那么跟数据科学家有什么区别。
找到 authenticate方法,改成下面。
@run_on_executor
def authenticate(self, handler, data):
"""Authenticate with PAM, and return the username if login is successful.
Return None otherwise.
"""
username = data['username']
try:
pamela.authenticate(username, data['password'], service=self.service, encoding=self.encoding)
username = self.kinit(username)
except pamela.PAMError as e:
if handler is not None:
self.log.warning("PAM Authentication failed (%s@%s): %s", username, handler.request.remote_ip, e)
else:
self.log.warning("PAM Authentication failed: %s", e)
else:
if not self.check_account:
return username
try:
pamela.check_account(username, service=self.service, encoding=self.encoding)
username = self.kinit(username)
except pamela.PAMError as e:
if handler is not None:
self.log.warning("PAM Account Check failed (%s@%s): %s", username, handler.request.remote_ip, e)
else:
self.log.warning("PAM Account Check failed: %s", e)
else:
return username这样 hub 在登录的时候就可以先做一次kinit认证,其实没什么用。但当我面对比集群机器还多的唐氏患者时,我还是需要一些心理安慰的。
然后找到 notebook 的 notebook/handler.py 文件,修改如下。
class NotebookHandler(IPythonHandler):
@web.authenticated
def get(self, path):
"""get renders the notebook template if a name is given, or
redirects to the '/files/' handler if the name is not given."""
path = path.strip('/')
cm = self.contents_manager
# will raise 404 on not found
try:
model = cm.get(path, content=False)
except web.HTTPError as e:
if e.status_code == 404 and 'files' in path.split('/'):
# 404, but '/files/' in URL, let FilesRedirect take care of it
return FilesRedirectHandler.redirect_to_files(self, path)
else:
raise
if model['type'] != 'notebook':
# not a notebook, redirect to files
return FilesRedirectHandler.redirect_to_files(self, path)
name = path.rsplit('/', 1)[-1]
username = self.current_user['name']
self.kinit(username)
self.write(self.render_template('notebook.html',
notebook_path=path,
notebook_name=name,
kill_kernel=False,
mathjax_url=self.mathjax_url,
mathjax_config=self.mathjax_config,
get_custom_frontend_exporters=get_custom_frontend_exporters
)
)以上代码的作用是在打开notebook的时候就做kinit认证。
然后打开 notebook的 service/contents/handlers.py
@gen.coroutine
def _save(self, model, path):
"""Save an existing file."""
chunk = model.get("chunk", None)
if not chunk or chunk == -1: # Avoid tedious log information
self.log.info(u"Saving file at %s", path)
if 'name' in self.current_user:
if isinstance(self.current_user['name'], str):
self.kinit(self.current_user['name'])
#pass
model = yield gen.maybe_future(self.contents_manager.save(model, path))
validate_model(model, expect_content=False)
self._finish_model(model)以上代码的作用是在notebook做自动或手动保存时就触发kinit认证。
各种保险措施做足,国际脸的唐氏患者们表示生活很幸福快乐,露出了久违的微笑。
三、hub与nginx反代集成多域名和SSL。
我作为一个正常人是永远猜不透唐氏患者内心在想什么,他们永远有办法让乙方永无休止的干活,或许这样他们就能打着系统升级的旗号不干活了。所以,IP不能访问吗?为啥非要弄个域名呢?
而且我们的集群环境是分为业务***和管理***的,两个***绑定的域名是不一样的,然后都需要SSL连接。
这里有点麻烦的是,Jupyter是禁止跨域访问的。SSL加上反代其实配置不难,难的是跨域访问,其实跨域访问也不难,难的是如何杀死这些数据科学家。
upstream hub10000 {
server 172.16.191.110:10000;
}
server {
listen 30000;
server_name mgmthub.xxx.cn buhub.xxx.cn;
ssl on;
ssl_certificate_key cert/xxx.cn.key;
ssl_certificate cert/xxx.cn.crt;
ssl_ciphers ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-AES256-SHA384:ECDHE-RSA-AES256-SHA384:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES128-SHA256:ECDHE-RSA-AES128-SHA256:ECDHE-ECDSA-RC4-SHA:!ECDHE-RSA-RC4-SHA:ECDH-ECDSA-RC4-SHA:ECDH-RSA-RC4-SHA:ECDHE-RSA-AES256-SHA:!RC4-SHA:HIGH:!aNULL:!eNULL:!LOW:!3DES:!MD5:!EXP:!CBC:!EDH:!kEDH:!PSK:!SRP:!kECDH;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
ssl_session_cache shared:SSL:10m;
ssl_prefer_server_ciphers on;
ssl_session_timeout 1d;
ssl_stapling on;
ssl_stapling_verify on;
add_header Strict-Transport-Security "max-age=31536000; includeSubdomains;";
add_header X-Frame-Options SAMEORIGIN;
add_header X-Content-Type-Options nosniff;
add_header X-XSS-Protection "1; mode=block";
add_header Content-Security-Policy "default-src 'self';style-src 'self' 'unsafe-inline';script-src 'self' 'unsafe-inline' 'unsafe-eval';font-src 'self' data:;connect-src 'self' wss:;img-src 'self' data:;";
location / {
proxy_pass http://hub10000;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_set_header Origin "";
include proxy.conf;
}
}proxy.conf
proxy_redirect off; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Nginx-Proxy true; proxy_connect_timeout 604800; proxy_send_timeout 604800; proxy_read_timeout 604800; proxy_buffer_size 64k; proxy_buffers 64 32k; proxy_busy_buffers_size 128k; proxy_temp_file_write_size 64k; proxy_next_upstream error timeout invalid_header http_500 http_503 http_404; proxy_max_temp_file_size 128m; client_body_temp_path client_body 1 2; proxy_temp_path proxy_temp 1 2;
110:10000是jupyterhub监听地址,是另一台机器。
然后加上
proxy_set_header Origin "";
就可以解决tornado的跨域访问问题,无需修改jupyterhub的配置里的 bind_url设置。
对文中提到唐氏患者致歉,虽然我知道用唐氏患者类比甲方数据科学家是对唐氏患者的不尊重,但才疏学浅,确实找不到合适的词汇来比喻甲方数据科学家。我本身并不歧视唐氏患者,我歧视的是数据科学家。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。