您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本文首发于 vivo互联网技术 微信公众号
链接:https://mp.weixin.qq.com/s/WlT8070LlrnSODFRDwZsUQ
作者:吴越
开坑这个系列的原因,主要是在大前端学习的过程中遇到了不少跟web协议有关的问题,之前对这一块的了解仅限于用charles抓个包,基本功欠缺。强迫症发作的我决定这一次彻底将web协议搞懂搞透,如果你遇到了和我一样的问题,例如
对http的了解,仅限于charles抓个包。
对https的了解仅限于大概知道tls,ssl,对称加密,非对称加密。真正一次完整的交互过程,无法做到心中有数。
对h6的各种缓存字段,了解的不够。
移动端各种深度弱网优化的文章因为基本功不扎实的原因各种看不懂。
有时作为移动端开发在定技术方案的时候,因为对前端或者服务器缺乏基本的了解,无法据理力争制定出更完美的方案。
移动端中的网页加载出了问题只能求助于前端工程师,无法第一时间自己定位问题。
每次想深度学习web协议的时候,因为不会写服务端程序导致只能泛泛而读,随意找几篇网上的博客就得过且过了,并没有真正解决心中的疑惑。没有实际动手过。
没有实际对照过浏览器和Android端使用okhttp在发送网络请求的时候有什么不同。
希望这个系列的文章可以帮助到和我一样对web协议有困惑的工程师们。本系列文章中所有的服务端程序均使用 Go语言开发完成。抓包工具使用的是wireshark,没有使用charles是因为charles看不到传输层的东西,不利于我理解协议的本质。本系列文章没有复制粘贴网上太多概念性的东西,以代码和wireshark抓包为主。概念性的东西需要读者自行搜索。实战有助于真正理解协议本身。
本文主要分为四块,如果觉得文章过长可以自行选择感兴趣的模块阅读:
chrome network面板的使用:主要以一个移动端工程师的视角来看chrome的network模块,主要列举了我认为可能会对定位h6问题有帮助的几个知识点。
Connection-keeplive:主要阐述了现在客户端/前端与服务端交互的方式,简略介绍了服务端大概的样子。
http 队头拥塞: 主要以若干个实验来理解http 队头拥塞的本质,并给出okhttp与浏览器在策略上的不同。
打开商城的页面,打开chrome控制台。

注意看红色标注部分,左边disable cache 代表关闭浏览器缓存,打开这个选项之后,每次访问页面都会重新拉取而不是使用缓存,右边的online可以下拉菜单选择弱网环境下访问此页面。在模拟弱网环境的时候此方法通常非常有效。例如我们正常访问的时候,耗时仅仅2s。

打开弱网(fast 3g)

时间膨胀到了26s.
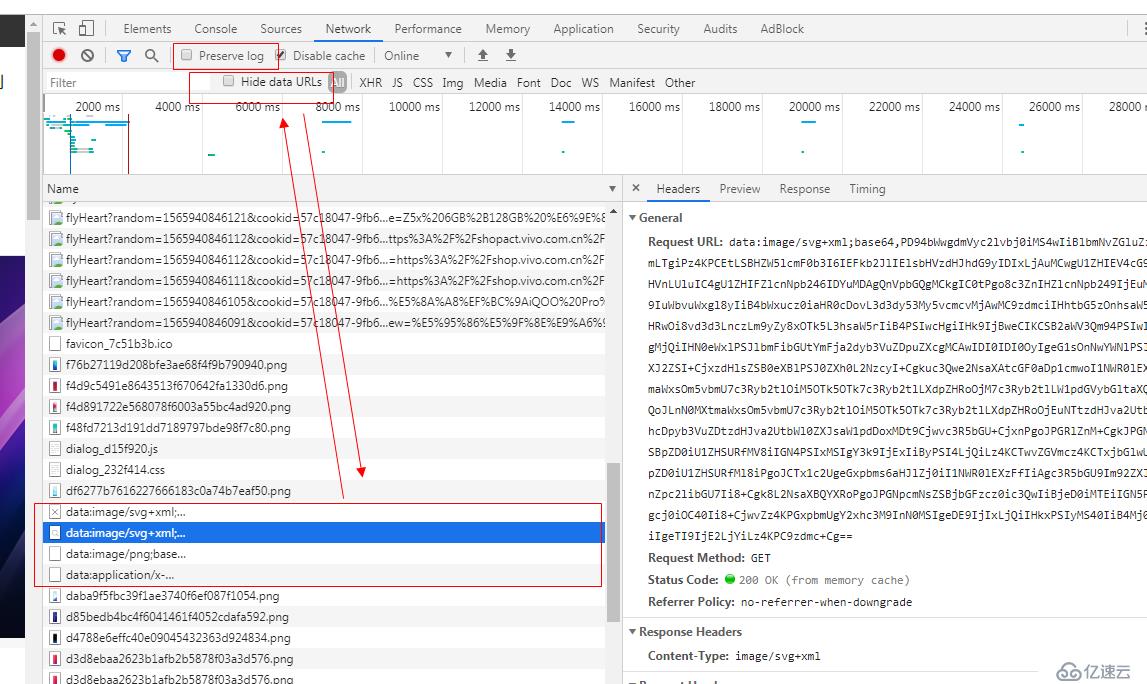
这里说一下这2个选项的作用,Preserve log主要就是保存前一个页面的请求日志,比如我们在当前页面a点击了一个超链接访问了页面b,那么页面a的请求在控制台就看不到了,如果勾选此选项那么就可以看到这个前面一个页面的请求。另外这个Hide data Urls,选项额外说明一下,有些h6页面的某些资源会直接用base64转码以后嵌入到代码里面(比如截图中data: 开头的东西),这样做的好处是可以省略一些http请求,当然坏处就是开启此选项浏览器针对这个资源就没有缓存了,且base64转码以后的体积大小要比原大小大4/3。我们可以勾选此选项过滤掉这种我们不想看的东西。
再比如,我们只想看看同一个页面下某一个域名的请求(这在做竞品分析时对竞品使用域名数量的分析很有帮助),那我们也可以如下操作:

再比如说我们只想看一下这个页面的post请求,或者是get请求也可以。
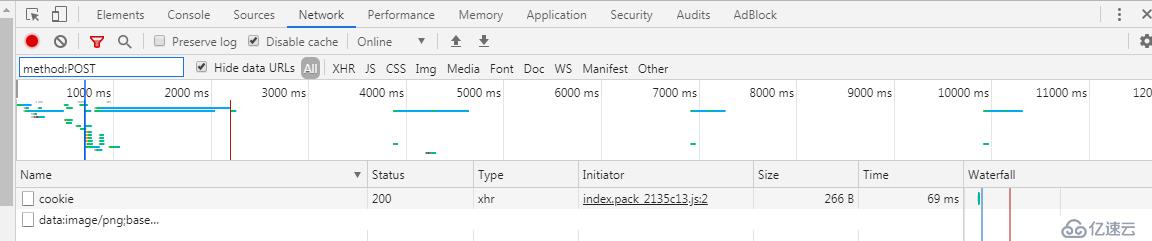
再比如我们可以用 is:from-cache 查看我们当前页面哪些资源使用了缓存。large-than:(单位是字节)这个也很有用,通常我们利用这个过滤出超出大小的请求,看看有多少超大的图片资源(移动端排查h6页面速度慢的一个手段)。
我们也可以点击其中一个请求,按住shift,注意看蓝色的就是我们选定的请求,绿色的代表这个请求是蓝色请求的上游,也就是说只有当绿色的请求执行完毕以后才会发出蓝色的请求,而红色的请求就代表只有蓝色的请求执行完毕以后才会请求。这种看请求上下游关系的方法是很多时候h6优化的一个技巧。将用户最关心的资源请求前移,可以极大优化用户体验,虽然在某种程度上这种行为并不会在数据上有所提高(例如activity之间跳转用动画,application启动优化用特殊theme等等,本质上耗时都没有减少,但给用户的感觉就是页面和app速度很快)。
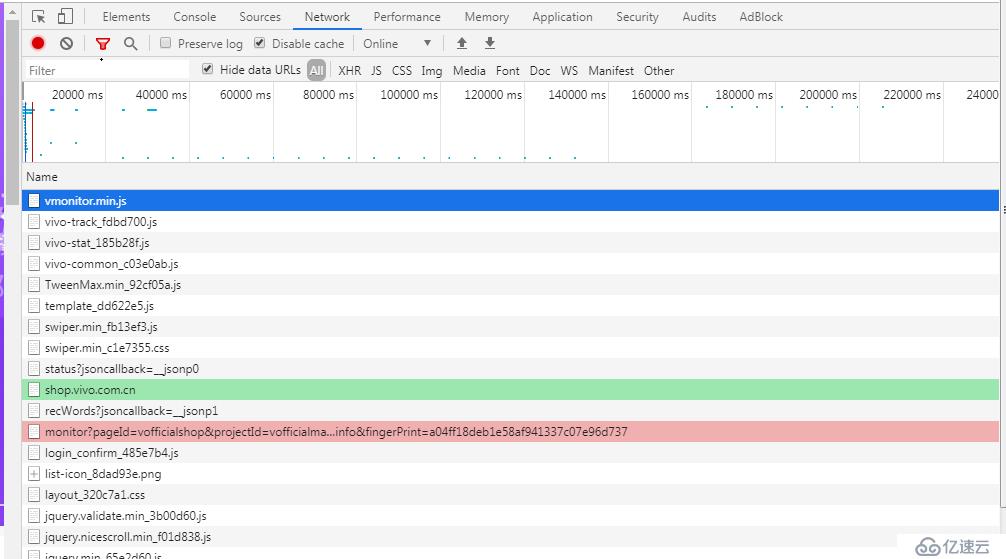
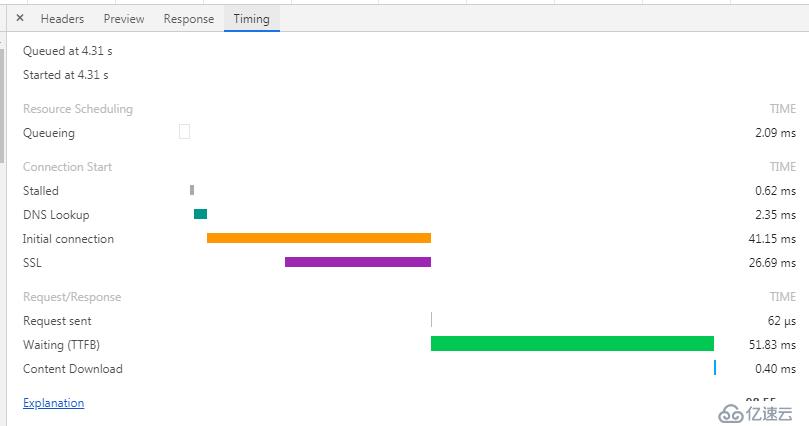
这个timing 可以显示一个请求的详细分段时间,比如排队时间,发出请求到第一个请求响应的字节时间,以及整个response都传输完毕的时间等等。有兴趣的可以自行搜索下相关资料。
在现代服务器架构中,客户端的长连接大部分时候并不是直接和源服务器打交道(所谓源服务器可以粗略理解为服务端开发兄弟实际代码部署的那台服务器),而是会经过很多代理服务器,这些代理服务器有的负责防火墙,有的负责负载均衡,还有的负责对消息进行路由分发(例如对客户端的请求根据客户端的版本号,ios还是Android等等分别将请求映射到不同的节点上)等等。
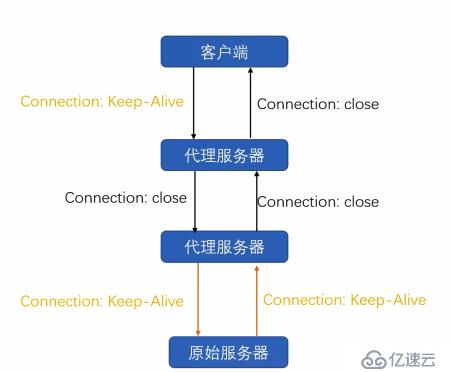
客户端的长连接仅仅意味着客户端发起的这条tcp连接是和第一层代理服务器保持连接关系。并不会直接命中到原始服务器。
再看一张图:
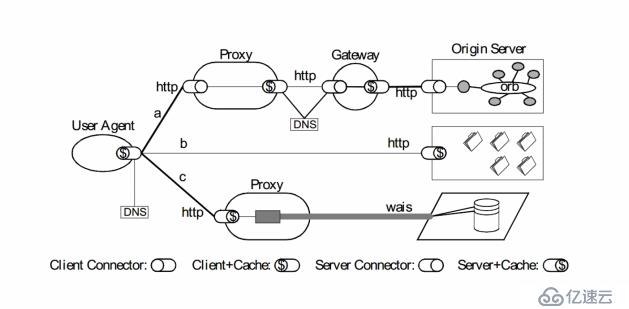
通常来讲,我们的请求客户端发出以后会经过若干个代理服务器才会到我们的源服务器。如果我们的源服务器想基于客户端的请求的ip地址来做一些操作,理论上就需要额外的http头部支持了。因为基于上述的架构图,我们的源服务器拿到的地址是跟源服务器建立tcp连接的代理服务器的地址,压根拿不到我们真正发起请求的客户端ip地址。
http RFC规范中,规定了X-Forwarded-For 用于传递真正的ip地址。当然了在实际应用中有些代理服务器并不遵循此规定,例如Nginx就是利用的X-Real-IP 这个头部来传递真正的ip地址(Nginx默认不开启此配置,需要手动更改配置项)。
在实际生产环境中,我们是可以在http response中将上述经过的代理服务器信息一一返回给客户端的。
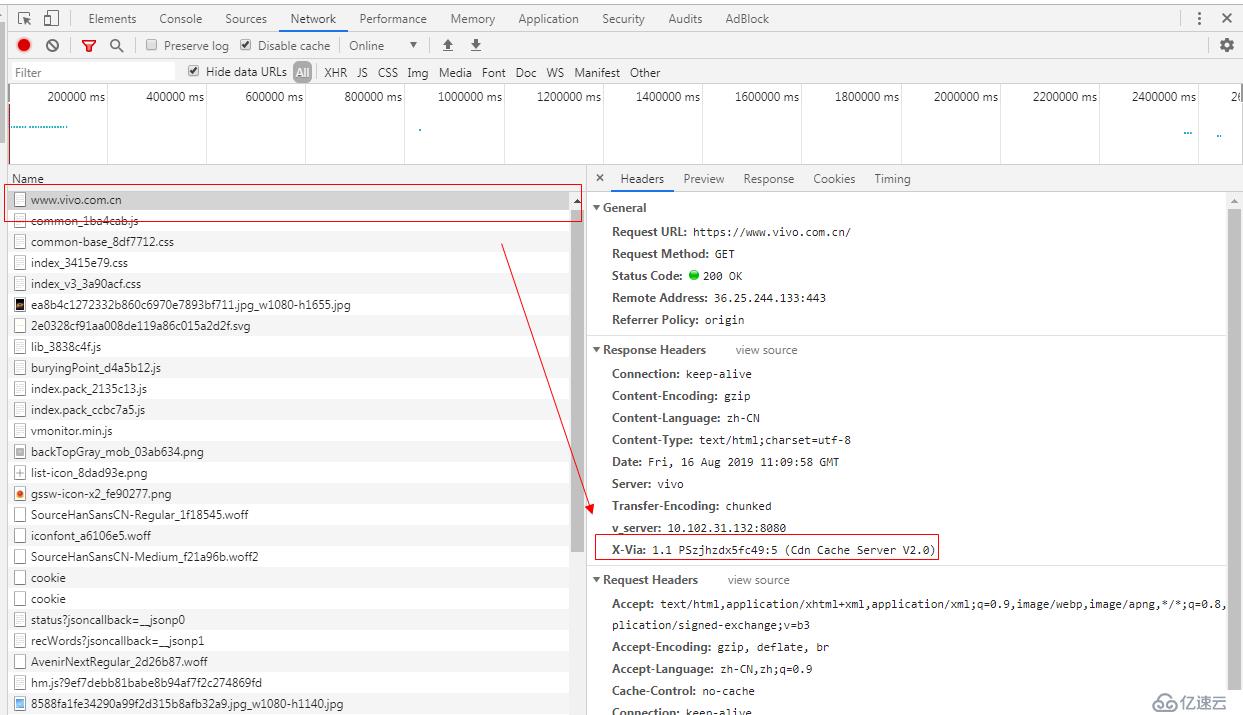
看这个reponse的返回里面的头部信息有一个X-via 里面的信息就是代理服务器的信息了。
再比如说 我们打开淘宝的首页,找个请求。
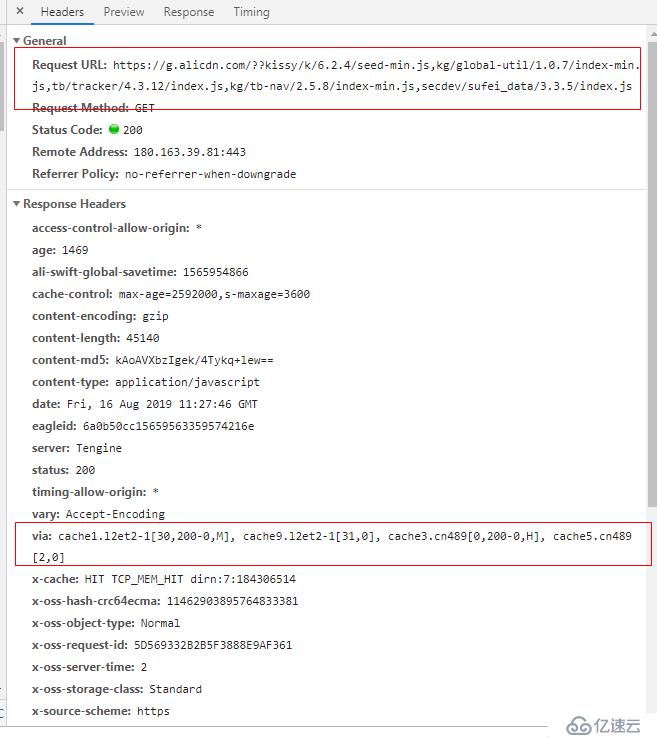
这里的代理服务器信息就更多了,说明这条请求经过了多个代理服务器的转发。另外有时我们在技术会议上会听到正向代理和反向代理,其实这2种代理都是指的代理服务器,作用都差不多,只不过应用的场景有一些区别。
正向代理:比如我们kexue上网的时候,这种是我们明确知道我们想访问外网的网站比如facebook、谷歌等等,我们可以主动将请求转发到一个代理服务器上,由代理服务器来转发请求给facebook,然后facebook将请求返回给代理服务器,服务器再转发给我们。这种就叫正向代理了。
反向代理:这个其实我们每天都在用,我们访问的服务器,99%都是反向代理而来的,现代计算机系统中指的服务器往往都是指的服务器集群了,我们在使用一个功能的时候,根本不知道到底要请求到哪一台服务器,通常这种情况都是由Nginx来完成,我们访问一个网站,dns返回给我们的地址,通常都是一台Nginx的地址,然后由Nginx自己来负责将这个请求转发给他觉得应该转发的那台服务器。
这里我们多次提到了Nginx服务器和代理服务器的概念,考虑到很多前端开发可能不太了解后端开发的工作,暂且在这里简单介绍一下。通常而言我们认为的服务器开发工程师每天大部分的工作都是在应用服务器上开发,所谓http的应用服务器就是指可以动态生成内容的http服务器。比如 java工程师写完代码以后打出包交给Tomcat,Tomcat本身就是一个应用服务器。再比如Go语言编译生成好的可执行文件,也是一个http的应用服务器,还有Python的simpleServer等等。而Nginx或者Apache更像是一个单纯的http server,这个单纯的http server 几乎没有动态生成http response的能力,他们只能返回静态的内容,或者做一次转发,是一个很单纯的http server。严格意义上说,不管是Tomcat还是Go语言编译出来的可执行文件还是Python等等,本质上他们也是http server,也可以拿来做代理服务器的,只是通常情况下没有人这么干,因为术业有专攻,这种工作通常而言都是交给Nginx来做。
下图是Nginx的简要介绍:用一个Master进程来管理n个worker进程,每个worker进程仅有一个线程在执行。
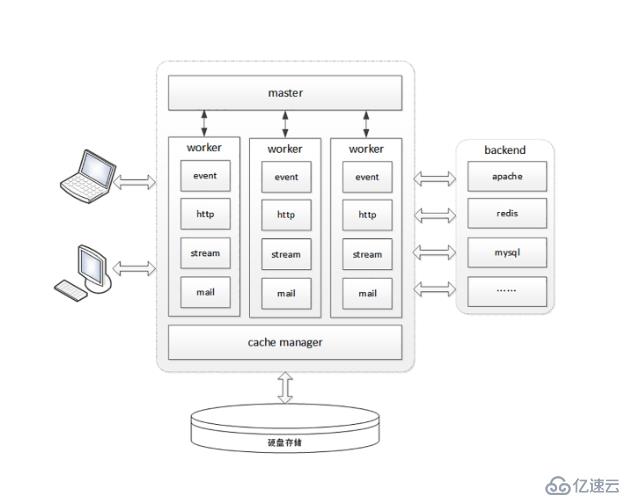
在Nginx之前,多数服务器都是开启多线程或者多进程的工作模式,然而进程或者线程的切换是有成本的,如果访问量过高,那么cpu就会消耗大量的资源在创建进程或者创建线程,还有线程和进程之前的切换上,而Nginx则没有使用类似的方案,而是采用了“进程池单线程”的工作模式,Nginx服务器在启动的时候会创建好固定数量的进程,然后在之后的运行中不会再额外创建进程,而且可以将这些进程和cpu绑定起来,完美的使用现代cpu中的多核心能力。

此外,web服务器有io密集型的特点(注意是io密集不是cpu密集),大部分的耗时都在网络开销而非cpu计算上,所以Nginx使用了io多路复用的技术,Nginx会将到来的http请求一一打散成一个个碎片,将这些碎片安排到单一的线程上,这样只要发现这个线程上的某个碎片进入io等待了就立即切换出去处理其他请求,等确定可读可写以后再切回来。这样就可以最大限度的将cpu的能力利用到极致。注意再次强调这里的切换不是线程切换,你可以把他理解为这个线程中要执行的程序里面有很多go to 的锚点,一旦发现某个执行碎片进入了io等待,就马上利用go to能力跳转到其他碎片(这里的碎片就是指的http请求了)上继续执行。
其实这个地方Nginx的工作模式有一点点类似于Go语言的协程机制,只不过Go语言中的若干个协程下面并不是只有一个线程,也可能有多个。但是思路都是一样的,就是降低线程切换的开销,尽量用少的线程来执行业务上的“高并发”需求。
然而Nginx再优秀,也抵不过岁月的侵蚀,说起来距离今天也有15年的时间了。还是有一些天生缺陷的,比如Nginx只要你修改了配置就必须手动将Nginx进程重启(master进程),如果你的业务非常庞大,一旦遇到要修改配置的情况,几百台甚至几千台Nginx手动修改配置重启不但容易出错而且重复劳动意义也不大。此外Nginx可扩展性一般,因为Nginx是c语言写的,我们都知道c语言其实还是挺难掌握的,尤其是想要掌握的好更加难。不是每个人都有信心用C语言写出良好可维护的代码。尤其你的代码还要跑在Nginx这种每天都要用的基础服务上。
基于上述缺陷,阿里有一个绰号为“春哥”的程序员章亦春,在Nginx的基础上开发了更为优秀的OpenResty开源项目,也是老罗锤子发布会上说要赞助的那个开源项目。此项目可以对外暴露Lua脚本的接口,80后玩过魔兽世界的同学一定对Lua语言不陌生,大名鼎鼎的魔兽世界的插件机制就是用Lua来完成的。OpenResty出现以后终于可以用Lua脚本语言来操作我们的Nginx服务器了,这里Lua也是用“协程”的概念来完成并发能力,与Go语言也是保持一致的。此外OpenResty对服务器配置的修改也可以及时生效,不需要再重启服务器。大大提高运维的效率。等等等等。。。
前文我们数次提到了服务器,高并发等关键字。我们印象中的服务器都是与高并发这3个字强关联的。那么所谓 http中的“队头拥塞”到底指的是什么呢?我们先来看一张图:
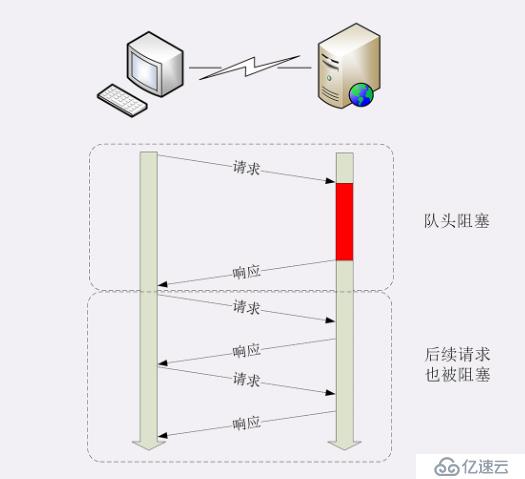
这张互联网中流传许久的图,到底应该怎么理解?有的同学认为http所谓的拥塞是因为传输协议是tcp导致的,因为tcp天生有拥塞的缺点。其实这句话并不全对。考虑如下场景:
网络情况很好。
客户端先用socket发送一组数据a,2s以后发送数据b。
服务端收到数据a 然后开始处理数据a,然后收到数据b,开始处理数据b(这里当然是开线程做)
此时服务端处理数据b的线程将数据b处理完毕以后开始将b的 responseb发到客户端,过了一段时间以后数据a的线程终于把数据处理完毕也将responsea发给客户端。
上述的通信场景就是完美诠释tcp作为全双工传输的能力了。相当于客户端和服务端是有2条传输信道在工作。所以从这个角度上来看,tcp不是导致http 协议 “队头拥塞”的根本原因。因为大家都知道http使用的传输层协议是tcp. 只有在网络环境不好的情况下,tcp作为可靠性协议,确实会出现不停重复发送数据包和等待数据包确认的情况。但是这不是http “队头拥塞“”的根本原因。
从这张图上看,似乎http 1.x 协议是只有等前面的http request的 response回来以后 后面的http request 才会发出去。但是这个角度上理解的话,服务器的效率是不是太低了一点?如果是这样的话怎么解释我们每天打开网页的速度都很快,打开app的速度也很快呢?经过一段时间的探索,我发现上述的图是针对单tcp连接来说的,所谓的http 队头拥塞 是指单条tcp连接上 才会发生。而我们与服务器的一个域名交互的时候往往不止一条tcp连接。比如说Chrome浏览器就默认了最大限度可以和一个域名有6条tcp连接,这样的话,即使有队头拥塞的现象,也可以保证我一台服务器最多可以同时处理你这个ip发出来的6条http请求了。
为什么浏览器会限制6条?按照这个理论难道不是越多的tcp连接速度就越快吗?但如果这样做每个浏览器都针对单域名开多条tcp连接来加快访问速度的话,服务器的tcp资源很快就会被耗尽,之后就是拒绝访问了。然而道高一尺魔高一丈,既然浏览器限制了单一域名最多只能使用6条tcp连接,那干脆我们在一个页面访问多个域名不就行了?实际上单一页面访问多域名也是前端优化中的一个点,浏览器只能限制你单一域名6条tcp连接,但是可没限制你一个页面可以有多个域名,我们多开几个域名不就相当于多开了几条tcp连接么?这样页面的访问速度就会大大增加了。
这里我们有人可能会觉得好奇,浏览器限制了单一域名的tcp连接数量,那么Android中我们每天使用的okhttp限制了吗?限制了多少?来看下源码:
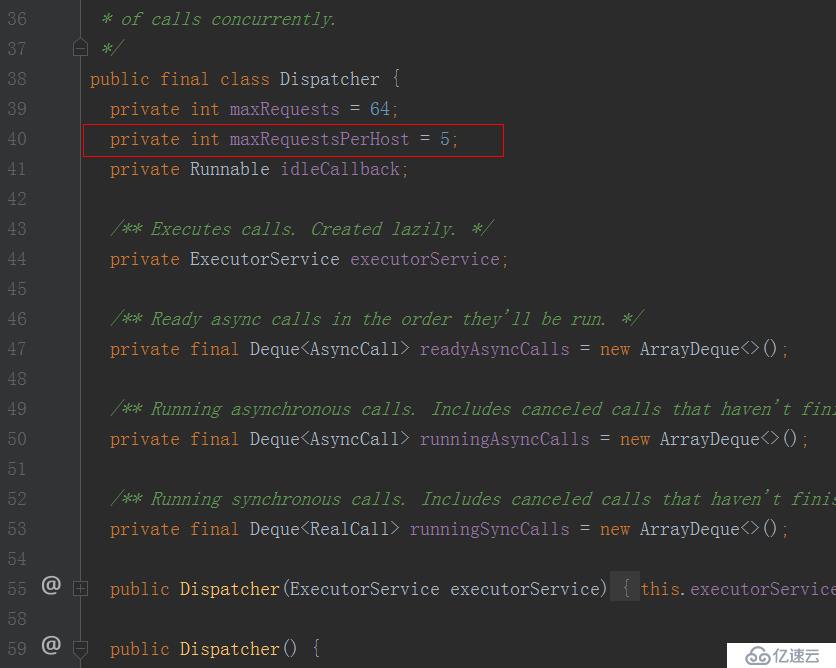
okhttp中默认对单一域名的tcp连接数量限制为5,且对外暴露了设置这个值的方法。但是问题到这里还没完,单一tcp连接上,http为什么要做成前一个消息的response回来以后,后面的http request才能发出去?这样的设计是不是有问题?速度太慢了?还是说我们理解错了?是不是还有一种可能是:
http消息可以在单一的tcp连接上 不停的发送,不需要等待前面一个http消息的返回以后再发送。
带着这个疑问,我做了一组实验,首先我们写一段服务端的代码,提供fast和slow2个接口,其中slow接口 延迟10秒返回消息,fast接口延迟5秒返回消息。
package main
import (
"io"
"net/http"
"os"
"time"
"github.com/labstack/echo"
)
func main() {
e := echo.New()
e.GET("/slow", slowRes)
e.GET("/fast", fastRes)
e.Logger.Fatal(e.Start(":1329"))
}
func fastRes(c echo.Context) error {
println("get fast request!!!!!")
time.Sleep(time.Duration(5) * time.Second)
return c.String(http.StatusOK, "fast reponse")
}
func slowRes(c echo.Context) error {
println("get slow request!!!!!")
time.Sleep(time.Duration(10) * time.Second)
return c.String(http.StatusOK, "slow reponse")
}
然后我们将这个服务器程序部署在云上,另外再写一段Android程序,我们让这个程序发http请求的时候单一域名只能使用一条tcp连接,并且设置超时时间为20s(否则默认的okhttp响应超时时间太短 等不到服务器的返回就断开连接了):
dispatcher = new Dispatcher();
dispatcher.setMaxRequestsPerHost(1);
client = new OkHttpClient.Builder().connectTimeout(20, TimeUnit.SECONDS).readTimeout(20, TimeUnit.SECONDS).dispatcher(dispatcher).build();
new Thread() {
@Override
public void run() {
Request request = new Request.Builder().get().url("http://www.dailyreport.ltd:1329/slow").build();
Call call = client.newCall(request);
call.enqueue(new Callback() {
@Override
public void onFailure(Call call, IOException e) {
Log.v("wuyue","slow e=="+e.getMessage());
}
@Override
public void onResponse(Call call, Response response) throws IOException {
Log.v("wuyue", "slow reponse==" + response.body().string());
}
});
}
}.start();
new Thread() {
@Override
public void run() {
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
Request request = new Request.Builder().get().url("http://www.dailyreport.ltd:1329/fast").build();
Call call = client.newCall(request);
call.enqueue(new Callback() {
@Override
public void onFailure(Call call, IOException e) {
Log.v("wuyue","fast e=="+e.getMessage());
}
@Override
public void onResponse(Call call, Response response) throws IOException {
Log.v("wuyue", "fast reponse==" + response.body().string());
}
});
}
}.start();
这里要注意一定要使用enqueue也就是异步的方法来发送http请求,否则你设置的域名tcp连接数量限制是失效的。然后我们用wireshark来抓包看看:

这里可以清晰的看出来,首先这2个http request 都是使用的同一条tcp连接, 都是源端口号60465到服务器1329. 然后看下time的时间,差不多0s开始发送了slow的请求,10s左右收到了slow的http response,然后马上 fast这个接口的request 就发出去了,过了5秒 fast的http response 也返回了。
如果将这个域名tcp数量限制为1改成5 那么再次抓包运行可以看到:
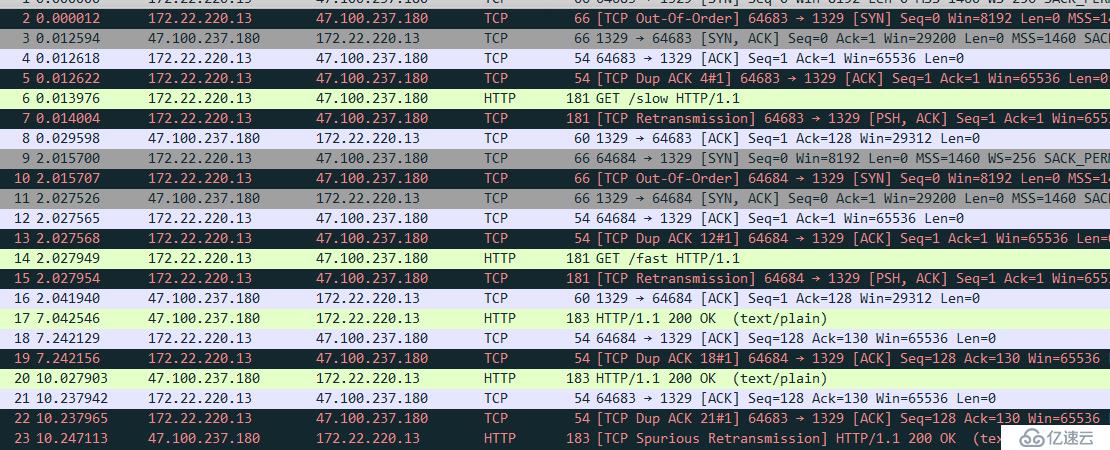
这个时候就可以清晰的看到,这一次fast大约在slow接口2秒以后就发出去了,并没有等待slow回来以后再发,且注意看这2条http消息使用的源端口号是不同的,一个是64683,一个是64684。也就是说这里使用了不同的tcp连接来传输我们的http消息。
综上所述,我们可以对http 1.x 中的“队头拥塞” 来下结论了:
所谓http1.x中的“队头拥塞”,除了本身传输层协议tcp的原因导致的tcp包拥塞机制以外,更多的是指的http 应用层上的限制。这种限制具体表现在,对于http协议来说,单条tcp连接上客户端要保证前面一条的request的response返回以后,才能发送后续的request。
http 1.x 中的 “队头拥塞” 本质上来说是由http的客户端来保证实现的。
如果你访问的网页里面的请求都指向着同一个域名,那么不管服务器有多么高的并发能力,他也最多只能同时处理你的6条http请求,因为大多数浏览器限制了针对单一域名只能开6条tcp连接。想翻过这个限制提高页面加载速度只能依靠开启多域名来实现。
经过上面的分析,我们得知其实http 1.x协议并没有完全发挥tcp 全双工通道的潜能,(也有可能是http协议出现的太早当时的设计者没有考虑现在的场景)所以从1.1协议开始,又有了一个Pipelining 也就是管道的约定。这个约定可以让http的客户端不用等前面一个request的response回来就可以继续发后面的request。但是各种原因下,现代浏览器都没有开启这个功能(相关资料感兴趣的可以自行查询Pipelining关键字,这里就不复制粘贴了)。我带着好奇搜索了一下okhttp的代码,想看看他们有没有类似的实现。最终我们在这个类中找到了线索:

看样子貌似这个tunnel的命名和我们http1.1中所谓的pipelining好似一个意思?那么okhttp中是可以使用这个浏览器默认关闭的技术了吗?继续看代码:

我们看到这个值使用的地方是来自于connectTunnel这个方法,我们看看这个方法是在connect方法里调用的:
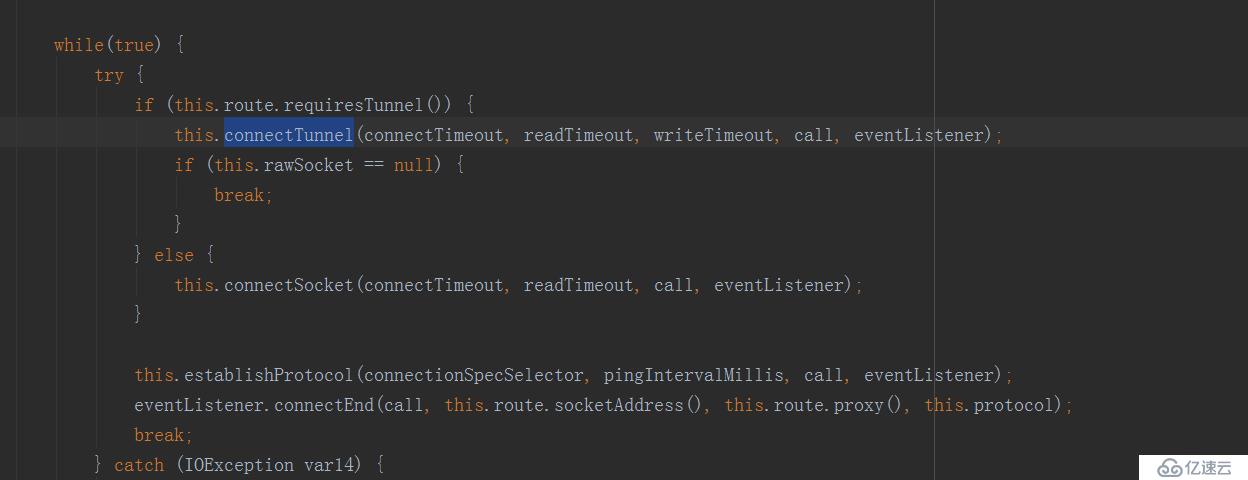
我们看下这个方法的实现:
/**
* Returns true if this route tunnels HTTPS through an HTTP proxy. See <a
* href="http://www.ietf.org/rfc/rfc2817.txt">RFC 2817, Section 5.2</a>.
*/
public boolean requiresTunnel() {
return address.sslSocketFactory != null && proxy.type() == Proxy.Type.HTTP;
}
从注释和rfc文档中可以看出来,要开启这个所谓的tunnel的功能,需要你的目标地址是https的,讲白了是tls来做报文的传输,此外还需要一个http代理服务器。同时满足这2个条件以后才会触发这部分代码。这部分由于涉及到tls协议的相关知识,我们将这一块的内容放到后续的第三个章节中再来解释。这里大家只需要大概清楚tunnel主要用来直接转发传输层的tcp报文到目标服务器,而不需要经过http的代理服务器额外进行应用层报文的转发即可。
比如说Referer(我在谷歌中搜索github,然后点击github的链接,然后看请求信息)
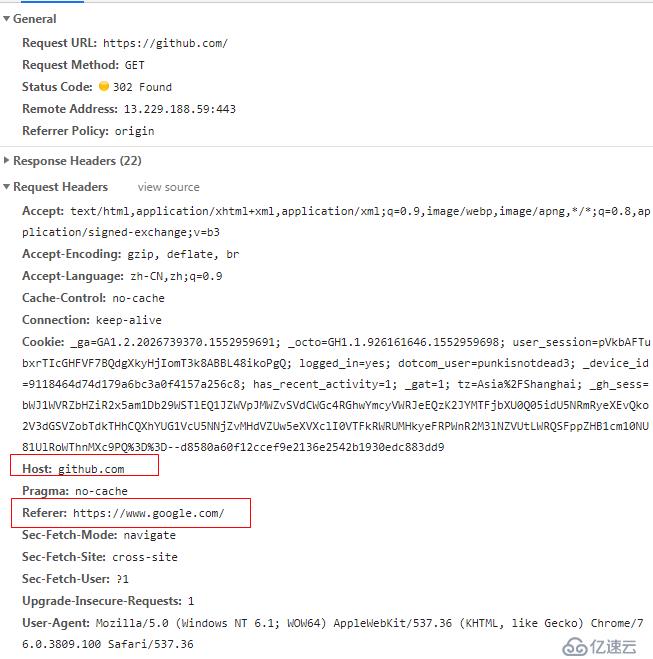
这个字段通常通常被利用做防盗链,页面来源统计分析,缓存优化等等。但是要注意的是,这个Referer字段浏览器在自动帮我们添加的时候有一个策略:要么来源是http 目标也是http,要么来源是https 目标也是https,一旦出现来源是http目标是https或者反着来的情况,浏览器就不会帮我们添加这个字段了。
此外,在http包体传输的时候,定长包体与不定长包体使用的单位是不一样的。
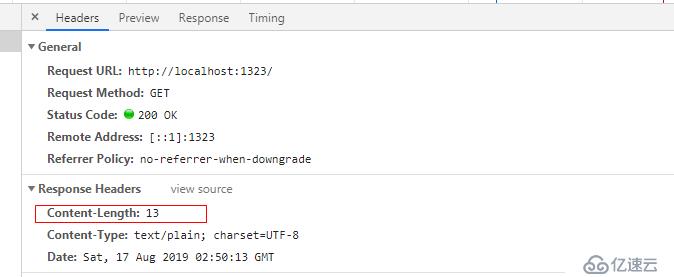
比如Content-Length这个字段后面的单位就是10进制。传输的就是这个“Hello, World!”。但是对于Chunk非定长包体来说 这个单位却是16进制的,且对于Chunk传输方式来说,有一些response的header是等待body传输完毕以后才继续传的。我们来简单写个server端的例子,返回一个叫hellowuyue的response,但是使用chunk的传输方式。这里我简单使用Go语言来完成对应的代码。
package main
import (
"net/http"
"github.com/labstack/echo"
)
func main() {
e := echo.New()
//采用chunk传输 不使用默认的定长包体
e.GET("/", func(c echo.Context) error {
c.Response().WriteHeader(http.StatusOK)
c.Response().Write([]byte("hello"))
c.Response().Flush()
c.Response().Write([]byte("wuyue"))
c.Response().Flush()
return nil
})
e.Logger.Fatal(e.Start(":1323"))
}
我们在浏览器访问一下,看看network的展示信息:
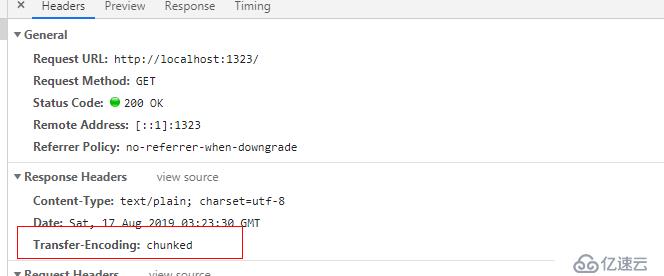
然后我们用wireshark 详细的看一下chunk的传输机制:这里要注意的是,我没有选择将我们服务端的代码部署在外部服务器上,只是简单的在本地,所以我们要选择环回地址,不要选择本地连接。同时监听1323端口.并且做 port 1323的过滤器。

然后我们来看下wireshark完整的还原过程:
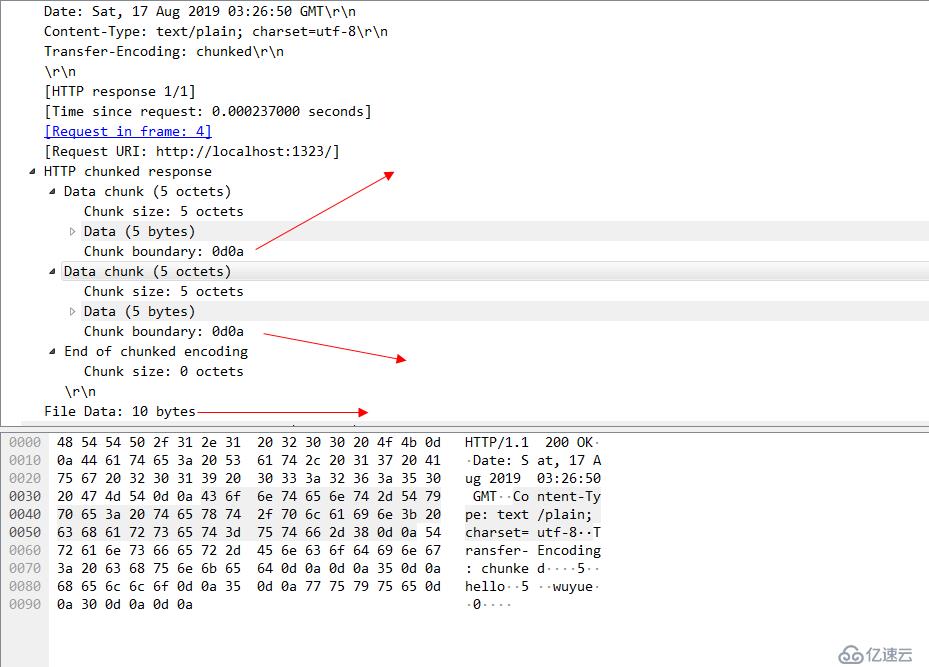
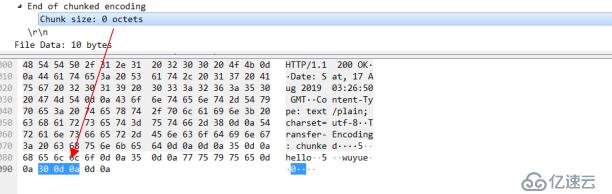
可以看一下这个chunk的结构,每一个chunk的结束都会伴随着一个0d0a的16进制,这个我们可以把他理解成就是/r/n 也就是crlf换行符。然后看一下 当chunk全部结束以后 还会有一个end chunked 这里面 也是包含了一个0d0a 。(这里篇幅所限就不放ABNF范式对chunk使用的规范了。有兴趣的同学可以自行对照ABNF的规范语法和wireshark实际抓包的内容进行对比加深理解)

最后我们看一下,浏览器和服务端在利用form表单上传文件时的交互过程以及okhttp完成类似功能时候的异同,加深对包体传输的理解。首先我们定义一个非常简单的html,提供一个表单。
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>上传文件</title>
</head>
<body>
<h2>上传文件</h2>
<form action="/uploadresult" method="post" enctype="multipart/form-data">
Name: <input type="text" name="name"><br>
Files: <input type="file" name="file"><br><br>
Files2: <input type="file" name="file2"><br><br>
<input type="submit" value="Submit">
</form>
</body>
</html>
然后定义一下我们的服务端:
package main
import (
"io"
"net/http"
"os"
"time"
"github.com/labstack/echo"
)
func main() {
e := echo.New()
//直接返回一个预先定义好的html
e.GET("/uploadtest", func(c echo.Context) error {
return c.File("html/upload.html")
})
//html里预先定义好点击上传以后就跳转到这个uri
e.POST("/uploadresult", getFile)
e.Logger.Fatal(e.Start(":1329"))
}
func getFile(c echo.Context) error {
name := c.FormValue("name")
println("name==" + name)
file, _ := c.FormFile("file")
file2, _ := c.FormFile("file2")
src, _ := file.Open()
src2, _ := file2.Open()
dst, _ := os.Create(file.Filename)
dst2, _ := os.Create(file2.Filename)
io.Copy(dst, src)
io.Copy(dst2, src2)
return c.String(http.StatusOK, "上传成功")
}
然后我们访问这个表单,上传一下文件以后用wireshark抓个包来体会一下浏览器在背后帮我们做的事情。
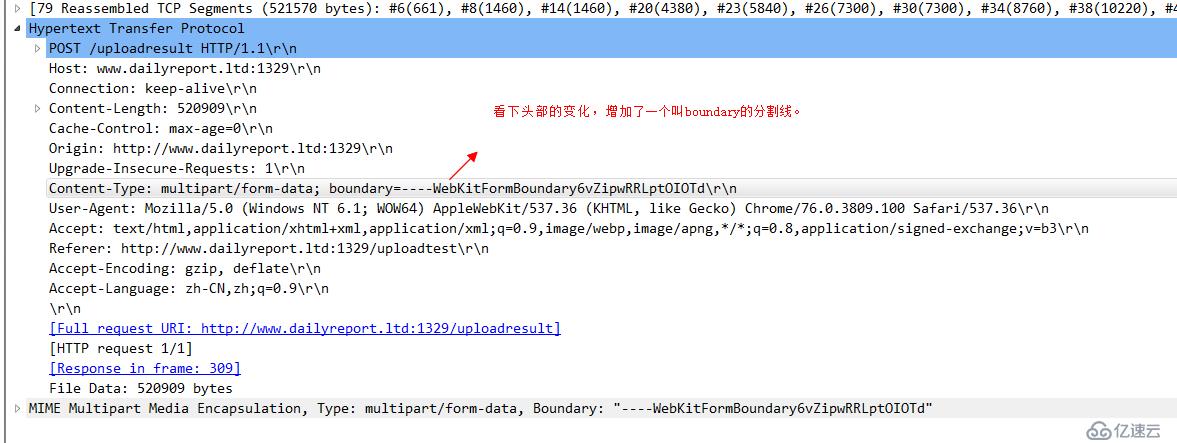
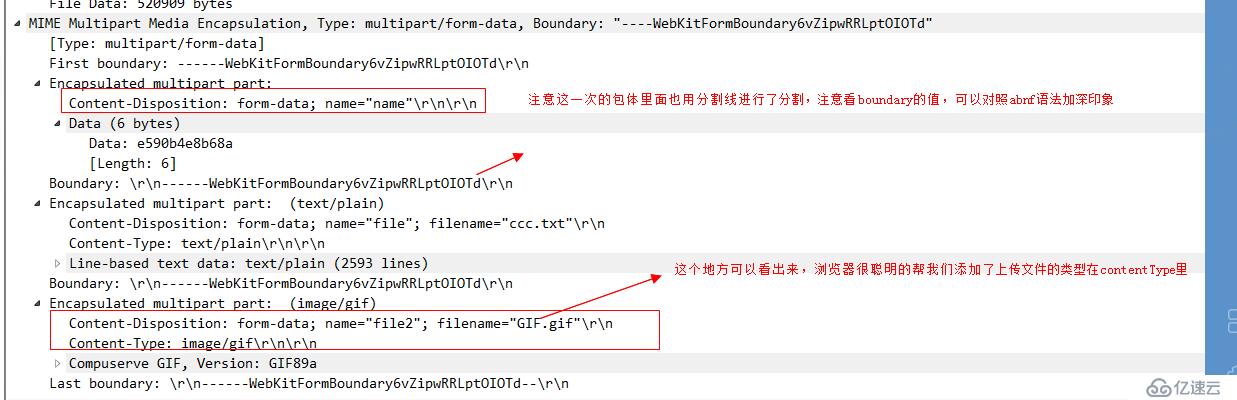
关于这个Content-Disposition有兴趣的可以自行搜索其含义。
最后我们用okhttp来完成这个操作,看看okhttp做这个操作的时候,wireshark显示的结果又是什么样子:
//注意看 contentType 是需要你手动去设置的,我们这里故意将这个contentType值写错 看看能不能上传文件成功
RequestBody requestBody1 = RequestBody.create(MediaType.parse("image/gifccc"), new File("/mnt/sdcard/ccc.txt"));
RequestBody requestBody2 = RequestBody.create(MediaType.parse("text/plain111"), new File("/mnt/sdcard/Gif.gif"));
RequestBody requestBody = new MultipartBody.Builder()
.setType(MultipartBody.FORM).addFormDataPart("file2", "Gif.gif", requestBody1)
.addFormDataPart("file", "ccc.txt", requestBody2)
.addFormDataPart("name","吴越")
.build();
Request request = new Request.Builder().get().url("http://47.100.237.180:1329/uploadresult").post(requestBody).build();

本章节初步介绍了如何使用chrome的network面板和wireshark抓包工具进行http协议的分析,重点介绍了http1.x协议中的“队头拥塞”的概念,以及该问题的应对方式和浏览器的限制策略。在后续的第二个章节中,将会详细介绍http协议中缓存,dns以及websocket的相关知识。在第三个章节中,将会详细分析http2以及tls协议的每一个细节。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。