жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮеҶ…е®№д»Ӣз»ҚдәҶвҖңMySqlеёёз”ЁжҹҘиҜўдјҳеҢ–зӯ–з•Ҙжңүе“ӘдәӣвҖқзҡ„жңүе…ізҹҘиҜҶпјҢеңЁе®һйҷ…жЎҲдҫӢзҡ„ж“ҚдҪңиҝҮзЁӢдёӯпјҢдёҚе°‘дәәйғҪдјҡйҒҮеҲ°иҝҷж ·зҡ„еӣ°еўғпјҢжҺҘдёӢжқҘе°ұи®©е°Ҹзј–еёҰйўҶеӨ§е®¶еӯҰд№ дёҖдёӢеҰӮдҪ•еӨ„зҗҶиҝҷдәӣжғ…еҶөеҗ§пјҒеёҢжңӣеӨ§е®¶д»”з»Ҷйҳ…иҜ»пјҢиғҪеӨҹеӯҰжңүжүҖжҲҗпјҒ
еҸҜд»ҘиҜҙпјҢеҜ№дәҺеӨ§еӨҡж•°зі»з»ҹжқҘиҜҙпјҢиҜ»еӨҡеҶҷе°‘дёҖе®ҡжҳҜеёёжҖҒпјҢиҝҷе°ұиЎЁзӨәж¶үеҸҠеҲ°жҹҘиҜўзҡ„SQLжҳҜйқһеёёй«ҳйў‘зҡ„ж“ҚдҪңпјӣ
еүҚзҪ®еҮҶеӨҮпјҢз»ҷдёҖеј жөӢиҜ•иЎЁж·»еҠ 10дёҮжқЎж•°жҚ®
дҪҝз”ЁдёӢйқўзҡ„еӯҳеӮЁиҝҮзЁӢз»ҷеҚ•иЎЁйҖ дёҖжү№ж•°жҚ®пјҢе°ҶиЎЁжҚўжҲҗиҮӘе·ұзҡ„е°ұеҘҪдәҶ
create procedure addMyData()
begin
declare num int;
set num =1;
while num <= 100000 do
insert into XXX_table values(
replace(uuid(),'-',''),concat('жөӢиҜ•',num),concat('cs',num),'123456'
);
set num =num +1;
end while;
end ;
然еҗҺи°ғз”ЁиҜҘеӯҳеӮЁиҝҮзЁӢ
call addMyData();
жң¬зҜҮеҮҶеӨҮдәҶ3еј иЎЁпјҢеҲҶеҲ«дёәеӯҰз”ҹпјҲstudentпјүиЎЁпјҢзҸӯзә§пјҲclassпјүиЎЁпјҢиҙҰжҲ·(account)иЎЁпјҢеҗ„иҮӘжңү50дёҮпјҢ1дёҮе’Ң10дёҮжқЎж•°жҚ®з”ЁдәҺжөӢиҜ•пјӣ
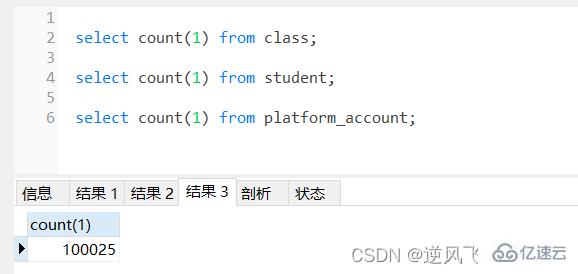
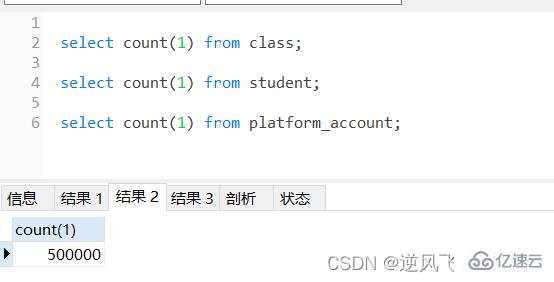
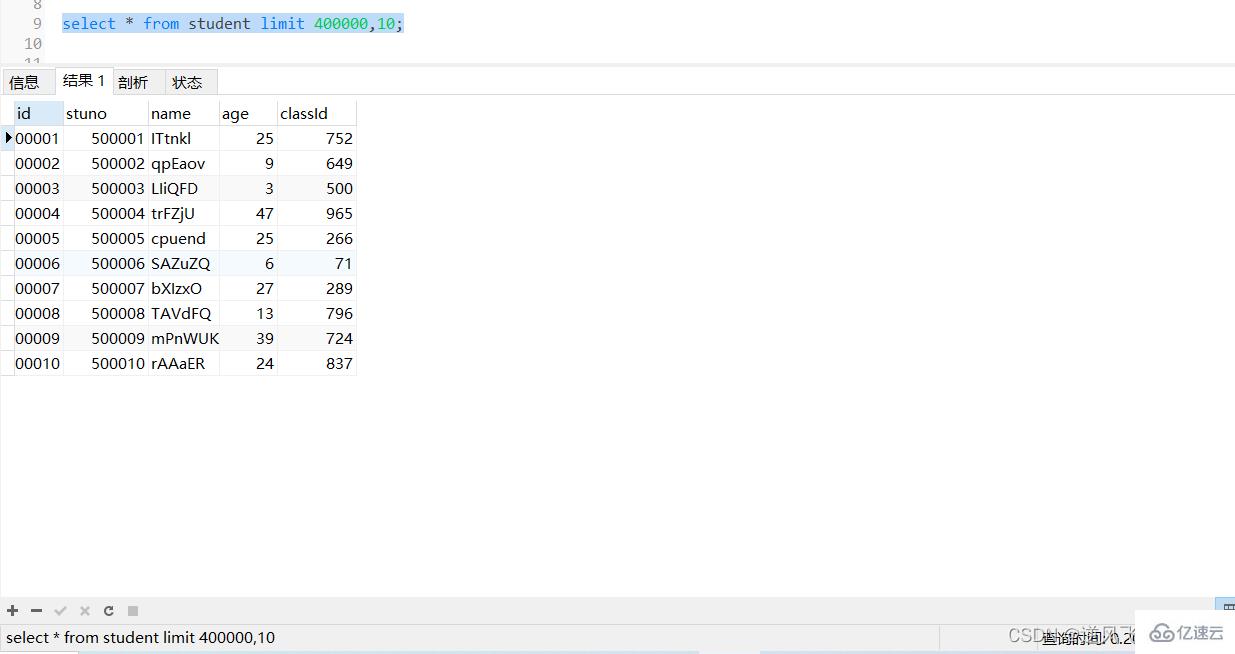
еҲҶйЎөжҹҘиҜўжҳҜејҖеҸ‘дёӯз»ҸеёёдјҡйҒҮеҲ°зҡ„пјҢжңүдёҖз§Қжғ…еҶөжҳҜпјҢеҪ“еҲҶйЎөзҡ„ж•°йҮҸйқһеёёеӨ§зҡ„ж—¶еҖҷпјҢжҹҘиҜўзҡ„ж—¶еҖҷеҫҖеҫҖйқһеёёиҖ—ж—¶пјҢжҜ”еҰӮжҹҘиҜўstudentиЎЁпјҢдҪҝз”ЁдёӢйқўзҡ„sqlжҹҘиҜўпјҢиҖ—ж—¶иҫҫеҲ°0.2з§’пјӣ
е®һи·өз»ҸйӘҢе‘ҠиҜүжҲ‘们пјҢи¶ҠеҫҖеҗҺпјҢеҲҶйЎөжҹҘиҜўж•ҲзҺҮи¶ҠдҪҺпјҢиҝҷе°ұжҳҜеҲҶйЎөжҹҘиҜўзҡ„й—®йўҳжүҖеңЁпјҢ еӣ дёәпјҢеҪ“еңЁиҝӣиЎҢеҲҶйЎөжҹҘиҜўж—¶пјҢеҰӮжһңжү§иЎҢ limit 400000,10 пјҢжӯӨж—¶йңҖиҰҒ MySQL жҺ’еәҸеүҚ4000 10 и®° еҪ•пјҢд»…д»…иҝ”еӣһ400000 - 4 00010 зҡ„и®°еҪ•пјҢе…¶д»–и®°еҪ•дёўејғпјҢжҹҘиҜўжҺ’еәҸзҡ„д»Јд»·йқһеёёеӨ§
дёҖиҲ¬еҲҶйЎөжҹҘиҜўж—¶пјҢйҖҡиҝҮеҲӣе»ә иҰҶзӣ–зҙўеј• иғҪеӨҹжҜ”иҫғеҘҪең°жҸҗй«ҳжҖ§иғҪпјҢеҸҜд»ҘйҖҡиҝҮиҰҶзӣ–зҙўеј•еҠ еӯҗжҹҘиҜўеҪўејҸиҝӣиЎҢдјҳеҢ–пјӣ
1пјү еңЁзҙўеј•дёҠе®ҢжҲҗжҺ’еәҸеҲҶйЎөж“ҚдҪңпјҢжңҖеҗҺж №жҚ®дё»й”®е…іиҒ”еӣһеҺҹиЎЁжҹҘиҜўжүҖйңҖиҰҒзҡ„е…¶д»–еҲ—еҶ…е®№
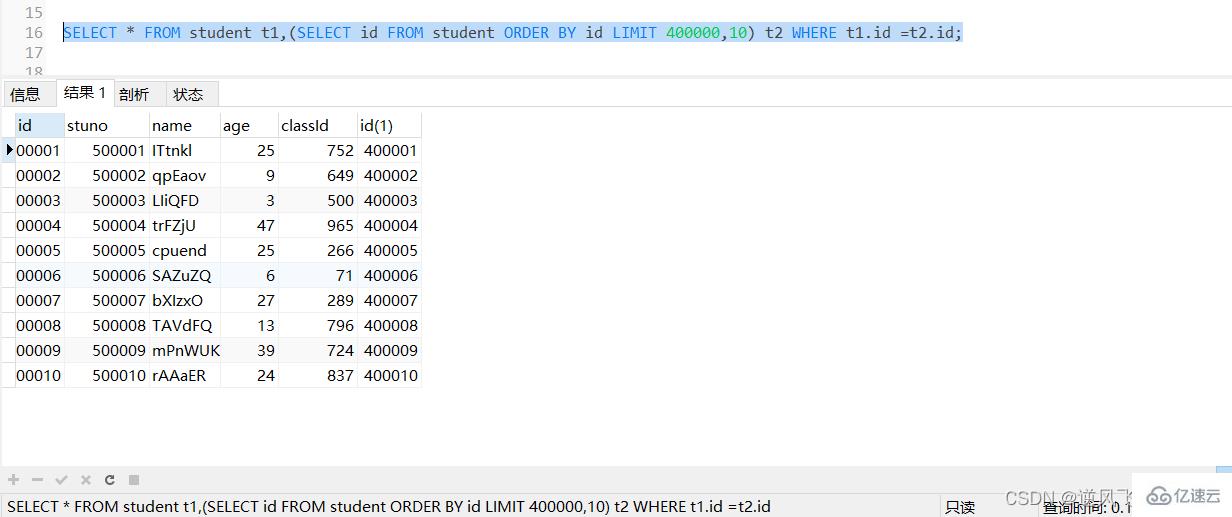
SELECT * FROM student t1,(SELECT id FROM student ORDER BY id LIMIT 400000,10) t2 WHERE t1.id =t2.id;
жү§иЎҢдёҠйқўзҡ„sqlпјҢеҸҜд»ҘзңӢеҲ°е“Қеә”ж—¶й—ҙжңүдёҖе®ҡзҡ„жҸҗеҚҮпјӣ
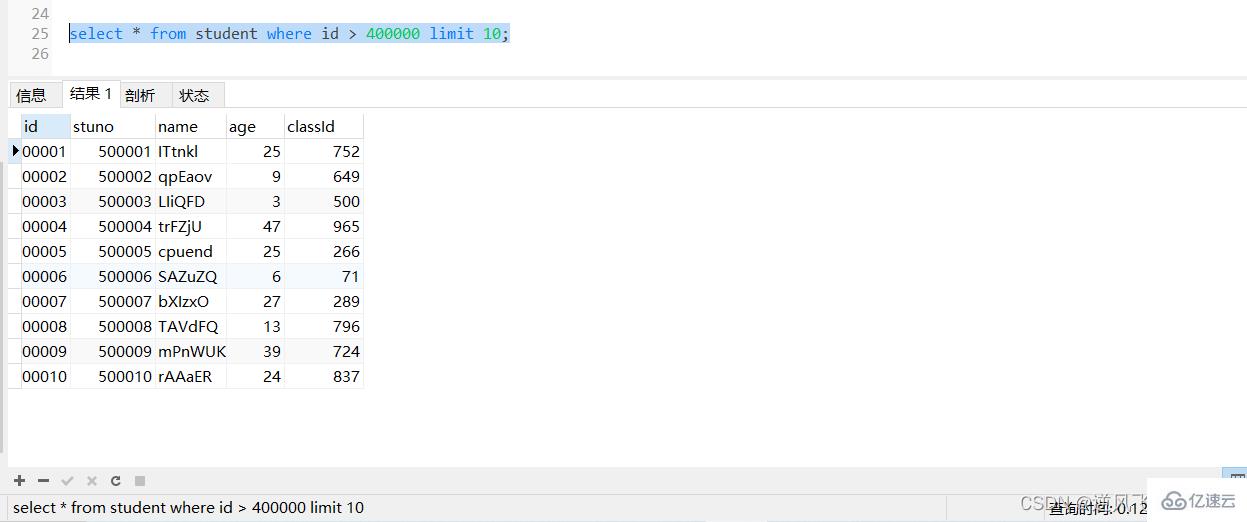
2пјүеҜ№дәҺдё»й”®иҮӘеўһзҡ„иЎЁпјҢеҸҜд»ҘжҠҠLimit жҹҘиҜўиҪ¬жҚўжҲҗжҹҗдёӘдҪҚзҪ®зҡ„жҹҘиҜў
select * from student where id > 400000 limit 10;
жү§иЎҢдёҠйқўзҡ„sqlпјҢеҸҜд»ҘзңӢеҲ°е“Қеә”ж—¶й—ҙжңүдёҖе®ҡзҡ„жҸҗеҚҮпјӣ
еңЁе®һйҷ…зҡ„дёҡеҠЎејҖеҸ‘иҝҮзЁӢдёӯпјҢе…іиҒ”жҹҘиҜўеҸҜд»ҘиҜҙйҡҸеӨ„еҸҜи§ҒпјҢе…іиҒ”жҹҘиҜўзҡ„дјҳеҢ–ж ёеҝғжҖқи·ҜжҳҜпјҢжңҖеҘҪдёәе…іиҒ”жҹҘиҜўзҡ„еӯ—ж®өж·»еҠ зҙўеј•пјҢиҝҷжҳҜе…ій”®пјҢе…·дҪ“еҲ°дёҚеҗҢзҡ„еңәжҷҜпјҢиҝҳйңҖиҰҒе…·дҪ“еҲҶжһҗпјҢиҝҷдёӘи·ҹmysqlзҡ„еј•ж“ҺеңЁжү§иЎҢдјҳеҢ–зӯ–з•Ҙзҡ„ж–№жЎҲйҖүжӢ©ж—¶жңүдёҖе®ҡе…ізі»пјӣ
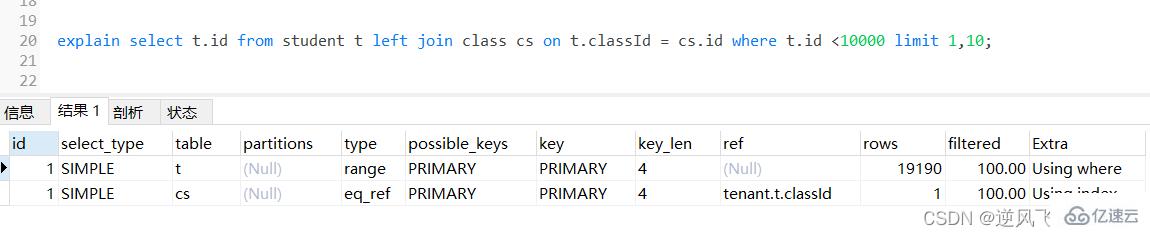
дёӢйқўжҳҜдёҖдёӘдҪҝз”Ёleft join зҡ„жҹҘиҜўпјҢеҸҜд»Ҙйў„жғіеҲ°иҝҷжқЎsqlжҹҘиҜўзҡ„з»“жһңйӣҶйқһеёёеӨ§
зҷ»еҪ•еҗҺеӨҚеҲ¶select t.* from student t left join class cs on t.classId = cs.id;
дёәдәҶжЈҖжҹҘдёӢsqlзҡ„жү§иЎҢж•ҲзҺҮпјҢдҪҝз”ЁexplainеҒҡдёҖдёӢеҲҶжһҗпјҢеҸҜд»ҘзңӢеҲ°пјҢ第дёҖеј иЎЁеҚіleft joinе·Ұиҫ№зҡ„иЎЁstudentиө°дәҶе…ЁиЎЁжү«жҸҸпјҢиҖҢclassиЎЁиө°дәҶдё»й”®зҙўеј•пјҢе°Ҫз®Ўз»“жһңйӣҶиҫғеӨ§пјҢиҝҳжҳҜиө°дәҶзҙўеј•пјӣ

й’ҲеҜ№иҝҷз§ҚеңәжҷҜзҡ„жҹҘиҜўпјҢжҖқи·ҜеҰӮдёӢпјҡ
и®©жҹҘиҜўзҡ„еӯ—ж®өе°ҪйҮҸеҢ…еҗ«еңЁдё»й”®зҙўеј•жҲ–иҖ…иҰҶзӣ–зҙўеј•дёӯпјӣ
жҹҘиҜўзҡ„ж—¶еҖҷе°ҪйҮҸдҪҝз”ЁеҲҶйЎөжҹҘиҜўпјӣ
е…ідәҺе·ҰиҝһжҺҘпјҲеҸіиҝһжҺҘпјүзҡ„explainз»“жһңиЎҘе……иҜҙжҳҺ
е·ҰиҝһжҺҘе·Ұиҫ№зҡ„иЎЁдёҖиҲ¬дёәй©ұеҠЁиЎЁпјҢеҸіиҫ№зҡ„иЎЁдёәиў«й©ұеҠЁиЎЁпјӣ
е°ҪеҸҜиғҪи®©ж•°жҚ®йӣҶе°Ҹзҡ„иЎЁдҪңдёәй©ұеҠЁиЎЁпјҢеҮҸе°‘mysqlеҶ…йғЁеҫӘзҺҜзҡ„ж¬Ўж•°пјӣ
дёӨиЎЁе…іиҒ”ж—¶пјҢexplainз»“жһңеұ•зӨәдёӯпјҢ第дёҖж ҸдёҖиҲ¬дёәй©ұеҠЁиЎЁпјӣ
зңӢдёӢйқўзҡ„иҝҷжқЎsqlпјҢе…¶е…іиҒ”еӯ—ж®өйқһиЎЁзҡ„дё»й”®пјҢиҖҢжҳҜжҷ®йҖҡзҡ„еӯ—ж®өпјӣ
зҷ»еҪ•еҗҺеӨҚеҲ¶explain select u.* from tenant t left join `user` u on u.account = t.tenant_name where t.removed is null and u.removed is null;

йҖҡиҝҮexplainеҲҶжһҗеҸҜд»ҘеҸ‘зҺ°пјҢе·Ұиҫ№зҡ„иЎЁиө°дәҶе…ЁиЎЁжү«жҸҸпјҢеҸҜд»ҘиҖғиҷ‘з»ҷе·Ұиҫ№зҡ„иЎЁзҡ„tenant_nameе’ҢuserиЎЁзҡ„account еҗ„иҮӘеҲӣе»әзҙўеј•пјӣ
create index idx_name on tenant(tenant_name);
create index idx_account on `user`(account);
еҶҚж¬ЎдҪҝз”ЁexplainеҲҶжһҗз»“жһңеҰӮдёӢ

еҸҜд»ҘзңӢеҲ°з¬¬дәҢиЎҢtypeеҸҳдёәrefпјҢrowsзҡ„ж•°йҮҸдјҳеҢ–жҜ”иҫғжҳҺжҳҫгҖӮиҝҷжҳҜз”ұе·ҰиҝһжҺҘзү№жҖ§еҶіе®ҡзҡ„пјҢLEFT JOINжқЎд»¶з”ЁдәҺзЎ®е®ҡеҰӮдҪ•д»ҺеҸіиЎЁжҗңзҙўиЎҢпјҢе·Ұиҫ№дёҖе®ҡйғҪжңүпјҢжүҖд»ҘеҸіиҫ№жҳҜжҲ‘们зҡ„е…ій”®зӮ№,дёҖе®ҡйңҖиҰҒе»әз«Ӣзҙўеј• гҖӮ
жҲ‘们зҹҘйҒ“пјҢе·ҰиҝһжҺҘе’ҢеҸіиҝһжҺҘжҹҘиҜўзҡ„ж•°жҚ®еҲҶеҲ«жҳҜе®Ңе…ЁеҢ…еҗ«е·ҰиЎЁж•°жҚ®пјҢе®Ңе…ЁеҢ…еҗ«еҸіиЎЁж•°жҚ®пјҢиҖҢеҶ…иҝһжҺҘпјҲinner join жҲ–joinпјү еҲҷжҳҜеҸ–дәӨйӣҶпјҲе…ұжңүзҡ„йғЁеҲҶпјүпјҢеңЁиҝҷз§Қжғ…еҶөдёӢпјҢй©ұеҠЁиЎЁзҡ„йҖүжӢ©жҳҜз”ұmysqlдјҳеҢ–еҷЁиҮӘеҠЁйҖүжӢ©зҡ„пјӣ
еңЁдёҠйқўзҡ„еҹәзЎҖдёҠпјҢйҰ–е…Ҳ移йҷӨдёӨеј иЎЁзҡ„зҙўеј•
ALTER TABLE `user` DROP INDEX idx_account;
ALTER TABLE `tenant` DROP INDEX idx_name;
дҪҝз”ЁexplainиҜӯеҸҘиҝӣиЎҢеҲҶжһҗ

然еҗҺз»ҷuserиЎЁзҡ„accountеӯ—ж®өж·»еҠ зҙўеј•пјҢеҶҚж¬Ўжү§иЎҢexplainжҲ‘们еҸ‘зҺ°пјҢuserиЎЁз«ҹ然被еҪ“дҪңжҳҜиў«й©ұеҠЁиЎЁдәҶпјӣ
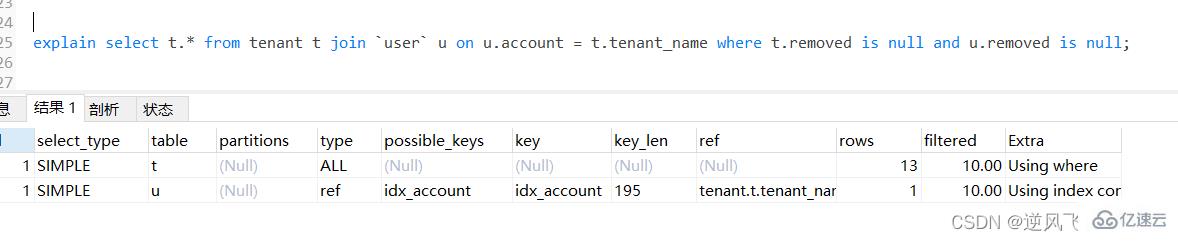
жӯӨж—¶пјҢеҰӮжһңжҲ‘们з»ҷtenantиЎЁзҡ„tenant_nameеҠ зҙўеј•пјҢ并移йҷӨuserиЎЁзҡ„accountзҙўеј•пјҢеҫ—еҮәзҡ„з»“жһңз«ҹ然йғҪжІЎжңүиө°зҙўеј•пјҢеҶҚж¬ЎиҜҙжҳҺпјҢдҪҝз”ЁеҶ…иҝһжҺҘзҡ„жғ…еҶөдёӢпјҢжҹҘиҜўдјҳеҢ–еҷЁе°Ҷдјҡж №жҚ®иҮӘе·ұзҡ„еҲӨж–ӯиҝӣиЎҢйҖүжӢ©пјӣ

еӯҗжҹҘиҜўеңЁж—Ҙеёёзј–еҶҷдёҡеҠЎзҡ„SQLж—¶д№ҹжҳҜдҪҝз”Ёйқһеёёйў‘з№Ғзҡ„еҒҡжі•пјҢдёҚжҳҜиҜҙеӯҗжҹҘиҜўдёҚиғҪз”ЁпјҢиҖҢжҳҜеҪ“ж•°жҚ®йҮҸи¶…еҮәдёҖе®ҡзҡ„иҢғеӣҙд№ӢеҗҺпјҢеӯҗжҹҘиҜўзҡ„жҖ§иғҪдёӢйҷҚжҳҜеҫҲжҳҺжҳҫзҡ„пјҢе…ідәҺиҝҷдёҖзӮ№пјҢжң¬дәәеңЁж—Ҙеёёе·ҘдҪңдёӯж·ұжңүдҪ“дјҡпјӣ
жҜ”еҰӮдёӢйқўиҝҷжқЎsqlпјҢз”ұдәҺstudentиЎЁж•°жҚ®йҮҸиҫғеӨ§пјҢжү§иЎҢиө·жқҘиҖ—ж—¶йқһеёёй•ҝпјҢеҸҜд»ҘзңӢеҲ°иҖ—иҙ№дәҶе°Ҷиҝ‘3з§’пјӣ
зҷ»еҪ•еҗҺеӨҚеҲ¶select st.* from student st where st.classId in (
select id from class where id > 100
);
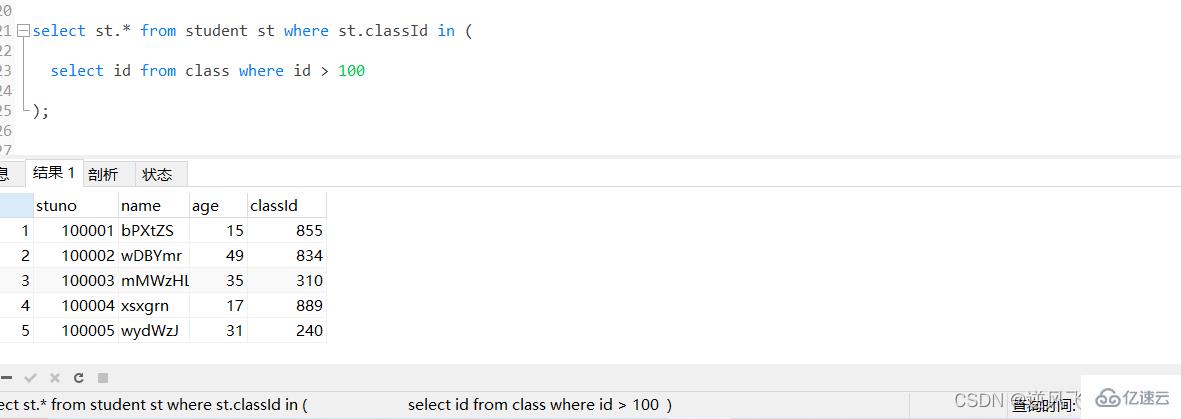
йҖҡиҝҮжү§иЎҢexplainиҝӣиЎҢеҲҶжһҗеҫ—зҹҘпјҢеҶ…еұӮжҹҘиҜў id > 100зҡ„еӯҗжҹҘиҜўе°Ҫз®Ўз”ЁдёҠдәҶдё»й”®зҙўеј•пјҢдҪҶжҳҜз”ұдәҺз»“жһңйӣҶеӨӘеӨ§пјҢеёҰе…ҘеҲ°еӨ–еұӮжҹҘиҜўпјҢеҚідҪңдёәinзҡ„жқЎд»¶ж—¶пјҢжҹҘиҜўдјҳеҢ–еҷЁиҝҳжҳҜиө°дәҶе…ЁиЎЁжү«жҸҸпјӣ
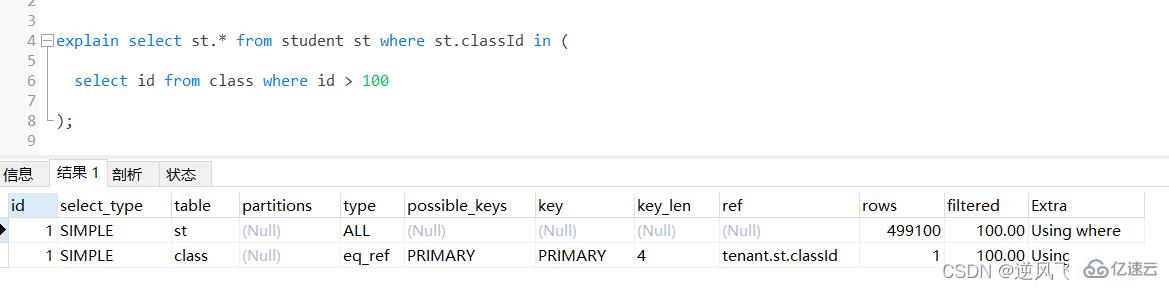
й’ҲеҜ№дёҠйқўзҡ„жғ…еҶөпјҢеҸҜд»ҘиҖғиҷ‘дёӢйқўзҡ„дјҳеҢ–ж–№ејҸ
select st.id from student st join class cl on st.classId = cl.id where cl.id > 100;
еӯҗжҹҘиҜўжҖ§иғҪдҪҺж•Ҳзҡ„еҺҹеӣ
еӯҗжҹҘиҜўж—¶пјҢMySQLйңҖиҰҒдёәеҶ…еұӮжҹҘиҜўиҜӯеҸҘзҡ„жҹҘиҜўз»“жһңе»әз«ӢдёҖдёӘдёҙж—¶иЎЁ пјҢ然еҗҺеӨ–еұӮжҹҘиҜўиҜӯеҸҘд»Һдёҙж—¶иЎЁдёӯжҹҘиҜўи®°еҪ•пјҢжҹҘиҜўе®ҢжҜ•еҗҺпјҢеҶҚж’Өй”Җиҝҷдәӣдёҙж—¶иЎЁ гҖӮиҝҷж ·дјҡж¶ҲиҖ—иҝҮеӨҡзҡ„CPUе’ҢIOиө„жәҗ,дә§з”ҹеӨ§йҮҸзҡ„ж…ўжҹҘиҜўпјӣ
еӯҗжҹҘиҜўз»“жһңйӣҶеӯҳеӮЁзҡ„дёҙж—¶иЎЁпјҢдёҚи®әжҳҜеҶ…еӯҳдёҙж—¶иЎЁиҝҳжҳҜзЈҒзӣҳдёҙж—¶иЎЁйғҪдёҚиғҪиө°зҙўеј• пјҢжүҖд»ҘжҹҘиҜўжҖ§иғҪдјҡеҸ—еҲ°дёҖе®ҡзҡ„еҪұе“Қпјӣ
еҜ№дәҺиҝ”еӣһз»“жһңйӣҶжҜ”иҫғеӨ§зҡ„еӯҗжҹҘиҜўпјҢе…¶еҜ№жҹҘиҜўжҖ§иғҪзҡ„еҪұе“Қд№ҹе°ұи¶ҠеӨ§пјӣ
дҪҝз”ЁmysqlжҹҘиҜўж—¶пјҢеҸҜд»ҘдҪҝз”ЁиҝһжҺҘпјҲJOINпјүжҹҘиҜўжқҘжӣҝд»ЈеӯҗжҹҘиҜўгҖӮиҝһжҺҘжҹҘиҜўдёҚйңҖиҰҒе»әз«Ӣдёҙж—¶иЎЁ пјҢе…¶йҖҹеәҰжҜ”еӯҗжҹҘиҜўиҰҒеҝ« пјҢеҰӮжһңжҹҘиҜўдёӯдҪҝз”Ёзҙўеј•зҡ„иҜқпјҢжҖ§иғҪе°ұдјҡжӣҙеҘҪпјҢе°ҪйҮҸдёҚиҰҒдҪҝз”ЁNOT IN жҲ–иҖ… NOT EXISTSпјҢз”ЁLEFT JOIN xxx ON xx WHERE xx IS NULLжӣҝд»Јпјӣ
еңЁдёӢйқўзҡ„иҝҷж®өsqlдёӯпјҢдјҳеҢ–еүҚдҪҝз”Ёзҡ„жҳҜеӯҗжҹҘиҜўпјҢеңЁдёҖж¬Ўз”ҹдә§й—®йўҳзҡ„жҖ§иғҪеҲҶжһҗдёӯпјҢеҸ‘зҺ°жҹҗдёӘtenant_idдёӢзҡ„ж•°жҚ®иҫҫеҲ°дәҶ35дёҮеӨҡпјҢиҝҷж ·зӣҙжҺҘеҜјиҮҙжҹҗдёӘеҲ—иЎЁйЎөйқўзҡ„жҺҘеҸЈжҹҘиҜўиҖ—ж—¶иҫҫеҲ°дәҶ5з§’е·ҰеҸіпјӣ
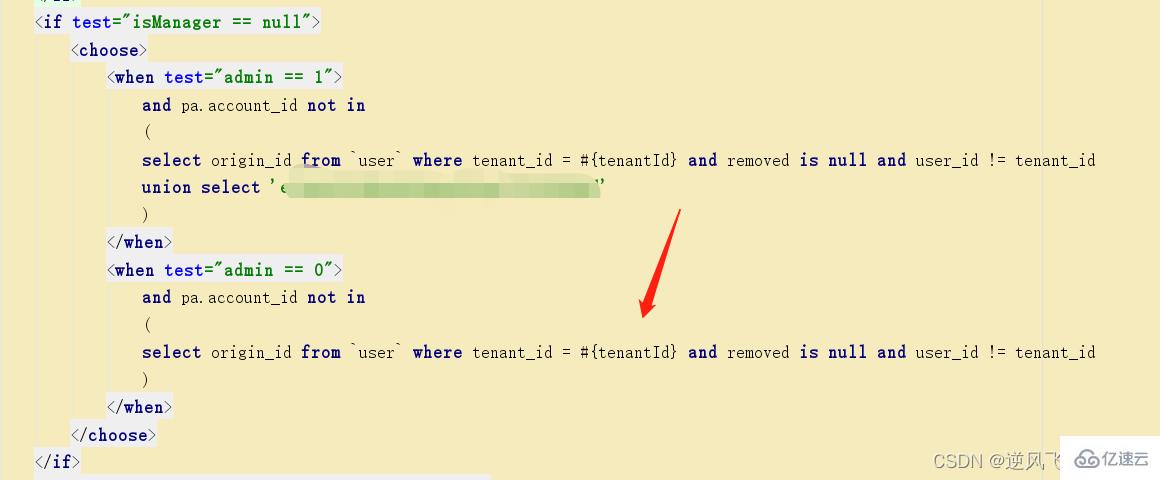
жүҫеҲ°дәҶй—®йўҳзҡ„ж №жәҗеҗҺпјҢе°қиҜ•дҪҝз”ЁдёҠйқўзҡ„дјҳеҢ–жҖқи·ҜиҝӣиЎҢи§ЈеҶіеҚіеҸҜпјҢдјҳеҢ–еҗҺзҡ„sqlеӨ§жҰӮеҰӮдёӢпјҢ
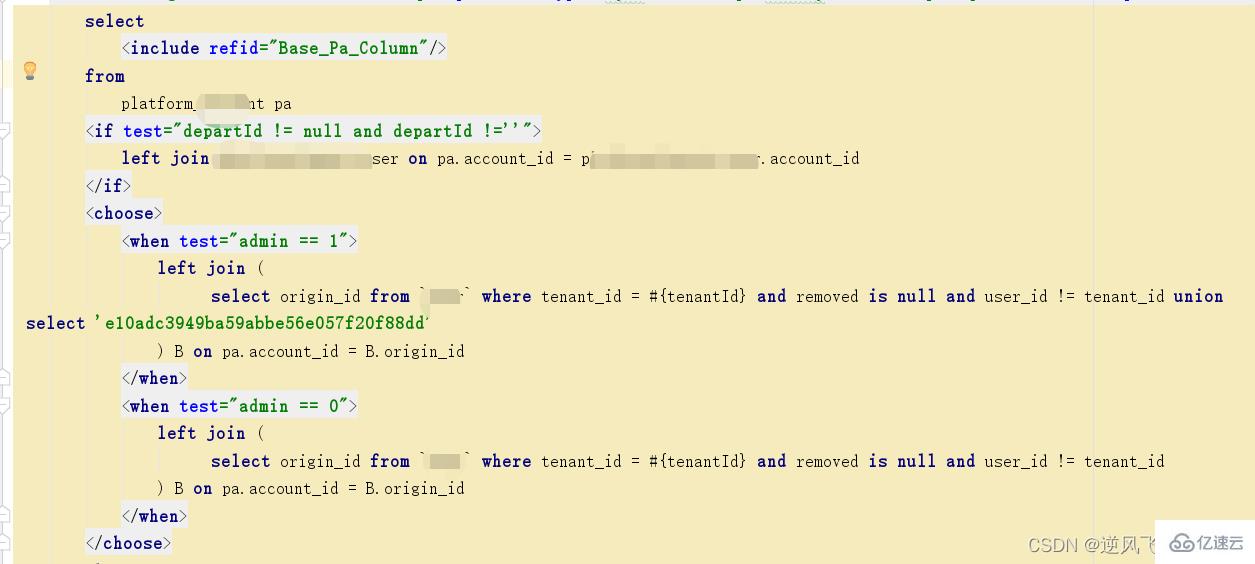
еңЁmysqlпјҢжҺ’еәҸдё»иҰҒжңүдёӨз§Қж–№ејҸ
Using filesort : йҖҡиҝҮиЎЁзҙўеј•жҲ–е…ЁиЎЁжү«жҸҸпјҢиҜ»еҸ–ж»Ўи¶іжқЎд»¶зҡ„ж•°жҚ®иЎҢпјҢ然еҗҺеңЁжҺ’еәҸзј“еҶІеҢәsort
bufferдёӯе®ҢжҲҗжҺ’еәҸж“ҚдҪңпјҢжүҖжңүдёҚжҳҜйҖҡиҝҮзҙўеј•зӣҙжҺҘиҝ”еӣһжҺ’еәҸз»“жһңзҡ„жҺ’еәҸйғҪеҸ« FileSort жҺ’еәҸпјӣ
Using index : йҖҡиҝҮжңүеәҸзҡ„зҙўеј•йЎәеәҸжү«жҸҸзӣҙжҺҘиҝ”еӣһжңүеәҸж•°жҚ®пјҢиҝҷз§Қжғ…еҶөеҚідёә using indexпјҢдёҚйңҖиҰҒйўқеӨ–жҺ’еәҸпјҢж“ҚдҪңж•ҲзҺҮй«ҳпјӣ
еҜ№дәҺд»ҘдёҠдёӨз§ҚжҺ’еәҸж–№ејҸпјҢUsing indexзҡ„жҖ§иғҪй«ҳпјҢиҖҢUsing filesortзҡ„жҖ§иғҪдҪҺпјҢжҲ‘们еңЁдјҳеҢ–жҺ’еәҸж“ҚдҪңж—¶пјҢе°ҪйҮҸиҰҒдјҳеҢ–дёә Using index
з”ұдәҺageеӯ—ж®өжңӘеҠ зҙўеј•пјҢжҹҘиҜўз»“жһңжҢүз…§ageжҺ’еәҸзҡ„ж—¶еҖҷеҸ‘зҺ°дҪҝз”ЁдәҶfilesortпјҢжҺ’еәҸжҖ§иғҪиҫғдҪҺпјӣ

з»ҷageеӯ—ж®өж·»еҠ зҙўеј•пјҢеҶҚж¬ЎдҪҝз”Ёorder byж—¶е°ұиө°дәҶзҙўеј•пјӣ

йҖҡеёёеңЁе®һйҷ…дёҡеҠЎдёӯпјҢеҸӮдёҺжҺ’еәҸзҡ„еӯ—ж®өеҫҖеҫҖдёҚеҸӘдёҖдёӘпјҢиҝҷж—¶еҖҷпјҢе°ұеҸҜд»ҘеҜ№еҸӮдёҺжҺ’еәҸзҡ„еӨҡдёӘеӯ—ж®өеҲӣе»әиҒ”еҗҲзҙўеј•пјӣ
еҰӮдёӢж №жҚ®stunoе’ҢageжҺ’еәҸ

з»ҷstunoе’Ңageж·»еҠ иҒ”еҗҲзҙўеј•
create index idx_stuno_age on `student`(stuno,age);
еҶҚж¬ЎеҲҶжһҗж—¶з»“жһңеҰӮдёӢпјҢжӯӨж—¶жҺ’еәҸиө°дәҶзҙўеј•

1пјүжҺ’еәҸж—¶пјҢйңҖиҰҒж»Ўи¶іжңҖе·ҰеүҚзјҖжі•еҲҷ,еҗҰеҲҷд№ҹдјҡеҮәзҺ° filesortпјӣ
еңЁдёҠйқўжҲ‘们еҲӣе»әзҡ„иҒ”еҗҲзҙўеј•йЎәеәҸжҳҜstunoе’ҢageпјҢеҚіstunoеңЁеүҚйқўпјҢиҖҢageеңЁеҗҺпјҢеҰӮжһңжҹҘиҜўзҡ„ж—¶еҖҷи°ғжҚўжҺ’еәҸйЎәеәҸдјҡжҖҺж ·е‘ўпјҹйҖҡиҝҮеҲҶжһҗз»“жһңеҸ‘зҺ°пјҢиө°дәҶfilesortпјӣ

2пјүжҺ’еәҸж—¶пјҢжҺ’еәҸзҡ„зұ»еһӢдҝқжҢҒдёҖиҮҙ
еңЁдҝқжҢҒеӯ—ж®өжҺ’еәҸйЎәеәҸдёҚеҸҳж—¶пјҢй»ҳи®Өжғ…еҶөдёӢпјҢеҰӮжһңйғҪжҢүз…§еҚҮеәҸжҲ–иҖ…йҷҚеәҸж—¶пјҢorder byеҸҜд»ҘдҪҝз”ЁindexпјҢеҰӮжһңдёҖдёӘжҳҜеҚҮеәҸпјҢеҸҰдёҖдёӘжҳҜйҷҚеәҸдјҡеҰӮдҪ•е‘ўпјҹеҲҶжһҗеҸ‘зҺ°пјҢиҝҷз§Қжғ…еҶөдёӢд№ҹдјҡиө°filesortпјӣ

group by зҡ„дјҳеҢ–зӯ–з•Ҙе’Ңorder by зҡ„дјҳеҢ–зӯ–з•ҘйқһеёёеғҸпјҢдё»иҰҒеҲ—дёҫеҰӮдёӢеҮ дёӘиҰҒзӮ№пјҡ
group by еҚідҪҝжІЎжңүиҝҮж»ӨжқЎд»¶з”ЁеҲ°зҙўеј•пјҢд№ҹеҸҜд»ҘзӣҙжҺҘдҪҝз”Ёзҙўеј•пјӣ
group by е…ҲжҺ’еәҸеҶҚеҲҶз»„пјҢйҒөз…§зҙўеј•е»әзҡ„жңҖдҪіе·ҰеүҚзјҖжі•еҲҷпјӣ
еҪ“ж— жі•дҪҝз”Ёзҙўеј•еҲ—ж—¶пјҢеўһеӨ§ max_length_for_sort_data е’Ң sort_buffer_size еҸӮж•°зҡ„и®ҫзҪ®пјӣ
whereж•ҲзҺҮй«ҳдәҺhavingпјҢиғҪеҶҷеңЁwhereйҷҗе®ҡзҡ„жқЎд»¶е°ұдёҚиҰҒеҶҷеңЁhavingдёӯдәҶпјӣ
еҮҸе°‘дҪҝз”Ёorder byпјҢиғҪдёҚжҺ’еәҸе°ұдёҚжҺ’еәҸпјҢжҲ–е°ҶжҺ’еәҸж”ҫеҲ°зЁӢеәҸеҺ»еҒҡгҖӮOrder byгҖҒgroupbyгҖҒdistinctиҝҷдәӣиҜӯеҸҘиҫғдёәиҖ—иҙ№CPUпјҢж•°жҚ®еә“зҡ„CPUиө„жәҗжҳҜжһҒе…¶е®қиҙөзҡ„пјӣ
еҰӮжһңsqlеҢ…еҗ«дәҶorder byгҖҒgroup byгҖҒdistinctиҝҷдәӣжҹҘиҜўзҡ„иҜӯеҸҘпјҢwhereжқЎд»¶иҝҮж»ӨеҮәжқҘзҡ„з»“жһңйӣҶиҜ·дҝқжҢҒеңЁ1000иЎҢд»ҘеҶ…пјҢеҗҰеҲҷSQLдјҡеҫҲж…ўпјӣ
еҰӮжһңеӯ—ж®өжңӘеҠ зҙўеј•пјҢеҲҶжһҗз»“жһңеҰӮдёӢпјҢиҝҷз§Қз»“жһңжҖ§иғҪжҳҫ然еҫҲдҪҺж•Ҳ

з»ҷstunoж·»еҠ зҙўеј•д№ӢеҗҺ

з»ҷstunoе’Ңageж·»еҠ иҒ”еҗҲзҙўеј•

еҰӮжһңдёҚйҒөеҫӘжңҖдҪіе·ҰеүҚзјҖпјҢgroup by жҖ§иғҪе°ҶдјҡжҜ”иҫғдҪҺж•Ҳ

йҒөеҫӘжңҖдҪіе·ҰеүҚзјҖзҡ„жғ…еҶөеҰӮдёӢ

count() жҳҜдёҖдёӘиҒҡеҗҲеҮҪж•°пјҢеҜ№дәҺиҝ”еӣһзҡ„з»“жһңйӣҶпјҢдёҖиЎҢиЎҢеҲӨж–ӯпјҢеҰӮжһң count еҮҪж•°зҡ„еҸӮж•°дёҚжҳҜNULLпјҢзҙҜи®ЎеҖје°ұеҠ 1пјҢеҗҰеҲҷдёҚеҠ пјҢжңҖеҗҺиҝ”еӣһзҙҜи®ЎеҖјпјӣ
з”Ёжі•пјҡcountпјҲ*пјүгҖҒcountпјҲдё»й”®пјүгҖҒcountпјҲеӯ—ж®өпјүгҖҒcountпјҲж•°еӯ—пјү
еҰӮдёӢеҲ—дёҫдәҶcountзҡ„еҮ з§ҚеҶҷжі•зҡ„иҜҰз»ҶиҜҙжҳҺ
| з”Ёжі• | иҜҙжҳҺ |
| countпјҲдё»й”®пјү | InnoDB дјҡйҒҚеҺҶж•ҙеј иЎЁпјҢжҠҠжҜҸдёҖиЎҢзҡ„дё»й”®idеҖјйғҪеҸ–еҮәжқҘпјҢиҝ”еӣһз»ҷжңҚеҠЎеұӮпјҢжңҚеҠЎеұӮжӢҝеҲ°дё»й”®еҗҺпјҢзӣҙжҺҘжҢүиЎҢиҝӣиЎҢзҙҜеҠ (дё»й”®дёҚеҸҜиғҪдёәnull)пјӣ |
| count(*) | InnoDBдёҚдјҡжҠҠе…ЁйғЁеӯ—ж®өеҸ–еҮәжқҘпјҢиҖҢжҳҜдё“й—ЁеҒҡдәҶдјҳеҢ–пјҢдёҚеҸ–еҖјпјҢжңҚеҠЎеұӮзӣҙжҺҘжҢүиЎҢиҝӣиЎҢзҙҜеҠ ; |
| countпјҲеӯ—ж®өпјү | жІЎжңүnot null зәҰжқҹ : InnoDB еј•ж“ҺдјҡйҒҚеҺҶж•ҙеј иЎЁжҠҠжҜҸдёҖиЎҢзҡ„еӯ—ж®өеҖјйғҪеҸ–еҮәжқҘпјҢиҝ”еӣһз»ҷжңҚеҠЎеұӮпјҢжңҚеҠЎеұӮеҲӨж–ӯжҳҜеҗҰдёәnullпјҢдёҚдёәnullпјҢи®Ўж•°зҙҜеҠ пјҢжңүnot null зәҰжқҹпјҡInnoDB еј•ж“ҺдјҡйҒҚеҺҶж•ҙеј иЎЁжҠҠжҜҸдёҖиЎҢзҡ„еӯ—ж®өеҖјйғҪеҸ–еҮәжқҘпјҢиҝ”еӣһз»ҷжңҚеҠЎеұӮпјҢзӣҙжҺҘжҢүиЎҢиҝӣиЎҢзҙҜеҠ пјӣ |
| countпјҲж•°еӯ—пјү | InnoDB еј•ж“ҺйҒҚеҺҶж•ҙеј иЎЁпјҢдҪҶдёҚеҸ–еҖјгҖӮжңҚеҠЎеұӮеҜ№дәҺиҝ”еӣһзҡ„жҜҸдёҖиЎҢпјҢж”ҫдёҖдёӘж•°еӯ—вҖң1вҖқиҝӣеҺ»пјҢзӣҙжҺҘжҢүиЎҢиҝӣиЎҢзҙҜеҠ пјӣ |
з»ҸйӘҢеҖјжҖ»з»“
жҢүз…§ж•ҲзҺҮжҺ’еәҸжқҘзңӢпјҢcount(еӯ—ж®ө) < count(дё»й”® id) < count(1) вүҲ count(*)пјҢжүҖд»Ҙе°ҪйҮҸдҪҝз”Ё count(*)
вҖңMySqlеёёз”ЁжҹҘиҜўдјҳеҢ–зӯ–з•Ҙжңүе“ӘдәӣвҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–е°ҶдёәеӨ§е®¶иҫ“еҮәжӣҙеӨҡй«ҳиҙЁйҮҸзҡ„е®һз”Ёж–Үз« пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ