жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
йҡҸзқҖдјҒдёҡIT规模зҡ„дёҚж–ӯжү©еӨ§пјҢеҗ„еӨ§дјҒдёҡејҖе§ӢдёҚеҶҚд»…д»…иҖғиҷ‘еҚ•дёӘжңҚеҠЎеҷЁиҠӮзӮ№зҡ„зҒҫйҡҫжҒўеӨҚпјҢиҖҢжҳҜиҖғиҷ‘еҲ°ж•ҙдёӘж•°жҚ®дёӯеҝғзҡ„зҒҫйҡҫжҒўеӨҚпјҢдёҖж—ҰжҲ‘ж•ҙдёӘж•°жҚ®дёӯеҝғйғҪеҮәзҺ°зҒҫйҡҫпјҢжҲ‘еә”иҜҘжҖҺд№ҲеҺ»жҒўеӨҚпјҢеӣ жӯӨиҝҷдёӨе№ҙеҫҲеӨҡдјҒдёҡйғҪж„ҸиҜҶеҲ°дәҶиҝҷдёҖзӮ№пјҢејҖе§ӢеңЁеҗҢеҹҺжҲ–ејӮең°е»әз«ӢеӨҡдёӘж•°жҚ®дёӯеҝғпјҢд»Ҙе®һзҺ°ж•°жҚ®дёӯеҝғзә§еҲ«зҡ„е…Ёйқўй«ҳеҸҜз”ЁпјҢзҒҫйҡҫжҒўеӨҚпјҢйӮЈд№ҲеңЁеҲ¶е®ҡиҝҷз§ҚзҒҫйҡҫжҒўеӨҚиҝҮзЁӢдёӯдјҡйҒҮеҲ°зҡ„дёҖдәӣй—®йўҳпјҢеә”иҜҘеҰӮдҪ•еҲ¶е®ҡзҒҫйҡҫжҒўеӨҚи®ЎеҲ’пјҢеҰӮжһңдҪҝз”Ёеҫ®иҪҜWSFCдҪңдёәзҒҫйҡҫжҒўеӨҚж–№ејҸпјҢжҲ‘еә”иҜҘеҰӮдҪ•еҺ»иҖғиҷ‘пјҢжңүе“ӘдәӣйңҖиҰҒжіЁж„Ҹзҡ„ең°ж–№пјҢе°ұжҳҜжҲ‘们д»ҠеӨ©йңҖиҰҒи®Ёи®әзҡ„иҜқйўҳгҖӮ
йҰ–е…ҲпјҢи°Ҳиө·зҒҫйҡҫжҒўеӨҚпјҢеҫҲеӨҡдјҒдёҡжғіиҝҮиҰҒеҒҡпјҢдҪҶжҳҜдёҖдәӣжғ…еҶөдёӢпјҢеҒҡдәҶзҒҫйҡҫжҒўеӨҚж–№жЎҲпјҢдҪҶжҳҜжңҖз»ҲзҒҫйҡҫеҸ‘з”ҹзҡ„ж—¶еҖҷпјҢеҚҙжІЎжңүжҲҗеҠҹпјҢе…¶еҺҹеӣ еӨ§жҰӮжңүдёү
зҒҫйҡҫжҒўеӨҚжңәеҲ¶жңӘз”ҹж•Ҳ
жІЎжңүжҳҺзЎ®зҡ„зҒҫйҡҫжҒўеӨҚи®ЎеҲ’пјҢж“ҚдҪңдәәе‘ҳжңӘиҝӣиЎҢжөӢиҜ•пјҢеҜјиҮҙ延иҝҹзҒҫйҡҫжҒўеӨҚж—¶й—ҙ
жңӘе®һзҺ°иҮӘеҠЁеҢ–жңәеҲ¶пјҢзҒҫйҡҫеҸ‘з”ҹж—¶йңҖиҰҒжүӢеҠЁж“ҚдҪңпјҢдәәе‘ҳеӣ дёәзҒҫйҡҫеҸ‘з”ҹж— жі•иҝӣиЎҢж“ҚдҪң
жҖ»з»“жқҘзңӢпјҢдёҚеӨ–д№ҺдёӨзӮ№пјҢ1.зҒҫйҡҫжҒўеӨҚи®ЎеҲ’жңӘз»ҸиҝҮе‘ЁеҜҶжөӢиҜ• 2.зҒҫйҡҫжҒўеӨҚжңәеҲ¶жңӘе®һзҺ°иҮӘеҠЁеҢ–жңәеҲ¶
иҮӘеҠЁеҢ–жҠҖжңҜжҳҜITиҝҗз»ҙзҡ„еҲ©еҷЁпјҢеҸҜд»Ҙеё®еҠ©жҲ‘们иҠӮзңҒеҫҲеӨ§ж•ҲзҺҮпјҢдёҖдәӣж—¶еҖҷжҲ‘们еә”иҜҘеҺ»дҪҝз”ЁиҮӘеҠЁеҢ–пјҢдҪҶд№ҹдёҚеә”иҜҘе…ЁйғЁдҪҝз”ЁиҮӘеҠЁеҢ–пјҢдёҚиҝҮеңЁзҒҫйҡҫжҒўеӨҚйўҶеҹҹпјҢеҪ“жҲ‘们зңҹжӯЈеҺ»йҮҮз”ЁдёҖдёӘзҒҫйҡҫжҒўеӨҚж–№ејҸж—¶пјҢдёҖе®ҡиҰҒи¶ҠиҮӘеҠЁеҢ–и¶ҠеҘҪпјҢе°ұжҳҜиҜҙпјҢжҲ‘иҝҷдёӘзҒҫйҡҫжҒўеӨҚж–№жЎҲпјҢеңЁжҒўеӨҚзҡ„ж—¶еҖҷпјҢи¶Ҡе°‘йҖҡиҝҮдәәдёәж“ҚдҪңи¶ҠеҘҪпјҢзҗҶжғіжғ…еҶөдёӢпјҢжҲ‘们еә”иҜҘжҳҜе®һзҺ°ж—ўе®ҡзҡ„дёҖеҘ—зҒҫйҡҫжҒўеӨҚжңәеҲ¶пјҢзҒҫйҡҫеҸ‘з”ҹж—¶дёҖеҲҮиҮӘеҠЁеҢ–жү§иЎҢпјҢеә”з”ЁжҒўеӨҚпјҢеҰӮжһңзҒҫйҡҫжҒўеӨҚиҝҮеӨҡдҫқиө–дәәдёәж“ҚдҪңпјҢеҲҷиҝҷдёҚдёҖе®ҡжҳҜдёӘеҫҲеҘҪзҡ„ж–№жЎҲпјҢеӣ дёәдёҖж—Ұзңҹзҡ„зҒҫйҡҫеҸ‘з”ҹпјҢдәәдёҚдёҖе®ҡиғҪеӨҹ第дёҖж—¶й—ҙеҲ°зҺ°еңәжҒўеӨҚеә”з”ЁгҖӮ
жүҖд»ҘпјҢеҪ“жҲ‘们иҰҒеҒҡејӮең°ж•°жҚ®дёӯеҝғж—¶пјҢдёҖе®ҡиҰҒи®Өзңҹзҡ„еқҗдёӢжқҘпјҢе®ҡеҘҪзҒҫйҡҫжҒўеӨҚзҡ„и®ЎеҲ’пјҢе®ҡд№үзҒҫйҡҫжҒўеӨҚи®ЎеҲ’ жҲ‘们йҰ–е…ҲиҰҒиҖғиҷ‘д»ҘдёӢеҮ дёӘеҶ…е®№
зҒҫйҡҫеҸ‘з”ҹеҗҺпјҢжҲ‘们еә”иҜҘеҒҡйӮЈдәӣдәӢпјҢе®ҢжҲҗйӮЈдәӣзӣ®ж ҮпјҢеҰӮдҪ•е°Ҫеҝ«иҫҫжҲҗиҝҷдәӣзӣ®ж Ү
иҝҷдәӣдәӢжғ…зҡ„дјҳе…Ҳзә§йЎәеәҸжҳҜжҖҺд№Ҳж ·зҡ„пјҢжҲ‘еә”иҜҘе…ҲеҒҡйӮЈд»¶пјҢеҗҺеҒҡйӮЈд»¶
иҝҷдәӣдәӢжғ…еә”иҜҘжңүйӮЈдәӣдәәеҒҡпјҢжҳҜеҗҰжҜҸ件дәӢжғ…йғҪеңЁз”ұжңҖеҗҲйҖӮзҡ„дәәеҒҡпјҢжҜҸдёӘжӯҘйӘӨжҜҸдёӘдәәжҳҜеҗҰжңүеӨҮеІ—
жү§иЎҢзҒҫйҡҫжҒўеӨҚзҡ„е…·дҪ“жӯҘйӘӨпјҢеә”иҜҘжҳҜеҪўжҲҗж ҮеҮҶеҢ–жүӢеҶҢгҖӮ
еӨ§дҪ“еҶ…е®№жғіеҘҪдәҶеҗҺпјҢжҲ‘们е°ұеҸҜд»ҘејҖе§ӢеҲ¶е®ҡе…·дҪ“зҡ„зҒҫйҡҫжҒўеӨҚи®ЎеҲ’пјҢдёҖдёӘе®Ңж•ҙзҡ„зҒҫйҡҫжҒўеӨҚи®ЎеҲ’иҮіе°‘еә”иҜҘеҢ…еҗ«д»ҘдёӢеҶ…е®№
зҒҫйҡҫжҒўеӨҚзҡ„иҢғеӣҙпјҡе®ҡд№үзҒҫйҡҫжҒўеӨҚзҡ„иҢғеӣҙпјҢиҢғеӣҙи¶ҠеӨ§пјҢиҝҷйҮҢиҰҒеҶҷзҡ„еҶ…е®№е°ұи¶ҠеӨҡпјҢж•°жҚ®дёӯеҝғпјҢдёӢйқўзҡ„жңҚеҠЎеҷЁпјҢдёҠйқўзҡ„еә”з”ЁпјҢзӯүзӯүгҖӮ
зҒҫйҡҫжҒўеӨҚзі»з»ҹзӣёдҫқжҖ§пјҡжӯӨеӨ„д»ҘдёҡеҠЎзі»з»ҹзә§еҲ«дёәдё»пјҢжҢүз…§еә”з”Ёзі»з»ҹзә§еҲ«жқҘзңӢжҜҸдёӘзі»з»ҹзҡ„дҫқиө–жҖ§пјҢдҫҝдәҺжҲ‘们еҲ¶е®ҡжҒўеӨҚзӯ–з•ҘжөҒзЁӢ
зҒҫйҡҫжҒўеӨҚзӯ–з•Ҙпјҡж №жҚ®зҒҫйҡҫжҒўеӨҚиҢғеӣҙе’Ңдҫқиө–жҖ§зҡ„е®ҡд№үпјҢзј–еҶҷжҒўеӨҚзӯ–з•ҘпјҢжҜҸдёҖдёӘзі»з»ҹпјҢжҜҸдёҖдёӘ组件пјҢзҒҫйҡҫеҸ‘з”ҹж—¶еә”иҜҘеҰӮдҪ•жҒўеӨҚпјҢдҪҝз”Ёд»Җд№Ҳж–№ејҸпјҢеә”иҜҘжҢүз…§жҖҺд№Ҳж ·зҡ„йЎәеәҸпјҢеҰӮдҪ•ж“ҚдҪңпјҢж“ҚдҪңе®ҢжҲҗеҗҺеҰӮдҪ•йӘҢиҜҒпјҢеҰӮдҪ•и§„йҒҝйЈҺйҷ©гҖӮ
зҒҫйҡҫжҒўеӨҚж–№ејҸпјҡе…·дҪ“зҒҫйҡҫжҒўеӨҚзӯ–з•Ҙжү§иЎҢж—¶иҰҒдҪҝз”Ёзҡ„ж–№ејҸпјҡеҸҜд»ҘжҳҜжүӢеҠЁпјҢй«ҳеҸҜз”ЁзҫӨйӣҶпјҢеӨҚеҲ¶еүҜжң¬пјҢеӨҮд»ҪпјҢзӯүзӯүпјҢе°ҪеҸҜиғҪйҮҮз”ЁдёҡеҠЎзі»з»ҹж”ҜжҢҒзҡ„пјҢдәәе‘ҳзҶҹжӮүзҡ„пјҢиҮӘеҠЁеҢ–зҡ„ж–№ејҸгҖӮ
зҙ§жҖҘиҒ”з»ңж–№ејҸпјҡзҒҫйҡҫжҒўеӨҚе№Ізі»дәәпјҢйўҶеҜјиҙҹиҙЈдәәпјҢзҒҫйҡҫжҒўеӨҚж“ҚдҪңдәәе‘ҳпјҢеә”з”ЁйӘҢиҜҒдәәе‘ҳзҡ„иҒ”зі»ж–№ејҸпјҢзЎ®дҝқеҸҜд»Ҙ第дёҖж—¶й—ҙиҒ”зі»еҲ°
зҒҫйҡҫе®ҡжңҹжј”з»ғ : зҒҫйҡҫжҒўеӨҚдёҖеӨ§йғЁеҲҶжІЎжңүжҲҗеҠҹзҡ„еҺҹеӣ е°ұжҳҜеӣ дёәзјәе°‘е®ҡжңҹжј”з»ғпјҢеҜјиҮҙзҒҫйҡҫеҸ‘з”ҹж—¶пјҢж—ўе®ҡзҡ„зҒҫйҡҫжҒўеӨҚи®ЎеҲ’еӨұж•ҲпјҢдёҚиғҪеҫ—еҲ°жү§иЎҢпјҢеӣ жӯӨзҒҫйҡҫе®ҡжңҹжј”з»ғдәӢе…ійҮҚиҰҒпјҢе»әи®®жңҖе°‘жҜҸе№ҙжү§иЎҢдёҖж¬ЎзҒҫйҡҫжј”з»ғ
зҒҫйҡҫйҮҚзҺ° пјҡеҰӮжһңиғҪеҒҡеҲ°иҝҷдёҖзӮ№жңҖеҘҪпјҢжҜҸж¬ЎзҒҫйҡҫжҒўеӨҚжј”з»ғеҗҺпјҢжҲ–е®һйҷ…зҡ„зҒҫйҡҫжҒўеӨҚеҗҺпјҢиҰҒжұӮж“ҚдҪңдәәе‘ҳпјҢжҲ–зҒҫйҡҫжҒўеӨҚе°Ҹз»„пјҢе°ҶжӯӨж¬ЎзҒҫйҡҫжҒўеӨҚиҝҮзЁӢиҝӣиЎҢи®°еҪ•пјҢдәӢеҗҺеӣһзңӢпјҢжҳҜеҗҰжҢүз…§и®ЎеҲ’жү§иЎҢпјҢиҝҳжңүйӮЈдәӣеҸҜд»ҘдјҳеҢ–зҡ„ең°ж–№пјҢдҪңдёәе®қиҙөзҡ„зҹҘиҜҶгҖӮ
д»ҘдёҠпјҢиҖҒзҺӢз»“еҗҲиҮӘе·ұзҡ„дёҖзӮ№еӯҰд№ пјҢдёәеӨ§е®¶жҖ»з»“зҡ„зҒҫйҡҫжҒўеӨҚеҹәжң¬зҗҶи®әпјҢд№ӢжүҖд»ҘиҰҒеҶҷиҝҷдәӣе‘ўпјҢжҳҜеӣ дёәиҖҒзҺӢзңӢеҲ°еҫҲеӨҡдјҒдёҡжҳҺжҳҺжғіиҰҒеҒҡеӨҡең°ж•°жҚ®дёӯеҝғпјҢжғіиҰҒеҒҡеҸҢжҙ»ж•°жҚ®дёӯеҝғпјҢзҒҫеӨҮж•°жҚ®дёӯеҝғпјҢдҪҶжҳҜдёҖжӢҚи„‘иўӢе°ұеҒҡдәҶпјҢжІЎжңүдәӢе…Ҳ规еҲ’еҘҪпјҢд№ҹе°ұжІЎжңүж„Ҹд№үпјҢеёҢжңӣзңӢеҲ°зҡ„жңӢеҸӢеҸҜд»ҘжңүжүҖ收иҺ·пјҢеңЁеҲ¶е®ҡзҒҫеӨҮж•°жҚ®дёӯеҝғзҡ„ж—¶еҖҷеҸҜд»ҘеёҰжқҘдёҖдәӣеё®еҠ©гҖӮ
йӮЈд№ҲпјҢжҲ‘们д»ҠеӨ©дё»иҰҒи°Ҳзҡ„жҳҜзҒҫйҡҫжҒўеӨҚзҡ„ж–№ејҸпјҢеҫ®иҪҜеҜ№дәҺзҒҫйҡҫжҒўеӨҚзҡ„ж–№ејҸжңүеҫҲеӨҡпјҢhyper-vеӨҚеҲ¶пјҢеӨҮд»ҪпјҢWSFCзҫӨйӣҶпјҢASRпјҢзӯүзӯүпјҢйғҪеҸҜд»ҘеҒҡзҒҫйҡҫжҒўеӨҚзҡ„ж–№ејҸ
е…¶дёӯжҲ‘们д»ҠеӨ©е…іжіЁзҡ„е°ұжҳҜWSFCзҫӨйӣҶпјҢWSFCз”ЁдәҺеӨҡз«ҷзӮ№ж•°жҚ®дёӯеҝғзҫӨйӣҶпјҢе®ғжңүдёҖдёӘеҘҪеӨ„пјҢе°ұжҳҜWSFCзі»з»ҹжң¬иә«пјҢжҳҜеҸҜд»Ҙе®һзҺ°е®Ңе…ЁиҮӘеҠЁеҢ–зҡ„ж•…йҡңиҪ¬з§»жңәеҲ¶зҡ„пјҢеҸӘиҰҒзҫӨйӣҶеҫ—еҲ°жӯЈзЎ®зҡ„й…ҚзҪ®пјҢж•…йҡңеҸ‘з”ҹж—¶пјҢWSFCдјҡиҮӘеҠЁзҡ„иҝӣиЎҢеҲҮжҚўпјҢдёҚйңҖиҰҒдәәдёәе№Ійў„пјҢйҷӨйқһдҪ WSFCзҫӨйӣҶдёҠйқўи·‘зҡ„еә”з”ЁпјҢйңҖиҰҒж•…йҡңиҪ¬з§»еҗҺйўқеӨ–еҒҡй…ҚзҪ®гҖӮ
WSFCзңҹжӯЈејҖе§ӢеҜ№дәҺеӨҡз«ҷзӮ№ж•°жҚ®дёӯеҝғж”ҜжҢҒзҡ„жҳҜWSFC 2008пјҢеңЁ2008ж—¶д»ЈпјҢWSFCејҖе§Ӣж”ҜжҢҒеӨҡеӯҗзҪ‘зҡ„зҫӨйӣҶжһ¶жһ„пјҢеҚіжҳҜиҜҙпјҢдҪ еҸҜд»ҘеҢ—дә¬дёӨдёӘиҠӮзӮ№жҳҜ10зҪ‘ж®өпјҢдёҠжө·дёӨдёӘиҠӮзӮ№жҳҜ20зҪ‘ж®өпјҢд№ҹеҸҜд»Ҙе…Ғи®ёдҪ еҲӣе»әдёҖдёӘзҫӨйӣҶпјҢеҢ—дә¬иҠӮзӮ№еҙ©жәғж—¶еҖҷпјҢеә”з”Ёд№ҹеҸҜд»ҘжјӮ移еҲ°20зҪ‘ж®өзҡ„дёҠжө·дёҠйқўз»§з»ӯе·ҘдҪңпјҢиҖҢеңЁ2003еҲҷдёҚеҸҜд»ҘпјҢ2003ж—¶д»ЈжүҖжңүзҫӨйӣҶиҠӮзӮ№еҝ…йЎ»жҳҜеҗҢдёҖеӯҗзҪ‘гҖӮ
е®һзҺ°еӨҡеӯҗзҪ‘жҠҖжңҜпјҢжңҖе…ій”®зҡ„жҳҜ2008ж—¶д»ЈWSFCејҖе§Ӣж”ҜжҢҒзҫӨйӣҶз»„зҪ‘з»ңеҗҚз§°дҫқиө–е…ізі»иҮӘе®ҡд№үдәҶпјҢеҜ№дәҺдёҖдёӘзҫӨйӣҶз»„пјҢжҲ‘们еҸҜд»Ҙи®©зҪ‘з»ңеҗҚз§°еҜ№еә”еҫҲеӨҡдёӘеӯҗзҪ‘зҡ„IPең°еқҖпјҢиҝҷдәӣдёҚеҗҢеӯҗзҪ‘IPең°еқҖеҸҜд»ҘжҳҜORе…ізі»пјҢеҸӘиҰҒе…¶дёӯдёҖдёӘиғҪеӨҹиҒ”жңәжіЁеҶҢпјҢйӮЈд№Ҳеә”з”Ёе°ұеҸҜд»ҘжӯЈеёёжҸҗдҫӣжңҚеҠЎгҖӮеҪ“ж•…йҡңиҪ¬з§»д№ӢеҗҺпјҢеңЁеҸҰеӨ–еӯҗзҪ‘ең°еқҖиҒ”жңәжіЁеҶҢеҗҚз§°пјҢеә”з”ЁеҲҮжҚўеҲ°еҸҰеӨ–еӯҗзҪ‘ең°еқҖжҸҗдҫӣжңҚеҠЎгҖӮ
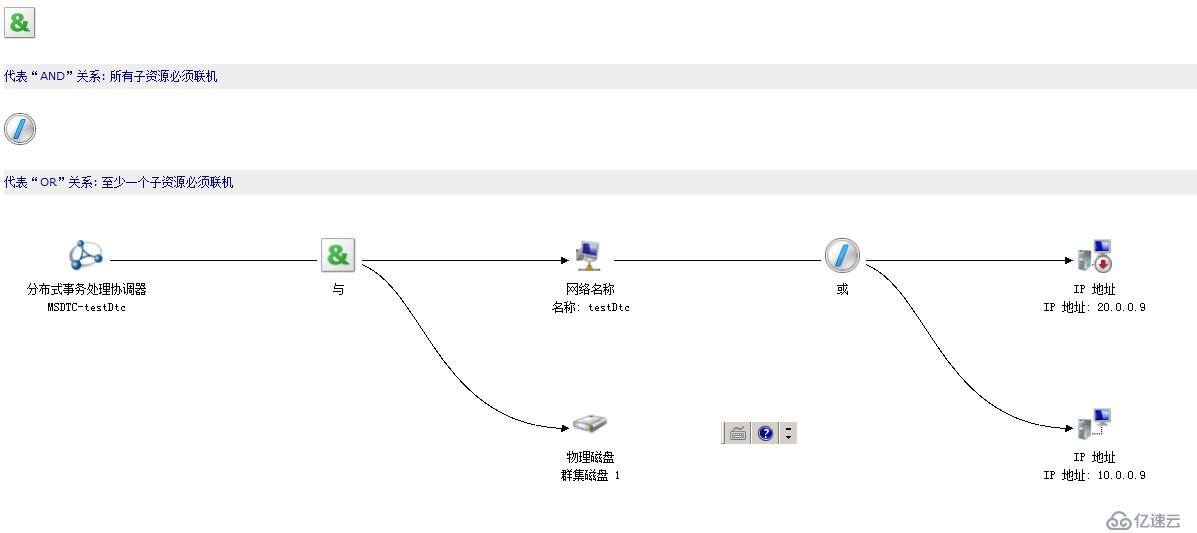
еңЁWSFC 2008ж—¶д»ЈпјҢиҷҪ然WSFCжң¬иә«е®һзҺ°дәҶеҜ№дәҺеӨҡеӯҗзҪ‘зҡ„ж”ҜжҢҒпјҢдҪҶжҳҜдёҖдәӣзҫӨйӣҶдёҠйқўзҡ„еә”з”ЁеҚҙ并дёҚиғҪеҫҲеҘҪзҡ„ж”ҜжҢҒеӨҡеӯҗзҪ‘пјҢдҫӢеҰӮSQL 2005пјҢSQL 2008пјҢHyper-V 2008е®һж—¶иҝҒ移 пјҢиҷҪ然жҲ‘们йғЁзҪІдәҶеӨҡеӯҗзҪ‘зҡ„зҫӨйӣҶпјҢдҪҶжҳҜиҝҷдәӣеә”з”ЁеҚҙ并дёҚж”ҜжҢҒеӨҡеӯҗзҪ‘пјҢдҫқ然д№ҹжІЎжңүж„Ҹд№үпјҢSQL2008R2пјҢHyper-V 2012еҗҺпјҢдёҖеҲҮйғҪеҫ—еҲ°дәҶж”№е–„гҖӮ
еңЁжҲ‘们иҖғиҷ‘WSFCеӨҡз«ҷзӮ№ж—¶пјҢжҲ‘们主иҰҒеҸҜд»Ҙд»Һд»ҘдёӢеҮ дёӘж–№йқўжқҘзңӢ
зҪ‘з»ң
д»ІиЈҒ
еӯҳеӮЁ
зҪ‘з»ң
еҜ№дәҺWSFCеӨҡз«ҷзӮ№зҪ‘з»ңпјҢжҲ‘们йҰ–е…ҲиҰҒжҖқиҖғпјҢж•ҙдёӘеӨҡз«ҷзӮ№зҺҜеўғйҮҮз”Ёд»Җд№Ҳж ·зҡ„зҪ‘з»ңжһ¶жһ„
еӨҡеӯҗзҪ‘
дёҚеҗҢз«ҷзӮ№зҡ„иҠӮзӮ№пјҢжҳҜеҗҰиҰҒдҪҝз”ЁдёҚеҗҢеӯҗзҪ‘пјҢеҰӮжһңдҪҝз”ЁдёҚеҗҢеӯҗзҪ‘пјҢдёҠеұӮеә”з”ЁжҳҜеҗҰж”ҜжҢҒпјҢжҳҜеҗҰдјҡеёҰжқҘйўқеӨ–зҡ„жүӢеҠЁж“ҚдҪңпјҢеӨҡеӯҗзҪ‘жҳҜеҜ№еӨ–зҪ‘з»ңеӨҡеӯҗзҪ‘пјҢиҝҳжҳҜеҝғи·ізҪ‘з»ңд№ҹиҰҒеӨҡеӯҗзҪ‘пјҢеҰӮжһңеҝғи·ізҪ‘з»ңеӨҡеӯҗзҪ‘еҰӮдҪ•йҖҡи®ҜпјҢжҳҜеҗҰйңҖиҰҒж·»еҠ йқҷжҖҒи·Ҝз”ұгҖӮ
2.延伸VLANпјҢзҪ‘з»ңжү“йҖҡ
дёҚеҗҢз«ҷзӮ№зҡ„иҠӮзӮ№пјҢзҪ‘з»ңе·Із»Ҹжү“йҖҡпјҢдёҚйңҖиҰҒеҗ„иҠӮзӮ№дҪҝз”ЁдёҚеҗҢеӯҗзҪ‘пјҢжүҖжңүиҠӮзӮ№йғҪеңЁдёҖдёӘеӯҗзҪ‘пјҢиҝҷз§Қж–№жЎҲпјҢеҜ№дәҺзҫӨйӣҶпјҢеә”з”ЁжқҘи®ІжңҖдёәзңҒдәӢпјҢж”ҜжҢҒеәҰжңҖеҘҪпјҢдҪҶжҳҜеҸҜиғҪзҪ‘з»ңдәәе‘ҳдјҡйңҖиҰҒйўқеӨ–иҝӣиЎҢдёҖдәӣй…ҚзҪ®гҖӮ
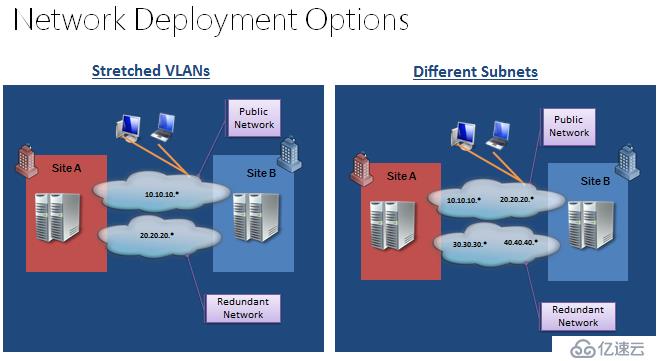
еӨҡз«ҷзӮ№зҫӨйӣҶзҪ‘з»ңзҺҜеўғдёӢзҡ„жҖқиҖғ
и·Ёз«ҷзӮ№еҝғи·іжЈҖжөӢйҳҖеҖј
з”ұдәҺзҫӨйӣҶйғЁзҪІдёәеӨҡз«ҷзӮ№пјҢе…¶й—ҙзҪ‘з»ңиӮҜе®ҡдјҡеӨҡжҲ–е°‘дјҡжңүдёҖдәӣ延иҝҹпјҢеҰӮдҪ•и°ғж•ҙеҝғи·іжЈҖжөӢйҳҖеҖјдёәжңҖеҗҲйҖӮпјҢиҝҷйҮҢзҡ„еҝғи·іжЈҖжөӢйҳҖеҖјдёәжңҖе…ій”®пјҢдёҖж—Ұз”ұдәҺзҪ‘з»ң延иҝҹпјҢжҲ–зҪ‘з»ңиҙЁйҮҸпјҢеҜјиҮҙеҝғи·іжЈҖжөӢйҳҖеҖјиҫҫеҲ°пјҢе°Ҷдјҡи§ҰеҸ‘ж•…йҡңиҪ¬з§»пјҢеӣ жӯӨеҠЎеҝ…иҰҒзЎ®дҝқзҪ‘з»ңиҙЁйҮҸеҸҜйқ пјҢе№¶ж №жҚ®е®һйҷ…зҡ„зҪ‘з»ң延иҝҹжғ…еҶөи°ғж•ҙжңҖдёәеҗҲйҖӮпјҢжңҖиғҪеҮҶзЎ®еҸҚеә”ж•…йҡңзҡ„жЈҖжөӢйҳҖеҖјпјҢеҰӮжһңеӨҡз«ҷзӮ№зҪ‘з»ңжһ¶жһ„дҪҝ用延伸VLANзҡ„ж–№ејҸпјҢеҸҜд»ҘдҪҝз”ЁWSFC 2016йҮҢйқўзҡ„и·Ёз«ҷзӮ№йҳҖеҖје®ҡд№үеҠҹиғҪ
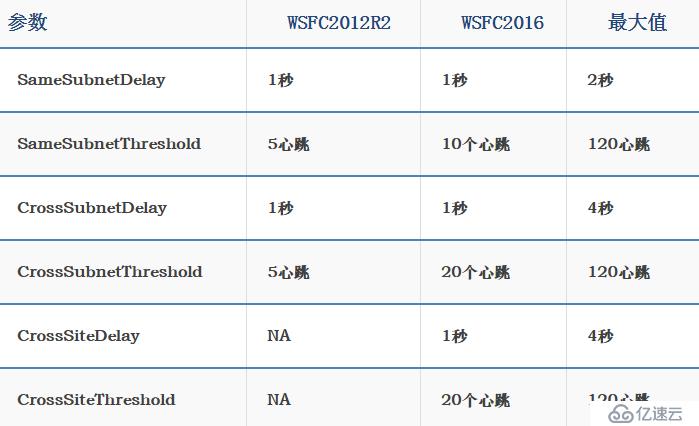
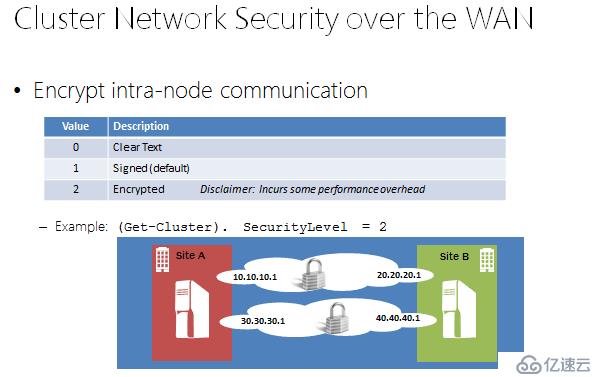
2.и·Ёз«ҷзӮ№зҫӨйӣҶйҖҡи®ҜжҳҜеҗҰеҠ еҜҶ
й»ҳи®Өжғ…еҶөдёӢеҗҢдёҖеӯҗзҪ‘еҶ…иҠӮзӮ№зҫӨйӣҶйҖҡдҝЎпјҢе°Ҷдјҡиў«зӯҫеҗҚпјҢйҖҡеёёжғ…еҶөдёӢдёҚйңҖиҰҒжӣҙж”№жӯӨеҶ…е®№пјҢеҰӮжһңиҜҙжӮЁзҡ„зҫӨйӣҶжһ¶жһ„жҳҜи·Ёз«ҷзӮ№пјҢдјҡз»ҸиҝҮinternetпјҢжӮЁеҸҜд»ҘжҠҠзҫӨйӣҶйҖҡдҝЎе®үе…Ёзә§еҲ«ж”№дёәеҠ еҜҶпјҢиҝҷж ·зҫӨйӣҶй—ҙйҖҡдҝЎдјҡйҖҡиҝҮеҠ еҜҶпјҢжӣҙдёәе®үе…ЁпјҢеҰӮжһңжӮЁзҡ„и·Ёз«ҷзӮ№жһ¶жһ„пјҢжҳҜйҖҡиҝҮеҚ•зӢ¬зҡ„е®үе…ЁйҖҡйҒ“жһ„е»әпјҢйӮЈд№ҲжӮЁд№ҹеҸҜд»ҘеҸ–ж¶ҲзӯҫеҗҚе’ҢеҠ еҜҶпјҢйңҖиҰҒжіЁж„Ҹзҡ„жҳҜеҸ–ж¶ҲзҫӨйӣҶйҖҡдҝЎзӯҫеҗҚе’ҢеҠ еҜҶдјҡеёҰжқҘжҖ§иғҪжҸҗй«ҳпјҢеҰӮжһңйҮҮз”ЁзҫӨйӣҶйҖҡдҝЎеҠ еҜҶпјҢдјҡеёҰжқҘдёҖзӮ№зӮ№зҡ„жҖ§иғҪдёӢйҷҚпјҢеӣ дёәиҠӮзӮ№жҜҸ次收еҸ‘жөҒйҮҸйғҪдјҡеӨҡдёҖдёӘеҠ еҜҶи§ЈеҜҶзҡ„иҝҮзЁӢпјҢеҰӮйңҖжӣҙж”№пјҢе»әи®®дәӢе…ҲеҒҡеҘҪжөӢиҜ•пјҢзЎ®и®ӨеҠ еҜҶеҗҺжҖ§иғҪеёҰжқҘзҡ„дёӢйҷҚеҸҜд»ҘжҺҘеҸ—пјҢеҶҚжӣҙж”№дёәеҠ еҜҶ
3.еӨҡеӯҗзҪ‘зҺҜеўғдёӢVMеҰӮдҪ•иҝһжҺҘ
еҰӮжһңжҲ‘们еңЁеӨҡеӯҗзҪ‘зҡ„зҺҜеўғдёӢйғЁзҪІдәҶиҷҡжӢҹжңәпјҢйӮЈд№ҲиҷҡжӢҹжңәзҡ„зҪ‘з»ңиҝһжҺҘжҳҜдёӘй—®йўҳпјҢеҰӮжһңиҷҡжӢҹжңәеңЁеҢ—дә¬з«ҷзӮ№й…ҚзҪ®зҡ„йқҷжҖҒIPпјҢжҳҜйҖҡиҝҮеҢ—дә¬иҷҡжӢҹдәӨжҚўжңәеҮәеҺ»зҡ„пјҢеҲ°дәҶдёҠжө·еӯҗзҪ‘дёҚеҗҢпјҢиҷҡжӢҹжңәеҺҹжңүIPе°Ҷж— жі•йҖҡдҝЎ
еӣ жӯӨпјҢеҜ№дәҺеӨҡз«ҷзӮ№зҺҜеўғдёӢзҡ„VMпјҢжҲ‘们йҖҡеёёжңүд»ҘдёӢеҮ з§ҚеҠһжі•
й’ҲеҜ№иҷҡжӢҹжңәдҪҝз”ЁDHCP IPең°еқҖ
й’ҲеҜ№иҷҡжӢҹжңәдҪҝз”ЁйқҷжҖҒIPпјҢдҪҶжҳҜеңЁиҷҡжӢҹжңәеҶ…йғЁзј–еҶҷи„ҡжң¬пјҢдёҖж—ҰжЈҖжөӢеҲ°зҪ‘з»ңзҺҜеўғеҸ‘з”ҹж”№еҸҳпјҢеҚіеҲҮжҚўдёәзӣ®ж ҮйқҷжҖҒIP
й’ҲеҜ№еӨҡз«ҷзӮ№зҺҜеўғдҪҝ用延伸VLANзҪ‘з»ңжһ¶жһ„пјҢиҷҡжӢҹжңәжҺҘе…ҘеҗҢдёҖдёӘеӯҗзҪ‘
й’ҲеҜ№иҷҡжӢҹжңәдҪҝз”ЁзҪ‘з»ңиҷҡжӢҹеҢ–еҠҹиғҪпјҢи®©иҷҡжӢҹжңәеёҰзқҖIPиҝҒ移еҲ°дёҚеҗҢз«ҷзӮ№
еңЁHyper-VеӨҚеҲ¶дёӯе’ҢASRдёӯеҸҲжӣҙеҘҪзҡ„и§ЈеҶіж–№жЎҲпјҢеҸҜд»Ҙе®һзҺ°зҒҫйҡҫжҒўеӨҚеҗҺиҮӘеҠЁи®ҫзҪ®иҷҡжӢҹжңәдёәзӣ®ж ҮIPпјҢеӣ жӯӨеҜ№дәҺиҷҡжӢҹеҢ–зҡ„зҒҫйҡҫжҒўеӨҚпјҢеҰӮжһңиҖғиҷ‘еҲ°еӨҡеӯҗзҪ‘WSFCдёҚеӨӘж–№дҫҝпјҢжӮЁд№ҹеҸҜд»ҘйҖүжӢ©Hyper-VеӨҚеҲ¶пјҢжҲ–ASRгҖӮ
4.еӨҡз«ҷзӮ№зҺҜеўғдёӢе®ўжҲ·з«ҜиҝһжҺҘ延иҝҹзҡ„й—®йўҳ
жүҖи°“е®ўжҲ·з«ҜиҝһжҺҘ延иҝҹпјҢеҚіжҳҜиҜҙпјҢзҫӨйӣҶе®ҢжҲҗдәҶж•…йҡңиҪ¬з§»пјҢдҪҶжҳҜе®ўжҲ·з«ҜеҚҙиҝҳжҳҜдёҚиғҪи®ҝй—®еә”з”Ёзҡ„иҝҷж®өж—¶й—ҙпјҢйҖҡеёёжғ…еҶөдёӢпјҢжңүдёӨз§ҚеҺҹеӣ пјҢ1.зҫӨйӣҶж•…йҡңиҪ¬з§»е®ҢжҲҗеҗҺеә”з”ЁйңҖиҰҒйўқеӨ–й…ҚзҪ®жүҚеҸҜд»ҘжҸҗдҫӣи®ҝй—® 2.DNSе®ўжҲ·з«Ҝ延иҝҹ
иҝҷйҮҢжҲ‘们主иҰҒи°Ҳзҡ„жҳҜDNSе®ўжҲ·з«Ҝ延иҝҹзҡ„й—®йўҳпјҢд»Җд№ҲжҳҜDNSе®ўжҲ·з«Ҝ延иҝҹпјҢд»ҘдёӢеӣҫдёәдҫӢпјҢеҰӮжһңжҲ‘们дҪҝз”ЁеӨҡз«ҷзӮ№еӨҡеӯҗзҪ‘зҡ„зҪ‘з»ңжһ¶жһ„пјҢе°ұдјҡйқўдёҙиҝҷж ·зҡ„й—®йўҳпјҢVCOеңЁ SiteAжҳҜ10зҪ‘ж®өIPпјҢжіЁеҶҢеҲ°DNSпјҢDNSжҠҠиҝҷжқЎи®°еҪ•еӨҚеҲ¶еҲ°SiteBпјҢSiteBе®ўжҲ·з«Ҝи®ҝй—®VCOд»Ҙдёәең°еқҖе°ұжҳҜ10зҪ‘ж®өпјҢеҪ“еҸ‘з”ҹж•…йҡңиҪ¬з§»пјҢзҫӨйӣҶд»ҺSiteAиҪ¬з§»еҲ°SiteBпјҢVCOзҡ„ең°еқҖеҸ‘з”ҹдәҶж”№еҸҳпјҢдҝ®ж”№еҗҺзҡ„и®°еҪ•еӨҚеҲ¶еҲ°DNS Server 2пјҢиҷҪ然зҫӨйӣҶе®ҢжҲҗдәҶж•…йҡңиҪ¬з§»пјҢDNSи®°еҪ•д№ҹеҫ—еҲ°дәҶеӨҚеҲ¶пјҢдҪҶжҳҜSiteBзҡ„е®ўжҲ·з«ҜеңЁ1200з§’еҶ…иҝҳжҳҜжІЎеҠһжі•и®ҝй—®иҪ¬з§»еҗҺзҡ„жңҚеҠЎпјҢеӣ дёәDNSжңҚеҠЎеҷЁдёҠжҜҸдёӘи®°еҪ•йғҪдјҡжңүдёҖдёӘHostRecordTTLж—¶й—ҙпјҢиҝҷж®өж—¶й—ҙеҶ…пјҢе®ўжҲ·з«Ҝе°ҶдҪҝз”Ёзј“еӯҳзҡ„ең°еқҖпјҢиҖҢдёҚеҶҚиҜ·жұӮж–°зҡ„ең°еқҖпјҢеӣ жӯӨпјҢиҝҷжҳҜжҲ‘们йңҖиҰҒиҖғиҷ‘зҡ„ең°ж–№гҖӮ
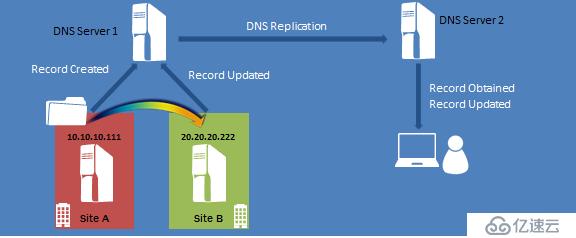
иҰҒи§ЈеҶіDNSе®ўжҲ·з«Ҝ延иҝҹй—®йўҳпјҢжңүеҮ з§ҚеҠһжі•
дҪҝ用延伸VLANзҡ„зҪ‘з»ңжһ¶жһ„пјҢйғҪжҳҜеҗҢдёҖдёӘеӯҗзҪ‘пјҢдёҚйңҖиҰҒдҝ®ж”№ең°еқҖпјҢдёҚж¶үеҸҠеҲ°DNSзј“еӯҳ
дҪҝз”ЁзҪ‘з»ңжҠҪиұЎи®ҫеӨҮпјҢи®©зҫӨйӣҶзҪ‘з»ңеҗҚз§°е§Ӣз»ҲжіЁеҶҢеҲ°дёҖдёӘжҠҪиұЎзҡ„зҪ‘з»ңи®ҫеӨҮдёҠйқўпјҢ然еҗҺзҪ‘з»ңи®ҫеӨҮеңЁжҠҠдёҖдёӘжҠҪиұЎзҡ„ең°еқҖжіЁеҶҢеҲ°DNSпјҢдёҚи®әжҳҜSite AжҲ–жҳҜSite BпјҢDNS Serverе§Ӣз»ҲйқўеҜ№жҠҪиұЎзҪ‘з»ңи®ҫеӨҮзҡ„ең°еқҖпјҢдёҚж¶үеҸҠеҲ°DNSзј“еӯҳ
дҪҝз”Ёдјҳе…Ҳжң¬ең°иҪ¬з§»ж–№жЎҲпјҢй…ҚзҪ®еә”з”Ёзҡ„йҰ–йҖүжүҖжңүиҖ…жңӘжң¬ең°иҠӮзӮ№пјҢжң¬ең°жүҖжңүиҖ…еӨұиҙҘеҗҺпјҢеҶҚиҪ¬з§»иҮіи·Ёз«ҷзӮ№
дјҳеҢ–еӨҡеӯҗзҪ‘дёӢзҡ„DNSзј“еӯҳж—¶й—ҙе’ҢжңәеҲ¶пјҡ2008ж—¶д»ЈWSFCй’ҲеҜ№дәҺеӨҡз«ҷзӮ№пјҢж–°еўһдёӨдёӘеұһжҖ§пјҢеҲҶеҲ«жҳҜHostRecordTTLе’ҢRegisterAllProvidersIPпјҢHostRecordTTLеұһжҖ§еҸҜд»Ҙдҝ®ж”№DNSзј“еӯҳзҡ„ж—¶й—ҙпјҢй»ҳи®ӨжҳҜ1200з§’е®ўжҲ·з«ҜеҶҚе’ҢDNSиҜ·жұӮж–°зҡ„ең°еқҖпјҢжҲ‘们дҝ®ж”№жҹҗдёӘзҫӨйӣҶзҪ‘з»ңеҗҚз§°зҡ„иҝҷдёӘж—¶й—ҙдёә300з§’пјҢиҝҷж ·е®ўжҲ·з«Ҝе°ұдјҡжӣҙйў‘з№Ғзҡ„е’ҢDNSжңҚеҠЎеҷЁиҜ·жұӮж–°зҡ„ең°еқҖгҖӮеҫ®иҪҜе»әи®®жңҖзҹӯдёҚиҰҒи¶…иҝҮ300з§’пјҢеҗҰеҲҷдјҡеёҰжқҘDNSжңҚеҠЎеҷЁжҖ§иғҪй—®йўҳгҖӮRegisterAllProvidersIPеұһжҖ§еҸҜд»Ҙи®©дёҖдёӘзҪ‘з»ңеҗҚз§°пјҢеҗҢж—¶жіЁеҶҢеӨҡдёӘеӯҗзҪ‘зҡ„ең°еқҖпјҢй»ҳи®Өжғ…еҶөдёӢзҪ‘з»ңеҗҚз§°еҜ№еә”еӨҡдёӘORе…ізі»IPпјҢеҗҢдёҖдёӘж—¶й—ҙеҸӘдјҡжіЁеҶҢдёҖдёӘең°еқҖпјҢеҰӮжһңиҝҷдёӘзҪ‘з»ңзҡ„ең°еқҖдёҚеҸҜз”ЁпјҢеҲҮжҚўеҲ°еҸҰеӨ–з«ҷзӮ№пјҢеҶҚжіЁеҶҢеҸҰеӨ–дёҖдёӘпјҢиҖҢRegisterAllProvidersIPеҲҷжҳҜзӣҙжҺҘж”ҜжҢҒжіЁеҶҢжүҖжңүз«ҷзӮ№зҡ„DNSи®°еҪ•пјҢдҪҶжӯӨеҠҹиғҪиҰҒжұӮеә”з”Ёж”ҜжҢҒпјҢSQL 2012д№ӢеҗҺејҖе§Ӣж”ҜжҢҒжӯӨеҠҹиғҪпјҢеә”з”Ёе®һйҷ…дёҠдјҡе…Ҳе°қиҜ•иҝһжҺҘдёҖдёӘIPпјҢеҰӮжһңе°қиҜ•иҝһдёҚеҲ°пјҢиҮӘеҠЁиҝһеҸҰеӨ–дёҖдёӘең°еқҖгҖӮ
д»ІиЈҒ
еҜ№дәҺеӨҡз«ҷзӮ№зҫӨйӣҶжқҘиҜҙпјҢд»ІиЈҒд№ҹжҳҜдёӘеҖјеҫ—жҖқиҖғзҡ„й—®йўҳ
и§ҒиҜҒеә”иҜҘж”ҫеңЁйӮЈ
еҜ№дәҺеӨҡз«ҷзӮ№зҫӨйӣҶиҖҢиЁҖпјҢи§ҒиҜҒжңҖеҘҪдёҚиҰҒж”ҫеңЁеӨҡз«ҷзӮ№жң¬иә«пјҢеӣ дёәиҝҷж ·дјҡеӯҳеңЁдёҖе®ҡзҡ„еҒҸиў’ж•Ҳеә”пјҢеҪ“еҸ‘з”ҹзҪ‘з»ңеҲҶеҢәж—¶пјҢеҸӘиҰҒиҺ·еҫ—и§ҒиҜҒзҡ„дёҖж–№е°ҶдјҡеҗҜеҠЁжҸҗдҫӣжңҚеҠЎ
еӣ жӯӨпјҢе»әи®®еҜ№дәҺеӨҡз«ҷзҡ„и§ҒиҜҒд»ІиЈҒпјҢжңҖеҘҪж”ҫеңЁз¬¬дёүдёӘз«ҷзӮ№зҡ„ж–Ү件и§ҒиҜҒпјҢзЈҒзӣҳи§ҒиҜҒпјҢжҲ–дҪҝз”ЁWSFC 2016зҡ„дә‘и§ҒиҜҒеҠҹиғҪпјҢиҝҷж ·дёҚеӯҳеңЁеҒҸиў’ж•Ҳеә”пјҢйӮЈдёӘз«ҷзӮ№еҸҜд»ҘжӯЈеёёдёҺ第дёүдёӘз«ҷзӮ№жҲ–дә‘иҝһжҺҘпјҢеҚіеӯҳжҙ»гҖӮ
2.и§ҒиҜҒзҪ‘з»ңеә”иҜҘеҰӮдҪ•и®ҫи®Ў
дёҖдёӘеӨұиҙҘзҡ„и§ҒиҜҒзҪ‘з»ңи®ҫи®ЎжҳҜе’Ңеҝғи·ізҪ‘з»ңпјҢеҜ№еӨ–зҪ‘з»ңи®ҫи®ЎеңЁдёҖиө·пјҢдҫӢеҰӮпјҢеҰӮжһңеӨҡз«ҷзӮ№зҡ„еҜ№еӨ–зҪ‘з»ңзәҝи·ҜеҪ»еә•зҳ«з—ӘпјҢиҖҢи§ҒиҜҒиҝһжҺҘзҪ‘з»ңе’ҢеҜ№еӨ–зҪ‘з»ңдҪҝз”ЁзӣёеҗҢзҪ‘з»ңй“ҫи·ҜпјҢйӮЈд№Ҳи§ҒиҜҒиҝһжҺҘзҪ‘з»ңд№ҹе°Ҷдјҡзҳ«з—ӘпјҢзҒҫеӨҮз«ҷзӮ№еҸҜиғҪеӣ жӯӨжІЎеҠһжі•жӯЈеёёеҗҜеҠЁпјҢеӣ жӯӨи§ҒиҜҒзҡ„иҝһжҺҘдёҖе®ҡиҰҒеҒҡеҲ°еҚ•зӢ¬дҪҝз”ЁдёҖдёӘзҪ‘з»ңпјҢйҳІжӯўеӣ дёәзҪ‘з»ңж•…йҡңпјҢиҖҢеҜјиҮҙи§ҒиҜҒеӨұеҺ»ж•ҲжһңгҖӮ
3.жҳҜеҗҰиҰҒжҗӯе»әеҶ·еӨҮз«ҷзӮ№
дёҖдәӣдјҒдёҡеҸҜиғҪдјҡжңүеҶ·еӨҮз«ҷзӮ№зҡ„йңҖжұӮпјҢеҚідёҖдёӘжӯЈеёёжғ…еҶөдёӢпјҢдёҚеҜ№еӨ–жҸҗдҫӣжңҚеҠЎзҡ„з«ҷзӮ№пјҢеҸӘжңүеҪ“еҮәзҺ°йҮҚеӨ§зҒҫйҡҫж—¶жүҚдјҡе°Ҷе…¶еҗҜеҠЁпјҢдҫӢеҰӮеҢ—дә¬дёҖдёӘз«ҷзӮ№пјҢеӨ©жҙҘдёҖдёӘз«ҷзӮ№пјҢдёҠжө·дёҖдёӘз«ҷзӮ№пјҢжҲ‘еёҢжңӣжӯЈеёёжғ…еҶөеҢ—дә¬еқҸдәҶпјҢеҸӘиҰҒиҪ¬з§»еҲ°еӨ©жҙҘе°ұеҘҪдәҶпјҢеҸӘжңүдёҮдёҚеҫ—е·Ізҡ„жғ…еҶөдёӢжүҚиҪ¬з§»еҲ°дёҠжө·пјҢиҝҷж—¶еҖҷжӮЁе°ұеҸҜд»Ҙжҗӯе»әдёҖдёӘеҶ·еӨҮз«ҷзӮ№пјҢж“ҚдҪңжңүдёӨз§ҚйҖүжӢ© 1.еҸ–ж¶ҲдёҠжө·з«ҷзӮ№зҡ„жҠ•зҘЁиө„ж јпјҢиҝҷж ·дёҠжө·з«ҷзӮ№е°Ҷж— жі•иҺ·еҫ—дәүеҸ–иө„ж јпјҢйҷӨйқһжӮЁеҶҚејәеҲ¶еҗҜеҠЁдёҠжө·з«ҷзӮ№пјҢ并дёәе…¶иөӢдәҲжҠ•зҘЁгҖӮ 2.и®ҫзҪ®еә”з”ЁеҸҜиғҪжүҖжңүиҖ…еҸӘжңүеҢ—дә¬е’ҢеӨ©жҙҘпјҢиҝҷж ·д№ҹеҸҜд»Ҙе®һзҺ°зұ»дјјзҡ„ж•ҲжһңпјҢдҪҶжҳҜеҰӮжһңзҫӨйӣҶеә”з”Ёе°‘иҝҳеҸҜд»ҘпјҢзҫӨйӣҶеә”з”ЁиҝҮеӨҡпјҢеҲ°ж—¶ж“ҚдҪңиө·жқҘдјҡжңүжүҖйә»зғҰпјҢйңҖиҰҒдёҖдёӘдёҖдёӘж”№гҖӮ
4.жҳҜеҗҰиҰҒдјҳе…Ҳжң¬ең°з«ҷзӮ№иҪ¬з§»
еҪ“зҒҫйҡҫеҸ‘з”ҹж—¶пјҢеҰӮжһңжңӘж»Ўи¶ідёҖе®ҡйҳҖеҖјпјҢжҲ‘们其е®һжІЎеҝ…иҰҒеҗҜеҠЁж•°жҚ®дёӯеҝғзә§еҲ«зҡ„зҒҫйҡҫжҒўеӨҚзҡ„и®ЎеҲ’пјҢеҸҜд»ҘеңЁж•°жҚ®дёӯеҝғеҶ…йғЁдё»жңәзә§еҲ«е®һзҺ°зҒҫйҡҫжҒўеӨҚпјҢиҝҷж—¶еҸҜд»Ҙй…ҚзҪ®еә”з”ЁйҰ–йҖүжүҖжңүиҖ…дёәжң¬ең°пјҢжң¬ең°жІЎеҠһжі•иҪ¬з§»еҶҚиҪ¬з§»иҮіи·Ёз«ҷзӮ№пјҢжҲ–еҰӮжһңдҪҝз”ЁWSFC 2016еҸҜд»ҘеҲ©з”Ёеә”з”Ёз«ҷзӮ№ж„ҹзҹҘеҠҹиғҪпјҢе®һзҺ°еә”з”ЁеӨҡдё»з«ҷзӮ№иҝҗдҪңгҖӮ
жҲ–иҖ…иҜҙж•°жҚ®дёӯеҝғеҶ…йғЁпјҢй’ҲеҜ№дәҺйҮҚиҰҒеә”з”ЁпјҢжһ¶и®ҫеҮ еҸ°еҶ·еӨҮжңәпјҢе№іж—¶е…іжңәпјҢеә”жҖҘж—¶еҖҷејҖжңәдҪҝз”ЁпјҢејәеҲ¶еҗҜеҠЁпјҢиөӢдәҲжҠ•зҘЁпјҢеҠ е…ҘзҫӨйӣҶпјҢдҪҶеүҚжҸҗжҳҜи§ҒиҜҒзЈҒзӣҳеӯҳжҙ»пјҢеҶ·еӨҮжңәеҸҜд»ҘиҺ·еҫ—жңҖж–°зҫӨйӣҶй…ҚзҪ®ж•°жҚ®еә“гҖӮ
5.и„‘иЈӮжҲ–е°‘ж•°з«ҷзӮ№жғ…еҶөеҰӮдҪ•еӨ„зҗҶзҡ„ж“ҚдҪң规иҢғ
еңЁ2008R2ж—¶д»ЈпјҢеҰӮжһңжҲ‘们йғЁзҪІеӨҡз«ҷзӮ№жһ¶жһ„пјҢеҫҲе®№жҳ“зў°и§ҒзҪ‘з»ңй—®йўҳиҖҢеҜјиҮҙзҫӨйӣҶеҮәзҺ°и„‘иЈӮпјҢ2012ејҖе§ӢпјҢеҫ®иҪҜж–°еўһеҠЁжҖҒд»ІиЈҒеҠҹиғҪпјҢеңЁеҠЁжҖҒд»ІиЈҒжғ…еҶөдёӢпјҢжҲ‘们еҫҲе°‘еҸҜд»ҘзңӢи§Ғи„‘иЈӮзҡ„жғ…еҶөпјҢдёҖиҲ¬еҰӮжһңеҮәзҺ°и„‘иЈӮжғ…еҶөпјҢжҲ‘们дјҡж №жҚ®дёҡеҠЎйңҖиҰҒпјҢйҖүжӢ©жңҖеҗҲйҖӮзҡ„дёҖдёӘз«ҷзӮ№пјҢејәеҲ¶еҗҜеҠЁе®ғпјҢе…¶е®ғз«ҷзӮ№зЁҚеҗҺеҗҜеҠЁж—¶йңҖиҰҒз»ҸиҝҮйҳ»жӯўеҗҜеҠЁпјҢд»Ҙе’ҢејәеҲ¶еҗҜеҠЁз«ҷзӮ№еҗҢжӯҘжңҖж–°зҫӨйӣҶж•°жҚ®еә“пјҢеӣ жӯӨпјҢеӨҡз«ҷзӮ№жһ¶жһ„йңҖиҰҒиҖғиҷ‘и„‘иЈӮжғ…еҶөдёӢпјҢеҰӮдҪ•иҜ„е®ҡйӮЈж–№дёәжқғеЁҒз«ҷзӮ№пјҢеә”иҜҘеҰӮдҪ•ж“ҚдҪңеҗҜеҠЁжқғеЁҒз«ҷзӮ№гҖӮ
WSFC 2012ж—¶Г—Г—Г—е§ӢжҺЁеҮәеҠЁжҖҒд»ІиЈҒеҠҹиғҪпјҢеҚіжҳҜиҜҙеҪ“зҫӨйӣҶдёәеҒ¶ж•°иҠӮзӮ№пјҢжІЎжңүи§ҒиҜҒзҡ„жғ…еҶөдёӢпјҢзҫӨйӣҶдјҡе§Ӣз»ҲиҮӘеҠЁеҺ»жҺүдёҖдёӘиҠӮзӮ№зҡ„жҠ•зҘЁпјҢз»ҙжҢҒзҫӨйӣҶжңӘеҘҮж•°жҠ•зҘЁпјҢеҪ“еҸ‘з”ҹзҪ‘з»ңеҲҶеҢәж—¶пјҢиў«еҺ»жҺүиҠӮзӮ№жҠ•зҘЁзҡ„з«ҷзӮ№пјҢе°ҶдјҡдёӢйҷҚпјҢжІЎжңүиў«еҺ»жҺүиҠӮзӮ№жҠ•зҘЁзҡ„з«ҷзӮ№з»§з»ӯжҸҗдҫӣжңҚеҠЎпјҢжҲ‘们еҸҜд»ҘйҖҡиҝҮ2012ж—¶д»Јзҡ„LowerQuorumPriorityNodeIDпјҢжҲ–иҖ…2016ж—¶д»Јзҡ„PreferredSiteеҠҹиғҪжқҘжҢҮе®ҡпјҢи®©зҫӨйӣҶе§Ӣз»ҲеҺ»жҺүжҹҗдёӘиҠӮзӮ№зҡ„жҠ•зҘЁпјҢжңҖз»ҲиҫҫжҲҗжҺ§еҲ¶з«ҷзӮ№еҗҜеҠЁзҡ„ж•ҲжһңпјҢеңЁеӨҡз«ҷзӮ№WSFCжһ¶жһ„д№ҹеҸҜд»ҘиҖғиҷ‘иҜҘеҠҹиғҪзҡ„дҪҝз”ЁпјҢеҰӮжһңжңүеӨҡдёӘз«ҷзӮ№пјҢ50 50иҠӮзӮ№ж•°жғ…еҶөдёӢеёҢжңӣжҹҗдёӘз«ҷзӮ№е§Ӣз»ҲдёҚиҰҒиҺ·иғңгҖӮ
иҝҳжңүдёҖз§Қжғ…еҶөеҚіпјҢе°‘ж•°иҠӮзӮ№ж•°з«ҷзӮ№пјҢеҪ“еҸ‘з”ҹзҒҫйҡҫжҒўеӨҚж—¶пјҢеҸҜиғҪдјҡжңүеҘҪеҮ дёӘз«ҷзӮ№пјҢжңүзҡ„з«ҷзӮ№жңүеӨҡж•°иҠӮзӮ№пјҢжңүзҡ„з«ҷзӮ№жңүе°‘ж•°иҠӮзӮ№пјҢжӯЈеёёжғ…еҶөдёӢеә”иҜҘжҳҜеӨҡж•°иҠӮзӮ№зҡ„з«ҷзӮ№иҺ·иғңпјҢдҪҶжҳҜжҲ‘们зҹҘйҒ“е°‘ж•°иҠӮзӮ№зҡ„з«ҷзӮ№жүҚжҳҜжҲ‘们жңҖеёҢжңӣжҸҗдҫӣжңҚеҠЎзҡ„з«ҷзӮ№пјҢжүҖд»ҘжҲ‘们еҸҜд»Ҙйҳ»жӯўеӨҡж•°иҠӮзӮ№еҗҜеҠЁпјҢејәеҲ¶еҗҜеҠЁе°‘ж•°иҠӮзӮ№гҖӮиҝҷйЎ№еҠҹиғҪйңҖиҰҒдәӢе…Ҳ规еҲ’еҘҪпјҢзҒҫйҡҫжҒўеӨҚеҗҺеә”з”Ёеә”иҜҘйҰ–е…ҲеңЁйӮЈдәӣз«ҷзӮ№еҗҜеҠЁпјҢеҰӮжһңеҸ‘з”ҹж„ҸеӨ–жғ…еҶөпјҢзҗҶжғіз«ҷзӮ№жҳҜе°‘ж•°иҠӮзӮ№пјҢжҲ‘еә”иҜҘеҰӮдҪ•ж“ҚдҪңгҖӮ
еӯҳеӮЁ
еҜ№дәҺеӨҡз«ҷзӮ№зҫӨйӣҶиҖҢиЁҖе…ұдә«еӯҳеӮЁж”ҫеңЁйӮЈйҮҢжҳҜдёӘй—®йўҳпјҢеӣ дёәжҲ‘们йңҖиҰҒзЎ®дҝқзҫӨйӣҶеңЁзҒҫйҡҫеҸ‘з”ҹж—¶еҸҜд»Ҙе®Ңж•ҙзҡ„еңЁеҸҰеӨ–дёҖдёӘз«ҷзӮ№еҗҜеҠЁиө·жқҘ
еҰӮжһңзҫӨйӣҶзҡ„е…ұдә«еӯҳеӮЁж”ҫеңЁдёӨз«Ҝд»»дҪ•дёҖдёӘж•°жҚ®дёӯеҝғпјҢеҪ“иҝҷдёӘж•°жҚ®дёӯеҝғеҮәзҺ°зҒҫйҡҫж—¶пјҢеҸҰеӨ–дёҖдёӘз«ҷзӮ№д№ҹжІЎеҠһ法继з»ӯжҸҗдҫӣжңҚеҠЎпјҢеӣ дёәиҒ”зі»дёҚеҲ°е…ұдә«еӯҳеӮЁ
еӣ жӯӨпјҢиҰҒжһ¶и®ҫеӨҡз«ҷзӮ№зҫӨйӣҶпјҢжҲ‘们иҝҳйңҖиҰҒиҖғиҷ‘еҲ°е…ұдә«еӯҳеӮЁж”ҫзҪ®й—®йўҳ
йҖҡеёёжғ…еҶөдёӢпјҢеӨҡз«ҷзӮ№зҡ„зҒҫеӨҮжҒўеӨҚпјҢдәә们дјҡеҜ№еӯҳеӮЁе®һзҺ°еӨҚеҲ¶жңәеҲ¶
еҹәдәҺи®ҫеӨҮзә§еҲ«еӯҳеӮЁеӨҚеҲ¶пјҡзӣҙжҺҘйҖүжӢ©ж”ҜжҢҒеӯҳеӮЁеӨҚеҲ¶зҡ„йҳөеҲ—пјҢеҪ“еӯҳеӮЁдәӨд»ҳз»ҷзҫӨйӣҶиҠӮзӮ№ж—¶еҖҷе°ұжҳҜиў«еӨҚеҲ¶зҡ„пјҢи®ҫеӨҮдјҡеҹәдәҺеӯҳеӮЁеқ—зә§еҲ«иҝӣиЎҢеӨҚеҲ¶пјҢеҰӮжһңеңЁеӨҡз«ҷзӮ№е®һзҺ°иҝҷз§Қи®ҫеӨҮзә§еҲ«еӨҚеҲ¶пјҢжңҖеҘҪиҰҒжңүдё“й—Ёзәҝи·ҜпјҢеӣ жӯӨдјҡиҠұиҙ№дёҖ笔дёҚе°‘зҡ„иҙ№з”Ё
еҹәдәҺдё»жңәиҪҜ件зә§еҲ«еӯҳеӮЁеӨҚеҲ¶пјҡеҸҜд»ҘдҪҝз”Ёзұ»дјјдәҺиөӣй—Ёй“Ғе…ӢпјҢSteelEye DataKeeper Cluster EditionпјҢжҲ–Windows Server 2016еҺҹз”ҹиҮӘеёҰзҡ„еӯҳеӮЁеӨҚеҲ¶пјҢиҝҷзұ»иҪҜ件дјҡжҠҠеӨҡдёӘиҠӮзӮ№ж“ҚдҪңзі»з»ҹдёҠйқўзҡ„еӯҳеӮЁжһ„е»әжҲҗдёҖдёӘйҖ»иҫ‘пјҢз»ҸиҝҮеӨҚеҲ¶зҡ„зЈҒзӣҳпјҢдәӨд»ҳз»ҷзҫӨйӣҶзЈҒзӣҳиҜҶеҲ«пјҢзҺ°еңЁи¶ҠжқҘи¶ҠеӨҡдәәејҖе§ӢдҪҝз”Ёиҝҷз§Қж–№жЎҲе®һзҺ°и·Ёз«ҷзӮ№еӯҳеӮЁзҡ„еӨҚеҲ¶
еҹәдәҺеә”з”Ёзә§еҲ«еӯҳеӮЁеӨҚеҲ¶пјҡзӣҙжҺҘдҪҝз”Ёзұ»дјјдәҺexchange dagпјҢSQL agзӯүпјҢеә”з”ЁеҸҜд»Ҙе…·еӨҮеӯҳеӮЁеӨҚеҲ¶жҠҖжңҜ
йҷӨдәҶйҖүжӢ©еҗҲйҖӮзҡ„еӯҳеӮЁеӨҚеҲ¶жңәеҲ¶пјҢзЎ®дҝқеӯҳеӮЁжҢҒз»ӯеҸҜз”ЁеӨ–пјҢжҲ‘们иҝҳйңҖиҰҒйҖүжӢ©еӯҳеӮЁеӨҚеҲ¶зҡ„ж–№жі•
дҪҝз”ЁеҗҢжӯҘеӨҚеҲ¶жҲ–ејӮжӯҘеӨҚеҲ¶
дҪҝз”ЁеҗҢжӯҘеӨҚеҲ¶пјҢдёҚдјҡдёўеӨұж•°жҚ®пјҢжҜҸж¬ЎеҶҷе…ҘиҰҒжұӮдјҡзЎ®дҝқеҗҢж—¶еҶҷе…ҘдёӨдёӘз«ҷзӮ№еӯҳеӮЁпјҢжүҚдјҡе®ҢжҲҗпјҢе®№жҳ“еёҰжқҘеә”用延иҝҹпјҢеҜ№зҪ‘з»ңжҖ§иғҪиҰҒжұӮй«ҳгҖӮ
дҪҝз”ЁејӮжӯҘеӨҚеҲ¶пјҢжңүеҸҜиғҪдјҡдёўеӨұж•°жҚ®пјҢжҜҸж¬ЎеҶҷе…ҘиҜ·жұӮеҸӘеҶҷе…ҘеҲ°жүҖеңЁз«ҷзӮ№еҚіз»“жқҹпјҢзЁҚеҗҺеҶҚеӨҚеҲ¶еҲ°е…¶е®ғз«ҷзӮ№пјҢиҝҷж ·еә”з”ЁдёҚдјҡж„ҹи§үеҲ°е»¶иҝҹпјҢеӨҚеҲ¶зЁҚеҗҺдјҡеңЁеҗҺеҸ°дёҖзӮ№дёҖзӮ№иҝӣиЎҢпјҢеҜ№зҪ‘з»ңжҖ§иғҪиҰҒжұӮдёҚй«ҳпјҢдҪҶеҸҜиғҪиҝҳжІЎеӨҚеҲ¶иҝҮеҺ»ж—¶еҸ‘з”ҹзҒҫйҡҫпјҢиҖҢеҜјиҮҙж•°жҚ®дёўеӨұгҖӮ
еңЁе®һйҷ…зҺҜеўғдёӯпјҢиҖҒзҺӢзңӢеҲ°еӨ§йғЁеҲҶдјҒдёҡиҝҳжҳҜеңЁдҪҝз”ЁеҗҢжӯҘеӨҚеҲ¶пјҢд»ҘзЎ®дҝқж•°жҚ®зҡ„е®Ңж•ҙжҖ§
еҫҲеӨҡдәәдјҡиҖғиҷ‘еҲ°DFSеӨҚеҲ¶пјҢе®һйҷ…дёҠпјҢеҫ®иҪҜзҡ„DFSеӨҚеҲ¶зҡ„йҖӮз”ЁеңәжҷҜжҳҜдҝЎжҒҜе·ҘдҪңз»„пјҢз”ЁдәҺеӯҳж”ҫи§Ҷйў‘пјҢж–Ү件пјҢеӣҫзүҮпјҢзӯүиө„ж–ҷпјҢеҜ№дәҺзҫӨйӣҶпјҢжҲ–иҖ…VMMзҡ„еә“пјҢDFSеҲҷ并дёҚйҖӮеҗҲпјҢеӣ дёәDFSеҸӘдјҡеӨҚеҲ¶е…ій—ӯеҗҺзҡ„ж•°жҚ®пјҢеҰӮжһңжҲ‘们зҡ„зҫӨйӣҶйҮҢйқўжңүиҷҡжӢҹжңәпјҢж•°жҚ®еә“пјҢиҝҷдәӣдёҚдјҡе…ій—ӯзҡ„ж–Ү件пјҢDFSжҳҜдёҚдјҡеӨҚеҲ¶зҡ„
д»ҘдёҠиҖҒзҺӢд»ҺзҪ‘з»ңпјҢд»ІиЈҒпјҢи§ҒиҜҒзҡ„и§’еәҰпјҢжқҘдёәеӨ§е®¶и®Іи§ЈдәҶдёӢWSFCеӨҡз«ҷзӮ№йңҖиҰҒиҖғиҷ‘зҡ„зӮ№пјҢеёҢжңӣеҸҜд»Ҙдёәж„ҹе…ҙи¶Јзҡ„жңӢеҸӢеёҰжқҘ收иҺ·
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ