您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
上回书讲完了部署,部署完成之后,就开始了无休止的调优,对于Ceph运维人员来说最头痛的莫过于两件事:一、Ceph调优;二、Ceph运维。调优是件非常头疼的事情,下面来看看运维小哥是如何调优的,运维小哥根据网上资料进行了一个调优方法论(调优总结)。
通过对网上公开资料的分析进行总结,对Ceph的优化离不开以下几点:
硬件层面· 硬件规划· SSD选择· BIOS设置操作系统层面· Linux Kernel· 内存· Cgroup网络层面· 巨型帧· 中断亲和· 硬件加速Ceph层面· Ceph Configurations· PG Number调整ceph-osd进程在运行过程中会消耗CPU资源,所以一般会为每一个ceph-osd进程绑定一个CPU核上。当然如果你使用EC方式,可能需要更多的CPU资源。
ceph-mon进程并不十分消耗CPU资源,所以不必为ceph-mon进程预留过多的CPU资源。
ceph-msd也是非常消耗CPU资源的,所以需要提供更多的CPU资源。
· 内存
ceph-mon和ceph-mds需要2G内存,每个ceph-osd进程需要1G内存,当然2G更好。
· 网络规划
万兆网络现在基本上是跑Ceph必备的,网络规划上,也尽量考虑分离cilent和cluster网络。
2、SSD选择硬件的选择也直接决定了Ceph集群的性能,从成本考虑,一般选择SATA SSD作为Journal,Intel SSD DC S3500 Series(http://www.intel.com/content/www/us/en/solid-state-drives/solid-state-drives-dc-s3500-series.html)基本是目前看到的方案中的首选。400G的规格4K随机写可以达到11000 IOPS。如果在预算足够的情况下,推荐使用PCIE SSD,性能会得到进一步提升,但是由于Journal在向数据盘写入数据时Block后续请求,所以Journal的加入并未呈现出想象中的性能提升,但是的确会对Latency有很大的改善。
如何确定你的SSD是否适合作为SSD Journal,可以参考SéBASTIEN HAN的Ceph: How to Test if Your SSD Is Suitable as a Journal Device?(http://www.sebastien-han.fr/blog/2014/10/10/ceph-how-to-test-if-your-ssd-is-suitable-as-a-journal-device/),这里面他也列出了常见的SSD的测试结果,从结果来看SATA SSD中,Intel S3500性能表现最好。
3、BIOS设置(1)Hyper-Threading(HT)
使用超线程(Hyper-Threading)技术,可以实现在一个CPU物理核心上提供两个逻辑线程并行处理任务,在拥有12个物理核心的E5 2620 v3中,配合超线程,可以达到24个逻辑线程。更多的逻辑线程可以让操作系统更好地利用CPU,让CPU尽可能处于工作状态。基本做云平台的,VT和HT打开都是必须的,超线程技术(HT)就是利用特殊的硬件指令,把两个逻辑内核模拟成两个物理芯片,让单个处理器都能使用线程级并行计算,进而兼容多线程操作系统和软件,减少了CPU的闲置时间,提高的CPU的运行效率。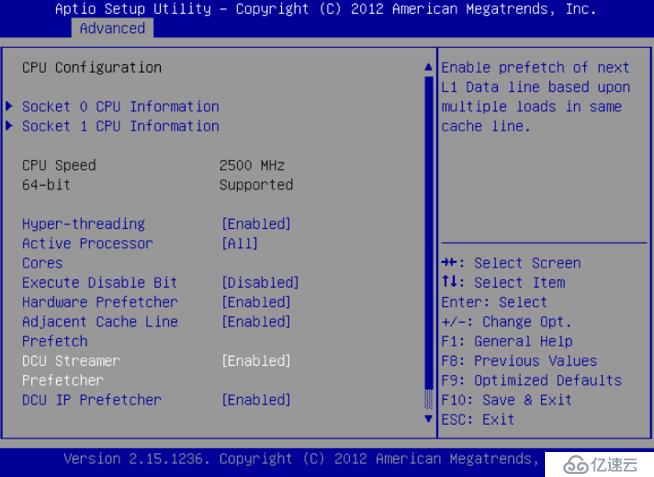
图1 打开超线程
(2)关闭节能
很多服务器出于能耗考虑,在出场时会在BIOS中打开节能模式,在节能模式下,CPU会根据机器负载动态调整频率。但是这个动态调频并不像想象中的那么美好,有时候会因此影响CPU的性能,在像Ceph这种需要高性能的应用场景下,建议关闭节能模式。关闭节能后,对性能还是有所提升的。
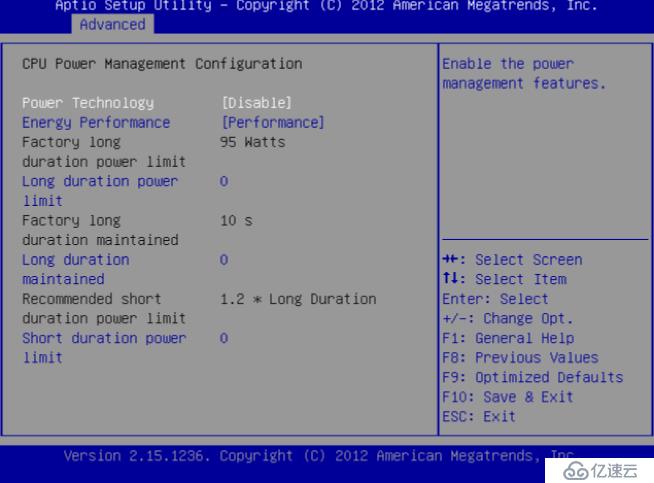
图2关闭节能
当然也可以在操作系统级别进行调整,详细的调整过程请参考链接(http://www.servernoobs.com/avoiding-cpu-speed-scaling-in-modern-linux-distributions-running-cpu-at-full-speed-tips/),但是不知道是不是由于BIOS已经调整的缘故,所以在CentOS 6.6上并没有发现相关的设置。
for CPUFREQ in /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor; do [ -f $CPUFREQ ] || continue; echo -n performance > $CPUFREQ; done
(3)NUMA
简单来说,NUMA思路就是将内存和CPU分割为多个区域,每个区域叫做NODE,然后将NODE高速互联。 node内cpu与内存访问速度快于访问其他node的内存,NUMA可能会在某些情况下影响ceph-osd(http://lists.ceph.com/pipermail/ceph-users-ceph.com/2013-December/036211.html)。解决的方案,一种是通过BIOS关闭NUMA,另外一种就是通过cgroup将ceph-osd进程与某一个CPU Core以及同一NODE下的内存进行绑定。但是第二种看起来更麻烦,所以一般部署的时候可以在系统层面关闭NUMA。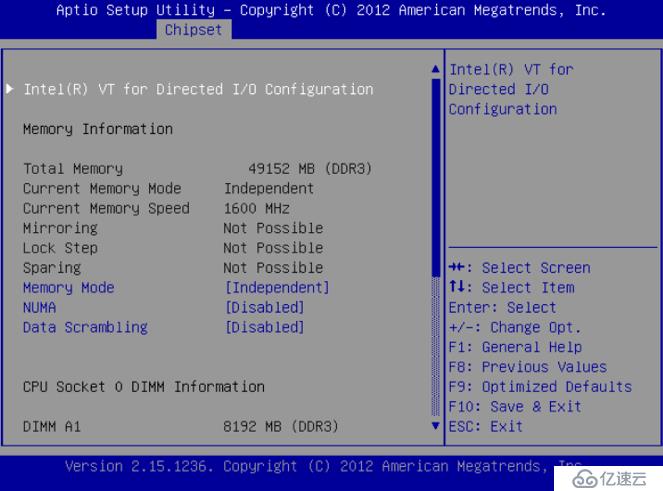
图3 关闭NUMA
CentOS系统下,通过修改/etc/grub.conf文件,添加numa=off来关闭NUMA。
kernel /vmlinuz-2.6.32-504.12.2.el6.x86_64 ro root=UUID=870d47f8-0357-4a32-909f-74173a9f0633 rd_NO_LUKS rd_NO_LVM.UTF-8 rd_NO_MD SYSFONT=latarcyrheb-sun16 crashkernel=auto KEYBOARDTYPE=pc KEYTABLE=us rd_NO_DM biosdevname=0 numa=off
Linux操作系统在服务器市场中占据了相当大的份额,各种发行版及其衍生版在不同领域中承载着各式各样的服务。针对不同的应用环境,可以对Linux的性能进行相应的调整,性能调优涵盖了虚拟内存管理、I/O子系统、进程调度系统、文件系统等众多内容,这里仅讨论对于Ceph性能影响显著的部分内容。
在Linux的各种发行版中,为了保证对硬件的兼容和可靠性,很多内核参数都采用了较为保守的设置,然而这无法满足我们对于高性能计算的需求,为了Ceph能更好地利用系统资源,我们需要对部分参数进行调整。
(1)调度
Linux默认的I/O调度一般针对磁盘寻址慢的特性做了专门优化,但对于SSD而言,由于访问磁盘不同逻辑扇区的时间几乎是一样的,这个优化就没有什么作用了,反而耗费了CPU时间。所以,使用Noop调度器替代内核默认的CFQ。操作如下:
echo noop > /sys/block/sdX/queue/scheduler而机械硬盘设置为:
echo deadline > /sys/block/sdX/queue/scheduler(2)预读
Linux默认的预读read_ahead_kb并不适合RADOS对象存储读,建议设置更大值:
echo “8192” > /sys/block/sdX/queue/read_ahead_kb(3)进程数量
OSD进程需要消耗大量进程。关于内核PID上限,如果单服务器OSD数量多的情况下,建议设置更大值:
echo 4194303 > /proc/sys/kernel/pid_max调整CPU频率,使其运行在最高性能下:
echo performance | tee /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor >/dev/null2、内存(1)SMP和NUMA
SMP(Symmetric Multi Processor)架构中,所有的CPU共享全部资源,如总线、内存和I/O等。多个CPU之间对称工作,无主从或从属关系。每个CPU都需要通过总线访问内存,整个系统中的内存能被每个CPU平等(消耗时间相同)的访问。然而,在CPU数量不断增加后,总线的压力不断增加,最终导致CPU的处理能力大大降低。
NUMA架构体系中由多个节点组成,每个节点有若干CPU和它们独立的本地内存组成,各个节点通过互联模块(CrossbarSwitch)进行访问,所以每个CPU可以访问整个系统的内存。但是,访问本地内存的速度远比访问远程内存要快,导致在进程发生调度后可能需要访问远端内存,这种情况下程序的效率会大大降低。
Ceph目前并未对NUMA架构的内存做过多优化,在日常使用过程中,我们通常使用2~4颗CPU,这种情况下,选择SMP架构的内存在效率上还是要高一些。如果条件允许,可以通过进程绑定的方法,在保证CPU能尽可能访问自身内存的前提下,使用NUMA架构。
(2)SWAP
当系统中的物理内存不足时,就需要将一部分内存非活跃(inactive)内存页置换到交换分区(SWAP)中。有时候我们会发现,在物理内存还有剩余的情况下,交换分区就已经开始被使用了,这就涉及到kernel中关于交换分区的使用策略,由vm.swappiness这个内核参数控制,该参数代表使用交换分区的程度:当值为0时,表示进可能地避免换页操作;当值为100时,表示kernel会积极的换页,这会产生大量磁盘IO。因此,在内存充足的情况下,我们一般会将该参数设置为0以保证系统性能。设定Linux操作系统参数:vm.swappiness=0,配置到/etc/sysctl.conf。
(3)内存管理
Ceph默认使用TCmalloc管理内存,在非全闪存环境下,TCmalloc的性能已经足够。全闪存的环境中,建议增加TCmalloc的Cache大小或者使用jemalloc替换TCmalloc。
增加TCmalloc的Cache大小需要设置环境变量,建议设置为256MB大小:
TCMALLOC_MAX_TOTAL_THREAD_CACHE_BYTES=268435456使用jemalloc需要重新编译打包Ceph,修改编译选项:
–with-jemalloc–without-tcmalloc3、CgroupCgroups是control groups的缩写,是Linux内核提供的一种可以限制、记录、隔离进程组(process groups)所使用的物理资源(如CPU、Memory、IO等)的机制。最初由Google的工程师提出,后来被整合进Linux内核。Cgroups也是LXC为实现虚拟化所使用的资源管理手段,可以说没有Cgroups就没有LXC。Cgroups内容非常丰富,展开讨论完全可以单独写一篇,这里我们简单说下Cgroups在Ceph中的应用。
说到Cgroups,就不得不说下CPU的架构,以E5-2620 v3为例(见图4):整颗CPU共享L3缓存,每个物理核心有独立的L1和L2缓存,如果开启超线程后两个逻辑CPU会共享同一块L1和L2,所以,在使用Cgroups的时候,我们需要考虑CPU的缓存命中问题。

图4 E5 2620 v3 CPU拓扑图
查看CPU的拓扑,可以通过hwloc工具(http://www.open-mpi.org/projects/hwloc/)来辨别CPU号码与真实物理核心的对应关系。例如在配置2个Intel(R) Xeon(R) CPU E5-2680 v2的服务器,CPU拓扑:
Machine (64GB) NUMANode L#0 (P#0 32GB) Socket L#0 + L3 L#0 (25MB) L2 L#0 (256KB) + L1d L#0 (32KB) + L1i L#0 (32KB) + Core L#0 PU L#0 (P#0) PU L#1 (P#20) L2 L#1 (256KB) + L1d L#1 (32KB) + L1i L#1 (32KB) + Core L#1 PU L#2 (P#1) PU L#3 (P#21)L2 L#2 (256KB) + L1d L#2 (32KB) + L1i L#2 (32KB) + Core L#2
PU L#4 (P#2)
PU L#5 (P#22)
L2 L#3 (256KB) + L1d L#3 (32KB) + L1i L#3 (32KB) + Core L#3
PU L#6 (P#3)
PU L#7 (P#23)
L2 L#4 (256KB) + L1d L#4 (32KB) + L1i L#4 (32KB) + Core L#4
PU L#8 (P#4)
PU L#9 (P#24)
L2 L#5 (256KB) + L1d L#5 (32KB) + L1i L#5 (32KB) + Core L#5
PU L#10 (P#5)
PU L#11 (P#25)
L2 L#6 (256KB) + L1d L#6 (32KB) + L1i L#6 (32KB) + Core L#6
PU L#12 (P#6)
PU L#13 (P#26)
L2 L#7 (256KB) + L1d L#7 (32KB) + L1i L#7 (32KB) + Core L#7
PU L#14 (P#7)
PU L#15 (P#27)
L2 L#8 (256KB) + L1d L#8 (32KB) + L1i L#8 (32KB) + Core L#8
PU L#16 (P#8)
PU L#17 (P#28)
L2 L#9 (256KB) + L1d L#9 (32KB) + L1i L#9 (32KB) + Core L#9
PU L#18 (P#9)
PU L#19 (P#29)
HostBridge L#0
PCIBridge
PCIBridge
PCIBridge
PCI 8086:1d6a
PCIBridge
PCI 8086:1521
Net L#0 “eno1”
PCI 8086:1521
Net L#1 “eno2”
PCI 8086:1521
Net L#2 “eno3”
PCI 8086:1521
Net L#3 “eno4”
PCIBridge
PCI 1000:0079
Block L#4 “sda”
Block L#5 “sdb”
Block L#6 “sdc”
Block L#7 “sdd”
Block L#8 “sde”
PCIBridge
PCI 102b:0522
GPU L#9 “card0”
GPU L#10 “controlD64”
PCI 8086:1d02
Block L#11 “sr0”
NUMANode L#1 (P#1 32GB)
Socket L#1 + L3 L#1 (25MB)
L2 L#10 (256KB) + L1d L#10 (32KB) + L1i L#10 (32KB) + Core L#10
PU L#20 (P#10)
PU L#21 (P#30)
L2 L#11 (256KB) + L1d L#11 (32KB) + L1i L#11 (32KB) + Core L#11
PU L#22 (P#11)
PU L#23 (P#31)
L2 L#12 (256KB) + L1d L#12 (32KB) + L1i L#12 (32KB) + Core L#12
PU L#24 (P#12)
PU L#25 (P#32)
L2 L#13 (256KB) + L1d L#13 (32KB) + L1i L#13 (32KB) + Core L#13
PU L#26 (P#13)
PU L#27 (P#33)
L2 L#14 (256KB) + L1d L#14 (32KB) + L1i L#14 (32KB) + Core L#14
PU L#28 (P#14)
PU L#29 (P#34)
L2 L#15 (256KB) + L1d L#15 (32KB) + L1i L#15 (32KB) + Core L#15
PU L#30 (P#15)
PU L#31 (P#35)
L2 L#16 (256KB) + L1d L#16 (32KB) + L1i L#16 (32KB) + Core L#16
PU L#32 (P#16)
PU L#33 (P#36)
L2 L#17 (256KB) + L1d L#17 (32KB) + L1i L#17 (32KB) + Core L#17
PU L#34 (P#17)
PU L#35 (P#37)
L2 L#18 (256KB) + L1d L#18 (32KB) + L1i L#18 (32KB) + Core L#18
PU L#36 (P#18)
PU L#37 (P#38)
L2 L#19 (256KB) + L1d L#19 (32KB) + L1i L#19 (32KB) + Core L#19
PU L#38 (P#19)
PU L#39 (P#39)
HostBridge L#7
PCIBridge
PCI 8086:10fb
Net L#12 “enp129s0f0”
PCI 8086:10fb
Net L#13 “enp129s0f1”
由此可见,操作系统识别的CPU号和物理核心是一一对应的关系,在对程序做CPU绑定或者使用Cgroups进行隔离时,注意不要跨CPU,以便更好地命中内存和缓存。另外也看到,不同HostBridge的对应PCI插槽位置不一样,管理着不同的资源,CPU中断设置时候也需要考虑这个因素。
总结一下,使用Cgroups的过程中,我们应当注意以下问题:
· 防止进程跨CPU核心迁移,以更好的利用缓存;
· 防止进程跨物理CPU迁移,以更好的利用内存和缓存;
· Ceph进程和其他进程会互相抢占资源,使用Cgroups做好隔离措施;
· 为Ceph进程预留足够多的CPU和内存资源,防止影响性能或产生OOM。尤其是高性能环境中并不能完全满足Ceph进程的开销,在高性能场景(全SSD)下,每个OSD进程可能需要高达6GHz的CPU和4GB以上的内存。
因为优化部分涉及内容较多,所以分为两篇文章来讲述,希望本文能够给予Ceph新手参考,请读者见仁见智,预知后事如何,请期待《部署调优关卡之调优二》。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。