жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
д»ҠеӨ©е°Ҹзј–з»ҷеӨ§е®¶еҲҶдә«дёҖдёӢPandasеә“жҳҜд»Җд№ҲеҸҠжҖҺд№ҲдҪҝз”Ёзҡ„зӣёе…ізҹҘиҜҶзӮ№пјҢеҶ…е®№иҜҰз»ҶпјҢйҖ»иҫ‘жё…жҷ°пјҢзӣёдҝЎеӨ§йғЁеҲҶдәәйғҪиҝҳеӨӘдәҶи§Јиҝҷж–№йқўзҡ„зҹҘиҜҶпјҢжүҖд»ҘеҲҶдә«иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶еҸӮиҖғдёҖдёӢпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺжңүжүҖ收иҺ·пјҢдёӢйқўжҲ‘们дёҖиө·жқҘдәҶи§ЈдёҖдёӢеҗ§гҖӮ
pandas жҳҜеҹәдәҺNumPy зҡ„дёҖз§Қе·Ҙе…·пјҢиҜҘе·Ҙе…·жҳҜдёәи§ЈеҶіж•°жҚ®еҲҶжһҗд»»еҠЎиҖҢеҲӣе»әзҡ„гҖӮPandas зәіе…ҘдәҶеӨ§йҮҸеә“е’ҢдёҖдәӣж ҮеҮҶзҡ„ж•°жҚ®жЁЎеһӢпјҢжҸҗдҫӣдәҶй«ҳж•Ҳең°ж“ҚдҪңеӨ§еһӢж•°жҚ®йӣҶжүҖйңҖзҡ„е·Ҙе…·гҖӮpandasжҸҗдҫӣдәҶеӨ§йҮҸиғҪдҪҝжҲ‘们еҝ«йҖҹдҫҝжҚ·ең°еӨ„зҗҶж•°жҚ®зҡ„еҮҪж•°е’Ңж–№жі•гҖӮдҪ еҫҲеҝ«е°ұдјҡеҸ‘зҺ°пјҢе®ғжҳҜдҪҝPythonжҲҗдёәејәеӨ§иҖҢй«ҳж•Ҳзҡ„ж•°жҚ®еҲҶжһҗзҺҜеўғзҡ„йҮҚиҰҒеӣ зҙ д№ӢдёҖгҖӮ
2008е№ҙWesMcKinneyејҖеҸ‘еҮәзҡ„еә“
дё“й—Ёз”ЁдәҺж•°жҚ®жҢ–жҺҳзҡ„ејҖжәҗpythonеә“
д»ҘNumpyдёәеҹәзЎҖпјҢеҖҹеҠӣNumpyжЁЎеқ—еңЁи®Ўз®—ж–№йқўжҖ§иғҪй«ҳзҡ„дјҳеҠҝ
еҹәдәҺmatplotlibпјҢиғҪеӨҹз®Җдҫҝзҡ„з”»еӣҫ
зӢ¬зү№зҡ„ж•°жҚ®з»“жһ„
ж•°жҚ®еӨ„зҗҶзҡ„ж—¶еҖҷз»ҸеёёжҖ§йңҖиҰҒж•ҙзҗҶеҮәиЎЁж јпјҢеңЁиҝҷйҮҢд»Ӣз»Қpandasеёёи§ҒдҪҝз”Ёпјҡ
еҸӮиҖғй“ҫжҺҘпјҡ10 minutes to pandas https://pandas.pydata.org/docs/user_guide/10min.html#min
Pandasеёёи§Ғзҡ„е°ұдёӨз§Қж•°жҚ®зұ»еһӢпјҡSeriesе’ҢDataFrameпјҢеҸҜд»ҘеҜ№еә”зҗҶи§Јдёәеҗ‘йҮҸе’Ңзҹ©йҳөпјҢеүҚиҖ…жҳҜдёҖз»ҙзҡ„пјҢеҗҺиҖ…жҳҜдәҢз»ҙзҡ„гҖӮеңЁDFдёӯзұ»дјјз»ҹи®ЎеӯҰдёӯзҡ„ж•°жҚ®з»„з»Үж–№ејҸпјҢдёҖиЎҢд»ЈиЎЁдёҖйЎ№ж•°жҚ®пјҢдёҖеҲ—д»ЈиЎЁдёҖз§Қзү№еҫҒпјҢз”Ёиҝҷз§Қж–№ејҸи®°еҝҶиғҪеӨҹеё®дҪ жӣҙеҘҪзҗҶи§ЈDFгҖӮйңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҡеңЁDFдёӯindexжҳҜиЎҢпјҢcolumnжҳҜеҲ—гҖӮ


еёёдҪҝз”Ё.csvж јејҸзҡ„ж–Ү件пјҢжҲ‘们еңЁеҜје…Ҙж•°жҚ®зҡ„ж—¶еҖҷдҪҝз”Ёpd.read_csv()пјҢеңЁеҜјеҮәж•°жҚ®зҡ„ж—¶еҖҷз”Ёdf.write_csv(вҖң/data/ymz.csvвҖқ).
# иҜ»е…Ҙж•°жҚ®
In [144]: pd.read_csv("foo.csv")
Out[144]:
Unnamed: 0 A B C D
0 2000-01-01 0.350262 0.843315 1.798556 0.782234
1 2000-01-02 -0.586873 0.034907 1.923792 -0.562651
2 2000-01-03 -1.245477 -0.963406 2.269575 -1.612566
3 2000-01-04 -0.252830 -0.498066 3.176886 -1.275581
4 2000-01-05 -1.044057 0.118042 2.768571 0.386039
.. ... ... ... ... ...
995 2002-09-22 -48.017654 31.474551 69.146374 -47.541670
996 2002-09-23 -47.207912 32.627390 68.505254 -48.828331
997 2002-09-24 -48.907133 31.990402 67.310924 -49.391051
998 2002-09-25 -50.146062 33.716770 67.717434 -49.037577
999 2002-09-26 -49.724318 33.479952 68.108014 -48.822030
[1000 rows x 5 columns]# еҶҷеҮәж•°жҚ®
In [143]: df.to_csv("foo.csv")еҜ№ж•°жҚ®ж“ҚдҪңеҢ…жӢ¬еўһпјҲеҲӣе»әпјүпјҢеҲ пјҢж”№пјҢжҹҘгҖӮ
зӣёжҜ”иҫғSeriesпјҢжҲ‘们жӣҙеёёдҪҝз”ЁDataFrameж•°жҚ®зұ»еһӢпјҢеёёдҪҝз”Ёзҡ„еҲӣе»әDataFrameзұ»еһӢжңүдёӨз§ҚпјҢдёҖз§ҚжҳҜдҪҝз”ЁdataеҲӣе»әпјҲжіЁж„Ҹdataеҫ—жҳҜдёҖдёӘдәҢз»ҙlist/arrayзӯүпјүпјҢдёҖз§ҚжҳҜдҪҝз”Ёеӯ—е…ёеҲӣе»әгҖӮ
# дҪҝз”ЁdataеҜје…Ҙ
In [5]: dates = pd.date_range("20130101", periods=6)
In [6]: dates
Out[6]:
DatetimeIndex(['2013-01-01', '2013-01-02', '2013-01-03', '2013-01-04',
'2013-01-05', '2013-01-06'],
dtype='datetime64[ns]', freq='D')
In [7]: df = pd.DataFrame(data=np.random.randn(6, 4), index=dates, columns=list("ABCD"))
In [8]: df
Out[8]:
A B C D
2013-01-01 0.469112 -0.282863 -1.509059 -1.135632
2013-01-02 1.212112 -0.173215 0.119209 -1.044236
2013-01-03 -0.861849 -2.104569 -0.494929 1.071804
2013-01-04 0.721555 -0.706771 -1.039575 0.271860
2013-01-05 -0.424972 0.567020 0.276232 -1.087401
2013-01-06 -0.673690 0.113648 -1.478427 0.524988# дҪҝз”Ёеӯ—е…ё
In [9]: df2 = pd.DataFrame(
...: {
...: "A": 1.0,
...: "B": pd.Timestamp("20130102"),
...: "C": pd.Series(1, index=list(range(4)), dtype="float32"),
...: "D": np.array([3] * 4, dtype="int32"),
...: "E": pd.Categorical(["test", "train", "test", "train"]),
...: "F": "foo",
...: }
...: )
...:
In [10]: df2
Out[10]:
A B C D E F
0 1.0 2013-01-02 1.0 3 test foo
1 1.0 2013-01-02 1.0 3 train foo
2 1.0 2013-01-02 1.0 3 test foo
3 1.0 2013-01-02 1.0 3 train foo1пјүдҪҝз”ЁlocеңЁиЎҢе°ҫеўһеҠ
еўһеҠ дёҖиЎҢж•°жҚ®зҡ„ж–№жі•жңүloc, iloc, append, concat, mergeгҖӮиҝҷйҮҢд»Ӣз»ҚдёҖдёӢlocпјҢloc[index]жҳҜеңЁдёҖиЎҢзҡ„жңҖеҗҺеўһеҠ ж•°жҚ®гҖӮдҪҶжҳҜдҪ йңҖиҰҒжіЁж„Ҹloc[index]дёӯзҡ„indexпјҢеҰӮжһңдёҺе·ІеҮәзҺ°иҝҮзҡ„indexзӣёеҗҢпјҢеҲҷдјҡиҰҶзӣ–еҺҹе…ҲindexиЎҢпјҢиӢҘдёҚзӣёеҗҢеҲҷжүҚдјҡеўһеҠ дёҖиЎҢж•°жҚ®гҖӮ
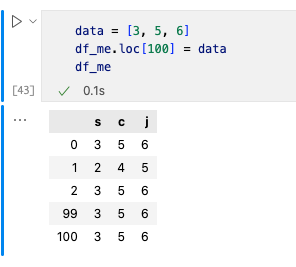
2пјүдҪҝз”Ёconcatе°ҶдёӨдёӘDFеҗҲ并
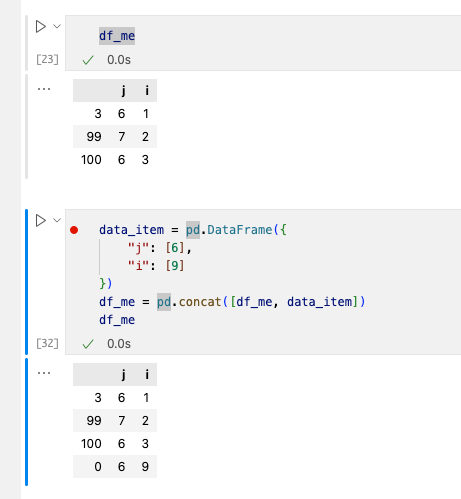
concat()д№ҹжҳҜдёҖдёӘеўһеҠ ж•°жҚ®еёёз”Ёзҡ„ж–№жі•пјҢеёёи§ҒдәҺдёӨдёӘиЎЁзҡ„жӢјжҺҘдёҺзҲ¬иҷ«дҪҝз”ЁдёӯпјҢдҪңз”Ёзұ»дјјдәҺappend()пјҢдҪҶжҳҜappend()е°ҶеңЁдёҚд№…еҗҺиў«pandasиҲҚејғпјҢжүҖд»ҘиҝҳжҳҜжҺЁиҚҗдҪҝз”Ёconcat()гҖӮ
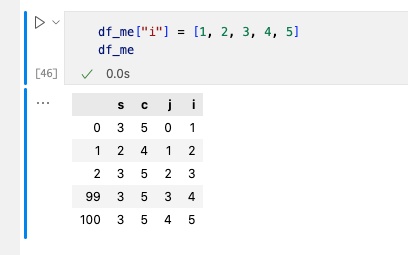
еўһеҠ дёҖеҲ—ж•°жҚ®зҡ„ж–№жі•зӣҙжҺҘз”Ё[]дҫҝеҸҜпјҢдҫӢеӯҗеҰӮдёӢпјҡ
Seriesз”Ёзҡ„жҜ”иҫғе°‘пјҢжЎҲдҫӢеҰӮдёӢпјҡ
In [3]: s = pd.Series([1, 3, 5, np.nan, 6, 8]) In [4]: s Out[4]: 0 1.0 1 3.0 2 5.0 3 NaN 4 6.0 5 8.0 dtype: float64
еҜ№дәҺеҲ йҷӨж•°жҚ®пјҢжҲ‘们дҪҝз”Ёdrop()ж–№жі•пјҢ并жҢҮе®ҡеҸӮж•°дёәindexпјҲиЎҢпјүжҲ–иҖ…columnпјҲеҲ—пјү
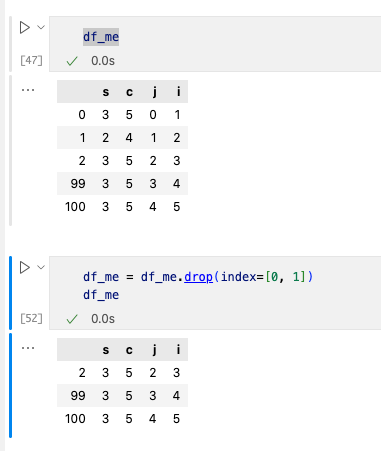
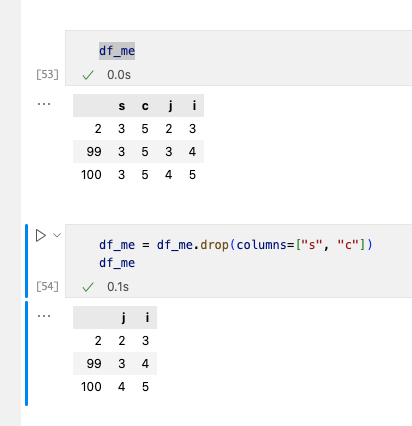
ж”№еҠЁдёҖиЎҢпјҢеҲ—ж•°жҚ®еёёз”Ёloc()е’Ң[]ж–№жі•гҖӮ
ж”№еҠЁдёҖиЎҢжҲ‘们дҪҝз”Ёloc[]=[…]иҝӣиЎҢжӣҙж”№гҖӮ
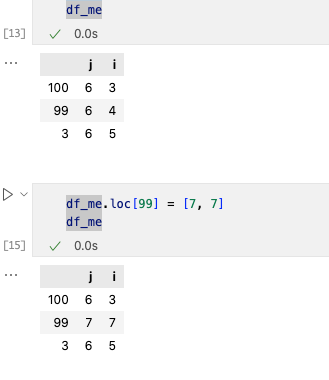
ж”№еҠЁдёҖеҲ—ж•°жҚ®жҲ‘们дҪҝз”Ё[]иҝӣиЎҢжӣҙж”№гҖӮ
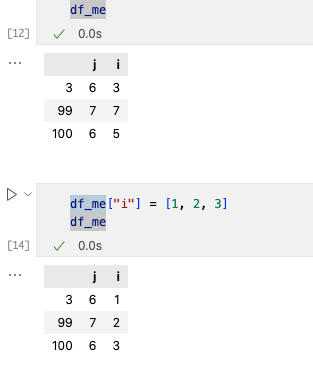
еңЁжҹҘжүҫж•°жҚ®зҡ„ж—¶еҖҷпјҢжҲ‘们常дҪҝз”Ё[]жқҘжҹҘзңӢиЎҢеҲ—ж•°жҚ®пјҢй…ҚеҗҲ.TжқҘе°Ҷзҹ©йҳөиҪ¬зҪ®гҖӮд№ҹеҸҜд»ҘдҪҝз”Ёhead()пјҢtail()жқҘжҹҘзңӢеүҚеҮ иЎҢе’ҢеҗҺеҮ иЎҢж•°жҚ®гҖӮ
дҪҝз”Ё.loc[index]жқҘжҹҘзңӢзү№е®ҡиЎҢж•°жҚ®пјҢжҲ–иҖ…[]гҖӮе»әи®®дҪҝз”Ё.loc[]ж–№жі•жҲ–иҖ….iloc[]ж–№жі•пјҢloc[]йҖҡиҝҮиЎҢзҡ„еҗҚеӯ—еҜ»жүҫпјҢiloc[]йҖҡиҝҮзҙўеј•еҜ»жүҫгҖӮ
дҪҝз”Ёзұ»дјј[0:2]жқҘжҹҘзңӢзү№е®ҡиЎҢж•°жҚ®пјҢе’ҢpythonдёӯlistдҪҝз”Ёзұ»дјјгҖӮиҝҷдёӘж–№жі•е…¶е®һжҳҜи°ғз”ЁдәҶ__getitem__()ж–№жі•гҖӮ

жҲ‘们йңҖиҰҒдҪҝз”ЁдёӨеұӮ[]еөҢеҘ—жқҘи®ҝй—®ж•°жҚ®пјҢдҫӢеҰӮ[ [вҖңjвҖқ, вҖңiвҖқ] ]гҖӮ
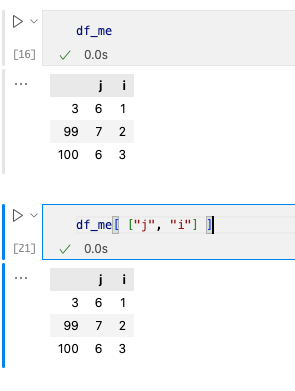
зЎ®е®ҡ第еҮ иЎҢ第еҮ еҲ—еҗҺпјҢдҪҝз”Ё.loc()ж–№жі•жҲ–иҖ….iloc()ж–№жі•жҹҘжүҫгҖӮ
b = a.loc[ 1, "dir_name" ]
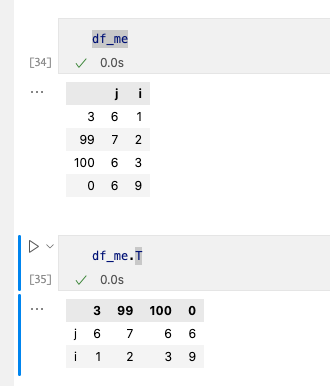
ж•°жҚ®еҲҶжһҗж—¶еёёз”Ёзҡ„дёӨдёӘж“ҚдҪңпјҢиҪ¬зҪ®е’Ңи®Ўз®—з»ҹи®ЎйҮҸгҖӮ
дҪҝз”Ё.TдҫҝеҸҜд»Ҙе®ҢжҲҗгҖӮ
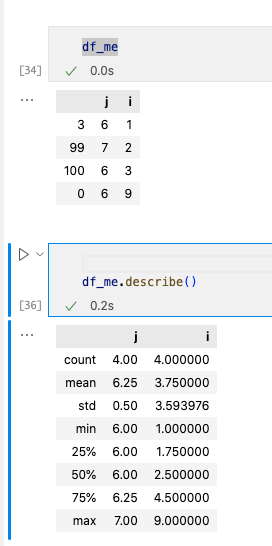
дҪҝз”Ё.describe()гҖӮ
дҪҝз”Ё.drop_duplicates()
id_df = self.frames_meta_sub[['time_idx', 'pos_idx', 'slice_idx']].drop_duplicates()
дҪҝз”Ё.to_numpy()ж–№жі•е°ҶдҪ жүҖйҖүжӢ©зҡ„ж•°жҚ®е…ЁйғЁиҪ¬жҲҗдәҢз»ҙзҡ„жҲ–иҖ…дёҖз»ҙзҡ„ndarrayпјҢйңҖиҰҒжіЁж„Ҹзҡ„жҳҜto_numpy()并дёҚд»…д»…еұҖйҷҗдәҺж•°еӯ—пјҢеӯ—з¬ҰдёІд№ҹжҳҜеҸҜд»ҘиҪ¬жҚўзҡ„пјҲиҷҪ然иҝҷж ·ејҖй”ҖжҜ”иҫғеӨ§пјүпјҢndarrayиғҪеӯҳеӮЁеӯ—з¬ҰдёІпјҢиҝҷдјҡи®©дҪ еӨ„зҗҶж•°жҚ®зҡ„иҝҮзЁӢеҸҳеҫ—ејӮеёёз®ҖеҚ•гҖӮжңүеҮ дёӘз»ҙеәҰеҸ–еҶідәҺдҪ еҸ–дәҶеҮ иЎҢжҲ–иҖ…еҮ еҲ—гҖӮ
df = df[ ["channel"] ] ar = df.to_numpy()
иҰҒеҸ–еҮә DataFrame дёӯзү№е®ҡдҪҚзҪ®зҡ„еҖјпјҢеҸҜд»ҘдҪҝз”Ё .loc жҲ– .iloc ж–№жі•пјҢе…·дҪ“еҸ–еҶідәҺжӮЁжғіиҰҒдҪҝз”Ёзҡ„зҙўеј•зұ»еһӢгҖӮ
еҰӮжһңжӮЁдҪҝз”Ёж Үзӯҫзҙўеј•пјҲдҫӢеҰӮпјҢиЎҢе’ҢеҲ—йғҪдҪҝз”Ёж ҮзӯҫеҗҚз§°пјүпјҢеҲҷеҸҜд»ҘдҪҝз”Ё .loc ж–№жі•гҖӮдҫӢеҰӮпјҢеҰӮжһңжӮЁжңүдёҖдёӘеҗҚдёә df зҡ„ DataFrameпјҢе®ғе…·жңүиЎҢж Үзӯҫдёә row_labelпјҢеҲ—ж Үзӯҫдёә column_label зҡ„е…ғзҙ пјҢеҲҷеҸҜд»ҘдҪҝз”Ёд»ҘдёӢд»Јз ҒиҺ·еҸ–иҜҘе…ғзҙ зҡ„еҖјпјҡ
value = df.loc[row_label, column_label]
еҰӮжһңжӮЁдҪҝз”Ёж•ҙж•°дҪҚзҪ®зҙўеј•пјҲдҫӢеҰӮпјҢиЎҢе’ҢеҲ—йғҪдҪҝз”Ёж•ҙж•°дҪҚзҪ®пјүпјҢеҲҷеҸҜд»ҘдҪҝз”Ё .iloc ж–№жі•гҖӮдҫӢеҰӮпјҢеҰӮжһңжӮЁжңүдёҖдёӘеҗҚдёә df зҡ„ DataFrameпјҢе®ғе…·жңү第дёҖдёӘиЎҢе’Ң第дёҖдёӘеҲ—зҡ„е…ғзҙ пјҢеҲҷеҸҜд»ҘдҪҝз”Ёд»ҘдёӢд»Јз ҒиҺ·еҸ–иҜҘе…ғзҙ зҡ„еҖјпјҡ
value = df.iloc[0, 0]
иҜ·жіЁж„ҸпјҢзҙўеј•д»Һйӣ¶ејҖе§ӢпјҢеӣ жӯӨ第дёҖдёӘиЎҢе’Ң第дёҖдёӘеҲ—зҡ„дҪҚзҪ®дёә 0гҖӮ
д»ҘдёҠе°ұжҳҜвҖңPandasеә“жҳҜд»Җд№ҲеҸҠжҖҺд№ҲдҪҝз”ЁвҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒзӣёдҝЎеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« йғҪжңүеҫҲеӨ§зҡ„收иҺ·пјҢе°Ҹзј–жҜҸеӨ©йғҪдјҡдёәеӨ§е®¶жӣҙж–°дёҚеҗҢзҡ„зҹҘиҜҶпјҢеҰӮжһңиҝҳжғіеӯҰд№ жӣҙеӨҡзҡ„зҹҘиҜҶпјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ