жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒи®Іи§ЈдәҶвҖңPythonдёӯSyncдёҺAsyncжү§иЎҢйҖҹеәҰеҝ«ж…ўе®һдҫӢеҜ№жҜ”еҲҶжһҗвҖқпјҢж–Үдёӯзҡ„и®Іи§ЈеҶ…е®№з®ҖеҚ•жё…жҷ°пјҢжҳ“дәҺеӯҰд№ дёҺзҗҶи§ЈпјҢдёӢйқўиҜ·еӨ§е®¶и·ҹзқҖе°Ҹзј–зҡ„жҖқи·Ҝж…ўж…ўж·ұе…ҘпјҢдёҖиө·жқҘз ”з©¶е’ҢеӯҰд№ вҖңPythonдёӯSyncдёҺAsyncжү§иЎҢйҖҹеәҰеҝ«ж…ўе®һдҫӢеҜ№жҜ”еҲҶжһҗвҖқеҗ§пјҒ
йҰ–е…Ҳе…Ҳд»ҺдёҖдёӘдҫӢеӯҗдәҶи§ЈдёӨз§Қи°ғз”Ёж–№жі•зҡ„е·®еҲ«, дёәдәҶиғҪжё…жҷ°зҡ„зңӢеҮә他们зҡ„иҝҗиЎҢж—¶й•ҝе·®еҲ«пјҢ йғҪ让他们йҮҚеӨҚиҝҗиЎҢ10000ж¬ЎпјҢ е…·дҪ“д»Јз ҒеҰӮдёӢпјҡ
import asyncio import time n_call = 10000 # syncзҡ„и°ғз”Ёж—¶й•ҝ def demo(n: int) -> int: return n ** n s_time = time.time() for i in range(n_call): demo(i) print(time.time() - s_time) # asyncзҡ„и°ғз”Ёж—¶й•ҝ async def sub_demo(n: int) -> int: return n ** n async def async_main() -> None: for i in range(n_call): await sub_demo(i) loop = asyncio.get_event_loop() s_time = time.time() loop.run_until_complete(async_main()) print(time.time() - s_time) # иҫ“еҮә # 5.310615682601929 # 5.614157438278198
еҸҜд»ҘзңӢеҫ—еҮәжқҘпјҢ syncзҡ„иҜӯжі•еӨ§е®¶йғҪжҳҜеҫҲзҶҹжӮүпјҢ иҖҢasyncзҡ„иҜӯжі•жҜ”иҫғдёҚдёҖж ·пјҢ еҮҪж•°йңҖиҰҒдҪҝз”Ёasync defејҖеӨҙпјҢ еҗҢж—¶и°ғз”Ёasync defеҮҪж•°йңҖиҰҒдҪҝз”ЁawaitиҜӯжі•пјҢ иҝҗиЎҢзҡ„ж—¶еҖҷйңҖиҰҒе…ҲиҺ·еҸ–зәҝзЁӢзҡ„дәӢ件еҫӘзҺҜпјҢ 然еҗҺеңЁйҖҡиҝҮдәӢ件еҫӘзҺҜжқҘиҝҗиЎҢasync_mainеҮҪж•°жқҘиҫҫеҲ°дёҖж ·зҡ„ж•ҲжһңпјҢ дҪҶжҳҜд»ҺиҝҗиЎҢз»“жһңзҡ„иҫ“еҮәеҸҜд»ҘзңӢеҫ—еҮә, syncзҡ„иҜӯжі•еңЁиҝҷдёӘеңәжҷҜдёӯжҜ”asyncзҡ„иҜӯжі•йҖҹеәҰеҝ«дәҶдёҖдәӣдәӣпјҲз”ұдәҺPythonзҡ„GILеҺҹеӣ пјҢ иҝҷйҮҢж— жі•дҪҝз”ЁеӨҡж ёзҡ„жҖ§иғҪпјҢ еҸӘиғҪд»ҘеҚ•ж ёжқҘи·‘пјүгҖӮ
йҖ жҲҗиҝҷж ·зҡ„еҺҹеӣ жҳҜеҗҢж ·з”ұеҗҢдёҖдёӘзәҝзЁӢжү§иЎҢзҡ„жғ…еҶөдёӢ(cpuеҚ•ж ёеҝғ)пјҢasyncзҡ„и°ғз”ЁиҝҳйңҖиҰҒз»ҸиҝҮдёҖдәӣдәӢ件еҫӘзҺҜзҡ„йўқеӨ–и°ғз”ЁпјҢ иҝҷдјҡдә§з”ҹдёҖдәӣе°ҸејҖй”ҖпјҢ д»ҺиҖҢиҝҗиЎҢж—¶й—ҙдјҡжҜ”syncзҡ„ж…ўпјҢ еҗҢж—¶иҝҷжҳҜдёҖдёӘзәҜcpuиҝҗз®—зҡ„зӨәдҫӢпјҢ иҖҢasyncзҡ„зҡ„дјҳеҠҝеңЁдәҺзҪ‘з»ңioиҝҗз®—пјҢ еңЁиҝҷдёӘеңәжҷҜж— жі•еҸ‘жҢҘдјҳеҠҝпјҢ дҪҶдјҡеңЁй«ҳ并еҸ‘еңәжҷҜеҲҷдјҡеӨ§ж”ҫе…үеҪ©, йҖ жҲҗиҝҷж ·зҡ„еҺҹеӣ еҲҷжҳҜеӣ дёәasyncжҳҜд»ҘеҚҸзЁӢиҝҗиЎҢзҡ„пјҢ syncжҳҜд»ҘзәҝзЁӢиҝҗиЎҢзҡ„гҖӮ
NOTE: зӣ®еүҚжүҖиҜҙзҡ„asyncиҜӯжі•йғҪжҳҜж”ҜжҢҒзҪ‘з»ңioпјҢ иҖҢж–Ү件系з»ҹзҡ„ејӮжӯҘioиҝҳдёҚжҳҜйқһеёёзҡ„е®Ңе–„пјҢ жүҖд»Ҙж–Ү件系з»ҹзҡ„ејӮжӯҘиҜ»еҶҷжҳҜйҖҡиҝҮе°ҒиЈ…дәӨз»ҷеӨҡзәҝзЁӢеҺ»еӨ„зҗҶпјҢ иҖҢдёҚжҳҜеҚҸзЁӢгҖӮ
дёәдәҶдәҶи§ЈasyncеңЁioеңәжҷҜдёӢзҡ„иҝҗиЎҢдјҳеҠҝпјҢ е…ҲеҒҮе®ҡжңүдёҖдёӘioеңәжҷҜ--WebеҗҺеҸ°жңҚеҠЎйҖҡеёёйңҖиҰҒеӨ„зҗҶи®ёеӨҡиҜ·жұӮпјҢ жүҖжңүиҜ·жұӮйғҪжҳҜд»ҺдёҚеҗҢзҡ„е®ўжҲ·з«ҜеҸ‘еҮәзҡ„пјҢ зӨәдҫӢеҰӮеӣҫпјҡ
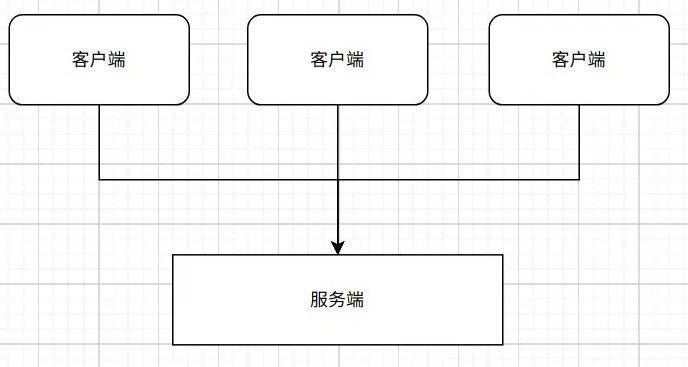
еңЁиҝҷз§ҚеңәжҷҜдёӢпјҢ е®ўжҲ·з«ҜиҜ·жұӮйғҪжҳҜеңЁзҹӯж—¶й—ҙеҶ…еҸ‘еҮәзҡ„гҖӮ иҖҢжңҚеҠЎз«ҜдёәдәҶиғҪеӨҹеңЁзҹӯж—¶й—ҙеҶ…еӨ„зҗҶеӨ§йҮҸзҡ„иҜ·жұӮпјҢ йҳІжӯўеӨ„зҗҶ延иҝҹпјҢ йғҪдјҡд»Ҙжҹҗз§Қж–№ејҸжқҘж”ҜжҢҒ并еҸ‘жҲ–иҖ…并иЎҢгҖӮ
NOTE: 并еҸ‘пјҢеңЁж“ҚдҪңзі»з»ҹдёӯпјҢжҳҜжҢҮдёҖдёӘж—¶й—ҙж®өдёӯжңүеҮ дёӘзЁӢеәҸйғҪеӨ„дәҺе·ІеҗҜеҠЁиҝҗиЎҢеҲ°иҝҗиЎҢе®ҢжҜ•д№Ӣй—ҙпјҢдё”иҝҷеҮ дёӘзЁӢеәҸйғҪжҳҜеңЁеҗҢдёҖдёӘеӨ„зҗҶжңәдёҠиҝҗиЎҢпјҢдҪҶд»»дёҖдёӘж—¶еҲ»зӮ№дёҠеҸӘжңүдёҖдёӘзЁӢеәҸеңЁеӨ„зҗҶжңәдёҠиҝҗиЎҢгҖӮ 并иЎҢжҳҜи®Ўз®—жңәзі»з»ҹдёӯиғҪеҗҢж—¶жү§иЎҢдёӨдёӘжҲ–еӨҡдёӘеӨ„зҗҶзҡ„дёҖз§Қи®Ўз®—ж–№жі•гҖӮ
еҜ№дәҺsyncиҜӯжі•жқҘиҜҙпјҢ иҝҷдёӘWebеҗҺеҸ°еҸҜд»ҘйҖҡиҝҮиҝӣзЁӢпјҢ зәҝзЁӢжҲ–иҖ…дёӨиҖ…з»“еҗҲжқҘе®һзҺ°пјҢ 他们зҡ„жҸҗдҫӣ并еҸ‘/并иЎҢзҡ„иғҪеҠӣдјҡеұҖйҷҗдәҺwokerзҡ„ж•°йҮҸпјҢ жҜ”еҰӮеҪ“жңү5дёӘе®ўжҲ·з«ҜеҗҢж—¶иҜ·жұӮиҖҢжңҚеҠЎз«ҜеҸӘжңү4дёӘworkerж—¶пјҢ жңүдёҖдёӘиҜ·жұӮдјҡиҝӣе…Ҙйҳ»еЎһзӯүеҫ…йҳ¶ж®ө, зӣҙеҲ°иҝҗиЎҢзҡ„4дёӘworkerжңүдёҖдёӘиў«еӨ„зҗҶе®ҢжҜ•гҖӮ дёәдәҶи®©жңҚеҠЎеҷЁиғҪжҸҗдҫӣжӣҙеҘҪзҡ„жңҚеҠЎпјҢ жҲ‘们йғҪдјҡжҸҗдҫӣи¶іеӨҹеӨҡзҡ„worker, еҗҢж—¶з”ұдәҺиҝӣзЁӢе…·жңүиүҜеҘҪзҡ„йҡ”зҰ»жҖ§дё”жҜ”иҫғжҜҸиө·дёҖдёӘиҝӣзЁӢйғҪдјҡеҚ з”ЁдёҖд»ҪзӢ¬з«Ӣзҡ„иө„жәҗпјҢ жүҖд»ҘйғҪжҳҜд»ҘеҮ дёӘиҝӣзЁӢ+еӨ§йҮҸзәҝзЁӢзҡ„еҪўејҸжқҘжҸҗдҫӣжңҚеҠЎгҖӮ
NOTEпјҡ иҝӣзЁӢжҳҜжңҖе°Ҹзҡ„иө„жәҗеҲҶй…ҚеҚ•дҪҚ, иҝҮеӨҡзҡ„иҝӣзЁӢдјҡеҚ з”ЁеҫҲеӨҡзі»з»ҹиө„жәҗпјҢ дёҖиҲ¬зҡ„еҗҺеҸ°жңҚеҠЎеҗҜз”Ёзҡ„иҝӣзЁӢж•°йҮҸдёҚдјҡеҫҲеӨҡпјҢ еҗҢж—¶зәҝзЁӢжҳҜжңҖе°Ҹзҡ„и°ғеәҰеҚ•дҪҚпјҢ жүҖд»Ҙд»ҘдёӢзҡ„и°ғеәҰжҲ‘йғҪд»ҘзәҝзЁӢжқҘжҸҸиҝ°гҖӮ
дҪҶжҳҜиҝҷз§Қж–№ејҸжҳҜеҫҲиҖ—зі»з»ҹзҡ„иө„жәҗзҡ„(зӣёеҜ№дәҺеҚҸзЁӢжқҘиҜҙ), еӣ дёәзәҝзЁӢзҡ„иҝҗиЎҢйғҪжҳҜйқ cpuжқҘжү§иЎҢзҡ„пјҢ иҖҢcpuжҳҜжңүйҷҗзҡ„пјҢ еҗҢдёҖж—¶еҲ»еҸӘиғҪж”ҜжҢҒеӣәе®ҡзҡ„еҮ дёӘworkerиҝҗиЎҢ, е…¶д»–зәҝзЁӢеҲҷеҫ—зӯүеҫ…иў«и°ғеәҰ, иҝҷж ·е°ұж„Ҹе‘ізқҖжҜҸдёӘзәҝзЁӢйғҪеҸӘиғҪе·ҘдҪңдёҖдёӘж—¶й—ҙеҲҶзүҮпјҢ д№ӢеҗҺе°ұдјҡиў«и°ғеәҰзі»з»ҹжҺ§еҲ¶иҝӣе…Ҙйҳ»еЎһжҲ–иҖ…е°ұз»Әйҳ¶ж®өпјҢ и®©дҪҚз»ҷе…¶д»–зәҝзЁӢпјҢ зӣҙеҲ°дёӢж¬ЎиҺ·еҸ–ж—¶й—ҙеҲҶзүҮж—¶жүҚеҸҜд»Ҙ继з»ӯиҝҗиЎҢгҖӮ дёәдәҶиғҪжЁЎжӢҹеҮәеҗҢдёҖж—¶еҲ»еҶ…пјҢ еӨҡдёӘзәҝзЁӢеҗҢж—¶иҝҗиЎҢпјҢ дё”йҳІжӯўе…¶д»–зәҝзЁӢйҘҝжӯ»зҡ„жғ…еҶөпјҢ зәҝзЁӢжҜҸж¬ЎиҺ·еҫ—зҡ„иҝҗиЎҢж—¶й—ҙеҫҲзҹӯпјҢ зәҝзЁӢй—ҙзҡ„и°ғеәҰеҲҮжҚўеҫҲйў‘з№ҒпјҢ еҪ“еҗҜз”ЁжӣҙеӨҡзҡ„иҝӣзЁӢе’ҢжӣҙеӨҡзҡ„зәҝзЁӢж—¶пјҢ и°ғеәҰе°ұдјҡжӣҙеҠ зҡ„йў‘з№ҒгҖӮ
дёҚиҝҮи°ғеәҰзәҝзЁӢзҡ„ејҖй”ҖиҝҳдёҚз®—еӨ§пјҢ жҜ”иҫғеӨ§зҡ„ејҖй”ҖжҳҜи°ғеәҰзәҝзЁӢиҖҢдә§з”ҹзҡ„дёӢж–ҮеҲҮжҚўе’Ңз«һдәүжқЎд»¶(е…·дҪ“еҸҜд»ҘеҸӮиҖғгҖҠи®Ўз®—жңәеҜји®әгҖӢдёӯиҝӣзЁӢи°ғеәҰзӣёе…ізҡ„иө„ж–ҷпјҢ жҲ‘иҝҷйҮҢеҸӘжҳҜз®ҖеҚ•иҜҙжҳҺ)пјҢ cpuеңЁжү§иЎҢд»Јз Ғж—¶пјҢе®ғйңҖиҰҒжҠҠж•°жҚ®еҠ иҪҪеҲ°cpuзҡ„зј“еӯҳдёӯеҺ»зҡ„еҶҚиҝҗиЎҢпјҢ еҪ“cpuиҝҗиЎҢзҡ„зәҝзЁӢеңЁиҝҷдёӘж—¶й—ҙеҲҶзүҮеҶ…жү§иЎҢе®ҢжҲҗж—¶пјҢ иҜҘзәҝзЁӢзҡ„жңҖж–°иҝҗиЎҢж•°жҚ®е°ұдјҡдҝқеӯҳиө·жқҘпјҢ 然еҗҺcpuдјҡеҺ»еҠ иҪҪеҮҶеӨҮиў«и°ғеәҰзҡ„зәҝзЁӢзҡ„ж•°жҚ®пјҢ 并иҝҗиЎҢгҖӮ иҷҪ然иҝҷйғЁеҲҶжҡӮеӯҳж•°жҚ®жҳҜдҝқеӯҳеңЁжҜ”еҶ…еӯҳжӣҙеҝ«пјҢ жҜ”еҶ…еӯҳжӣҙйқ иҝ‘cpuзҡ„еҜ„еӯҳеҷЁдёҠпјҢ дҪҶжҳҜеҜ„еӯҳеҷЁзҡ„и®ҝй—®йҖҹеәҰд№ҹжІЎжңүcpuзј“еӯҳзҡ„и®ҝй—®йҖҹеәҰеҝ«пјҢ жүҖд»ҘcpuеңЁеҲҮжҚўиҝҗиЎҢзҡ„зәҝзЁӢж—¶пјҢ йғҪдјҡиҠұдёҠдёҖйғЁеҲҶж—¶й—ҙз”ЁжқҘиЈ…иҪҪж•°жҚ®дёҠиҝҳжңүиЈ…иҪҪзј“еӯҳж—¶зҡ„з«һдәүй—®йўҳгҖӮ
еҜ№жҜ”зәҝзЁӢзҡ„и°ғеәҰдә§з”ҹзҡ„дёҠдёӢж–ҮеҲҮжҚўдёҺжҠўеҚ ејҸпјҢ asyncиҜӯжі•е®һзҺ°зҡ„еҚҸзЁӢжҳҜйқһжҠўеҚ ејҸзҡ„пјҢ еҚҸзЁӢзҡ„и°ғеәҰжҳҜдҫқиө–дәҺдёҖдёӘеҫӘзҺҜжқҘжҺ§еҲ¶пјҢ иҝҷдёӘеҫӘзҺҜжҳҜдёҖдёӘйқһеёёеёёй«ҳж•Ҳзҡ„д»»еҠЎз®ЎзҗҶеҷЁе’Ңи°ғеәҰеҷЁ, з”ұдәҺи°ғеәҰзҡ„жҳҜдёҖж®өд»Јз Ғзҡ„е®һзҺ°йҖ»иҫ‘пјҢ жүҖд»Ҙcpuзҡ„жү§иЎҢд»Јз Ғ并дёҚз”ЁеҲҮжҚўпјҢ д№ҹе°ұжІЎжңүдёҠдёӢж–ҮеҲҮжҚўзҡ„ејҖй”Җ, еҗҢж—¶пјҢ д№ҹдёҚз”ЁиҖғиҷ‘иЈ…иҪҪзј“еӯҳзҡ„з«һдәүй—®йўҳгҖӮ иҝҳжҳҜд»ҘдёҠйқўйӮЈдёӘеӣҫдёәдҫӢеӯҗпјҢ еңЁжңҚеҠЎејҖе§ӢеҗҜеҠЁж—¶пјҢ дјҡе…ҲеҗҜеҠЁдёҖдёӘдәӢ件еҫӘзҺҜпјҢ еҪ“收еҲ°иҜ·жұӮж—¶пјҢ е®ғдјҡеҲӣе»әдёҖдёӘд»»еҠЎжқҘеӨ„зҗҶе®ўжҲ·з«ҜеҸ‘йҖҒиҝҮжқҘзҡ„иҜ·жұӮпјҢ иҝҷдёӘд»»еҠЎдјҡд»ҺдәӢ件еҫӘзҺҜиҺ·еҸ–еҲ°дәҶжү§иЎҢжқғпјҢзӢ¬еҚ ж•ҙдёӘзәҝзЁӢиө„жәҗ并дёҖзӣҙжү§иЎҢпјҢ зӣҙеҲ°йҒҮеҲ°йңҖиҰҒзӯүеҫ…еӨ–йғЁдәӢ件пјҢ жҜ”еҰӮзӯүеҫ…ж•°жҚ®еә“иҝ”еӣһж•°жҚ®зҡ„дәӢ件пјҢ иҝҷж—¶д»»еҠЎдјҡе‘ҠиҜүдәӢ件еҫӘзҺҜиҮӘе·ұеңЁзӯүеҫ…иҝҷдёӘдәӢ件пјҢ 然еҗҺдәӨеҮәжү§иЎҢжқғпјҢ дәӢ件еҫӘзҺҜе°ұдјҡжҠҠжү§иЎҢжқғдј йҖ’з»ҷжңҖйңҖиҰҒиҝҗиЎҢзҡ„д»»еҠЎгҖӮ еҪ“еҲҡжүҚдәӨеҮәжү§иЎҢжқғзҡ„д»»еҠЎеңЁеҗҺз»ӯ收еҲ°ж•°жҚ®еә“дәӢ件е“Қеә”ж—¶пјҢ дәӢ件еҫӘзҺҜдјҡжҠҠе®ғе®үжҺ’еҲ°е°ұз»ӘеҲ—иЎЁзҡ„第дёҖдёӘ(дёҚеҗҢзҡ„дәӢ件еҫӘзҺҜе®һзҺ°еҸҜиғҪдёҚдёҖж ·)并еңЁдёӢдёҖж¬ЎеҲҮжҚўжү§иЎҢжқғж—¶пјҢ жҠҠжү§иЎҢжқғиҝ”еӣһз»ҷд»–, 让他继з»ӯжү§иЎҢпјҢ зӣҙеҲ°йҒҮеҲ°дёӢдёҖдёӘзӯүеҫ…дәӢ件гҖӮ
иҝҷз§ҚеҲҮжҚўеҚҸзЁӢзҡ„ж–№ејҸз§°дёәеҚҸдҪңејҸеӨҡд»»еҠЎеӨ„зҗҶпјҢ з”ұдәҺеҸӘдјҡеңЁеҚ•дёӘиҝӣзЁӢжҲ–иҖ…еҚ•дёӘзәҝзЁӢдёӯиҝҗиЎҢпјҢ еҲҮжҚўеҚҸзЁӢж—¶дёҠдёӢж–ҮжҳҜдёҚз”Ёж”№еҸҳзҡ„пјҢ cpuдёҚз”ЁйҮҚж–°иҜ»еҶҷзј“еӯҳпјҢ жүҖд»ҘдјҡиҠӮзңҒдёҖдәӣејҖй”ҖгҖӮ д»ҺдёҠйқўеҸҜд»ҘзңӢеҮәеҚҸдҪңејҸеҲҮжҚўжү§иЎҢжқғжҳҜеҹәдәҺеҚҸзЁӢиҮӘе·ұдё»еҠЁи®©еҮәзҡ„, иҖҢзәҝзЁӢжҳҜжҠўеҚ ејҸзҡ„пјҢ зәҝзЁӢеңЁжІЎйҒҮеҲ°ioдәӢ件时пјҢ д№ҹеҸҜиғҪд»ҺиҝҗиЎҢзҠ¶жҖҒиҪ¬дёәе°ұз»ӘзҠ¶жҖҒпјҢ зӣҙеҲ°еҶҚж¬Ўиў«и°ғз”Ё, иҝҷж ·дјҡеӨҡеҮәеҫҲеӨҡи°ғеәҰеёҰжқҘзҡ„ејҖй”Җ, иҖҢеҚҸзЁӢжҳҜдјҡдёҖзӣҙиҝҗиЎҢпјҢ зӣҙеҲ°йҒҮеҲ°и®©жӯҘдәӢ件жүҚеҲҮжҚўпјҢ жүҖд»ҘеҚҸзЁӢи°ғеәҰзҡ„ж¬Ўж•°дјҡжҜ”зәҝзЁӢе°‘еҫҲеӨҡгҖӮ еҗҢж—¶еҸҜд»ҘзңӢеҮәеҚҸзЁӢзҡ„дҪ•ж—¶и°ғеәҰжҳҜз”ұејҖеҸ‘иҖ…жҢҮе®ҡпјҲжҜ”еҰӮдёҠйқўжүҖиҜҙзҡ„зӯүзӯүж•°жҚ®еә“иҝ”еӣһдәӢ件пјүпјҢ иҖҢдё”жҳҜйқһжҠўеҚ ејҸзҡ„, иҝҷе°ұж„Ҹе‘ізқҖжҹҗдёӘеҚҸзЁӢеңЁиҝҗиЎҢж—¶пјҢ е…¶д»–еҚҸзЁӢжҳҜжІЎеҠһжі•иҝҗиЎҢзҡ„пјҢ еҸӘиғҪзӯүеҲ°иҝҗиЎҢзҡ„еҚҸзЁӢдәӨеҮәжү§иЎҢжқғпјҢ жүҖд»ҘејҖеҸ‘иҖ…иҰҒзЎ®дҝқдёҚиғҪи®©д»»еҠЎеңЁcpuдёҠеҒңз•ҷеӨӘй•ҝж—¶й—ҙпјҢеҗҰеҲҷеү©дҪҷзҡ„д»»еҠЎе°ұдјҡйҘҝжӯ»гҖӮ
ж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҢд»ҘдёҠе°ұжҳҜвҖңPythonдёӯSyncдёҺAsyncжү§иЎҢйҖҹеәҰеҝ«ж…ўе®һдҫӢеҜ№жҜ”еҲҶжһҗвҖқзҡ„еҶ…е®№дәҶпјҢз»ҸиҝҮжң¬ж–Үзҡ„еӯҰд№ еҗҺпјҢзӣёдҝЎеӨ§е®¶еҜ№PythonдёӯSyncдёҺAsyncжү§иЎҢйҖҹеәҰеҝ«ж…ўе®һдҫӢеҜ№жҜ”еҲҶжһҗиҝҷдёҖй—®йўҳжңүдәҶжӣҙж·ұеҲ»зҡ„дҪ“дјҡпјҢе…·дҪ“дҪҝз”Ёжғ…еҶөиҝҳйңҖиҰҒеӨ§е®¶е®һи·өйӘҢиҜҒгҖӮиҝҷйҮҢжҳҜдәҝйҖҹдә‘пјҢе°Ҹзј–е°ҶдёәеӨ§е®¶жҺЁйҖҒжӣҙеӨҡзӣёе…ізҹҘиҜҶзӮ№зҡ„ж–Үз« пјҢж¬ўиҝҺе…іжіЁпјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ