жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
д»ҠеӨ©е°Ҹзј–з»ҷеӨ§е®¶еҲҶдә«дёҖдёӢMySQLдёӯjoinиҜӯеҸҘеҰӮдҪ•дјҳеҢ–зҡ„зӣёе…ізҹҘиҜҶзӮ№пјҢеҶ…е®№иҜҰз»ҶпјҢйҖ»иҫ‘жё…жҷ°пјҢзӣёдҝЎеӨ§йғЁеҲҶдәәйғҪиҝҳеӨӘдәҶи§Јиҝҷж–№йқўзҡ„зҹҘиҜҶпјҢжүҖд»ҘеҲҶдә«иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶еҸӮиҖғдёҖдёӢпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺжңүжүҖ收иҺ·пјҢдёӢйқўжҲ‘们дёҖиө·жқҘдәҶи§ЈдёҖдёӢеҗ§гҖӮ
жҲ‘们жқҘзңӢдёҖдёӢеҪ“иҝӣиЎҢ join ж“ҚдҪңж—¶пјҢmysqlжҳҜеҰӮдҪ•е·ҘдҪңзҡ„гҖӮеёёи§Ғзҡ„ join ж–№ејҸжңүе“Әдәӣпјҹ
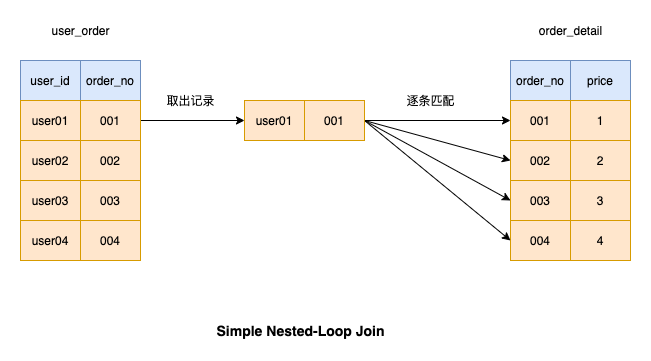
еҰӮеӣҫпјҢеҪ“жҲ‘们иҝӣиЎҢиҝһжҺҘж“ҚдҪңж—¶пјҢе·Ұиҫ№зҡ„иЎЁжҳҜй©ұеҠЁиЎЁпјҢеҸіиҫ№зҡ„иЎЁжҳҜиў«й©ұеҠЁиЎЁ
Simple Nested-Loop Join иҝҷз§ҚиҝһжҺҘж“ҚдҪңжҳҜд»Һй©ұеҠЁиЎЁдёӯеҸ–еҮәдёҖжқЎи®°еҪ•з„¶еҗҺйҖҗжқЎеҢ№й…Қиў«й©ұеҠЁиЎЁзҡ„и®°еҪ•пјҢеҰӮжһңжқЎд»¶еҢ№й…ҚеҲҷе°Ҷз»“жһңиҝ”еӣһгҖӮ然еҗҺжҺҘзқҖеҸ–й©ұеҠЁиЎЁзҡ„дёӢдёҖжқЎи®°еҪ•иҝӣиЎҢеҢ№й…ҚпјҢзӣҙеҲ°й©ұеҠЁиЎЁзҡ„ж•°жҚ®е…ЁйғҪеҢ№й…Қе®ҢжҜ•
еӣ дёәжҜҸж¬Ўд»Һй©ұеҠЁиЎЁеҸ–ж•°жҚ®жҜ”иҫғиҖ—ж—¶пјҢжүҖд»ҘMySQL并没жңүйҮҮз”Ёиҝҷз§Қз®—жі•жқҘиҝӣиЎҢиҝһжҺҘж“ҚдҪң
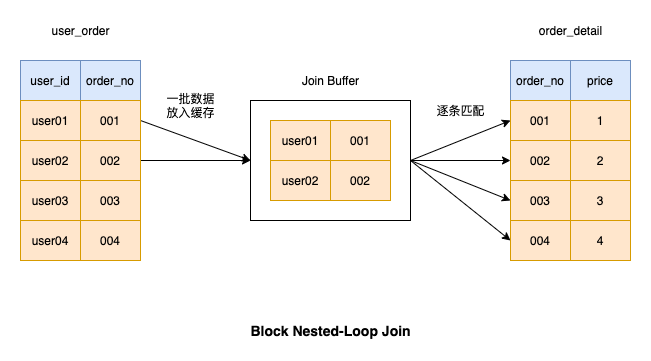
既然жҜҸж¬Ўд»Һй©ұеҠЁиЎЁеҸ–ж•°жҚ®жҜ”иҫғиҖ—ж—¶пјҢйӮЈжҲ‘们жҜҸж¬Ўд»Һй©ұеҠЁиЎЁеҸ–дёҖжү№ж•°жҚ®ж”ҫеҲ°еҶ…еӯҳдёӯпјҢ然еҗҺеҜ№иҝҷдёҖжү№ж•°жҚ®иҝӣиЎҢеҢ№й…Қж“ҚдҪңгҖӮиҝҷжү№ж•°жҚ®еҢ№й…Қе®ҢжҜ•пјҢеҶҚд»Һй©ұеҠЁиЎЁдёӯеҸ–дёҖжү№ж•°жҚ®ж”ҫеҲ°еҶ…еӯҳдёӯпјҢзӣҙеҲ°й©ұеҠЁиЎЁзҡ„ж•°жҚ®е…ЁйғҪеҢ№й…Қе®ҢжҜ•
жү№йҮҸеҸ–ж•°жҚ®иғҪеҮҸе°‘еҫҲеӨҡIOж“ҚдҪңпјҢеӣ жӯӨжү§иЎҢж•ҲзҺҮжҜ”иҫғй«ҳпјҢиҝҷз§ҚиҝһжҺҘж“ҚдҪңд№ҹиў«MySQLйҮҮз”Ё
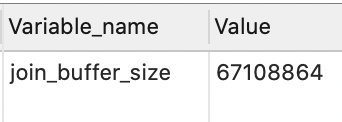
еҜ№дәҶпјҢиҝҷеқ—еҶ…еӯҳеңЁMySQдёӯжңүдёҖдёӘдё“жңүзҡ„еҗҚиҜҚпјҢеҸ«еҒҡ join bufferпјҢжҲ‘们еҸҜд»Ҙжү§иЎҢеҰӮдёӢиҜӯеҸҘжҹҘзңӢ join buffer зҡ„еӨ§е°Ҹ
show variables like '%join_buffer%'
жҠҠжҲ‘们д№ӢеүҚз”Ёзҡ„ single_table иЎЁжҗ¬еҮәжқҘпјҢеҹәдәҺ single_table иЎЁеҲӣе»ә2дёӘиЎЁпјҢжҜҸдёӘиЎЁжҸ’е…Ҙ1wжқЎйҡҸжңәи®°еҪ•
CREATE TABLE single_table ( id INT NOT NULL AUTO_INCREMENT, key1 VARCHAR(100), key2 INT, key3 VARCHAR(100), key_part1 VARCHAR(100), key_part2 VARCHAR(100), key_part3 VARCHAR(100), common_field VARCHAR(100), PRIMARY KEY (id), KEY idx_key1 (key1), UNIQUE KEY idx_key2 (key2), KEY idx_key3 (key3), KEY idx_key_part(key_part1, key_part2, key_part3) ) Engine=InnoDB CHARSET=utf8; create table t1 like single_table; create table t2 like single_table;
еҰӮжһңзӣҙжҺҘдҪҝз”Ё join иҜӯеҸҘпјҢMySQLдјҳеҢ–еҷЁеҸҜиғҪдјҡйҖүжӢ©иЎЁ t1 жҲ–иҖ… t2 дҪңдёәй©ұеҠЁиЎЁпјҢиҝҷж ·дјҡеҪұе“ҚжҲ‘们еҲҶжһҗsqlиҜӯеҸҘзҡ„иҝҮзЁӢпјҢжүҖд»ҘжҲ‘们用 straight_join и®©mysqlдҪҝз”Ёеӣәе®ҡзҡ„иҝһжҺҘж–№ејҸжү§иЎҢжҹҘиҜў
select * from t1 straight_join t2 on (t1.common_field = t2.common_field)
иҝҗиЎҢж—¶й—ҙдёә0.035s

жү§иЎҢи®ЎеҲ’еҰӮдёӢ

еңЁExtraеҲ—дёӯзңӢеҲ°дәҶ Using join buffer пјҢиҜҙжҳҺиҝһжҺҘж“ҚдҪңжҳҜеҹәдәҺ Block Nested-Loop Join з®—жі•
дәҶи§ЈдәҶ Block Nested-Loop Join з®—жі•д№ӢеҗҺпјҢеҸҜд»ҘзңӢеҲ°й©ұеҠЁиЎЁзҡ„жҜҸжқЎи®°еҪ•дјҡжҠҠиў«й©ұеҠЁиЎЁзҡ„жүҖжңүи®°еҪ•йғҪеҢ№й…ҚдёҖйҒҚпјҢйқһеёёиҖ—ж—¶пјҢиғҪдёҚиғҪжҸҗй«ҳдёҖдёӢиў«й©ұеҠЁиЎЁеҢ№й…Қзҡ„ж•ҲзҺҮе‘ўпјҹ
дј°и®Ўиҝҷз§Қз®—жі•дҪ д№ҹжғіеҲ°дәҶпјҢе°ұжҳҜз»ҷиў«й©ұеҠЁиЎЁиҝһжҺҘзҡ„еҲ—еҠ дёҠзҙўеј•пјҢиҝҷж ·еҢ№й…Қзҡ„иҝҮзЁӢе°ұйқһеёёеҝ«пјҢеҰӮеӣҫжүҖзӨә
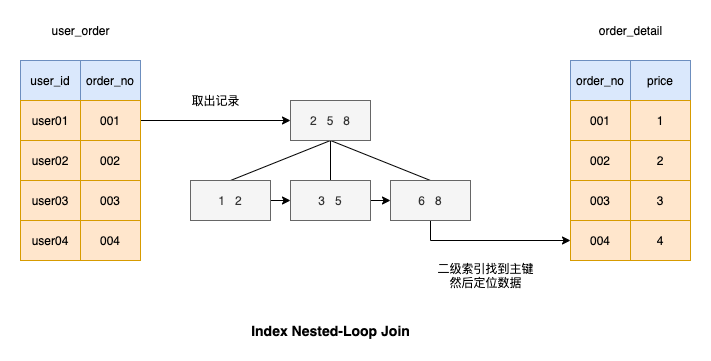
жҲ‘们жқҘзңӢдёҖдёӢеҹәдәҺзҙўеј•еҲ—иҝӣиЎҢиҝһжҺҘжү§иЎҢжҹҘиҜўжңүеӨҡеҝ«пјҹ
select * from t1 straight_join t2 on (t1.id = t2.id)
жү§иЎҢж—¶й—ҙдёә0.001з§’пјҢеҸҜд»ҘзңӢеҲ°жҜ”еҹәдәҺжҷ®йҖҡзҡ„еҲ—иҝӣиЎҢиҝһжҺҘеҝ«дәҶдёҚжӯўдёҖдёӘжЎЈж¬Ў

жү§иЎҢи®ЎеҲ’еҰӮдёӢ

й©ұеҠЁиЎЁзҡ„и®°еҪ•е№¶дёҚжҳҜжүҖжңүеҲ—йғҪдјҡиў«ж”ҫеҲ° join bufferпјҢеҸӘжңүжҹҘиҜўеҲ—иЎЁдёӯзҡ„еҲ—е’ҢиҝҮж»ӨжқЎд»¶дёӯзҡ„еҲ—жүҚдјҡиў«ж”ҫе…Ҙ join bufferпјҢеӣ жӯӨжҲ‘们дёҚиҰҒжҠҠ * дҪңдёәжҹҘиҜўеҲ—иЎЁпјҢеҸӘйңҖиҰҒжҠҠжҲ‘们关еҝғзҡ„еҲ—ж”ҫеҲ°жҹҘиҜўеҲ—иЎЁе°ұеҘҪдәҶпјҢиҝҷж ·еҸҜд»ҘеңЁ join buffer дёӯж”ҫзҪ®жӣҙеӨҡзҡ„и®°еҪ•
зҹҘйҒ“дәҶ join зҡ„е…·дҪ“е®һзҺ°пјҢжҲ‘们жқҘиҒҠдёҖдёӘеёёи§Ғзҡ„й—®йўҳпјҢеҚіеҰӮдҪ•йҖүжӢ©й©ұеҠЁиЎЁпјҹ
еҰӮжһңжҳҜ Block Nested-Loop Join з®—жі•пјҡ
еҪ“ join buffer и¶іеӨҹеӨ§ж—¶пјҢи°ҒеҒҡй©ұеҠЁиЎЁжІЎжңүеҪұе“Қ
еҪ“ join buffer дёҚеӨҹеӨ§ж—¶пјҢеә”иҜҘйҖүжӢ©е°ҸиЎЁеҒҡй©ұеҠЁиЎЁпјҲе°ҸиЎЁж•°жҚ®йҮҸе°‘пјҢж”ҫе…Ҙ join buffer зҡ„ж¬Ўж•°е°‘пјҢеҮҸе°‘иЎЁзҡ„жү«жҸҸж¬Ўж•°пјү
еҰӮжһңжҳҜ Index Nested-Loop Join з®—жі•
еҒҮи®ҫй©ұеҠЁиЎЁзҡ„иЎҢж•°жҳҜMпјҢеӣ жӯӨйңҖиҰҒжү«жҸҸй©ұеҠЁиЎЁMиЎҢ
иў«й©ұеҠЁиЎЁзҡ„иЎҢж•°жҳҜNпјҢжҜҸж¬ЎеңЁиў«й©ұеҠЁиЎЁжҹҘдёҖиЎҢж•°жҚ®пјҢиҰҒе…Ҳжҗңзҙўзҙўеј•aпјҢеҶҚжҗңзҙўдё»й”®зҙўеј•гҖӮжҜҸж¬ЎжҗңзҙўдёҖйў—ж ‘иҝ‘дјјеӨҚжқӮеәҰжҳҜд»Ҙ2дёәеә•Nзҡ„еҜ№ж•°пјҢжүҖд»ҘеңЁиў«й©ұеҠЁиЎЁдёҠжҹҘдёҖиЎҢзҡ„ж—¶й—ҙеӨҚжқӮеәҰжҳҜ 2 ∗ l o g 2 N 2*log2^N 2∗log2N
й©ұеҠЁиЎЁзҡ„жҜҸдёҖиЎҢж•°жҚ®йғҪиҰҒеҲ°иў«й©ұеҠЁиЎЁдёҠжҗңзҙўдёҖж¬ЎпјҢж•ҙдёӘжү§иЎҢиҝҮзЁӢиҝ‘дјјеӨҚжқӮеәҰдёә M + M ∗ 2 ∗ l o g 2 N M + M*2*log2^N M+M∗2∗log2N
жҳҫ然MеҜ№жү«жҸҸиЎҢж•°еҪұе“ҚжӣҙеӨ§пјҢеӣ жӯӨеә”иҜҘи®©е°ҸиЎЁеҒҡй©ұеҠЁиЎЁгҖӮеҪ“然иҝҷдёӘз»“и®әзҡ„еүҚжҸҗжҳҜеҸҜд»ҘдҪҝз”Ёиў«й©ұеҠЁиЎЁзҡ„зҙўеј•
жҖ»иҖҢиЁҖд№ӢпјҢжҲ‘们让е°ҸиЎЁеҒҡй©ұеҠЁиЎЁеҚіеҸҜ
еҪ“ join иҜӯеҸҘжү§иЎҢзҡ„жҜ”иҫғж…ўж—¶пјҢжҲ‘们еҸҜд»ҘйҖҡиҝҮеҰӮдёӢж–№жі•жқҘиҝӣиЎҢдјҳеҢ–
иҝӣиЎҢиҝһжҺҘж“ҚдҪңж—¶пјҢиғҪдҪҝз”Ёиў«й©ұеҠЁиЎЁзҡ„зҙўеј•
е°ҸиЎЁеҒҡй©ұеҠЁиЎЁ
еўһеӨ§ join buffer зҡ„еӨ§е°Ҹ
дёҚиҰҒз”Ё * дҪңдёәжҹҘиҜўеҲ—иЎЁпјҢеҸӘиҝ”еӣһйңҖиҰҒзҡ„еҲ—
д»ҘдёҠе°ұжҳҜвҖңMySQLдёӯjoinиҜӯеҸҘеҰӮдҪ•дјҳеҢ–вҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒзӣёдҝЎеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« йғҪжңүеҫҲеӨ§зҡ„收иҺ·пјҢе°Ҹзј–жҜҸеӨ©йғҪдјҡдёәеӨ§е®¶жӣҙж–°дёҚеҗҢзҡ„зҹҘиҜҶпјҢеҰӮжһңиҝҳжғіеӯҰд№ жӣҙеӨҡзҡ„зҹҘиҜҶпјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ