您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本篇内容主要讲解“如何使用R中的merge()函数合并数据”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“如何使用R中的merge()函数合并数据”吧!
在R中可以使用merge()函数去合并数据框,其强大之处在于在两个不同的数据框中标识共同的列或行。
merge()最简单的形式为获取两个不同数据框中交叉部分。举例,获取cold.states和large.states完全匹配的数据。代码如下:
> merge(cold.states, large.states) Name Frost Area 1 Alaska 152 566432 2 Colorado 166 103766 3 Montana 155 145587 4 Nevada 188 109889
如果你属性数据库语法SQL,你可能想merge()和数据库中JOIN功能很相似。确实如此,merge()函数的不同参数可以实现内join,left join,right join以及完整join。
merge()函数有很多参数,看起来非常吓人。但他们都几中类型参数有关:
x: 第一个数据框.
y: 第二个数据框.
by, by.x, by.y: 指定两个数据框中匹配列名称。缺省使用两个数据框中相同列名称。
all, all.x, all.y: 指定合并类型的逻辑值。缺省为false,all=FALSE (仅返回匹配的行).
最后一组参数all, all.x, all.y需要进一步解释,决定合并类型。
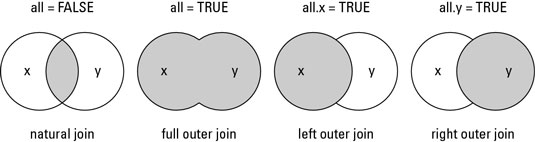
merge() 函数支持4种类型数据合并:
Natural join: 仅返回两数据框中匹配的数据框行,参数为:all=FALSE.
Full outer join: 返回两数据框中所有行, 参数为: all=TRUE.
Left outer join: 返回x数据框中所有行以及和y数据框中匹配的行,参数为: all.x=TRUE.
Right outer join: 返回y数据框中所有行以及和x数据框匹配的行,参数为: all.y=TRUE.
返回示例数据中美国的州,执行完整合并cold和large state,使用参数all=TRUE.
> merge(cold.states, large.states, all=TRUE) Name Frost Area 1 Alaska 152 566432 2 Arizona NA 113417 3 California NA 156361 .... 13 Texas NA 262134 14 Vermont 168 NA 15 Wyoming 173 NA
两个数据框有不同的名称,所以R基于两者state的name进行匹配。Frost来自cold.states数据框,Area来自large.states.
上面代码执行了完整合并,填充未匹配列值为NA。
到此,相信大家对“如何使用R中的merge()函数合并数据”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。