您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本篇内容介绍了“SQL Server如何实现全文搜索查询”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
全文索引在表中包括一个或多个基于字符的列。这些列可以具有以下任何数据类型:char、varchar、nchar、nvarchar、text、ntext、image、xml 或 varbinary(max) 和 FILESTREAM。每个全文索引为表中的一列或多列编制索引,并且每列可以使用特定的语言。
全文查询通过基于特定语言(如英语或中文)的规则对单词和短语进行操作,对全文索引中的文本数据执行语言搜索。全文查询可以包括简单的字词和短语,也可以包括字词或短语的多种形式。全文查询返回至少包含一个匹配项(也称为匹配项)的任何文档。当目标文档包含全文查询中指定的所有术语,并满足任何其他搜索条件(如匹配术语之间的距离)时,将发生匹配。
将列添加到全文索引后,用户和应用程序可以对列中的文本运行全文查询。这些查询可以搜索以下任何内容:
一个或多个特定单词或短语(简单术语)。
单词或短语,其中单词以指定文本(前缀术语)开头)。
特定单词的屈折形
式(世代术语))。
接近另一个单词或短语的单词或短语(邻近术语))。
特定单词的同义词形式(同义词库)。
使用加权值的字词或短语(加权术语)。
全文查询不区分大小写。例如,搜索"Aluminum" 或 "aluminum"将返回相同的结果。
全文查询使用一小组 Transact-SQL 谓词 ( and ) 和函数 ( and ) 。但是,给定业务方案的搜索目标会影响全文查询的结构。例如:CONTAINS FREETEXT CONTAINSTABLE FREETEXTTABLE
(1)电子商务-在网站上搜索产品:
SELECT product_id FROM products WHERE CONTAINS(product_description, '"Snap Happy 100EZ"' OR FORMSOF(THESAURUS,'"Snap Happy"') OR '100EZ') AND product_cost < 200 ;
(2)招聘方案 - 搜索具有使用 SQL Server 经验的求职者:
SELECT candidate_name,SSN FROM candidates WHERE CONTAINS(candidate_resume, '"SQL Server"') AND candidate_division = 'DBA';
与全文搜索相比,LIKE Transact-SQL 谓词仅适用于字符模式。此外,不能使用 LIKE 谓词查询格式化的二进制数据。此外,针对大量非结构化文本数据的 LIKE 查询比针对相同数据的等效全文查询慢得多。针对数百万行文本数据的 LIKE 查询可能需要几分钟才能返回;而全文查询对相同数据可能只需要几秒钟或更短的时间,具体取决于返回的行数。
全文搜索体系结构由以下过程组成:
SQL Server 进程 (sqlservr.exe)。
筛选器守护程序主机进程 (fdhost.exe)。
出于安全原因,过滤器由称为过滤器守护程序主机的单独进程加载。fdhost.exe进程由 FDHOST 启动器服务 (MSSQLFDLauncher) 创建,它们在 FDHOST 启动器服务帐户的安全凭据下运行。因此,FDHOST 启动器服务必须运行才能使全文索引和全文查询正常工作。
这两个过程包含全文搜索体系结构的组件。下图总结了这些组件及其关系。这些组件在图示后进行了描述。
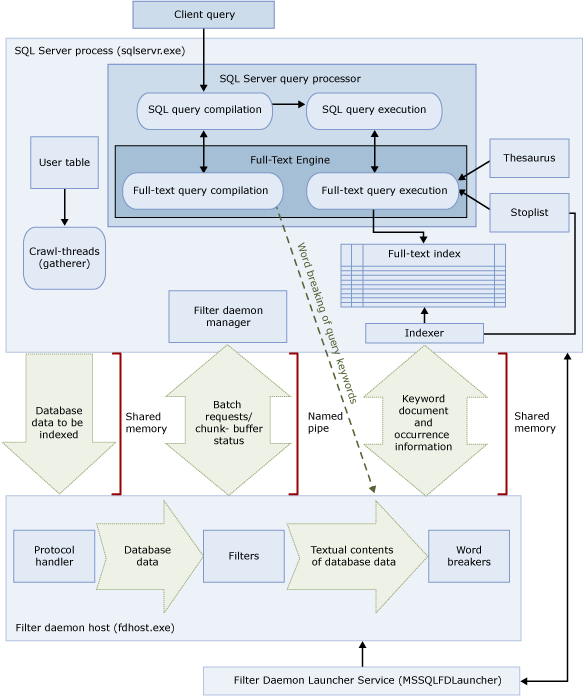
SQL Server 进程使用以下组件进行全文搜索:
用户表。这些表包含要进行全文索引的数据。
全文收集器。全文收集器使用全文爬网线程。它负责计划和驱动全文索引的填充,还负责监视全文目录。
同义词库文件。这些文件包含搜索词的同义词。有关详细信息,请参阅配置和管理全文搜索的同义词库文件。
非索引字表对象。非索引字表对象包含对搜索无用的常用词的列表。有关详细信息,请参阅配置和管理全文搜索的非索引字和非索引字表。
SQL Server 查询处理器。查询处理器编译并执行 SQL 查询。如果 SQL 查询包含全文搜索查询,则在编译和执行期间,该查询将发送到全文引擎。查询结果与全文索引匹配。
全文引擎。SQL Server 中的全文引擎与查询处理器完全集成。全文引擎编译并执行全文查询。作为查询执行的一部分,全文引擎可能会从同义词库和非索引字表接收输入。
索引编写器(索引器)。索引编写器生成用于存储索引令牌的结构。
筛选器守护程序管理器。筛选器守护程序管理器负责监视全文引擎筛选器守护程序主机的状态。
筛选器守护程序主机是由全文引擎启动的进程。它运行以下全文搜索组件,这些组件负责访问、筛选和分词表数据,以及分词和对查询输入进行词干提取。
筛选器守护程序主机的组件如下所示:
协议处理程序。此组件从内存中提取数据以进行进一步处理,并从指定数据库中的用户表中访问数据。它的职责之一是从全文索引的列中收集数据,并将其传递给筛选器守护程序主机,该主机将根据需要应用筛选和分词系统。
过滤器。某些数据类型需要筛选,然后才能对文档中的数据进行全文索引,包括变量、变量二元(最大值)、图像或 xml 列中的数据。用于给定文档的筛选器取决于其文档类型。例如,不同的筛选器用于 Microsoft Word (.doc) 文档、Microsoft Excel (.xls) 文档和 XML (.xml) 文档。然后,筛选器从文档中提取文本块,删除嵌入的格式并保留文本,并可能保留有关文本位置的信息。结果是文本信息流。有关详细信息,请参阅配置和管理搜索筛选器。
分词系统和词干分析器。分词系统是特定于语言的组件,它根据给定语言的词法规则(断词)查找单词边界。每个分词系统都与特定于语言的词干分析器组件相关联,该组件共轭动词并执行屈折扩展。在编制索引时,筛选器守护程序宿主使用分词系统和词干分析器对给定表列中的文本数据执行语言分析。与全文索引中的表列关联的语言确定用于为列编制索引的分词系统和词干分析器。
全文搜索由全文引擎提供支持。全文引擎有两个角色:索引支持和查询支持。
启动全文填充(也称为爬网)时,全文引擎会将大量数据推送到内存中,并通知筛选器守护程序主机。主机过滤和单词分解数据,并将转换后的数据转换为倒置单词列表。然后,全文搜索从单词列表中提取转换后的数据,处理数据以删除非索引字,并将批处理的单词列表保存到一个或多个倒排索引中。
对存储在 varbinary(max) 或图像列中的数据编制索引时,实现 IFilter 接口的筛选器会根据该数据的指定文件格式(例如 Microsoft Word)提取文本。在某些情况下,过滤器组件需要将变量(max)或图像数据写出到filterdata文件夹,而不是推送到内存中。
作为处理的一部分,收集的文本数据通过分词系统传递,以将文本分隔为单独的标记或关键字。用于标记化的语言在列级别指定,也可以通过过滤器组件在 varbinary(max)、图像或 xml 数据中标识。
可以执行其他处理以删除非索引字,并在标记存储在全文索引或索引片段中之前对其进行规范化。
填充完成后,将触发最终合并过程,将索引片段合并到一个主全文索引中。这提高了查询性能,因为只需要查询主索引而不是多个索引片段,并且可以使用更好的评分统计信息进行相关性排名。
查询处理器将查询的全文部分传递给全文引擎进行处理。全文引擎执行断词和(可选)同义词库扩展、词干提取和非索引字(干扰词)处理。然后,查询的全文部分以 SQL 运算符的形式表示,主要表示为流式表值函数 (STVF)。在查询执行期间,这些 STVF 访问倒排索引以检索正确的结果。此时,结果要么返回到客户端,要么在返回到客户端之前进一步处理。
全文引擎使用全文索引中的信息来编译全文查询,这些查询可以快速在表中搜索特定单词或单词组合。全文索引存储有关重要单词及其在数据库表的一列或多列中的位置的信息。全文索引是一种特殊类型的基于令牌的功能索引,由 SQL Server 全文引擎生成和维护。构建全文索引的过程不同于构建其他类型的索引。全文引擎不是基于存储在特定行中的值构造 B 树结构,而是基于要编制索引的文本中的单个标记构建倒置、堆叠、压缩的索引结构。全文索引的大小仅受运行 SQL Server 实例的计算机的可用内存资源的限制。
从 SQL Server 2008 (10.0.x) 开始,全文索引与数据库引擎集成,而不是像以前版本的 SQL Server 那样驻留在文件系统中。对于新数据库,全文目录现在是不属于任何文件组的虚拟对象;它只是一个逻辑概念,指的是一组全文索引。
每个表只允许有一个全文索引。若要在表上创建全文索引,该表必须具有单个唯一的非空列。可以在 char、varchar、nchar、nvarchar、nvarchar、text、ntext、image、xml、varbinary 和 varbinary(max) 类型的列上构建全文索引,以便为全文搜索编制索引。 在数据类型为变量、变量二进制(max)、图像或 xml 的列上创建全文索引需要指定类型列。类型列是表格列,您可以在其中将文档的文件扩展名(.doc、.pdf、.xls等)存储在每行中。
充分了解全文索引的结构将有助于您了解全文引擎的工作原理。例如:
| 标识 | 标题 |
|---|---|
| 1 | 曲柄臂和轮胎保养 |
| 2 | 前反射器支架和反射器组件 3 |
| 3 | 前反射器支架安装 |
下表显示了片段 1,描述了在“文档”表的“标题”列上创建的全文索引的内容。全文索引包含的信息比此表中显示的信息要多。该表是全文索引的逻辑表示形式,仅用于演示目的。这些行以压缩格式存储,以优化磁盘使用情况。
请注意,数据已从原始文档反转。发生反转是因为关键字映射到文档 ID。因此,全文索引通常称为倒排索引。
另请注意,关键字“and”已从全文索引中删除。这样做是因为“and”是非索引字,从全文索引中删除非索引字可以节省大量磁盘空间,从而提高查询性能。
片段一:
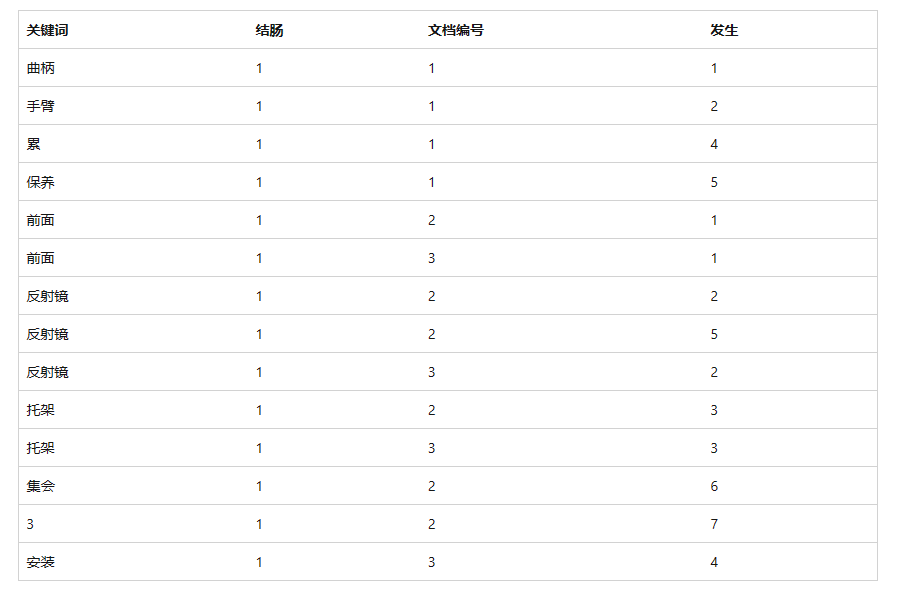
“关键字”列包含在编制索引时提取的单个标记的表示形式。分词系统确定令牌的组成。
逻辑全文索引通常拆分为多个内部表。每个内部表称为全文索引片段。其中一些片段可能包含比其他片段更新的数据。例如,如果用户更新 标识为 3 的以下行,并且表是自动更改跟踪的,则会创建一个新片段。
| 文档标识 | 标题 |
|---|---|
| 3 | 后反射器 |
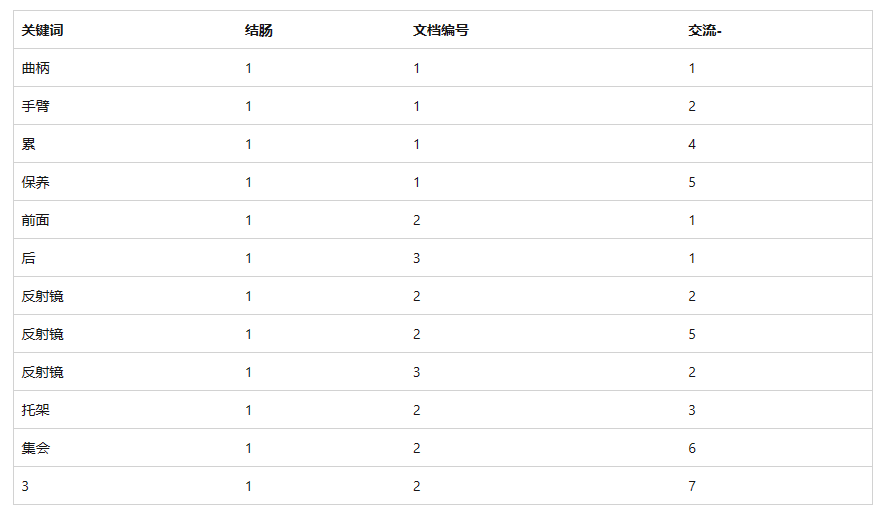
一下的片段 2,与片段 3 相比,片段包含有关 标识 1 的更新数据。因此,当用户查询“后反射器”时,片段 2 中的数据将用于 标识3。每个片段都标有创建时间戳,可以使用sys.fulltext_index_fragments目录视图查询该时间戳。
片段 2:
| 关键词 | 结肠 | 标识 | 交流 |
|---|---|---|---|
| 后 | 1 | 3 | 1 |
| 反射镜 | 1 | 3 | 2 |
从片段 2 可以看出,全文查询需要在内部查询每个片段并丢弃较旧的条目。因此,全文索引中的全文索引片段过多可能会导致查询性能大幅下降。若要减少片段数,请使用“更改全文目录 Transact-SQL”语句的“重新组织”选项重新组织全文目录。此语句执行主合并,这会将片段合并为一个较大的片段,并从全文索引中删除所有过时的条目。
重新组织后,示例索引将包含以下行:
| 全文索引 | 常规 SQL Server 索引 |
|---|---|
| 每个表只允许有一个全文索引。 | 每个表允许多个常规索引。 |
| 可以通过计划或特定请求向全文索引添加数据(称为填充),也可以通过添加新数据自动进行。 | 在插入、更新或删除它们所基于的数据时自动更新。 |
| 在同一数据库中分组到一个或多个全文目录中。 | 未分组。 |
“SQL Server如何实现全文搜索查询”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。