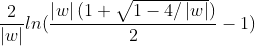
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮеҶ…е®№д»Ӣз»ҚдәҶвҖңPythonдёӯеёёз”Ёзҡ„жҝҖжҙ»еҮҪж•°жңүе“ӘдәӣвҖқзҡ„жңүе…ізҹҘиҜҶпјҢеңЁе®һйҷ…жЎҲдҫӢзҡ„ж“ҚдҪңиҝҮзЁӢдёӯпјҢдёҚе°‘дәәйғҪдјҡйҒҮеҲ°иҝҷж ·зҡ„еӣ°еўғпјҢжҺҘдёӢжқҘе°ұи®©е°Ҹзј–еёҰйўҶеӨ§е®¶еӯҰд№ дёҖдёӢеҰӮдҪ•еӨ„зҗҶиҝҷдәӣжғ…еҶөеҗ§пјҒеёҢжңӣеӨ§е®¶д»”з»Ҷйҳ…иҜ»пјҢиғҪеӨҹеӯҰжңүжүҖжҲҗпјҒ
жҝҖжҙ»еҮҪж•° (Activation functions) еҜ№дәҺдәәе·ҘзҘһз»ҸзҪ‘з»ңжЁЎеһӢеҺ»еӯҰд№ гҖҒзҗҶи§ЈйқһеёёеӨҚжқӮе’ҢйқһзәҝжҖ§зҡ„еҮҪж•°жқҘиҜҙе…·жңүеҚҒеҲҶйҮҚиҰҒзҡ„дҪңз”ЁгҖӮе®ғ们е°ҶйқһзәҝжҖ§зү№жҖ§еј•е…ҘеҲ°зҘһз»ҸзҪ‘з»ңдёӯгҖӮеңЁдёӢеӣҫдёӯпјҢиҫ“е…Ҙзҡ„ inputs йҖҡиҝҮеҠ жқғпјҢжұӮе’ҢеҗҺпјҢиҝҳиў«дҪңз”ЁдәҶдёҖдёӘеҮҪж•°fпјҢиҝҷдёӘеҮҪж•°fе°ұжҳҜжҝҖжҙ»еҮҪж•°гҖӮеј•е…ҘжҝҖжҙ»еҮҪж•°жҳҜдёәдәҶеўһеҠ зҘһз»ҸзҪ‘з»ңжЁЎеһӢзҡ„йқһзәҝжҖ§гҖӮжІЎжңүжҝҖжҙ»еҮҪж•°зҡ„жҜҸеұӮйғҪзӣёеҪ“дәҺзҹ©йҳөзӣёд№ҳгҖӮе°ұз®—дҪ еҸ еҠ дәҶиӢҘе№ІеұӮд№ӢеҗҺпјҢж— йқһиҝҳжҳҜдёӘзҹ©йҳөзӣёд№ҳзҪўдәҶгҖӮ
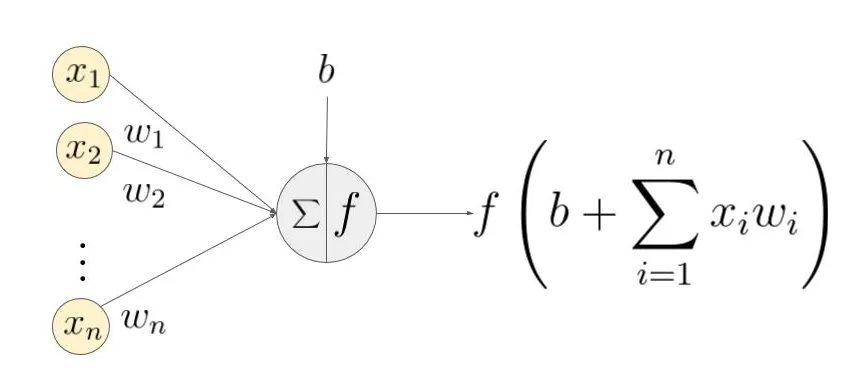
дёәд»Җд№ҲдҪҝз”ЁжҝҖжҙ»еҮҪж•°пјҹ
еҰӮжһңдёҚз”ЁжҝҖеҠұеҮҪж•°пјҲе…¶е®һзӣёеҪ“дәҺжҝҖеҠұеҮҪж•°жҳҜf(x) = xпјүпјҢеңЁиҝҷз§Қжғ…еҶөдёӢдҪ жҜҸдёҖеұӮиҠӮзӮ№зҡ„иҫ“е…ҘйғҪжҳҜдёҠеұӮиҫ“еҮәзҡ„зәҝжҖ§еҮҪж•°пјҢеҫҲе®№жҳ“йӘҢиҜҒпјҢж— и®әдҪ зҘһз»ҸзҪ‘з»ңжңүеӨҡе°‘еұӮпјҢиҫ“еҮәйғҪжҳҜиҫ“е…Ҙзҡ„зәҝжҖ§з»„еҗҲпјҢдёҺжІЎжңүйҡҗи—ҸеұӮж•ҲжһңзӣёеҪ“пјҢиҝҷз§Қжғ…еҶөе°ұжҳҜжңҖеҺҹе§Ӣзҡ„ж„ҹзҹҘжңәпјҲPerceptronпјүдәҶпјҢйӮЈд№ҲзҪ‘з»ңзҡ„йҖјиҝ‘иғҪеҠӣе°ұзӣёеҪ“жңүйҷҗгҖӮжӯЈеӣ дёәдёҠйқўзҡ„еҺҹеӣ пјҢжҲ‘们еҶіе®ҡеј•е…ҘйқһзәҝжҖ§еҮҪж•°дҪңдёәжҝҖеҠұеҮҪж•°пјҢиҝҷж ·ж·ұеұӮзҘһз»ҸзҪ‘з»ңиЎЁиҫҫиғҪеҠӣе°ұжӣҙеҠ ејәеӨ§пјҲдёҚеҶҚжҳҜиҫ“е…Ҙзҡ„зәҝжҖ§з»„еҗҲпјҢиҖҢжҳҜеҮ д№ҺеҸҜд»ҘйҖјиҝ‘д»»ж„ҸеҮҪж•°пјүгҖӮ
жҝҖжҙ»еҮҪж•°жңүе“ӘдәӣжҖ§иҙЁпјҹ
йқһзәҝжҖ§пјҡеҪ“жҝҖжҙ»еҮҪж•°жҳҜйқһзәҝжҖ§зҡ„пјҢдёҖдёӘдёӨеұӮзҡ„зҘһз»ҸзҪ‘з»ңе°ұеҸҜд»Ҙеҹәжң¬дёҠйҖјиҝ‘жүҖжңүзҡ„еҮҪж•°гҖӮдҪҶеҰӮжһңжҝҖжҙ»еҮҪж•°жҳҜжҒ’зӯүжҝҖжҙ»еҮҪж•°зҡ„ж—¶еҖҷпјҢеҚіf(x) = xпјҢе°ұдёҚж»Ўи¶іиҝҷдёӘжҖ§иҙЁпјҢиҖҢдё”еҰӮжһңMLPдҪҝз”Ёзҡ„жҳҜжҒ’зӯүжҝҖжҙ»еҮҪж•°пјҢйӮЈд№Ҳе…¶е®һж•ҙдёӘзҪ‘з»ңи·ҹеҚ•еұӮзҘһз»ҸзҪ‘з»ңжҳҜзӯүд»·зҡ„гҖӮ
еҸҜеҫ®жҖ§пјҡеҪ“дјҳеҢ–ж–№жі•жҳҜеҹәдәҺжўҜеәҰзҡ„ж—¶еҖҷпјҢе°ұдҪ“зҺ°зҡ„иҜҘжң¬иҙЁгҖӮ
еҚ•и°ғжҖ§пјҡеҪ“жҝҖжҙ»еҮҪж•°жҳҜеҚ•и°ғзҡ„ж—¶еҖҷпјҢеҚ•еұӮзҪ‘з»ңиғҪеӨҹдҝқиҜҒжҳҜеҮёеҮҪж•°гҖӮ
иҫ“еҮәеҖјзҡ„иҢғеӣҙпјҡеҪ“жҝҖжҙ»еҮҪж•°иҫ“еҮәеҖјжҳҜжңүйҷҗзҡ„ж—¶еҖҷпјҢеҹәдәҺжўҜеәҰзҡ„дјҳеҢ–ж–№жі•дјҡжӣҙеҠ зЁіе®ҡпјҢеӣ дёәзү№еҫҒзҡ„иЎЁзӨәеҸ—жңүйҷҗжқғеҖјзҡ„еҪұе“Қжӣҙжҳҫи‘—пјӣеҪ“жҝҖжҙ»еҮҪж•°зҡ„иҫ“еҮәжҳҜж— йҷҗзҡ„ж—¶еҖҷпјҢжЁЎеһӢзҡ„и®ӯз»ғжӣҙеҠ й«ҳж•ҲпјҢдёҚиҝҮиҝҷз§Қжғ…еҶөеҫҲе°ҸпјҢдёҖиҲ¬йңҖиҰҒжӣҙе°Ҹзҡ„learning rateгҖӮ
жўҜеәҰж¶ҲеӨұдёҺжўҜеәҰзҲҶзӮё
еұӮж•°жҜ”иҫғеӨҡзҡ„зҘһз»ҸзҪ‘з»ңжЁЎеһӢеңЁи®ӯз»ғзҡ„ж—¶еҖҷдјҡеҮәзҺ°жўҜеәҰж¶ҲеӨұ(gradient vanishing problem)е’ҢжўҜеәҰзҲҶзӮё(gradient exploding problem)й—®йўҳгҖӮжўҜеәҰж¶ҲеӨұй—®йўҳе’ҢжўҜеәҰзҲҶзӮёй—®йўҳдёҖиҲ¬дјҡйҡҸзқҖзҪ‘з»ңеұӮж•°зҡ„еўһеҠ еҸҳеҫ—и¶ҠжқҘи¶ҠжҳҺжҳҫгҖӮ
дҫӢеҰӮпјҢдёҖдёӘзҪ‘з»ңеҗ«жңүдёүдёӘйҡҗи—ҸеұӮпјҢжўҜеәҰж¶ҲеӨұй—®йўҳеҸ‘з”ҹж—¶пјҢйқ иҝ‘иҫ“еҮәеұӮзҡ„hidden layer 3зҡ„жқғеҖјжӣҙж–°зӣёеҜ№жӯЈеёёпјҢдҪҶжҳҜйқ иҝ‘иҫ“е…ҘеұӮзҡ„hidden layer1зҡ„жқғеҖјжӣҙж–°дјҡеҸҳеҫ—еҫҲж…ўпјҢеҜјиҮҙйқ иҝ‘иҫ“е…ҘеұӮзҡ„йҡҗи—ҸеұӮжқғеҖјеҮ д№ҺдёҚеҸҳпјҢд»ҚжҺҘиҝ‘дәҺеҲқе§ӢеҢ–зҡ„жқғеҖјгҖӮиҝҷе°ұеҜјиҮҙhidden layer 1 зӣёеҪ“дәҺеҸӘжҳҜдёҖдёӘжҳ е°„еұӮпјҢеҜ№жүҖжңүзҡ„иҫ“е…ҘеҒҡдәҶдёҖдёӘеҮҪж•°жҳ е°„пјҢиҝҷж—¶жӯӨж·ұеәҰзҘһз»ҸзҪ‘з»ңзҡ„еӯҰд№ е°ұзӯүд»·дәҺеҸӘжңүеҗҺеҮ еұӮзҡ„йҡҗи—ҸеұӮзҪ‘з»ңеңЁеӯҰд№ гҖӮжўҜеәҰзҲҶзӮёзҡ„жғ…еҶөжҳҜпјҡеҪ“еҲқе§Ӣзҡ„жқғеҖјиҝҮеӨ§пјҢйқ иҝ‘иҫ“е…ҘеұӮзҡ„hidden layer 1зҡ„жқғеҖјеҸҳеҢ–жҜ”йқ иҝ‘иҫ“еҮәеұӮзҡ„hidden layer 3зҡ„жқғеҖјеҸҳеҢ–жӣҙеҝ«пјҢе°ұдјҡеј•иө·жўҜеәҰзҲҶзӮёзҡ„й—®йўҳгҖӮ
жўҜеәҰж¶ҲеӨұзҡ„ж №жң¬еҺҹеӣ
д»ҘдёӢеӣҫзҡ„еҸҚеҗ‘дј ж’ӯдёәдҫӢпјҡ
еҒҮи®ҫσдёәsigmoidпјҢCдёәд»Јд»·еҮҪж•°гҖӮ
дёӢеӣҫпјҲ1пјүејҸдёәиҜҘзҪ‘з»ңзҡ„еүҚеҗ‘дј ж’ӯе…¬ејҸгҖӮ
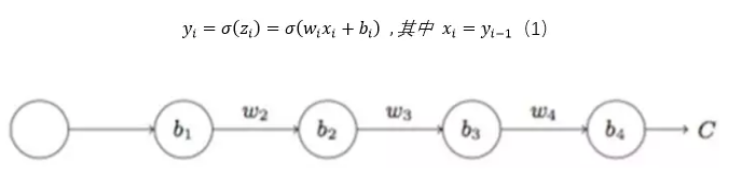
ж №жҚ®еүҚеҗ‘дј ж’ӯе…¬ејҸпјҢжҲ‘们еҫ—еҮәжўҜеәҰжӣҙж–°е…¬ејҸпјҡ
е…¶дёӯз”ұе…¬ејҸпјҲ1пјүеҫ—еҮә
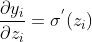
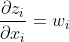
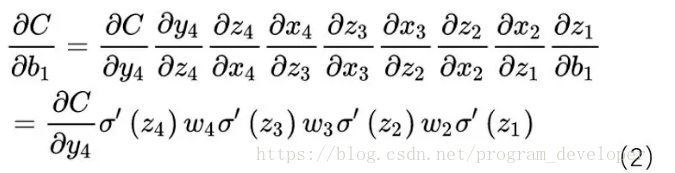
sigmoidеҮҪж•°зҡ„еҜјж•°еҰӮдёӢеӣҫжүҖзӨә
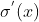
зҡ„жңҖеӨ§еҖјжҳҜ

пјҢиҖҢжҲ‘们дёҖиҲ¬дјҡдҪҝз”Ёж ҮеҮҶж–№жі•жқҘеҲқе§ӢеҢ–зҪ‘з»ңжқғйҮҚпјҢеҚідҪҝз”ЁдёҖдёӘеқҮеҖјдёә0ж ҮеҮҶе·®дёә1зҡ„й«ҳж–ҜеҲҶеёғгҖӮеӣ жӯӨпјҢеҲқе§ӢеҢ–зҡ„зҪ‘з»ңжқғеҖјйҖҡеёёйғҪе°ҸдәҺ1пјҢд»ҺиҖҢжңү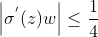 гҖӮеҜ№дәҺ2ејҸзҡ„й“ҫејҸжұӮеҜјпјҢеұӮж•°и¶ҠеӨҡпјҢжұӮеҜјз»“жһңи¶Ҡе°ҸпјҢеүҚйқўзҡ„зҪ‘з»ңеұӮжҜ”еҗҺйқўзҡ„зҪ‘з»ңеұӮжўҜеәҰеҸҳеҢ–жӣҙе°ҸпјҢж•…жқғеҖјеҸҳеҢ–зј“ж…ўпјҢжңҖз»ҲеҜјиҮҙжўҜеәҰж¶ҲеӨұзҡ„жғ…еҶөеҮәзҺ°гҖӮ
гҖӮеҜ№дәҺ2ејҸзҡ„й“ҫејҸжұӮеҜјпјҢеұӮж•°и¶ҠеӨҡпјҢжұӮеҜјз»“жһңи¶Ҡе°ҸпјҢеүҚйқўзҡ„зҪ‘з»ңеұӮжҜ”еҗҺйқўзҡ„зҪ‘з»ңеұӮжўҜеәҰеҸҳеҢ–жӣҙе°ҸпјҢж•…жқғеҖјеҸҳеҢ–зј“ж…ўпјҢжңҖз»ҲеҜјиҮҙжўҜеәҰж¶ҲеӨұзҡ„жғ…еҶөеҮәзҺ°гҖӮ
жўҜеәҰзҲҶзӮёзҡ„ж №жң¬еҺҹеӣ
еҪ“
пјҢд№ҹе°ұжҳҜwжҜ”иҫғеӨ§зҡ„жғ…еҶөгҖӮеҲҷеүҚйқўзҡ„зҪ‘з»ңеұӮжҜ”еҗҺйқўзҡ„зҪ‘з»ңеұӮжўҜеәҰеҸҳеҢ–жӣҙеҝ«пјҢеј•иө·дәҶжўҜеәҰзҲҶзӮёзҡ„й—®йўҳгҖӮ
еҪ“жҝҖжҙ»еҮҪж•°дёәsigmoidж—¶пјҢжўҜеәҰж¶ҲеӨұе’ҢжўҜеәҰзҲҶзӮёйӮЈдёӘжӣҙе®№жҳ“еҸ‘з”ҹпјҹ
жўҜеәҰж¶ҲеӨұиҫғе®№жҳ“еҸ‘з”ҹ
йҮҸеҢ–еҲҶжһҗжўҜеәҰзҲҶзӮёж—¶xзҡ„еҸ–еҖјиҢғеӣҙпјҡеӣ еҜјж•°жңҖеӨ§дёә0.25пјҢж•…|w|>4пјҢжүҚеҸҜиғҪеҮәзҺ°пјӣжҢүз…§еҸҜи®Ўз®—еҮәxзҡ„ж•°еҖјеҸҳеҢ–иҢғеӣҙеҫҲзӘ„пјҢд»…еңЁе…¬ејҸ3иҢғеӣҙеҶ…пјҢжүҚдјҡеҮәзҺ°жўҜеәҰзҲҶзӮёгҖӮз”»еӣҫеҰӮ5жүҖзӨәпјҢеҸҜи§Ғxзҡ„ж•°еҖјеҸҳеҢ–иҢғеӣҙеҫҲе°ҸпјӣжңҖеӨ§ж•°еҖјиҢғеӣҙд№ҹд»…д»…0.45пјҢеҪ“|w|=6.9ж—¶еҮәзҺ°гҖӮеӣ жӯӨд»…д»…еңЁжӯӨеҫҲзӘ„зҡ„иҢғеӣҙеҶ…дјҡеҮәзҺ°жўҜеәҰзҲҶзӮёзҡ„й—®йўҳгҖӮ
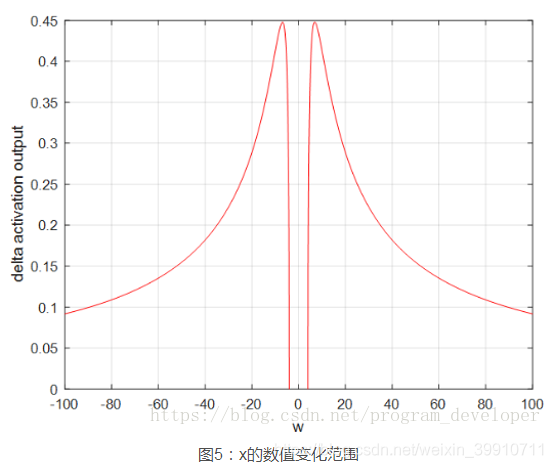
еҰӮдҪ•и§ЈеҶіжўҜеәҰж¶ҲеӨұе’ҢжўҜеәҰзҲҶзӮёй—®йўҳпјҹ
жўҜеәҰж¶ҲеӨұе’ҢжўҜеәҰзҲҶзӮёй—®йўҳйғҪжҳҜеӣ дёәзҪ‘з»ңеӨӘж·ұпјҢзҪ‘з»ңжқғеҖјжӣҙж–°дёҚзЁіе®ҡйҖ жҲҗзҡ„пјҢжң¬иҙЁдёҠжҳҜеӣ дёәжўҜеәҰеҸҚеҗ‘дј ж’ӯдёӯзҡ„иҝһд№ҳж•Ҳеә”гҖӮеҜ№дәҺжӣҙжҷ®йҒҚзҡ„жўҜеәҰж¶ҲеӨұй—®йўҳпјҢеҸҜд»ҘиҖғиҷ‘дёҖдёӢдёүз§Қж–№жЎҲи§ЈеҶіпјҡ
1. з”ЁReLUгҖҒLeaky-ReLUгҖҒP-ReLUгҖҒR-ReLUгҖҒMaxoutзӯүжӣҝд»ЈsigmoidеҮҪж•°гҖӮ
2. з”ЁBatch NormalizationгҖӮ
3. LSTMзҡ„з»“жһ„и®ҫи®Ўд№ҹеҸҜд»Ҙж”№е–„RNNдёӯзҡ„жўҜеәҰж¶ҲеӨұй—®йўҳгҖӮ
жҝҖжҙ»еҮҪж•°еҲҶдёәдёӨзұ»пјҢйҘұе’ҢжҝҖжҙ»еҮҪж•°е’ҢйқһйҘұе’ҢжҝҖжҙ»еҮҪж•°гҖӮ
йҘұе’ҢжҝҖжҙ»еҮҪж•°еҢ…жӢ¬sigmoidгҖҒtanhпјӣйқһйҘұе’ҢжҝҖжҙ»еҮҪж•°еҢ…жӢ¬ReLUгҖҒPReLUгҖҒLeaky ReLUгҖҒRReLUгҖҒELUзӯүгҖӮ
йӮЈд»Җд№ҲжҳҜйҘұе’ҢеҮҪж•°е‘ўпјҹ

sigmoidе’ҢtanhжҳҜвҖңйҘұе’ҢжҝҖжҙ»еҮҪж•°вҖқпјҢиҖҢReLUеҸҠе…¶еҸҳдҪ“еҲҷжҳҜвҖңйқһйҘұе’ҢжҝҖжҙ»еҮҪж•°вҖқгҖӮдҪҝз”ЁвҖңйқһйҘұе’ҢжҝҖжҙ»еҮҪж•°вҖқзҡ„дјҳеҠҝеңЁдәҺдёӨзӮ№пјҡ(1)"йқһйҘұе’ҢжҝҖжҙ»еҮҪж•°вҖқиғҪи§ЈеҶіжүҖи°“зҡ„вҖңжўҜеәҰж¶ҲеӨұвҖқй—®йўҳгҖӮ(2)е®ғиғҪеҠ еҝ«ж”¶ж•ӣйҖҹеәҰгҖӮ
SigmoidеҮҪж•°е°ҶдёҖдёӘе®һеҖјиҫ“е…ҘеҺӢзј©иҮі[0,1]зҡ„иҢғеӣҙ---------σ(x) = 1 / (1 + exp(−x))
tanhеҮҪж•°е°ҶдёҖдёӘе®һеҖјиҫ“е…ҘеҺӢзј©иҮі [-1, 1]зҡ„иҢғеӣҙ---------tanh(x) = 2σ(2x) − 1
з”ұдәҺдҪҝз”ЁsigmoidжҝҖжҙ»еҮҪж•°дјҡйҖ жҲҗзҘһз»ҸзҪ‘з»ңзҡ„жўҜеәҰж¶ҲеӨұе’ҢжўҜеәҰзҲҶзӮёй—®йўҳпјҢжүҖд»Ҙи®ёеӨҡдәәжҸҗеҮәдәҶдёҖдәӣж”№иҝӣзҡ„жҝҖжҙ»еҮҪж•°пјҢеҰӮпјҡtanhгҖҒReLUгҖҒLeaky ReLUгҖҒPReLUгҖҒRReLUгҖҒELUгҖҒMaxoutгҖӮ
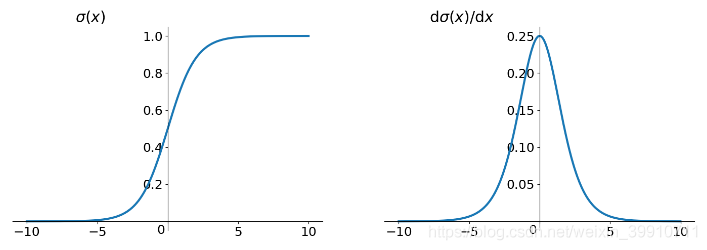
sigmoidзҡ„ж•°еӯҰе…¬ејҸдёә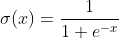
е…¶еҜјж•°е…¬ејҸдёә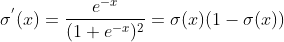
еҰӮдёӢеӣҫжүҖзӨәпјҢе·Ұеӣҫдёәsigmoidзҡ„еҮҪж•°еӣҫпјҢеҸіеӣҫдёәе…¶еҜјж•°еӣҫ.
зү№зӮ№пјҡе®ғиғҪеӨҹжҠҠиҫ“е…Ҙзҡ„иҝһз»ӯе®һеҖјеҸҳжҚўдёә0е’Ң1д№Ӣй—ҙзҡ„иҫ“еҮәпјҢзү№еҲ«зҡ„пјҢеҰӮжһңжҳҜйқһеёёеӨ§зҡ„иҙҹж•°пјҢйӮЈд№Ҳиҫ“еҮәе°ұжҳҜ0пјӣеҰӮжһңжҳҜйқһеёёеӨ§зҡ„жӯЈж•°пјҢиҫ“еҮәе°ұжҳҜ1гҖӮ
еңЁд»Җд№Ҳжғ…еҶөдёӢйҖӮеҗҲдҪҝз”Ё Sigmoid жҝҖжҙ»еҮҪж•°пјҹ
Sigmoid еҮҪж•°зҡ„иҫ“еҮәиҢғеӣҙжҳҜ 0 еҲ° 1гҖӮз”ұдәҺиҫ“еҮәеҖјйҷҗе®ҡеңЁ 0 еҲ° 1пјҢеӣ жӯӨе®ғеҜ№жҜҸдёӘзҘһз»Ҹе…ғзҡ„иҫ“еҮәиҝӣиЎҢдәҶеҪ’дёҖеҢ–пјӣз”ЁдәҺе°Ҷйў„жөӢжҰӮзҺҮдҪңдёәиҫ“еҮәзҡ„жЁЎеһӢгҖӮз”ұдәҺжҰӮзҺҮзҡ„еҸ–еҖјиҢғеӣҙжҳҜ 0 еҲ° 1пјҢеӣ жӯӨ Sigmoid еҮҪж•°йқһеёёеҗҲйҖӮпјӣжўҜеәҰе№іж»‘пјҢйҒҝе…ҚгҖҢи·іи·ғгҖҚзҡ„иҫ“еҮәеҖјпјӣеҮҪж•°жҳҜеҸҜеҫ®зҡ„гҖӮиҝҷж„Ҹе‘ізқҖеҸҜд»ҘжүҫеҲ°д»»ж„ҸдёӨдёӘзӮ№зҡ„ sigmoid жӣІзәҝзҡ„ж–ңзҺҮпјӣжҳҺзЎ®зҡ„йў„жөӢпјҢеҚійқһеёёжҺҘиҝ‘ 1 жҲ– 0гҖӮ
зјәзӮ№пјҡ
е®№жҳ“еҮәзҺ°жўҜеәҰж¶ҲеӨұеҮҪж•°иҫ“еҮә并дёҚжҳҜzero-centeredпјҲйӣ¶еқҮеҖјпјүе№Ӯиҝҗз®—зӣёеҜ№жқҘи®ІжҜ”иҫғиҖ—ж—¶1.жўҜеәҰж¶ҲеӨұ
дјҳеҢ–зҘһз»ҸзҪ‘з»ңзҡ„ж–№жі•жҳҜжўҜеәҰеӣһдј пјҡе…Ҳи®Ўз®—иҫ“еҮәеұӮеҜ№еә”зҡ„ lossпјҢ然еҗҺе°Ҷ loss д»ҘеҜјж•°зҡ„еҪўејҸдёҚж–ӯеҗ‘дёҠдёҖеұӮзҪ‘з»ңдј йҖ’пјҢдҝ®жӯЈзӣёеә”зҡ„еҸӮж•°пјҢиҫҫеҲ°йҷҚдҪҺlossзҡ„зӣ®зҡ„гҖӮ SigmoidеҮҪж•°еңЁж·ұеәҰзҪ‘з»ңдёӯеёёеёёдјҡеҜјиҮҙеҜјж•°йҖҗжёҗеҸҳдёә0пјҢдҪҝеҫ—еҸӮж•°ж— жі•иў«жӣҙж–°пјҢзҘһз»ҸзҪ‘з»ңж— жі•иў«дјҳеҢ–гҖӮеҺҹеӣ еңЁдәҺдёӨзӮ№пјҡ
еҪ“σ(x)дёӯзҡ„xиҫғеӨ§жҲ–иҫғе°Ҹж—¶пјҢеҜјж•°жҺҘиҝ‘0пјҢиҖҢеҗҺеҗ‘дј йҖ’зҡ„ж•°еӯҰдҫқжҚ®жҳҜеҫ®з§ҜеҲҶжұӮеҜјзҡ„й“ҫејҸжі•еҲҷпјҢеҪ“еүҚеұӮзҡ„еҜјж•°йңҖиҰҒд№ӢеүҚеҗ„еұӮеҜјж•°зҡ„д№ҳз§ҜпјҢеҮ дёӘе°Ҹж•°зҡ„зӣёд№ҳпјҢз»“жһңдјҡеҫҲжҺҘиҝ‘0гҖӮSigmoidеҜјж•°зҡ„жңҖеӨ§еҖјжҳҜ0.25пјҢиҝҷж„Ҹе‘ізқҖеҜјж•°еңЁжҜҸдёҖеұӮиҮіе°‘дјҡиў«еҺӢзј©дёәеҺҹжқҘзҡ„1/4пјҢйҖҡиҝҮдёӨеұӮеҗҺиў«еҸҳдёә1/16пјҢ…пјҢйҖҡиҝҮ10еұӮеҗҺдёә1/1048576гҖӮиҜ·жіЁж„ҸиҝҷйҮҢжҳҜвҖңиҮіе°‘вҖқпјҢеҜјж•°иҫҫеҲ°жңҖеӨ§еҖјиҝҷз§Қжғ…еҶөиҝҳжҳҜеҫҲе°‘и§Ғзҡ„гҖӮ2.йӣ¶еқҮеҖј
йӣ¶еқҮеҖјжҳҜдёҚеҸҜеҸ–зҡ„пјҢеӣ дёәиҝҷдјҡеҜјиҮҙеҗҺдёҖеұӮзҡ„зҘһз»Ҹе…ғе°Ҷеҫ—еҲ°дёҠдёҖеұӮиҫ“еҮәзҡ„йқһ0еқҮеҖјзҡ„дҝЎеҸ·дҪңдёәиҫ“е…ҘгҖӮ SigmoidеҮҪж•°зҡ„иҫ“еҮәеҖјжҒ’еӨ§дәҺ0пјҢиҝҷдјҡеҜјиҮҙжЁЎеһӢи®ӯз»ғзҡ„收ж•ӣйҖҹеәҰеҸҳж…ўгҖӮдёҫдҫӢжқҘи®ІпјҢеҜ№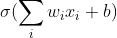 пјҢеҰӮжһңжүҖжңү
пјҢеҰӮжһңжүҖжңү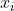 еқҮдёәжӯЈж•°жҲ–иҙҹж•°пјҢйӮЈд№Ҳе…¶еҜ№
еқҮдёәжӯЈж•°жҲ–иҙҹж•°пјҢйӮЈд№Ҳе…¶еҜ№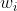 зҡ„еҜјж•°жҖ»жҳҜжӯЈж•°жҲ–иҙҹж•°пјҢиҝҷдјҡеҜјиҮҙеҰӮдёӢеӣҫзәўиүІз®ӯеӨҙжүҖзӨәзҡ„йҳ¶жўҜејҸжӣҙж–°пјҢиҝҷжҳҫ然并йқһдёҖдёӘеҘҪзҡ„дјҳеҢ–и·Ҝеҫ„гҖӮж·ұеәҰеӯҰд№ еҫҖеҫҖйңҖиҰҒеӨ§йҮҸж—¶й—ҙжқҘеӨ„зҗҶеӨ§йҮҸж•°жҚ®пјҢжЁЎеһӢзҡ„收ж•ӣйҖҹеәҰжҳҜе°ӨдёәйҮҚиҰҒзҡ„гҖӮжүҖд»ҘпјҢжҖ»дҪ“дёҠжқҘи®ІпјҢи®ӯз»ғж·ұеәҰеӯҰд№ зҪ‘з»ңе°ҪйҮҸдҪҝз”Ёzero-centeredж•°жҚ® (еҸҜд»Ҙз»ҸиҝҮж•°жҚ®йў„еӨ„зҗҶе®һзҺ°) е’Ңzero-centeredиҫ“еҮәгҖӮ
зҡ„еҜјж•°жҖ»жҳҜжӯЈж•°жҲ–иҙҹж•°пјҢиҝҷдјҡеҜјиҮҙеҰӮдёӢеӣҫзәўиүІз®ӯеӨҙжүҖзӨәзҡ„йҳ¶жўҜејҸжӣҙж–°пјҢиҝҷжҳҫ然并йқһдёҖдёӘеҘҪзҡ„дјҳеҢ–и·Ҝеҫ„гҖӮж·ұеәҰеӯҰд№ еҫҖеҫҖйңҖиҰҒеӨ§йҮҸж—¶й—ҙжқҘеӨ„зҗҶеӨ§йҮҸж•°жҚ®пјҢжЁЎеһӢзҡ„收ж•ӣйҖҹеәҰжҳҜе°ӨдёәйҮҚиҰҒзҡ„гҖӮжүҖд»ҘпјҢжҖ»дҪ“дёҠжқҘи®ІпјҢи®ӯз»ғж·ұеәҰеӯҰд№ зҪ‘з»ңе°ҪйҮҸдҪҝз”Ёzero-centeredж•°жҚ® (еҸҜд»Ҙз»ҸиҝҮж•°жҚ®йў„еӨ„зҗҶе®һзҺ°) е’Ңzero-centeredиҫ“еҮәгҖӮ
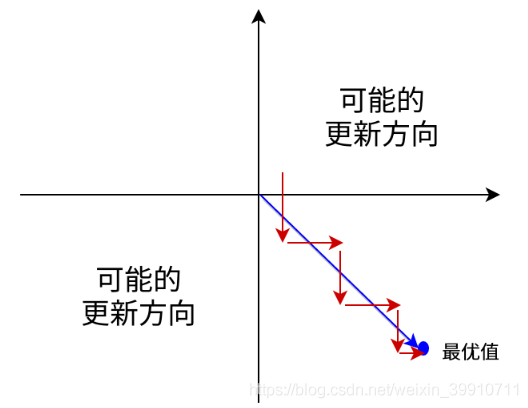
дёҚжҳҜzero-centeredдә§з”ҹзҡ„дёҖдёӘз»“жһңе°ұжҳҜпјҡеҰӮжһңж•°жҚ®иҝӣе…ҘзҘһз»Ҹе…ғзҡ„ж—¶еҖҷжҳҜжӯЈзҡ„
пјҢйӮЈд№Ҳ w и®Ўз®—еҮәзҡ„жўҜеәҰд№ҹдјҡе§Ӣз»ҲйғҪжҳҜжӯЈзҡ„гҖӮеҪ“然дәҶпјҢеҰӮжһңдҪ жҳҜжҢүbatchеҺ»и®ӯз»ғпјҢйӮЈд№ҲйӮЈдёӘbatchеҸҜиғҪеҫ—еҲ°дёҚеҗҢзҡ„дҝЎеҸ·пјҢжүҖд»ҘиҝҷдёӘй—®йўҳиҝҳжҳҜеҸҜд»Ҙзј“и§ЈдёҖдёӢзҡ„гҖӮеӣ жӯӨпјҢйқһ0еқҮеҖјиҝҷдёӘй—®йўҳиҷҪ然дјҡдә§з”ҹдёҖдәӣдёҚеҘҪзҡ„еҪұе“ҚпјҢдёҚиҝҮи·ҹдёҠйқўжҸҗеҲ°зҡ„жўҜеәҰж¶ҲеӨұй—®йўҳзӣёжҜ”иҝҳжҳҜиҰҒеҘҪеҫҲеӨҡзҡ„гҖӮ
3.е№Ӯиҝҗз®—зӣёеҜ№иҖ—ж—¶
зӣёеҜ№дәҺеүҚдёӨйЎ№пјҢиҝҷе…¶е®һ并дёҚжҳҜдёҖдёӘеӨ§й—®йўҳпјҢжҲ‘们зӣ®еүҚжҳҜе…·еӨҮзӣёеә”и®Ўз®—иғҪеҠӣзҡ„пјҢдҪҶйқўеҜ№ж·ұеәҰеӯҰд№ дёӯеәһеӨ§зҡ„и®Ўз®—йҮҸпјҢжңҖеҘҪжҳҜиғҪзңҒеҲҷзңҒгҖӮд№ӢеҗҺжҲ‘们дјҡзңӢеҲ°пјҢеңЁReLUеҮҪж•°дёӯпјҢйңҖиҰҒеҒҡзҡ„д»…д»…жҳҜдёҖдёӘthresholdingпјҢзӣёеҜ№дәҺе№Ӯиҝҗз®—жқҘи®Ідјҡеҝ«еҫҲеӨҡгҖӮ
tanhзҡ„ж•°еӯҰе…¬ејҸдёәпјҡ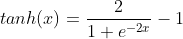
е…¶еҜјж•°дёәпјҡ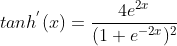
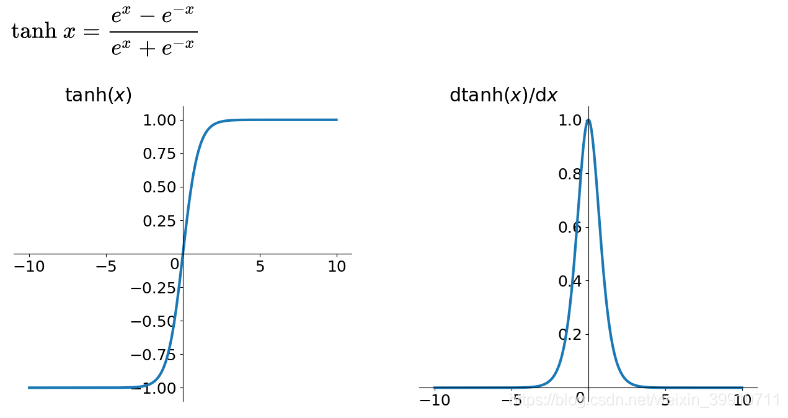
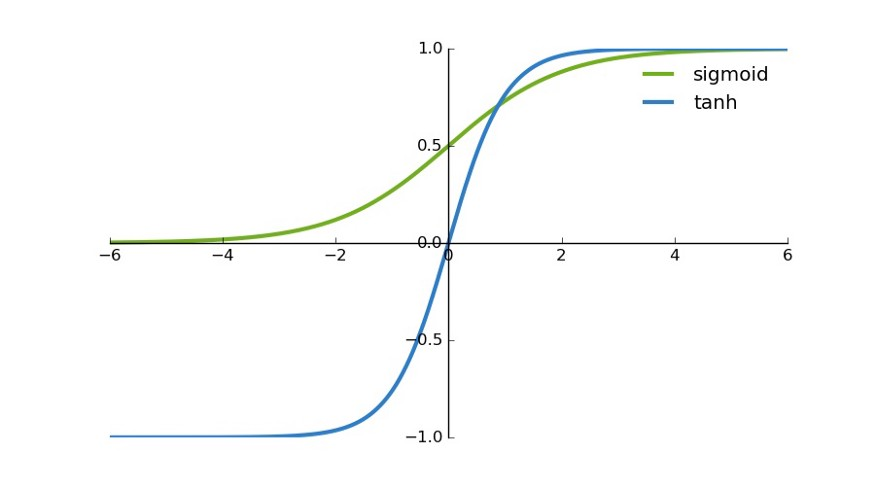
sigmoidдёҺtanhзҡ„жҜ”иҫғ
йҰ–е…ҲпјҢеҪ“иҫ“е…ҘиҫғеӨ§жҲ–иҫғе°Ҹж—¶пјҢиҫ“еҮәеҮ д№ҺжҳҜе№іж»‘зҡ„并且жўҜеәҰиҫғе°ҸпјҢиҝҷдёҚеҲ©дәҺжқғйҮҚжӣҙж–°гҖӮдәҢиҖ…зҡ„еҢәеҲ«еңЁдәҺиҫ“еҮәй—ҙйҡ”пјҢtanh зҡ„иҫ“еҮәй—ҙйҡ”дёә 1пјҢ并且ж•ҙдёӘеҮҪж•°д»Ҙ 0 дёәдёӯеҝғпјҢжҜ” sigmoid еҮҪж•°жӣҙеҘҪпјӣ
еңЁ tanh еӣҫдёӯпјҢиҙҹиҫ“е…Ҙе°Ҷиў«ејәжҳ е°„дёәиҙҹпјҢиҖҢйӣ¶иҫ“е…Ҙиў«жҳ е°„дёәжҺҘиҝ‘йӣ¶гҖӮ
жіЁж„ҸпјҡеңЁдёҖиҲ¬зҡ„дәҢе…ғеҲҶзұ»й—®йўҳдёӯпјҢtanh еҮҪж•°з”ЁдәҺйҡҗи—ҸеұӮпјҢиҖҢ sigmoid еҮҪж•°з”ЁдәҺиҫ“еҮәеұӮпјҢдҪҶиҝҷ并дёҚжҳҜеӣәе®ҡзҡ„пјҢйңҖиҰҒж №жҚ®зү№е®ҡй—®йўҳиҝӣиЎҢи°ғж•ҙгҖӮ
ReLUзҡ„ж•°еӯҰиЎЁиҫҫејҸдёә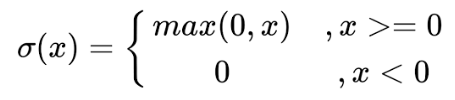
е…¶еҜјж•°е…¬ејҸдёә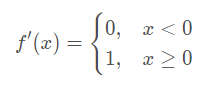
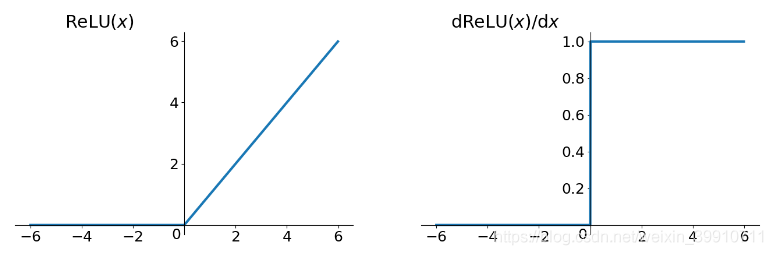
ReLUзҡ„дјҳзӮ№пјҡ
и§ЈеҶідәҶжўҜеәҰж¶ҲеӨұй—®йўҳ (еңЁжӯЈеҢәй—ҙ)пјҢReLUзҡ„йқһйҘұе’ҢжҖ§еҸҜд»Ҙжңүж•Ҳең°и§ЈеҶіжўҜеәҰж¶ҲеӨұзҡ„й—®йўҳпјҢ жҸҗдҫӣзӣёеҜ№е®Ҫзҡ„жҝҖжҙ»иҫ№з•ҢгҖӮSigmoidе’ҢTanhжҝҖжҙ»еҮҪж•°еқҮйңҖиҰҒи®Ўз®—жҢҮж•°пјҢ еӨҚжқӮеәҰй«ҳпјҢ иҖҢReLUеҸӘйңҖиҰҒдёҖдёӘйҳҲеҖјеҚіеҸҜеҫ—еҲ°жҝҖжҙ»еҖјгҖӮReLU еҮҪж•°дёӯеҸӘеӯҳеңЁзәҝжҖ§е…ізі»пјҢеӣ жӯӨе®ғзҡ„и®Ўз®—йҖҹеәҰжҜ” sigmoid е’Ң tanh жӣҙеҝ«гҖӮи®Ўз®—йҖҹеәҰйқһеёёеҝ«пјҢеҸӘйңҖиҰҒеҲӨж–ӯиҫ“е…ҘжҳҜеҗҰеӨ§дәҺ0гҖӮ收ж•ӣйҖҹеәҰиҝңеҝ«дәҺsigmoidе’ҢtanhReLUдҪҝеҫ—дёҖйғЁеҲҶзҘһз»Ҹе…ғзҡ„иҫ“еҮәдёә0пјҢиҝҷж ·е°ұйҖ жҲҗдәҶзҪ‘з»ңзҡ„зЁҖз–ҸжҖ§пјҢ并且еҮҸе°‘дәҶеҸӮж•°зҡ„дә’зӣёдҫқеӯҳе…ізі»пјҢзј“и§ЈдәҶиҝҮжӢҹеҗҲй—®йўҳзҡ„еҸ‘з”ҹ
ReLUеӯҳеңЁзҡ„й—®йўҳ
ReLU еҮҪж•°зҡ„иҫ“еҮәдёә 0 жҲ–жӯЈж•°пјҢдёҚжҳҜzero-centeredеҜ№еҸӮж•°еҲқе§ӢеҢ–е’ҢеӯҰд№ зҺҮйқһеёёж•Ҹж„ҹпјӣReLU еҮҪж•°зҡ„иҫ“еҮәеқҮеҖјеӨ§дәҺ0пјҢеҒҸ移зҺ°иұЎе’ҢзҘһз»Ҹе…ғжӯ»дәЎдјҡе…ұеҗҢеҪұе“ҚзҪ‘з»ңзҡ„收ж•ӣжҖ§гҖӮеӯҳеңЁзҘһз»Ҹе…ғжӯ»дәЎпјҢжҢҮзҡ„жҳҜжҹҗдәӣзҘһз»Ҹе…ғеҸҜиғҪж°ёиҝңдёҚдјҡиў«жҝҖжҙ»пјҢеҜјиҮҙзӣёеә”зҡ„еҸӮж•°ж°ёиҝңдёҚиғҪиў«жӣҙж–°гҖӮиҝҷжҳҜз”ұдәҺеҮҪж•°еҜјиҮҙиҙҹжўҜеәҰеңЁз»ҸиҝҮиҜҘReLUеҚ•е…ғж—¶иў«зҪ®дёә0пјҢ дё”еңЁд№ӢеҗҺд№ҹдёҚиў«д»»дҪ•ж•°жҚ®жҝҖжҙ»пјҢ еҚіжөҒз»ҸиҜҘзҘһз»Ҹе…ғзҡ„жўҜеәҰж°ёиҝңдёә0пјҢ дёҚеҜ№д»»дҪ•ж•°жҚ®дә§з”ҹе“Қеә”гҖӮ еҪ“иҫ“е…Ҙдёәиҙҹж—¶пјҢReLU е®Ңе…ЁеӨұж•ҲпјҢеңЁжӯЈеҗ‘дј ж’ӯиҝҮзЁӢдёӯпјҢиҝҷдёҚжҳҜй—®йўҳгҖӮжңүдәӣеҢәеҹҹеҫҲж•Ҹж„ҹпјҢжңүдәӣеҲҷдёҚж•Ҹж„ҹгҖӮдҪҶжҳҜеңЁеҸҚеҗ‘дј ж’ӯиҝҮзЁӢдёӯпјҢеҰӮжһңиҫ“е…Ҙиҙҹж•°пјҢеҲҷжўҜеәҰе°Ҷе®Ңе…Ёдёәйӣ¶пјҢsigmoid еҮҪж•°е’Ң tanh еҮҪж•°д№ҹе…·жңүзӣёеҗҢзҡ„й—®йўҳгҖӮжңүдёӨдёӘдё»иҰҒеҺҹеӣ еҸҜиғҪеҜјиҮҙиҝҷз§Қжғ…еҶөдә§з”ҹ: (1) йқһеёёдёҚе№ёзҡ„еҸӮж•°еҲқе§ӢеҢ–пјҢиҝҷз§Қжғ…еҶөжҜ”иҫғе°‘и§Ғпјӣ (2) learning rateеӨӘй«ҳеҜјиҮҙеңЁи®ӯз»ғиҝҮзЁӢдёӯеҸӮж•°жӣҙж–°еӨӘеӨ§пјҢдјҡеҜјиҮҙи¶…иҝҮдёҖе®ҡжҜ”дҫӢзҡ„зҘһз»Ҹе…ғдёҚеҸҜйҖҶжӯ»дәЎпјҢ иҝӣиҖҢеҸӮж•°жўҜеәҰж— жі•жӣҙж–°пјҢ ж•ҙдёӘи®ӯз»ғиҝҮзЁӢеӨұиҙҘгҖӮи§ЈеҶіж–№жі•жҳҜеҸҜд»ҘйҮҮз”ЁXavierеҲқе§ӢеҢ–ж–№жі•пјҢд»ҘеҸҠйҒҝе…Қе°Ҷlearning rateи®ҫзҪ®еӨӘеӨ§жҲ–дҪҝз”ЁadagradзӯүиҮӘеҠЁи°ғиҠӮlearning rateзҡ„з®—жі•гҖӮ
жҖҺж ·зҗҶи§ЈReLUпјҲ<0пјүж—¶жҳҜйқһзәҝжҖ§жҝҖжҙ»еҮҪж•°пјҹ
д»ҺеӣҫеғҸеҸҜзңӢеҮәе…·жңүеҰӮдёӢзү№зӮ№пјҡ
еҚ•дҫ§жҠ‘еҲ¶зӣёеҜ№е®Ҫйҳ”зҡ„е…ҙеҘӢиҫ№з•ҢзЁҖз–ҸжҝҖжҙ»жҖ§ReLUеҮҪж•°д»ҺеӣҫеғҸдёҠзңӢпјҢжҳҜдёҖдёӘеҲҶж®өзәҝжҖ§еҮҪж•°пјҢжҠҠжүҖжңүзҡ„иҙҹеҖјйғҪеҸҳдёә0пјҢиҖҢжӯЈеҖјдёҚеҸҳпјҢиҝҷж ·е°ұжҲҗдёәеҚ•дҫ§жҠ‘еҲ¶гҖӮ
еӣ дёәжңүдәҶиҝҷеҚ•дҫ§жҠ‘еҲ¶пјҢжүҚдҪҝеҫ—зҘһз»ҸзҪ‘з»ңдёӯзҡ„зҘһз»Ҹе…ғд№ҹе…·жңүдәҶзЁҖз–ҸжҝҖжҙ»жҖ§гҖӮ
зЁҖз–ҸжҝҖжҙ»жҖ§пјҡд»ҺдҝЎеҸ·ж–№йқўжқҘзңӢпјҢеҚізҘһз»Ҹе…ғеҗҢж—¶еҸӘеҜ№иҫ“е…ҘдҝЎеҸ·зҡ„е°‘йғЁеҲҶйҖүжӢ©жҖ§е“Қеә”пјҢеӨ§йҮҸдҝЎеҸ·иў«еҲ»ж„Ҹзҡ„еұҸи”ҪдәҶпјҢиҝҷж ·еҸҜд»ҘжҸҗй«ҳеӯҰд№ зҡ„зІҫеәҰпјҢжӣҙеҘҪжӣҙеҝ«ең°жҸҗеҸ–зЁҖз–Ҹзү№еҫҒгҖӮеҪ“x<0ж—¶пјҢReLUзЎ¬йҘұе’ҢпјҢеҪ“x>0ж—¶пјҢеҲҷдёҚеӯҳеңЁйҘұе’ҢеҮҪж•°гҖӮReLUиғҪеӨҹеңЁеңЁx>0ж—¶дҝқжҢҒжўҜеәҰдёҚиЎ°еҮҸпјҢд»ҺиҖҢзј“и§ЈжўҜеәҰж¶ҲеӨұй—®йўҳгҖӮ
дәә们дёәдәҶи§ЈеҶіеӨұж•ҲзҘһз»Ҹе…ғпјҢжҸҗеҮәдәҶе°ҶReLUзҡ„еүҚеҚҠж®өи®ҫдёәαxиҖҢйқһ0гҖӮ
Leaky ReLUзҡ„ж•°еӯҰиЎЁиҫҫејҸдёә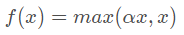
е…¶еҜјж•°е…¬ејҸдёә
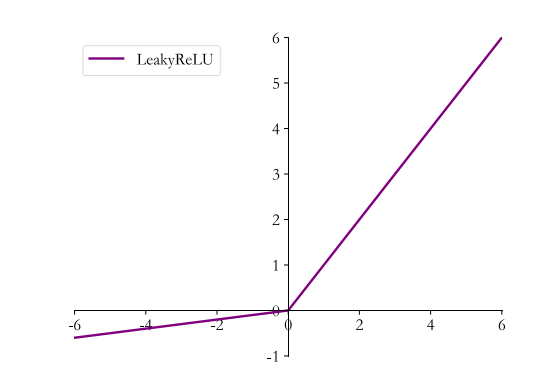
дёәд»Җд№Ҳ Leaky ReLU жҜ” ReLU жӣҙеҘҪпјҹ
Leaky ReLU йҖҡиҝҮжҠҠ x зҡ„йқһеёёе°Ҹзҡ„зәҝжҖ§еҲҶйҮҸз»ҷдәҲиҙҹиҫ“е…ҘпјҲαxпјүжқҘи°ғж•ҙиҙҹеҖјзҡ„йӣ¶жўҜеәҰпјҲzero gradientsпјүй—®йўҳпјӣleak жңүеҠ©дәҺжү©еӨ§ ReLU еҮҪж•°зҡ„иҢғеӣҙпјҢйҖҡеёё a зҡ„еҖјдёә 0.01 е·ҰеҸіпјӣLeaky ReLU зҡ„еҮҪж•°иҢғеӣҙжҳҜпјҲиҙҹж— з©·еҲ°жӯЈж— з©·пјүгҖӮдҪҶеҸҰдёҖж–№йқўпјҢ aеҖјзҡ„йҖүжӢ©еўһеҠ дәҶй—®йўҳйҡҫеәҰпјҢ йңҖиҰҒиҫғејәзҡ„дәәе·Ҙе…ҲйӘҢжҲ–еӨҡж¬ЎйҮҚеӨҚи®ӯз»ғд»ҘзЎ®е®ҡеҗҲйҖӮзҡ„еҸӮж•°еҖјгҖӮ
LeakyReLUдёҺReLUе’ҢPReLUд№Ӣй—ҙеҢәеҲ«
if α=0 пјҢеҲҷеҮҪж•°жҳҜReLUif α>0 пјҢеҲҷеҮҪж•°жҳҜLeaky ReLUif αжҳҜеҸҜеӯҰд№ еҸӮж•°пјҢеҲҷеҮҪж•°жҳҜPReLUпјҲParametric ReLUпјү
ELU зҡ„жҸҗеҮәд№ҹи§ЈеҶідәҶ ReLU зҡ„й—®йўҳгҖӮдёҺ ReLU зӣёжҜ”пјҢELU жңүиҙҹеҖјпјҢиҝҷдјҡдҪҝжҝҖжҙ»зҡ„е№іеқҮеҖјжҺҘиҝ‘йӣ¶гҖӮеқҮеҖјжҝҖжҙ»жҺҘиҝ‘дәҺйӣ¶еҸҜд»ҘдҪҝеӯҰд№ жӣҙеҝ«пјҢеӣ дёәе®ғ们дҪҝжўҜеәҰжӣҙжҺҘиҝ‘иҮӘ然жўҜеәҰгҖӮ

жҳҫ然пјҢELU е…·жңү ReLU зҡ„жүҖжңүдјҳзӮ№пјҢ并且пјҡ
жІЎжңү Dead ReLU й—®йўҳпјҢиҫ“еҮәзҡ„е№іеқҮеҖјжҺҘиҝ‘ 0пјҢд»Ҙ 0 дёәдёӯеҝғпјӣELU йҖҡиҝҮеҮҸе°‘еҒҸзҪ®еҒҸ移зҡ„еҪұе“ҚпјҢдҪҝжӯЈеёёжўҜеәҰжӣҙжҺҘиҝ‘дәҺеҚ•дҪҚиҮӘ然жўҜеәҰпјҢд»ҺиҖҢдҪҝеқҮеҖјеҗ‘йӣ¶еҠ йҖҹеӯҰд№ пјӣELU еңЁиҫғе°Ҹзҡ„иҫ“е…ҘдёӢдјҡйҘұе’ҢиҮіиҙҹеҖјпјҢд»ҺиҖҢеҮҸе°‘еүҚеҗ‘дј ж’ӯзҡ„еҸҳејӮе’ҢдҝЎжҒҜгҖӮдёҖдёӘе°Ҹй—®йўҳжҳҜе®ғзҡ„и®Ўз®—ејәеәҰжӣҙй«ҳгҖӮдёҺ Leaky ReLU зұ»дјјпјҢе°Ҫз®ЎзҗҶи®әдёҠжҜ” ReLU иҰҒеҘҪпјҢдҪҶзӣ®еүҚеңЁе®һи·өдёӯжІЎжңүе……еҲҶзҡ„иҜҒжҚ®иЎЁжҳҺ ELU жҖ»жҳҜжҜ” ReLU еҘҪгҖӮ
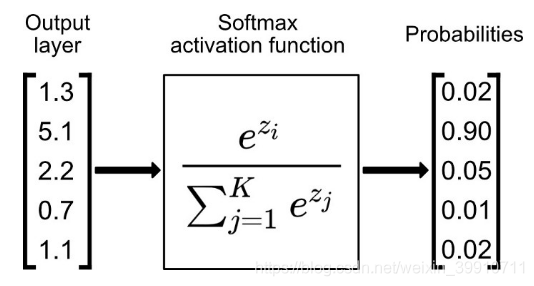
Softmax жҳҜз”ЁдәҺеӨҡзұ»еҲҶзұ»й—®йўҳзҡ„жҝҖжҙ»еҮҪж•°пјҢеңЁеӨҡзұ»еҲҶзұ»й—®йўҳдёӯпјҢи¶…иҝҮдёӨдёӘзұ»ж ҮзӯҫеҲҷйңҖиҰҒзұ»жҲҗе‘ҳе…ізі»гҖӮеҜ№дәҺй•ҝеәҰдёә K зҡ„д»»ж„Ҹе®һеҗ‘йҮҸпјҢSoftmax еҸҜд»Ҙе°Ҷе…¶еҺӢзј©дёәй•ҝеәҰдёә KпјҢеҖјеңЁпјҲ0пјҢ1пјүиҢғ еӣҙеҶ…пјҢ并且еҗ‘йҮҸдёӯе…ғзҙ зҡ„жҖ»е’Ңдёә 1 зҡ„е®һеҗ‘йҮҸгҖӮ
Softmax дёҺжӯЈеёёзҡ„ max еҮҪж•°дёҚеҗҢпјҡmax еҮҪж•°д»…иҫ“еҮәжңҖеӨ§еҖјпјҢдҪҶ Softmax зЎ®дҝқиҫғе°Ҹзҡ„еҖје…·жңүиҫғе°Ҹзҡ„жҰӮзҺҮпјҢ并且дёҚдјҡзӣҙжҺҘдёўејғгҖӮжҲ‘们еҸҜд»Ҙи®Өдёәе®ғжҳҜ argmax еҮҪж•°зҡ„жҰӮзҺҮзүҲжң¬жҲ–гҖҢsoftгҖҚзүҲжң¬гҖӮ
Softmax еҮҪж•°зҡ„еҲҶжҜҚз»“еҗҲдәҶеҺҹе§Ӣиҫ“еҮәеҖјзҡ„жүҖжңүеӣ еӯҗпјҢиҝҷж„Ҹе‘ізқҖ Softmax еҮҪж•°иҺ·еҫ—зҡ„еҗ„з§ҚжҰӮзҺҮеҪјжӯӨзӣёе…ігҖӮ
Softmax жҝҖжҙ»еҮҪж•°зҡ„дё»иҰҒзјәзӮ№жҳҜпјҡ
еңЁйӣ¶зӮ№дёҚеҸҜеҫ®пјӣиҙҹиҫ“е…Ҙзҡ„жўҜеәҰдёәйӣ¶пјҢиҝҷж„Ҹе‘ізқҖеҜ№дәҺиҜҘеҢәеҹҹзҡ„жҝҖжҙ»пјҢжқғйҮҚдёҚдјҡеңЁеҸҚеҗ‘дј ж’ӯжңҹй—ҙжӣҙж–°пјҢеӣ жӯӨдјҡдә§з”ҹж°ёдёҚжҝҖжҙ»зҡ„жӯ»дәЎзҘһз»Ҹе…ғгҖӮ
Swishзҡ„иЎЁиҫҫејҸдёәy = x * sigmoid (x)
Swish зҡ„и®ҫи®ЎеҸ—еҲ°дәҶ LSTM е’Ңй«ҳйҖҹзҪ‘з»ңдёӯ gating зҡ„ sigmoid еҮҪж•°дҪҝз”Ёзҡ„еҗҜеҸ‘гҖӮжҲ‘们дҪҝз”ЁзӣёеҗҢзҡ„ gating еҖјжқҘз®ҖеҢ– gating жңәеҲ¶пјҢиҝҷз§°дёә self-gatingгҖӮ
self-gating зҡ„дјҳзӮ№еңЁдәҺе®ғеҸӘйңҖиҰҒз®ҖеҚ•зҡ„ж ҮйҮҸиҫ“е…ҘпјҢиҖҢжҷ®йҖҡзҡ„ gating еҲҷйңҖиҰҒеӨҡдёӘж ҮйҮҸиҫ“е…ҘгҖӮиҝҷдҪҝеҫ—иҜёеҰӮ Swish д№Ӣзұ»зҡ„ self-gated жҝҖжҙ»еҮҪж•°иғҪеӨҹиҪ»жқҫжӣҝжҚўд»ҘеҚ•дёӘж ҮйҮҸдёәиҫ“е…Ҙзҡ„жҝҖжҙ»еҮҪж•°пјҲдҫӢеҰӮ ReLUпјүпјҢиҖҢж— йңҖжӣҙж”№йҡҗи—Ҹе®№йҮҸжҲ–еҸӮж•°ж•°йҮҸгҖӮ
Swish жҝҖжҙ»еҮҪж•°зҡ„дё»иҰҒдјҳзӮ№еҰӮдёӢпјҡ
гҖҢж— з•ҢжҖ§гҖҚжңүеҠ©дәҺйҳІжӯўж…ўйҖҹи®ӯз»ғжңҹй—ҙпјҢжўҜеәҰйҖҗжёҗжҺҘиҝ‘ 0 并еҜјиҮҙйҘұе’ҢпјӣпјҲеҗҢж—¶пјҢжңүз•ҢжҖ§д№ҹжҳҜжңүдјҳеҠҝзҡ„пјҢеӣ дёәжңүз•ҢжҝҖжҙ»еҮҪж•°еҸҜд»Ҙе…·жңүеҫҲејәзҡ„жӯЈеҲҷеҢ–пјҢ并且иҫғеӨ§зҡ„иҙҹиҫ“е…Ҙй—®йўҳд№ҹиғҪи§ЈеҶіпјүпјӣеҜјж•°жҒ’ > 0пјӣе№іж»‘еәҰеңЁдјҳеҢ–е’ҢжіӣеҢ–дёӯиө·дәҶйҮҚиҰҒдҪңз”ЁгҖӮ
вҖңPythonдёӯеёёз”Ёзҡ„жҝҖжҙ»еҮҪж•°жңүе“ӘдәӣвҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–е°ҶдёәеӨ§е®¶иҫ“еҮәжӣҙеӨҡй«ҳиҙЁйҮҸзҡ„е®һз”Ёж–Үз« пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ