жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
д»ҠеӨ©е°Ҹзј–з»ҷеӨ§е®¶еҲҶдә«дёҖдёӢgo mapжҗ¬иҝҒжҖҺд№Ҳе®һзҺ°зҡ„зӣёе…ізҹҘиҜҶзӮ№пјҢеҶ…е®№иҜҰз»ҶпјҢйҖ»иҫ‘жё…жҷ°пјҢзӣёдҝЎеӨ§йғЁеҲҶдәәйғҪиҝҳеӨӘдәҶи§Јиҝҷж–№йқўзҡ„зҹҘиҜҶпјҢжүҖд»ҘеҲҶдә«иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶еҸӮиҖғдёҖдёӢпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺжңүжүҖ收иҺ·пјҢдёӢйқўжҲ‘们дёҖиө·жқҘдәҶи§ЈдёҖдёӢеҗ§гҖӮ
д»ҘдёӢд»Јз ҒеҹәдәҺgo1.17
жЎ¶з”ЁеӨӘеӨҡ
goз”ЁдәҶдёҖдёӘиҙҹиҪҪеӣ еӯҗloadFactorжқҘиЎЎйҮҸгҖӮд№ҹе°ұжҳҜеҰӮжһңж•°йҮҸcountеӨ§дәҺloadFactor * bucketж•°пјҢйӮЈд№Ҳе°ұиҰҒжү©е®№
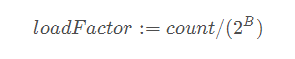
д»Јз ҒеҰӮдёӢ
const (
// Maximum number of key/elem pairs a bucket can hold.
bucketCntBits = 3
bucketCnt = 1 << bucketCntBits
// Maximum average load of a bucket that triggers growth is 6.5.
// Represent as loadFactorNum/loadFactorDen, to allow integer math.
loadFactorNum = 13
loadFactorDen = 2
)
// еңЁе…ғзҙ ж•°йҮҸеӨ§дәҺ8дё”е…ғзҙ ж•°йҮҸеӨ§дәҺиҙҹиҪҪеӣ еӯҗ(6.5)*жЎ¶жҖ»ж•°пјҢе°ұиҰҒиҝӣиЎҢжү©е®№
func overLoadFactor(count int, B uint8) bool {
return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
}overflowеӨӘеӨҡ
overflowеӨӘеӨҡеңЁgoдёӯеҲҶдёӨз§Қжғ…еҶө
bucketж•°йҮҸе°ҸдәҺ1<<15ж—¶пјҢoverflowи¶…иҝҮжЎ¶жҖ»ж•°
bucketж•°йҮҸеӨ§дәҺ1<<15ж—¶пјҢoverflowи¶…иҝҮ1<<15
// overflow buckets еӨӘеӨҡ
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
if B > 15 {
B = 15
}
return noverflow >= uint16(1)<<(B&15)
}еҮҶеӨҮжҗ¬иҝҒе·ҘдҪңжҳҜз”ұhashGrowж–№жі•е®ҢжҲҗзҡ„пјҢд»–дё»иҰҒе°ұжҳҜиҝӣиЎҢз”іиҜ·ж–°bucketsз©әй—ҙгҖҒеҲқе§ӢеҢ–жҗ¬иҝҒиҝӣеәҰдёә0гҖҒе°ҶеҺҹжЎ¶ж Үи®°дёәж—§жЎ¶зӯү
func hashGrow(t *maptype, h *hmap) {
// еҲӨж–ӯжҳҜbucketеӨҡиҝҳжҳҜoverflowеӨҡпјҢ然еҗҺж №жҚ®иҝҷдёӨз§Қжғ…еҶөеҺ»з”іиҜ·ж–°bucketsз©әй—ҙ
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
oldbuckets := h.buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
// commit the grow (atomic wrt gc)
// жӣҙж–°жңҖж–°зҡ„bucketжҖ»ж•°гҖҒе°ҶеҺҹжЎ¶ж Үи®°дёәж—§жЎ¶пјҲеҗҺйқўеҲӨж–ӯжҳҜеҗҰеңЁжҗ¬иҝҒе°ұжҳҜйҖҡиҝҮиҝҷдёӘиҝӣиЎҢеҲӨж–ӯзҡ„пјү
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
// еҲқе§ӢеҢ–жҗ¬иҝҒиҝӣеәҰдёә0
h.nevacuate = 0
// еҲқе§ӢеҢ–ж–°жЎ¶overflowж•°йҮҸдёә0
h.noverflow = 0
// е°ҶеҺҹжқҘextraзҡ„overflowжҢӮиҪҪеҲ°old overflowпјҢд»ЈиЎЁиҝҷе·Із»ҸжҳҜж—§зҡ„дәҶ
if h.extra != nil && h.extra.overflow != nil {
// Promote current overflow buckets to the old generation.
if h.extra.oldoverflow != nil {
throw("oldoverflow is not nil")
}
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
// extraжҢҮеҗ‘дёӢдёҖеқ—з©әй—Ізҡ„overflowз©әй—ҙ
if nextOverflow != nil {
if h.extra == nil {
h.extra = new(mapextra)
}
h.extra.nextOverflow = nextOverflow
}
}жӯЈејҸжҗ¬иҝҒе…¶е®һжҳҜеңЁж·»еҠ гҖҒеҲ йҷӨе…ғзҙ зҡ„ж—¶еҖҷйЎәдҫҝе№Ізҡ„гҖӮеңЁеҸ‘зҺ°жҗ¬иҝҒзҡ„ж—¶еҖҷпјҢе°ұеҸҜиғҪдјҡеҒҡдёҖеҲ°дёӨж¬Ўзҡ„жҗ¬иҝҒпјҢжҜҸж¬Ўжҗ¬иҝҒдёҖдёӘbucketгҖӮе…·дҪ“жҳҜдёҖж¬ЎиҝҳжҳҜдёӨж¬Ўе°ұжҳҜдёӢйқўзҡ„йҖ»иҫ‘еҶіе®ҡзҡ„
жҗ¬иҝҒжӯЈеңЁдҪҝз”Ёзҡ„bucketеҜ№еә”old bucketпјҲеҰӮжһңжІЎжңүжҗ¬иҝҒиҝҮзҡ„иҜқпјү
иӢҘиҝҳжӯЈеңЁжҗ¬иҝҒе°ұеҶҚжҗ¬дёҖдёӘд»ҘеҠ еҝ«жҗ¬иҝҒ
func growWork(t *maptype, h *hmap, bucket uintptr) {
// make sure we evacuate the oldbucket corresponding
// to the bucket we're about to use
evacuate(t, h, bucket&h.oldbucketmask())
// evacuate one more oldbucket to make progress on growing
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}еҜ№дәҺдёҚжү©е®№зҡ„жғ…еҶөпјҢеҸҜиғҪеҸӘжңүдёҖдёӘ——е°ұжҳҜеҺҹжқҘеәҸеҸ·еҜ№еә”зҡ„жЎ¶пјҲе°ұжҳҜдёӢйқўзҡ„xпјүгҖӮ
еҜ№дәҺжү©е®№2еҖҚзҡ„жғ…еҶөпјҢжҳҫ然既жңүеҸҜиғҪжҳҜеңЁеҺҹжқҘеәҸеҸ·еҜ№еә”жЎ¶пјҢд№ҹжңүеҸҜиғҪжҳҜеҺҹжқҘеәҸеҸ·еҠ дёҠжү©е®№зҡ„жЎ¶ж•°зҡ„еәҸеҸ·
жҜ”еҰӮBз”ұ2еҸҳжҲҗдәҶ3пјҢйӮЈд№Ҳе°ұиҰҒзңӢhash第3bitеҲ°еә•жҳҜ0иҝҳжҳҜ1дәҶпјҢеҰӮжһңжҳҜ001пјҢйӮЈд№Ҳе’ҢеҺҹжқҘзҡ„дёҖж ·пјҢжҳҜеәҸеҸ·дёә1зҡ„жЎ¶пјӣеҰӮжһңжҳҜ101пјҢйӮЈд№Ҳе°ұжҳҜеҺҹжқҘеәҸеҸ·1+22 пјҲжү©е®№жЎ¶ж•°пјү=еәҸеҸ·дёә5зҡ„жЎ¶
// xy contains the x and y (low and high) evacuation destinations.
var xy [2]evacDst
x := &xy[0]
x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize)))
x.k = add(unsafe.Pointer(x.b), dataOffset)
x.e = add(x.k, bucketCnt*uintptr(t.keysize))
if !h.sameSizeGrow() {
// Only calculate y pointers if we're growing bigger.
// Otherwise GC can see bad pointers.
y := &xy[1]
// newBitеңЁжү©е®№зҡ„жғ…еҶөдёӢзӯүдәҺ1<<(B-1)
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.e = add(y.k, bucketCnt*uintptr(t.keysize))
}жҜҸдёҖдёӘbucketеңЁжәўеҮәд№ӢеҗҺйғҪдјҡйҷ„жҺҘoverflowжЎ¶пјҢжҜҸдёӘbucketеҢ…жӢ¬overflowеӮЁеӯҳзқҖ8дёӘе…ғзҙ
иӢҘе…ғзҙ tophashдёәз©әпјҢеҲҷиЎЁзӨәиў«жҗ¬иҝҒиҝҮпјҢ继з»ӯдёӢдёҖдёӘ
и®Ўз®—hashеҖј
иӢҘи¶…еҮәеҪ“еүҚbucketе®№йҮҸпјҢе°ұж–°е»әдёҖдёӘoverflow bucket
е°ҶеҺҹжқҘзҡ„keyгҖҒvalueеӨҚеҲ¶еҲ°ж–°bucketж–°дҪҚзҪ®
е®ҡдҪҚеҲ°дёӢдёҖдёӘе…ғзҙ
еңЁдёҠйқўзҡ„жӯҘйӘӨи®Ўз®—hashеҖјеңЁoverflowз”ЁеӨӘеӨҡзҡ„жғ…еҶөдёӢжҳҜдёҚз”Ёзҡ„
жӯӨеӨ–пјҢеңЁжЎ¶з”ЁеӨӘеӨҡзҡ„жғ…еҶөдёӢпјҢи®Ўз®—hash
for ; b != nil; b = b.overflow(t) {
// жүҫеҲ°keyејҖе§ӢдҪҚзҪ®kпјҢе’ҢvalueејҖе§ӢдҪҚзҪ®e
k := add(unsafe.Pointer(b), dataOffset)
e := add(k, bucketCnt*uintptr(t.keysize))
// йҒҚеҺҶbucketдёӯе…ғзҙ иҝӣиЎҢжҗ¬иҝҒ
for i := 0; i < bucketCnt; i, k, e = i+1, add(k, uintptr(t.keysize)), add(e, uintptr(t.elemsize)) {
// иҺ·еҸ–tophashпјҢиӢҘеҸ‘зҺ°жҳҜз©әпјҢиҜҙжҳҺе·Із»Ҹжҗ¬иҝҒиҝҮгҖӮ并ж Үи®°дёәз©әдё”е·Іжҗ¬иҝҒ
top := b.tophash[i]
if isEmpty(top) {
b.tophash[i] = evacuatedEmpty
continue
}
if top < minTopHash {
throw("bad map state")
}
k2 := k
// иӢҘkeyдёәеј•з”Ёзұ»еһӢе°ұи§Јеј•з”Ё
if t.indirectkey() {
k2 = *((*unsafe.Pointer)(k2))
}
// XжҢҮзҡ„е°ұжҳҜеҺҹеәҸеҸ·жЎ¶
// YжҢҮзҡ„е°ұжҳҜжү©е®№жғ…еҶөдёӢпјҢж–°зҡ„жңҖй«ҳдҪҚдёә1зҡ„ж—¶еҖҷеә”иҜҘеҺ»зҡ„жЎ¶
var useY uint8
if !h.sameSizeGrow() {
// Compute hash to make our evacuation decision (whether we need
// to send this key/elem to bucket x or bucket y).
hash := t.hasher(k2, uintptr(h.hash0))
// иӢҘжӯЈеңЁиҝӯд»ЈпјҢдё”keyдёәNaNsгҖӮжҳҜдёҚжҳҜдҪҝз”ЁYе°ұеҸ–еҶіжңҖдҪҺдҪҚжҳҜдёҚжҳҜ1дәҶ
if h.flags&iterator != 0 && !t.reflexivekey() && !t.key.equal(k2, k2) {
useY = top & 1
top = tophash(hash)
} else {
// еҰӮжһңжңҖй«ҳдҪҚдёә1пјҢйӮЈд№Ҳе°ұеә”иҜҘйҖүYжЎ¶
if hash&newbit != 0 {
useY = 1
}
}
}
if evacuatedX+1 != evacuatedY || evacuatedX^1 != evacuatedY {
throw("bad evacuatedN")
}
// ж Үи®°XиҝҳжҳҜYжҗ¬иҝҒпјҢ并дҫқжӯӨиҺ·еҸ–еҲ°жҗ¬иҝҒзӣ®ж ҮжЎ¶
b.tophash[i] = evacuatedX + useY
dst := &xy[useY]
// иӢҘзӣ®ж ҮжЎ¶е·Із»Ҹи¶…еҮәжЎ¶е®№йҮҸпјҢе°ұеҲҶй…Қж–°overflow
if dst.i == bucketCnt {
dst.b = h.newoverflow(t, dst.b)
dst.i = 0
dst.k = add(unsafe.Pointer(dst.b), dataOffset)
dst.e = add(dst.k, bucketCnt*uintptr(t.keysize))
}
// жӣҙж–°е…ғзҙ зӣ®ж ҮжЎ¶еҜ№еә”зҡ„tophash
// йҮҮз”ЁдёҺиҖҢйқһеҸ–жЁЎпјҢеә”иҜҘжҳҜеҮәдәҺжҖ§иғҪзӣ®зҡ„
dst.b.tophash[dst.i&(bucketCnt-1)] = top
// еӨҚеҲ¶keyеҲ°зӣ®ж ҮжЎ¶
if t.indirectkey() {
*(*unsafe.Pointer)(dst.k) = k2 // copy pointer
} else {
typedmemmove(t.key, dst.k, k) // copy elem
}
// еӨҚеҲ¶valueеҲ°зӣ®ж ҮжЎ¶
if t.indirectelem() {
*(*unsafe.Pointer)(dst.e) = *(*unsafe.Pointer)(e)
} else {
typedmemmove(t.elem, dst.e, e)
}
// жӣҙж–°зӣ®ж ҮжЎ¶е…ғзҙ ж•°йҮҸгҖҒkeyгҖҒvalueдҪҚзҪ®
dst.i++
// These updates might push these pointers past the end of the key or elem arrays.
// That's ok, as we have the overflow pointer at the end of the bucket to protect against pointing past the end of the bucket.
dst.k = add(dst.k, uintptr(t.keysize))
dst.e = add(dst.e, uintptr(t.elemsize))
}
}еҰӮжһңеҸ‘зҺ°жІЎжңүеңЁдҪҝз”Ёж—§bucketsзҡ„е°ұжҠҠеҺҹbucketsдёӯзҡ„key-valueжё…зҗҶжҺүеҗ§пјҲtophashиҝҳжҳҜдҝқз•ҷз”ЁжқҘжҗ¬иҝҒж—¶еҲӨж–ӯзҠ¶жҖҒпјү
// Unlink the overflow buckets & clear key/elem to help GC.
if h.flags&oldIterator == 0 && t.bucket.ptrdata != 0 {
// и®Ўз®—еҪ“еүҚеҺҹbucketжүҖеңЁзҡ„ејҖе§ӢдҪҚзҪ®b
b := add(h.oldbuckets, oldbucket*uintptr(t.bucketsize))
// Preserve b.tophash because the evacuation
// state is maintained there.
// д»ҺејҖе§ӢдҪҚзҪ®еҠ дёҠkey-valueзҡ„еҒҸ移йҮҸпјҢйӮЈд№ҲptrжүҖеңЁзҡ„дҪҚзҪ®е°ұжҳҜе®һйҷ…key-valueзҡ„ејҖе§ӢдҪҚзҪ®
ptr := add(b, dataOffset)
// nжҳҜжҖ»bucketеӨ§е°ҸеҮҸеҺ»key-valueзҡ„еҒҸ移йҮҸпјҢе°ұkey-valueеҚ з”Ёз©әй—ҙзҡ„еӨ§е°Ҹ
n := uintptr(t.bucketsize) - dataOffset
// жё…зҗҶд»ҺptrејҖе§Ӣзҡ„nдёӘеӯ—иҠӮ
memclrHasPointers(ptr, n)
}еңЁжң¬ж¬Ўжҗ¬иҝҒиҝӣеәҰжҳҜжңҖж–°иҝӣеәҰзҡ„жғ…еҶөдёӢпјҲдёҚжҳҜжңҖж–°е°ұи®©жңҖж–°зҡ„еҺ»е№Іеҗ§пјү
жӣҙж–°иҝӣеәҰ
е°қиҜ•еҫҖеҗҺзңӢ1024дёӘbucketпјҢеҰӮжһңеҸ‘зҺ°жңүжҗ¬иҝҒе®Ңзҡ„пјҢдҪҶжҳҜжІЎжӣҙж–°иҝӣеәҰе°ұйЎәдҫҝеё®еҲ«дәәжӣҙж–°дәҶ
иӢҘжҳҜе…ЁйғЁbucketйғҪе®ҢжҲҗжҗ¬иҝҒдәҶпјҢйӮЈе°ұзӣҙжҺҘе°ҶеҺҹbucketsйҮҠж”ҫжҺү
func advanceEvacuationMark(h *hmap, t *maptype, newbit uintptr) {
// жӣҙж–°иҝӣеәҰ
h.nevacuate++
// Experiments suggest that 1024 is overkill by at least an order of magnitude.
// Put it in there as a safeguard anyway, to ensure O(1) behavior.
// еҗ‘еҗҺзңӢпјҢжӣҙж–°е·Із»Ҹе®ҢжҲҗзҡ„иҝӣеәҰ
stop := h.nevacuate + 1024
if stop > newbit {
stop = newbit
}
for h.nevacuate != stop && bucketEvacuated(t, h, h.nevacuate) {
h.nevacuate++
}
// иӢҘжҳҜе®ҢжҲҗжҗ¬иҝҒпјҢе°ұйҮҠж”ҫжҺүold bucketsгҖҒйҮҚзҪ®жҗ¬иҝҒзҠ¶жҖҒгҖҒйҮҠж”ҫеҺҹbucketжҢӮиҪҪеҲ°extraзҡ„overflowжҢҮй’Ҳ
if h.nevacuate == newbit { // newbit == # of oldbuckets
// Growing is all done. Free old main bucket array.
h.oldbuckets = nil
// Can discard old overflow buckets as well.
// If they are still referenced by an iterator,
// then the iterator holds a pointers to the slice.
if h.extra != nil {
h.extra.oldoverflow = nil
}
h.flags &^= sameSizeGrow
}
}д»ҘдёҠе°ұжҳҜвҖңgo mapжҗ¬иҝҒжҖҺд№Ҳе®һзҺ°вҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒзӣёдҝЎеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« йғҪжңүеҫҲеӨ§зҡ„收иҺ·пјҢе°Ҹзј–жҜҸеӨ©йғҪдјҡдёәеӨ§е®¶жӣҙж–°дёҚеҗҢзҡ„зҹҘиҜҶпјҢеҰӮжһңиҝҳжғіеӯҰд№ жӣҙеӨҡзҡ„зҹҘиҜҶпјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ