您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
Ganglia 是UC Berkeley发起的一个开源监视项目,设计用于测量数以千计的节点。每台计算机都运行一个收集和发送度量数据(如处理器速度、内存使用量等)的名为gmond的守护进程。它将从操作系统和指定主机中收集。接收所有度量数据的主机可以显示这些数据并且可以将这些数据的精简表单传递到层次结构中。正因为有这种层次结构模式,才使得Ganglia 可以实现良好的扩展。gmond带来的系统负载非常少,这使得它成为在集群中各台计算机上运行的一段代码,而不会影响用户性能。
所有这些数据收集会多次影响节点性能。网络中的 “抖动(Jitter)” 发生在大量小消息同时出现时。我们发现通过将节点时钟保持一致,就可以避免这个问题。
RRDTool 表示:轮循数据库工具(Round Robin Database Tool)。它是由Tobias Oetiker创建的,并且为许多高性能监视工具提供了引擎。Ganglia是其中之一,但是Cacti 和Zenoss 是另外两个。
要安装 Ganglia,首先需要让RRDTool 运行在监视服务器上。RRDTool将提供其他程序使用的两个非常优秀的功能:
它将在轮循数据库中存储数据。随着捕捉的数据变得越来越旧,解析的精确性将变得越来越低。这将占用很少的内存并且在大多数情况下仍然有用。
它可以通过使用命令行实参根据捕捉的数据生成图形。
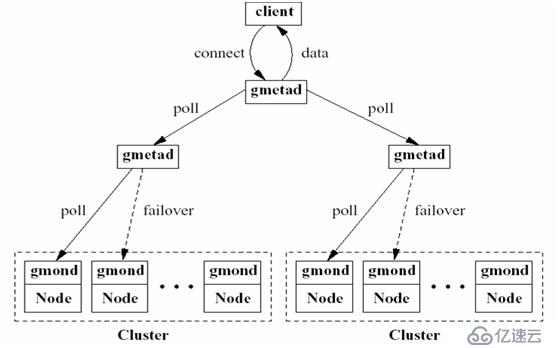
工作原理图
Ganglia的核心包含gmetad、gmond以及一个Web前端。主要是用来监控系统性能,如:cpu、mem、硬盘利用率,I/O负载、网络流量情况等,通过曲线很容易见到每个节点的工作状态,对合理调整、分配系统资源,提高系统整体性能起到重要作用。
gmetad可以部署在集群内任一台节点或者通过网络连接到集群的独立主机,它通过单播路由的方式与gmond通信,收集区域内节点的状态信息,并以XML数据的形式,保存在数据库中。
每台计算机都运行一个收集和发送度量数据的名为gmond(带来的系统负载非常少)的守护进程。
由RRDTool工具处理数据,并生成相应的的图形显示,以Web方式直观的提供给客户端。
安装软件包依赖性
yum install -y libart_lgpl_devel gcc gcc-c++ python-devel pcre-devel expat-devel rrdtool-devel apr-devel rpm-build
rpm -ivh libconfuse-2.6-3.el6.x86_64.rpm libconfuse-devel-2.6-3.el6.x86_64.rpm
rpmbuild -tb ganglia-3.3.7.tar.gz cd /root/rpmbuild/RPMS/x86_64 //放有ganglia源码包rpmbuild的包5个 ganglia-devel-3.6.0-1.x86_64.rpm ganglia-gmetad-3.6.0-1.x86_64.rpm ganglia-gmond-3.6.0-1.x86_64.rpm ganglia-gmond-modules-python-3.6.0-1.x86_64.rpm libganglia-3.6.0-1.x86_64.rpm
rpm -ivh *
vi /etc/ganglia/gmond.conf
cluster {
name = "my cluster"
owner = "unspecified"
latlong = "unspecified"
url = "unspecified"
}service gmetad start
service gmond start
rpmbuild -tb ganglia-web-3.4.2.tar.gz
cd /root/rpmbuild/RPMS/noarch
ganglia-web-3.5.10-1.noarch.rpm
yum localinstall ganglia-web-3.5.10-1.noarch.rpm (默认安装路径是/var/www/html/ganglia)
/etc/init.d/httpd restart //现在就可以用打开ganglia-web(http://ip/ganglia)查看本机检测信息
此时本机是server+client,若想再监测其他主机,须在其上安装以下包:
ganglia-gmond-3.6.0-1.x86_64.rpm
ganglia-gmond-modules-python-3.6.0-1.x86_64.rpm
libganglia-3.6.0-1.x86_64.rpm
libconfuse-2.6-3.el6.x86_64.rpm
vi /etc/ganglia/gmond.conf //和上边修改一样
/etc/init.d/gmond start
现在可以重新启动 gmetad,刷新Web 浏览器,然后应当会看到节点现在出现在列表中
进入/var/lib/ganglia/rrds目录,可以看到每个主机的度量指标,生成了易于查看的图形.
-------------------------------------------------------------
ganglia+nagios整合:
Ganglia 和Nagios,这是两个用于监视数据中心的工具。这两个工具被大量用于高性能计算(HPC)环境中,但是它们对于其他环境也具有很大的吸引力(例如云、呈
现集群和托管中心)。此外,两者对监视的定义也采取了不同的侧重点。Ganglia更多地与收集度量数据并随时跟踪这些数据有关,而Nagios 一直致力于成为一种报警机制。
tar zxf ganglia-3.6.0.tar.gz
cd ganglia-3.6.0/contrib
./check_ganglia.py -h ip -m disk_free -w 20 -c 10 //-h后根检测主机的ip或hostname,-m后跟要监测的对象,-w、-c指定警告和紧急的阀值
cp /ganglia-3.1.7/contrib/check_ganglia.py /usr/local/nagios/libexec 注:ganglia与nagios可以部署在不同的主机
vi /usr/local/nagios/libexec/check_ganglia.py //注意此处格式要求严格 if critical > warning: if value >= critical: print "CHECKGANGLIA CRITICAL: %s is %.2f" % (metric,value) sys.exit(2) elif value >= warning: print "CHECKGANGLIA WARNING: %s is %.2f" % (metric,value) sys.exit(1) else: print "CHECKGANGLIA OK: %s is %.2f" % (metric,value) sys.exit(0) else: if critical >= value: print "CHECKGANGLIA CRITICAL: %s is %.2f" % (metric,value) sys.exit(2) elif warning >= value: print "CHECKGANGLIA WARNING: %s is %.2f" % (metric,value) sys.exit(1) else: print "CHECKGANGLIA OK: %s is %.2f" % (metric,value) sys.exit(0)
chown nagios.nagios check_ganglia.py
配置nagios:
vi /usr/local/nagios/etc/objects/commands.cfg
define command {
command_name check_ganglia
command_line $USER1$/check_ganglia.py -h $HOSTNAME$ -m $ARG1$ -w $ARG2$ -c $ARG3$
}
vi /usr/local/nagios/etc/objects/templates.cfg
define service {
use generic-service
name ganglia-service
hostgroup_name ganglia-servers
service_groups ganglia-metrics
}
vi /usr/local/nagios/etc/objects/hosts.cfg
define host {
use linux-server
host_name ty2.org
address 192.168.0.21
}
define hostgroup {
hostgroup_name ganglia-servers
alias ganglia-servers
members ty2.org //hostgroup中的members必须要有host定义匹配
}
vi services.cfg
define service{
use ganglia-service
service_description 根分区
check_command check_ganglia!disk_free_percent_rootfs!20!10
}
define service{
use ganglia-service
service_description 系统负载
check_command check_ganglia!load_one!4!5
}
define service{
use ganglia-service
service_description 内存空闲
check_command check_ganglia!mem_free!50000!30000
}
define servicegroup {
servicegroup_name ganglia-metrics
alias Ganglia Metrics
}
/usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfg
/etc/init.d/nagios reload
监控成功,nagios下就可以看见ganglia监测主机的信息
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。