жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
дҪңдёәDBAпјҢжңүж—¶дјҡиў«жҢ‘жҲҳзұ»дјјиҝҷж ·зҡ„й—®йўҳпјҡ
йқўеҜ№иҜёеҰӮдёҠйқўзҡ„иҝҷдәӣиҙЁз–‘пјҢDBAеә”иҜҘеҰӮдҪ•йқўеҜ№пјҹ
иә«дёәDBAиҜҘеҰӮдҪ•иҜ„дј°зҺ°жңүиө„жәҗдҪҝз”Ёжғ…еҶөпјҹ
еҰӮжһңзҺ°жңүж•°жҚ®еә“иө„жәҗзЎ®е®һж— жі•ж”Ҝж’‘пјҢеҸҲиҜҘжң¬зқҖд»Җд№ҲеҺҹеҲҷиҝӣиЎҢж”№йҖ е‘ўпјҹ
жң¬ж–ҮжҳҜй’ҲеҜ№дёҠйқўй—®йўҳзҡ„дёҖдәӣз»ҸйӘҢжҖ»з»“пјҢдҫӣеӨ§е®¶еҸӮиҖғгҖӮ
йқўеҜ№иҝҷж ·зҡ„й—®йўҳпјҢйҰ–е…ҲиҰҒиҝӣиЎҢиҜ„дј°е·ҘдҪңпјҢеҸҜйҒөеҫӘдёӢйқўзҡ„жӯҘйӘӨпјҡ
й’ҲеҜ№зі»з»ҹиҝҗиЎҢзҺ°зҠ¶пјҢе»әз«ӢжҖ§иғҪеҹәзәҝгҖӮе°ҶдёҡеҠЎжҢҮж ҮдёҺжҖ§иғҪжҢҮж Үе»әз«Ӣиө·еҜ№еә”е…ізі»гҖӮиҝҷйҮҢжүҖиҜҙзҡ„жҖ§иғҪжҢҮж ҮеҢ…жӢ¬CPUгҖҒMEMгҖҒDISKгҖҒNETзӯүгҖӮеңЁиҜёеӨҡиө„жәҗдёӯпјҢиӮҜе®ҡеӯҳеңЁдёҚеқҮиЎЎзҡ„жғ…еҶөпјҢзҹӯжқҝзҡ„иө„жәҗжңҖжңүеҸҜиғҪжҲҗдёәдёҡеҠЎеўһй•ҝеҗҺзҡ„瓶йўҲгҖӮеңЁе…·дҪ“ж“ҚдҪңдёҠпјҢеҸҜйҰ–е…ҲзЎ®е®ҡдёҖдёӘдёҡеҠЎй«ҳеі°ж—¶й—ҙж®өпјҢйҖҡиҝҮзӣ‘жҺ§е№іеҸ°жҲ–зӣ‘жҺ§е·Ҙ具收йӣҶзі»з»ҹеҗ„иө„жәҗзҡ„дҪҝз”Ёжғ…еҶөгҖӮ然еҗҺдҫқжҚ®ж”¶йӣҶзҡ„дҝЎжҒҜпјҢеҲҶжһҗеҸҜиғҪзҡ„жҖ§иғҪзҹӯжқҝеңЁе“ӘйҮҢгҖӮ
еҜ№дәҺDBAжқҘиҜҙпјҢеҜ№иҮӘе·ұжҺҢз®Ўзі»з»ҹзҡ„жҖ§иғҪдҪҝз”Ёжғ…еҶөиҰҒдәҶ然дәҺиғёгҖӮйҖҡиҝҮеҜ№дёҡеҠЎзҡ„дәҶи§ЈпјҢе°ҶдёҡеҠЎжҢҮж Үжҳ е°„еҲ°жҖ§иғҪжҢҮж ҮдёҠпјҢе°ұеҸҜд»ҘеҫҲе®№жҳ“ең°жҺЁж–ӯеҮәзҺ°жңүзі»з»ҹеҸҜжүҝиҪҪзҡ„жңҖеӨ§дёҡеҠЎйҮҸгҖӮжӯӨеӨ–пјҢеҜ№дәҺеҸҜиғҪеҪұе“ҚжүҝиҪҪдёҡеҠЎеўһй•ҝзҡ„зҹӯжқҝпјҢд№ҹдјҡжңүжҜ”иҫғжё…жҷ°зҡ„и®ӨиҜҶгҖӮ
дёҖиҲ¬жқҘиҜҙпјҢж•°жҚ®еә“зұ»зҡ„еә”з”ЁжҳҜйҮҚиө„жәҗж¶ҲиҖ—зұ»зҡ„еә”з”ЁгҖӮеҜ№CPUгҖҒMEMгҖҒDISKгҖҒNETзӯүпјҢеқҮжңүиҫғеӨ§зҡ„ж¶ҲиҖ—гҖӮдҪҶз”ұдәҺдёҚеҗҢ硬件еҸ‘еұ•ж°ҙе№ідёҚеқҮиЎЎпјҢеҗ„ж•°жҚ®еә“иө„жәҗж¶ҲиҖ—зү№зӮ№д№ҹдёҚеҗҢпјҢеӣ жӯӨйңҖиҰҒе…·дҪ“й—®йўҳе…·дҪ“еҲҶжһҗгҖӮ
дёӢйқўи°Ҳи°ҲжҲ‘еҜ№зЎ¬д»¶еҸ‘еұ•еҸҠдёҺж•°жҚ®еә“е…ізі»зҡ„дёҖзӮ№дёӘдәәи§ӮзӮ№:
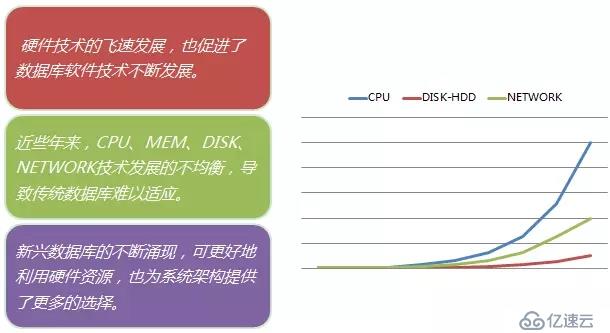
зӣёеҜ№дәҺ其他硬件иҖҢиЁҖпјҢCPUжҠҖжңҜеҸ‘еұ•иҫғеҝ«гҖӮйҡҸзқҖCPUдё»йў‘жҸҗй«ҳеҸҠеӨҡж ёCPUжҠҖжңҜзҡ„еҸ‘еұ•пјҢCPUжҸҗдҫӣзҡ„и®Ўз®—иғҪеҠӣеҫҖеҫҖдёҚдјҡжҲҗдёәзі»з»ҹзҡ„жҖ§иғҪ瓶йўҲгҖӮдҪҶжҲ‘们йңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢжңүдәӣж•°жҚ®еә“жҳҜж— жі•е®Ңе…ЁеҲ©з”ЁCPUзҡ„иғҪеҠӣ(дҫӢеҰӮMySQLе°ұжҳҜиҝҷж ·)гҖӮжӯӨж—¶пјҢдёәдәҶе……еҲҶеҲ©з”ЁCPUзҡ„иө„жәҗпјҢеҸҜд»ҘиҖғиҷ‘иҜёеҰӮ"еӨҡе®һдҫӢж··и·‘"зҡ„ж–№жЎҲпјҢжҸҗй«ҳCPUеҲ©з”ЁзҺҮгҖӮ
йҡҸзқҖеҶ…еӯҳжҠҖжңҜзҡ„еҸ‘жҢҘпјҢеҶ…еӯҳзҡ„д»·ж ји¶ҠжқҘи¶Ҡдҫҝе®ңгҖӮзҺ°еңЁжҲ‘们еңЁз”ҹдә§зҺҜеўғдёӯпјҢеҸҜд»Ҙи§ҒеҲ°128гҖҒ256GBпјҢз”ҡиҮіTBзә§зҡ„еҶ…еӯҳд№ҹдёҚзҪ•и§ҒгҖӮдёҖиҲ¬жқҘиҜҙпјҢж•°жҚ®еә“йҖҡеёёдјҡеҲ©з”ЁеҶ…еӯҳдҪңдёәзј“еҶІеҢәпјҢеӨ§еҶ…еӯҳзҡ„й…ҚзҪ®еҜ№ж•°жҚ®еә“зҡ„жҖ§иғҪжңүзқҖжҜ”иҫғжҳҺжҳҫзҡ„жҸҗеҚҮгҖӮжӯӨеӨ–пјҢж•°жҚ®еә“иҮӘиә«жҠҖжңҜд№ҹеңЁйҖӮеә”зқҖеӨ§еҶ…еӯҳзҡ„еңәжҷҜпјҢйҖҡеёёйҮҮз”Ёзҡ„зӯ–з•ҘжҳҜеҲ’еҲҶеӯҗжұ гҖӮе°Ҷз®ЎзҗҶзҡ„еҚ•дҪҚиҝӣдёҖжӯҘз»ҶеҲҶпјҢдҫӢеҰӮOracleдёӯзҡ„Sub PoolгҖҒMySQLдёӯзҡ„еӨҡinstance buffer poolгҖӮ
йҡҸзқҖGigEгҖҒ10GbEгҖҒInfiniBandжҠҖжңҜзҡ„йЈһйҖҹеҸ‘еұ•пјҢдҪҺ延иҝҹгҖҒй«ҳеёҰе®Ҫзҡ„жңҚеҠЎе“ҒиҙЁз»ҷж•°жҚ®еә“д№ғиҮіж•ҙдёӘITзі»з»ҹеёҰжқҘдәҶеҫҲеӨҡеҸҳеҢ–гҖӮеёёи§Ғзҡ„еә”з”ЁйўҶеҹҹжңүпјҡ
еҠ йҖҹеҲҶеёғејҸж•°жҚ®еә“пјҢдҫӢеҰӮOracle RACгҖӮ
еҠ йҖҹеӨ§ж•°жҚ®еӨ„зҗҶпјҢдҫӢеҰӮжҸҗеҚҮHadoop MapReduceеӨ„зҗҶгҖӮ
еӯҳеӮЁжһ¶жһ„зҡ„еҸҳйқ©пјҢд»ҺScale-Upеҗ‘Scale-Outжј”еҸҳгҖӮ
зӣёеҜ№дәҺ其他硬件жҠҖжңҜеҸ‘еұ•иҖҢиЁҖпјҢдј з»ҹзҡ„жңәжў°ејҸзЈҒзӣҳжҳҜзӣёеҜ№иҖҢиЁҖеҸ‘еұ•жңҖж…ўзҡ„пјҢе…¶еҫҖеҫҖд№ҹжҳҜжңҖе®№жҳ“жҲҗдёәж•°жҚ®еә“зҡ„жҖ§иғҪ瓶йўҲгҖӮйҡҸзқҖй—ӘеӯҳжҠҖжңҜзҡ„жЁӘз©әеҮәдё–пјҢдёәеӯҳеӮЁжҠҖжңҜеёҰжқҘзҡ„дёҖз§ҚеҸҳйқ©гҖӮдёӢйқўжҲ‘们жқҘзңӢзңӢдё»иҰҒжҖ§иғҪжҢҮж Үзҡ„еҜ№жҜ”пјҡ
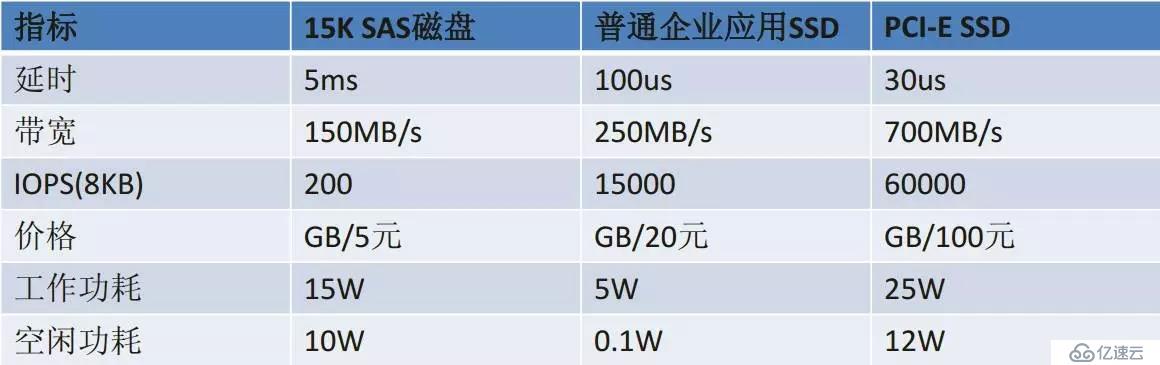
д»ҺдёҠиҝ°жҢҮж ҮжқҘзңӢпјҢдҪҝз”Ёй—ӘеӯҳжҠҖжңҜеҗҺпјҢеӯҳеӮЁиғҪеҠӣеӨ§еӨ§жҸҗй«ҳпјҢж¶ҲйҷӨдәҶзі»з»ҹжңҖеӨ§зҡ„瓶йўҲгҖӮиҝҷд№ҹжҳҜдёәд»Җд№ҲеҫҲеӨҡDBAйғҪеңЁдёҚеҗҢеңәеҗҲпјҢеӨ§еҠӣжҺЁиҚҗдҪҝз”Ёй—ӘеӯҳпјҢе…¶еҜ№дәҺж•°жҚ®еә“жҖ§иғҪзҡ„жҸҗеҚҮдјҡеёҰжқҘиҙЁзҡ„йЈһи·ғгҖӮдҪҶдёҺжӯӨеҗҢж—¶пјҢжҲ‘们д№ҹеә”иҜҘжіЁж„ҸеҲ°пјҢдј з»ҹе…ізі»еһӢж•°жҚ®еә“жҳҜжҢүз…§зЈҒзӣҳIOжЁЎеһӢи®ҫи®Ўзҡ„пјҢжІЎжңүиҖғиҷ‘еҲ°й—ӘеӯҳжҠҖжңҜпјҢзҺ°еңЁеұһдәҺиҪҜ件иҗҪеҗҺдәҺ硬件зҡ„йҳ¶ж®өпјӣзӣёеҜ№иҖҢиЁҖпјҢй—ӘеӯҳжҠҖжңҜеҜ№дәҺйқһе…ізі»еһӢжЁЎеһӢжӣҙжңүдјҳеҠҝгҖӮ
еҫҲеӨҡеҹәдәҺдј з»ҹи®ҫи®Ўзҡ„дјҳеҢ–зҗҶи®әеҸ‘з”ҹдәҶеҸҳеҢ–пјҢдҫӢеҰӮ: зҙўеј•иҒҡз°Үеӣ еӯҗзҡ„й—®йўҳгҖӮиҝҷдёҖзӮ№жҳҜйңҖиҰҒжҲ‘们еңЁиҖғиҷ‘ж•°жҚ®еә“дјҳеҢ–ж—¶пјҢдё»иҰҒжіЁж„Ҹзҡ„гҖӮжӯӨеӨ–пјҢNoSQLзҡ„жҖ§иғҪдјҳеҠҝеӣ дёәдј з»ҹж•°жҚ®еә“з»“еҗҲй—ӘеӯҳжҠҖжңҜпјҢиҖҢеҸҳеҫ—дёҚжҳҺжҳҫгҖӮйңҖиҰҒеңЁжһ¶жһ„йҖүжӢ©ж—¶еҠ д»ҘеҲҶжһҗгҖӮ
ж №жҚ®дёҡеҠЎзү№еҫҒпјҢе»әз«ӢдёҡеҠЎеҺӢеҠӣжЁЎеһӢгҖӮз®ҖеҚ•зҗҶи§Је°ұжҳҜе°ҶдёҡеҠЎжЁЎжӢҹжҠҪиұЎеҮәжқҘпјҢдҫҝдәҺеҗҺйқўиҝӣиЎҢеҺӢеҠӣж”ҫеӨ§жөӢиҜ•гҖӮиҰҒеҒҡеҲ°иҝҷдёҖжӯҘпјҢйңҖиҰҒеҜ№дёҡеҠЎжңүзқҖе……еҲҶзҡ„дәҶи§Је’ҢиҜ„дј°гҖӮ
дёӢйқўйҖҡиҝҮдёҖдёӘе°ҸдҫӢеӯҗиҜҙжҳҺдёҖдёӢ:
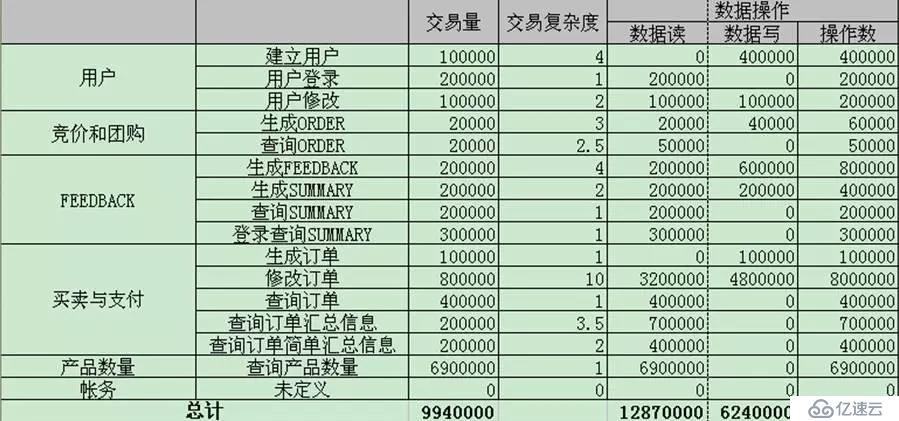
иҝҷдёӘиЎЁж јжЁЎжӢҹдәҶжҹҗдёӘзұ»з”өе•Ҷзҡ„дёҡеҠЎпјҢе…¶еҢ…еҗ«зҡ„дё»иҰҒжЁЎеқ—еҸҠжЁЎеқ—дёӯзҡ„дё»иҰҒж“ҚдҪңгҖӮй’ҲеҜ№дёҚеҗҢзҡ„ж“ҚдҪңе…¶дәӨжҳ“еӨҚжқӮеәҰдёҚеҗҢ пјҲдәӨжҳ“еӨҚжқӮеәҰеҸҜзҗҶи§Јдёәжү§иЎҢSQLиҜӯеҸҘзҡ„дёӘж•°пјүгҖӮж №жҚ®дёҚеҗҢзҡ„иҜ»еҶҷжғ…еҶөпјҢеҢәеҲҶжҳҜж•°жҚ®иҜ»иҝҳжҳҜж•°жҚ®еҶҷгҖӮеңЁдј°з®—дәҶдёҡеҠЎжҖ»йҮҸ(дәӨжҳ“йҮҸ)зҡ„жғ…еҶөдёӢпјҢеҫҲе®№жҳ“жҺЁз®—еҮәж•°жҚ®ж“ҚдҪңзҡ„йҮҸгҖӮйҖҡиҝҮиҝҷз§Қж–№ејҸе°ҶдёҡеҠЎеҺӢеҠӣжЁЎеһӢиҪ¬еҢ–дёәж•°жҚ®еҺӢеҠӣжЁЎеһӢгҖӮжӯӨеӨ„зҡ„йҡҫзӮ№еңЁдәҺеҜ№дёҡеҠЎйҖ»иҫ‘зҡ„жҠҪиұЎиғҪеҠӣеҸҠеҜ№жЁЎеқ—дёҡеҠЎйҮҸзҡ„жҜ”дҫӢиҜ„дј°гҖӮ
жңүдәҶдёҠиҝ°жҰӮи§Ҳзҡ„иЎЁж јеҗҺпјҢй’ҲеҜ№жҜҸдёҖз§ҚдёҡеҠЎж“ҚдҪңпјҢеҸҜз»ҶеҢ–е…¶ж“ҚдҪңгҖӮжңҖз»Ҳе°Ҷе…¶жҠҪиұЎжҲҗSQLиҜӯеҸҘеҸҠеҜ№еә”зҡ„и®ҝй—®зү№еҫҒгҖӮе…¶дјӘд»Јз ҒеҸҜжҸҸиҝ°дёә

еҸҜдҫқжҚ®дёҠиҝ°дјӘд»Јз ҒпјҢзј–еҲ¶еҺӢеҠӣжөӢиҜ•д»Јз ҒгҖӮйҖҡиҝҮдёҖдәӣе·Ҙе…·и°ғз”ЁжөӢиҜ•д»Јз ҒпјҢдә§з”ҹжЁЎжӢҹжөӢиҜ•зҡ„еҺӢеҠӣгҖӮдҫӢеҰӮжҲ‘з»ҸеёёдҪҝз”Ёзҡ„oradbtest/mydbtest(еҺҹйҳҝйҮҢжҘјж–№й‘«зҡ„дёҖдёӘжөӢиҜ•е·Ҙе…·)жҲ–sysbenchзӯүпјҢйғҪжҳҜдёҚй”ҷзҡ„еҺӢеҠӣжөӢиҜ•е·Ҙе…·гҖӮ
е»әи®®дјҒдёҡж №жҚ®иҮӘиә«жғ…еҶөпјҢж•ҙзҗҶеҮәиҮӘе·ұзҡ„дёҡеҠЎеҺӢеҠӣжЁЎеһӢгҖӮиҝҷеңЁзі»з»ҹж”№йҖ гҖҒеҚҮзә§гҖҒжү©е®№иҜ„дј°гҖҒ新硬件йҖүеһӢзӯүеӨҡз§ҚеңәеҗҲйғҪеҫҲжңүз”ЁеӨ„гҖӮе®ғиҰҒжҜ”еҺӮе•ҶжҸҗдҫӣзҡ„зұ»дјјTPCCжөӢиҜ•жҠҘе‘ҠпјҢжӣҙжңүж„Ҹд№үгҖӮжҚ®жҲ‘дәҶи§ЈпјҢеҫҲеӨҡ规模иҫғеӨ§зҡ„е…¬еҸёйғҪжңүжҜ”иҫғжҲҗзҶҹзҡ„еҺӢеҠӣжЁЎеһӢгҖӮ
иҰҒжғіиҖғеҜҹзҺ°жңүж•°жҚ®еә“иғҪеҗҰжүҝиҪҪеўһй•ҝеҗҺзҡ„дёҡеҠЎеҺӢеҠӣпјҢжңҖеҘҪзҡ„ж–№ејҸе°ұжҳҜжЁЎжӢҹеҺӢеҠӣжөӢиҜ•гҖӮи§ӮеҜҹеңЁиҝ‘дјјзңҹе®һзҡ„еҺӢеҠӣдёӢпјҢж•°жҚ®еә“зҡ„иЎЁзҺ°гҖӮйҮҚзӮ№и§ӮеҜҹпјҢж•°жҚ®еә“зҡ„жүҝиҪҪеҠӣеҸҳеҢ–гҖҒдё»иҰҒжҖ§иғҪ瓶йўҲзӯүгҖӮйҖҡеёёеҸҜд»ҘжңүдёӨз§Қж–№ејҸпјҢдёҖз§ҚжҳҜд»Һзңҹе®һзҺҜеўғеҜјжөҒпјҲ并еҸҜж №жҚ®йңҖиҰҒж”ҫеӨ§жөҒйҮҸпјҢеҸҜеҲ©з”Ёзұ»дјјTCPCOPYзӯүе·Ҙе…·пјү;дёҖз§ҚжҳҜж №жҚ®еүҚйқўж•ҙзҗҶзҡ„дёҡеҠЎеҺӢеҠӣжЁЎеһӢпјҢйҖҡиҝҮеҺӢеҠӣе·Ҙе…·жЁЎжӢҹеҺӢеҠӣгҖӮеүҚиҖ…йҖӮз”ЁдәҺе·ІжңүйЎ№зӣ®зҡ„жү©е®№иҜ„дј°гҖҒзі»з»ҹж”№йҖ иҜ„дј°зӯүпјҢеҗҺиҖ…йҖӮз”ЁдәҺж–°дёҠйЎ№зӣ®еҺҹеһӢж–№жЎҲиҜ„дј°гҖҒжҖ§иғҪеҹәеҮҶжөӢиҜ•зӯүеңәжҷҜгҖӮ
дёҠиҝ°жЁЎжӢҹеҺӢеҠӣжөӢиҜ•з»“жһңдёӯпјҢжҡҙйңІеҮәзҡ„жҖ§иғҪ瓶йўҲзӮ№пјҢе°ұжҳҜжҲ‘们еҗҺйқўйңҖиҰҒзқҖйҮҚж”№иҝӣгҖҒдјҳеҢ–зҡ„ж–№еҗ‘гҖӮ
й’ҲеҜ№дёҠйқўзҡ„иҜ„дј°з»“жһңпјҢжқҘзЎ®е®ҡеҗҺйқўзҡ„ж”№иҝӣгҖҒдјҳеҢ–ж–№жЎҲгҖӮеҸҜйҒөеҫӘеҰӮдёӢдёҖдәӣжӯҘйӘӨпјҡ
ж №жҚ®дёҠйқўзҡ„иҜ„жөӢз»“жһңпјҢеҲҶжһҗжҖ§иғҪ瓶йўҲзӮ№гҖӮй’ҲеҜ№дёҚеҗҢ瓶йўҲзӮ№пјҢеҸҜйҮҮеҸ–дёҚеҗҢзҡ„дёҖдәӣзӯ–з•ҘгҖӮжңүж—¶еҖҷжҖ§иғҪжөӢиҜ•ж—¶е…ЁжөҒзЁӢзҡ„пјҢеҜ№дәҺдёҖдёӘеӨҚжқӮзі»з»ҹжқҘиҜҙпјҢиҰҒжҳҺзЎ®е®ҡдҪҚеҲ°жҖ§иғҪ瓶йўҲзӮ№жҜ”иҫғеӣ°йҡҫгҖӮжӯӨж—¶пјҢеҸҜеҖҹеҠ©дёҖдәӣAPMе·Ҙе…·пјҢйҮҸеҢ–ж•ҙдёӘи®ҝй—®и·Ҝеҫ„пјҢеҚҸеҠ©жүҫеҲ°з“¶йўҲгҖӮд№ҹеҸҜд»Ҙзұ»дјјдёҠйқўзҡ„еҒҡжі•пјҢеҒҡеҘҪжҠҪиұЎе·ҘдҪңпјҢеҸӘеҜ№ж•°жҚ®еә“з«Ҝж–ҪеҠ еҺӢеҠӣпјҢи§ӮеҜҹж•°жҚ®еә“иЎҢдёәпјҢеҲӨиҜ»ж•°жҚ®еә“жҳҜеҗҰдёә瓶йўҲгҖӮеҰӮеҲӨж–ӯе°ұжҳҜж•°жҚ®еә“зҡ„жүҝиҪҪиғҪеҠӣдёҚеӨҹпјҢеҸҜжҢүз…§дёҚеҗҢеұӮж¬ЎиҝӣиЎҢиҖғиҷ‘гҖӮ
еңЁж•ҙдёӘиҜ„дј°ж•°жҚ®еә“жүҝиҪҪиғҪеҠӣдёӯпјҢиҝҷдёҖжӯҘйӘӨжҳҜжңҖеӨҚжқӮзҡ„гҖҒд№ҹжҳҜжңҖйҡҫзҡ„дёҖйғЁеҲҶгҖӮиҰҒеҢәеҲҶжё…жҘҡжҳҜеҗҰжҳҜж•°жҚ®еә“жүҝиҪҪиғҪеҠӣдёҚи¶іпјҢиҝҳжҳҜ其他组件зҡ„й—®йўҳгҖӮеҚідҪҝжҳҺзЎ®жҳҜж•°жҚ®еә“зҡ„й—®йўҳпјҢд№ҹиҰҒеҲҶжё…жҘҡжҳҜж•ҙдҪ“orеұҖйғЁзҡ„й—®йўҳпјӣжҳҜеҚ•дёҖдёҡеҠЎеҠҹиғҪж…ўпјҢиҝҳжҳҜж•ҙдҪ“йғҪжҜ”иҫғж…ўпјӣжҳҜеҒ¶е°”дјҡж…ўпјҢиҝҳжҳҜдёҖзӣҙйғҪеҫҲж…ўзӯүзӯүгҖӮиҝҷдәӣй—®йўҳзҡ„з•Ңе®ҡжңүеҠ©дәҺеҗҺйқўжҳҺзЎ®й—®йўҳеұӮж¬ЎпјҢйҮҮеҸ–дёҚеҗҢзҡ„зӯ–з•ҘиҝӣиЎҢи§ЈеҶігҖӮ
й’ҲеҜ№ж•°жҚ®еә“жүҝиҪҪиғҪеҠӣдёҚи¶іпјҢжҲ‘е°Ҷеёёи§ҒеҮәзҺ°й—®йўҳиҝӣиЎҢдәҶеұӮж¬ЎеҲ’еҲҶпјҢеҸҜз®ҖеҚ•еҲҶдёәиҜӯеҸҘзә§гҖҒеҜ№иұЎзә§гҖҒж•°жҚ®еә“зә§гҖҒж•°жҚ®еә“жһ¶жһ„зә§гҖҒеә”з”Ёжһ¶жһ„зә§гҖҒдёҡеҠЎжһ¶жһ„зә§гҖӮдёҚеҗҢеұӮж¬ЎйҮҮеҸ–зҡ„ж–№ејҸд№ҹжңүжүҖдёҚеҗҢпјҢдёӢйқўеҲҶеҲ«жҸҸиҝ°дёҖдёӢгҖӮ
еҰӮжҖ§иғҪж ёеҝғй—®йўҳпјҢеҸӘжҳҜжҹҗжқЎSQLиҜӯеҸҘзҡ„й—®йўҳпјҢеҸҜжңүй’ҲеҜ№жҖ§ең°иҝӣиЎҢдјҳеҢ–гҖӮиҝҷз§Қж–№ејҸжҳҜдҫөе…ҘжҖ§жҜ”иҫғе°Ҹзҡ„дёҖз§ҚдјҳеҢ–ж–№ејҸпјҢе…¶еҪұе“ҚиҢғеӣҙд№ҹжҜ”иҫғе°ҸгҖӮдёӢйқўеҜ№жҜ”еёёи§Ғзҡ„иҜӯеҸҘзә§дјҳеҢ–ж–№жі•гҖӮиҜҙжҳҺдёҖдёӢпјҢдёӢйқўж–№жі•е·Із»ҸжҺ’йҷӨдәҶиҜёеҰӮз»ҹи®ЎдҝЎжҒҜдёҚеҮҶзЎ®зӯүе…¶д»–еӣ зҙ пјҢд»…д»ҺSQLиҜӯеҸҘжң¬иә«дјҳеҢ–ж–№ејҸиҖғиҷ‘гҖӮ
йҖҡиҝҮж”№еҶҷиҜӯеҸҘпјҢиҫҫеҲ°и°ғж•ҙжү§иЎҢи®ЎеҲ’пјҢжҸҗй«ҳиҝҗиЎҢж•ҲзҺҮзҡ„зӣ®зҡ„гҖӮиҝҷз§Қж–№ејҸзҡ„зјәзӮ№жҳҜйңҖиҰҒз ”еҸ‘дәәе‘ҳдҝ®ж”№еҺҹд»Јз ҒпјҢ然еҗҺеҶҚиҝӣиЎҢйғЁзҪІдёҠзәҝзҡ„иҝҮзЁӢгҖӮжӯӨеӨ–пјҢжңүдәӣдҪҝз”ЁO/R Mappingе·Ҙе…·дә§з”ҹзҡ„SQLпјҢж— жі•зӣҙжҺҘдҝ®ж”№иҜӯеҸҘпјҢд№ҹж— жі•дҪҝз”ЁжӯӨж–№жі•гҖӮ
еҫҲеӨҡз§Қж•°жҚ®еә“йғҪжҸҗдҫӣдәҶжҸҗзӨәпјҲHintпјүзҡ„еҠҹиғҪгҖӮйҖҡиҝҮиҝҷз§Қж–№ејҸжқҘжҢҮе®ҡиҜӯеҸҘзҡ„жү§иЎҢиҝҮзЁӢгҖӮиҝҷз§Қж–№ејҸеҗҢж ·йңҖиҰҒдҝ®ж”№жәҗд»Јз ҒпјҢз»ҸеҺҶйғЁзҪІдёҠзәҝзҡ„иҝҮзЁӢгҖӮжӯӨеӨ–пјҢиҝҷз§Қдҝ®ж”№ж–№ејҸиҝҳеӯҳеңЁйҖӮеә”жҖ§иҫғе·®зҡ„й—®йўҳгҖӮеӣ дёәе…¶жҢҮе®ҡдәҶзү№жңүзҡ„жү§иЎҢиҝҮзЁӢпјҢйҡҸзқҖж•°жҚ®и§„жЁЎгҖҒж•°жҚ®зү№еҫҒзҡ„еҸҳеҢ–пјҢеӣәеҢ–зҡ„жү§иЎҢиҝҮзЁӢеҸҜиғҪдёҚжҳҜжңҖдҪіж–№ејҸдәҶгҖӮиҝҷз§Қж–№ејҸе®һйҷ…дёҠжҳҜж”ҫејғдәҶдјҳеҢ–еҷЁеҸҜиғҪдә§з”ҹзҡ„жңҖдјҳи·Ҝеҫ„гҖӮ
еңЁOracleдёӯиҝҳеҶ…зҪ®дәҶдёҖдәӣеҠҹиғҪпјҢе®ғ们еҸҜд»ҘеӣәеҢ–жҹҗдёҖжқЎиҜӯеҸҘзҡ„жү§иЎҢж–№ејҸпјҢд»Һжң¬иҙЁдёҠжқҘи®ІпјҢе…¶еҺҹзҗҶе’ҢдёҠйқўдҪҝз”ЁHintе·®дёҚеӨҡгҖӮе…¶зјәзӮ№д№ҹзұ»дјјдёҠйқўгҖӮ
жңүж—¶д№ҹеҸҜйҖҡиҝҮи°ғж•ҙжҹҗдәӣеҸӮж•°пјҢиҝӣиҖҢж”№еҸҳиҜӯеҸҘзҡ„жү§иЎҢи®ЎеҲ’гҖӮдҪҶжҳҜиҝҷз§Қж–№ејҸиҰҒжіЁж„ҸйҖӮз”ЁиҢғеӣҙпјҢдёҚиҰҒеңЁе…ЁеұҖдҪҝз”ЁпјҢйҒҝе…ҚеҪұе“ҚиҫғеӨҡзҡ„иҜӯеҸҘгҖӮеңЁдјҡиҜқзә§дҪҝз”Ёд№ҹиҰҒжҺ§еҲ¶иҢғеӣҙпјҢйҒҝе…Қдә§з”ҹиҫғеӨ§еҪұе“ҚгҖӮ
еҰӮжҖ§иғҪж ёеҝғй—®йўҳпјҢеңЁSQLеұӮйқўж— жі•и§ЈеҶіпјҢйңҖиҰҒиҖғиҷ‘еҜ№иұЎеұӮйқўзҡ„и°ғж•ҙгҖӮиҝҷз§Қжғ…еҶөиҰҒжҜ”иҫғж…ҺйҮҚпјҢйңҖиҰҒе……еҲҶиҜ„дј°еҸҜиғҪеёҰжқҘзҡ„йЈҺйҷ©еҸҠ收зӣҠгҖӮдёҖдёӘеҜ№иұЎзҡ„з»“жһ„дҝ®ж”№пјҢеҸҜд»Ҙж¶үеҸҠеҲ°ж•°зҷҫжқЎгҖҒз”ҡиҮіж•°еҚғжқЎе’ҢжӯӨзӣёе…іиҜӯеҸҘзҡ„жү§иЎҢи®ЎеҲ’еҸҳжӣҙгҖӮеҰӮдёҚеҒҡе……еҲҶжөӢиҜ•зҡ„жғ…еҶөдёӢпјҢеҫҲйҡҫдҝқиҜҒдёҚеҮәй—®йўҳгҖӮеҰӮжһңжҳҜOracleж•°жҚ®еә“пјҢеҸҜиҖғиҷ‘дҪҝз”ЁSPAиҜ„дј°дёҖдёӢгҖӮе…¶д»–ж•°жҚ®еә“зҡ„иҜқпјҢеҸҜжҸҗеүҚжүӢе·Ҙ收йӣҶдёҖдёӢзӣёе…іиҜӯеҸҘпјҢжЁЎжӢҹдҝ®ж”№еҗҺйҮҚж”ҫдёҠиҝ°иҜӯеҸҘпјҢиҜ„дј°жҖ§иғҪеҸҳеҢ–гҖӮ
1пјүеҪұе“Қеӣ зҙ
еңЁеҜ№иұЎзә§иҝӣиЎҢи°ғж•ҙпјҢйҷӨдәҶиҖғиҷ‘еҜ№е…¶д»–иҜӯеҸҘзҡ„жҖ§иғҪеҪұе“ҚеӨ–пјҢиҝҳйңҖиҰҒиҖғиҷ‘е…¶д»–еӣ зҙ гҖӮеёёи§Ғзҡ„д»ҘдёӢиҝҷдәӣпјҡ
еёёи§Ғзҡ„дҫӢеҰӮзҙўеј•гҖӮйҖҡиҝҮж·»еҠ зҙўеј•пјҢеҫҖеҫҖеҸҜд»Ҙиө·еҲ°еҠ йҖҹжҹҘиҜўзҡ„зӣ®зҡ„пјӣдҪҶжҳҜеўһеҠ зҙўеј•пјҢдјҡеҜјиҮҙж•°жҚ®DMLжҲҗжң¬зҡ„еўһеҠ гҖӮ
еёёи§Ғзҡ„дҫӢеҰӮе…ЁеұҖеҲҶеҢәзҙўеј•гҖӮе…ЁеұҖеҲҶеҢәзҙўеј•еңЁиҝӣиЎҢеҲҶеҢәз»ҙжҠӨеҠЁдҪңеҗҺпјҢдјҡеҜјиҮҙзҙўеј•еӨұж•ҲпјҢйңҖиҰҒиҮӘеҠЁжҲ–жүӢеҠЁиҝӣиЎҢз»ҙжҠӨзҙўеј•еҠЁдҪңгҖӮ
еёёи§Ғзҡ„зҙўеј•пјҢзҙўеј•з»“жһ„жҳҜж•°жҚ®еә“дёӯзңҹе®һеҚ жҚ®з©әй—ҙзҡ„з»“жһ„гҖӮеңЁд»ҘеҫҖзҡ„дёҖдәӣжЎҲдҫӢдёӯпјҢз”ҡиҮіеҮәзҺ°иҝҮзҙўеј•жҖ»еӨ§е°Ҹи¶…иҝҮиЎЁеӨ§е°Ҹзҡ„жғ…еҶөпјҢеӣ жӯӨж–°еўһж—¶иҰҒиҜ„дј°е…¶з©әй—ҙдҪҝз”ЁгҖӮ
2пјүе…Ёз”ҹе‘Ҫе‘Ёжңҹз®ЎзҗҶ
иҝҷйҮҢиҝҳжңүеҸҰеӨ–дёҖдёӘеҫҲйҮҚиҰҒзҡ„жҰӮеҝөвҖ”вҖ”вҖңеҜ№иұЎе…Ёз”ҹе‘Ҫе‘Ёжңҹз®ЎзҗҶвҖқпјҢз®ҖеҚ•жқҘиҜҙе°ұжҳҜеҜ№иұЎзҡ„з”ҹиҖҒз—…жӯ»гҖӮеңЁеҫҲеӨҡзі»з»ҹдёӯпјҢеҜ№иұЎд»Һж–°е»әејҖе§ӢпјҢж•°жҚ®дёҚж–ӯеўһеҠ гҖҒиҶЁиғҖпјҢеҪ“ж•°жҚ®и§„жЁЎиҫҫеҲ°дёҖе®ҡйҮҸзә§еҗҺпјҢеҗ„з§ҚжҖ§иғҪй—®йўҳе°ұеҮәзҺ°дәҶгҖӮеҜ№дёҖдёӘзҷҫдёҮзә§зҡ„иЎЁе’ҢдәҝдёҮзә§зҡ„иЎЁпјҢе…¶жҹҘиҜўжҖ§иғҪиӮҜе®ҡдёҚиғҪеҗҢж—ҘиҖҢиҜӯгҖӮеӣ жӯӨпјҢеңЁеҜ№иұЎи®ҫи®ЎеҲқжңҹпјҢе°ұиҰҒиҖғиҷ‘зӣёе…ізҡ„еҪ’жЎЈгҖҒжё…зҗҶгҖҒиҪ¬еӮЁгҖҒеҺӢзј©зӯ–з•ҘпјҢе°ҶеӯҳеӮЁз©әй—ҙзҡ„иҜ„дј°дёҺз”ҹе‘Ҫе‘Ёжңҹз®ЎзҗҶдёҖиө·иҖғиҷ‘гҖӮ
еҫҲеӨҡжҖ§иғҪй—®йўҳпјҢеңЁеҒҡдәҶж•°жҚ®жё…зҗҶеҗҺйғҪиҝҺеҲғиҖҢи§ЈгҖӮдҪҶж•°жҚ®жё…зҗҶеҫҖеҫҖжҳҜйңҖиҰҒд»Јд»·зҡ„пјҢеҝ…йЎ»еңЁи®ҫи®Ўд№ӢеҲқе°ұиҖғиҷ‘иҝҷдёӘй—®йўҳгҖӮеңЁеҒҡж•°жҚ®еә“иҜ„е®Ўзҡ„ж—¶еҖҷпјҢйҷӨдәҶ常规зҡ„з»“жһ„иҜ„е®ЎгҖҒиҜӯеҸҘиҜ„е®ЎеӨ–пјҢд№ҹиҰҒиҖғиҷ‘иҝҷйғЁеҲҶеӣ зҙ гҖӮ
еҲ°дәҶиҝҷдёӘеұӮйқўпјҢй—®йўҳеҫҖеҫҖе·Із»ҸжҜ”иҫғдёҘйҮҚдәҶгҖӮдёҖиҲ¬жғ…еҶөдёӢпјҢж•°жҚ®еә“зҡ„еҲқе§Ӣй…ҚзҪ®йғҪжҳҜеҹәдәҺе…¶дёҠйқўиҝҗиЎҢзі»з»ҹзҡ„иҙҹиҪҪзұ»еһӢиҝӣиЎҢдё“й—Ёй…ҚзҪ®зҡ„гҖӮеҰӮжһңиҝҗиЎҢдёҖж®өж—¶й—ҙеҗҺпјҢеҮәзҺ°жҖ§иғҪй—®йўҳпјҢз»ҸиҜ„дј°жҳҜеұһдәҺе…ЁеұҖжҖ§й—®йўҳзҡ„пјҢеҸҜд»ҘиҖғиҷ‘иҝӣиЎҢж•°жҚ®еә“зә§еҲ«зҡ„и°ғж•ҙгҖӮдҪҶжҳҜиҝҷз§Қй…ҚзҪ®еҫҖеҫҖд»Јд»·д№ҹжҜ”иҫғеӨ§пјҢдҫӢеҰӮйңҖиҰҒдё“й—Ёзҡ„еҒңжңәзӘ—еҸЈж“ҚдҪңзӯүгҖӮиҖҢдё”иҝҷз§Қж“ҚдҪңзҡ„йЈҺйҷ©жҖ§д№ҹжҜ”иҫғеӨ§пјҢжңүеҸҜиғҪдјҡеёҰжқҘеҫҲеӨҡдёҚзЎ®е®ҡеӣ зҙ пјҢеӣ жӯӨиҰҒж…ҺиҖҢеҸҲж…ҺгҖӮ
еҰӮжҖ§иғҪж ёеҝғй—®йўҳпјҢж— жі•еңЁдёҠиҝ°еұӮйқўи§ЈеҶіпјҢеҸҜиғҪе°ұйңҖиҰҒи°ғж•ҙж•°жҚ®еә“жһ¶жһ„гҖӮеёёи§Ғзҡ„дҫӢеҰӮйҮҮеҸ–иҜ»еҶҷеҲҶзҰ»зҡ„и®ҝй—®ж–№ејҸгҖҒеҲҶеә“еҲҶиЎЁеӯҳеӮЁж–№ејҸзӯүгҖӮиҝҷз§ҚеҜ№еә”з”Ёзҡ„дҫөе…ҘжҖ§еҫҲејәдәҶпјҢжңүдәӣжғ…еҶөдёӢз”ҡиҮідёҚдәҡдәҺйҮҚжһ„ж•ҙдёӘзі»з»ҹгҖӮ
дҫӢеҰӮпјҢйҡҸзқҖдёҡеҠЎзҡ„еҸ‘еұ•пјҢзі»з»ҹзҡ„ж•°жҚ®йҮҸжҲ–и®ҝй—®йҮҸи¶…еҮәдәҶйў„жңҹпјҢйҖҡиҝҮеҚ•дёҖж•°жҚ®еә“ж— жі•ж»Ўи¶із©әй—ҙжҲ–жҖ§иғҪиҰҒжұӮгҖӮжӯӨж—¶пјҢеҸҜиғҪе°ұйңҖиҰҒиҖғиҷ‘йҮҮз”ЁдёҖз§ҚеҲҶеә“еҲҶиЎЁзӯ–з•ҘпјҢжқҘж»Ўи¶іиҝҷйғЁеҲҶзҡ„йңҖжұӮгҖӮдҪҶе…¶ж”№йҖ йҡҫеәҰпјҢеҫҖеҫҖжҜ”йҮҚж–°ејҖеҸ‘дёҖеҘ—зі»з»ҹиҝҳиҰҒеӨ§гҖӮ
жҜ”еҰӮпјҢжҲ‘们еҸҜиғҪйңҖиҰҒдёҖдёӘж•°жҚ®дёӯй—ҙеұӮпјҢжқҘеұҸи”ҪеҗҺйқўзҡ„еҲҶеә“еҲҶиЎЁз»ҶиҠӮгҖӮиҝҷдёӘдёӯй—ҙеұӮеҸҜиғҪйңҖиҰҒе®ҢжҲҗиҜӯеҸҘи§ЈжһҗгҖҒи®ҝй—®и·Ҝз”ұгҖҒж•°жҚ®иҒҡеҗҲгҖҒдәӢеҠЎеӨ„зҗҶзӯүдёҖзі»еҲ—еҠҹиғҪгҖӮеҚідҪҝдҪҝз”ЁдәҶдёӯй—ҙеұӮдә§е“ҒпјҢеҜ№дәҺеә”з”ЁжқҘиҜҙпјҢж•°жҚ®еә“зҡ„еҠҹиғҪд№ҹдјҡзӣёеҜ№вҖңејұеҢ–вҖқпјҢеә”з”Ёзә§д»Јз ҒдёҚеҫ—дёҚиҝӣиЎҢеҫҲеӨҡзҡ„и°ғж•ҙжқҘйҖӮеә”иҝҷз§ҚеҸҳеҢ–гҖӮжӯӨеӨ–пјҢеҰӮдҪ•жҠҠдёҖдёӘзәҝдёҠжӯЈеңЁиҝҗиЎҢзҡ„зі»з»ҹпјҢйЎәеҲ©е№ізЁіең°иҝҒ移еҲ°ж–°зҡ„з»“жһ„дёӢпјҢиҝҷж— з–‘еҸҲжҳҜдёҖдёӘз»ҷйЈһй©°зҡ„и·‘иҪҰжҚўиҪ®иғҺзҡ„й—®йўҳзӯүзӯүгҖӮ
еҰӮжһңйЎ№зӣ®еңЁиҝҗиЎҢдёӯпјҢеҮәзҺ°дәҶж•°жҚ®еә“жһ¶жһ„зә§зҡ„и°ғж•ҙпјҢеҫҲжңүеҸҜиғҪиҜҙжҳҺеңЁеүҚжңҹйЎ№зӣ®и®ҫ计规еҲ’йҳ¶ж®өеҮәзҺ°дәҶеӨұиҜҜпјҢжҲ–иҖ…еҜ№йЎ№зӣ®зҡ„дёҡеҠЎйў„жңҹеҮәзҺ°дәҶеҒҸе·®гҖӮеӣ жӯӨпјҢиҝҷдёӨзӮ№дёҖе®ҡеңЁеҲқе§Ӣйҳ¶ж®өиҝӣиЎҢе……еҲҶзҡ„иҜ„дј°пјҢ并еңЁи®ҫи®ЎдёҠдҝқз•ҷжңүе……еҲҶзҡ„вҖңеј№жҖ§вҖқгҖӮ
жңүдәӣжғ…еҶөдёӢпјҢеҚ•зәҜдҫқйқ ж•°жҚ®еә“жҳҜж— жі•и§ЈеҶізҡ„пјҢйңҖиҰҒз»јеҗҲиҖғиҷ‘ж•ҙдёӘеә”з”Ёжһ¶жһ„гҖӮеңЁж•ҙдёӘзі»з»ҹжһ¶жһ„дёӯпјҢж•°жҚ®еә“еҫҖеҫҖеӨ„дәҺзі»з»ҹзҡ„жңҖжң«з«ҜпјҢе…¶жү©еұ•жҖ§жҳҜжңҖе·®зҡ„гҖӮеӣ жӯӨпјҢеңЁеә”з”Ёжһ¶жһ„и®ҫи®ЎеҲқжңҹпјҢе°ұеә”иҜҘжң¬зқҖе°ҪйҮҸдёҚиҰҒеҜ№ж•°жҚ®еә“дә§з”ҹеҺӢеҠӣзҡ„еҺҹеҲҷиҝӣиЎҢи®ҫи®ЎгҖӮжҲ–иҖ…еҚідҪҝжңүеӨ§зҡ„еҺӢеҠӣпјҢзі»з»ҹеҸҜд»ҘйҮҮеҸ–иҮӘеҠЁйҷҚзә§зӯүж–№ејҸдҝқиҜҒж•°жҚ®еә“зҡ„е№ізЁіиҝҗиЎҢгҖӮ
еёёи§Ғзҡ„дҫӢеҰӮеўһеҠ зј“еӯҳгҖҒйҖҡиҝҮMQе®һзҺ°еүҠеі°еЎ«и°·зӯүгҖӮйҖҡиҝҮеўһеҠ зј“еӯҳпјҢеҸҜд»ҘеӨ§е№…еәҰеҮҸе°‘еҜ№ж•°жҚ®еә“зҡ„и®ҝй—®еҺӢеҠӣпјҢжҸҗй«ҳж•ҙдҪ“зі»з»ҹзҡ„еҗһеҗҗиғҪеҠӣгҖӮеј•е…ҘMQпјҢеҲҷеҸҜд»Ҙе°ҶеҜ№ж•°жҚ®еә“зҡ„еҺӢеҠӣд»ҘвҖңзЁіжҖҒвҖқзҡ„еҪўејҸпјҢеҗ‘ж•°жҚ®еә“жҢҒз»ӯж–ҪеҺӢпјҢиҖҢдёҚиҮідәҺиў«жҹҗдёӘејӮеёёй«ҳеі°еҺӢжӯ»гҖӮ
жңҖеҗҺдёҖз§Қжғ…еҶөжҳҜд»ҺдёҡеҠЎи§’еәҰиҝӣиЎҢдёҖдәӣи°ғж•ҙгҖӮиҝҷеҫҖеҫҖжҳҜдёҖз§ҚеҰҘеҚҸпјҢйҖҡиҝҮеҒҡйҖӮеҪ“зҡ„еҮҸжі•дҝқиҜҒзі»з»ҹзҡ„ж•ҙдҪ“иҝҗиЎҢгҖӮз”ҡиҮідёҚжҺ’йҷӨзүәзүІдёҖйғЁеҲҶз”ЁжҲ·дҪ“йӘҢзӯүж–№ејҸпјҢжқҘж»Ўи¶іеӨ§йғЁеҲҶз”ЁжҲ·зҡ„еҸҜз”ЁжҖ§гҖӮиҝҷе°ұйңҖиҰҒжҲ‘们зҡ„жһ¶жһ„еёҲеҜ№зі»з»ҹиғҪжҸҗдҫӣзҡ„иғҪеҠӣиҰҒеҫҲжё…жҘҡпјҢеҜ№дёҡеҠЎд№ҹиҰҒжңүе……еҲҶзҡ„дәҶи§ЈгҖӮеҜ№дәҺжүҝиҪҪд»Җд№Ҳж ·зҡ„дёҡеҠЎпјҢеҸҠдёәдәҶжүҝиҪҪдёҡеҠЎжүҖйңҖиҰҒиҠұиҙ№зҡ„д»Јд»·жҲҗжң¬жңүе……еҲҶзҡ„и®ӨзҹҘпјҢжүҚеҸҜд»ҘеҒҡеҮәдёҖдәӣеҸ–иҲҚгҖӮ
иҝҷйҮҢиҰҒйҒҝе…ҚдёҖдәӣиҜҜеҢәпјҢи®ӨдёәжҠҖжңҜжҳҜвҖңдёҮиғҪвҖқзҡ„гҖӮжҠҖжңҜеҸҜд»Ҙи§ЈеҶідёҖе®ҡзҡ„й—®йўҳпјҢдҪҶдёҚиғҪи§ЈеҶіжүҖжңүй—®йўҳпјҢжҲ–иҖ…и§ЈеҶіжүҖжңүй—®йўҳзҡ„жҲҗжң¬д»Јд»·жҳҜйҡҫд»ҘжҺҘеҸ—зҡ„гҖӮиҝҷдёӘж—¶еҖҷпјҢд»ҺдёҡеҠЎи§’еәҰзЁҚдҪңи°ғж•ҙпјҢе°ұеҸҜд»ҘиҫҫеҲ°вҖңйҖҖдёҖжӯҘжө·йҳ”еӨ©з©әвҖқзҡ„з»“жһңгҖӮ
жӢ“еұ•йҳ…иҜ»пјҡиҮӘеҲ¶е°Ҹе·Ҙе…·еӨ§еӨ§еҠ йҖҹMySQL SQLиҜӯеҸҘдјҳеҢ–(йҷ„жәҗз Ғ)
е…Ёйқўи§ЈжһҗOracleзӯүеҫ…дәӢ件зҡ„еҲҶзұ»гҖҒеҸ‘зҺ°еҸҠдјҳеҢ–
еҫӘеәҸжёҗиҝӣи§ЈиҜ»Oracle AWRжҖ§иғҪеҲҶжһҗжҠҘе‘Ҡ
SQLдјҳеҢ–пјҡдёҖзҜҮж–Үз« иҜҙжё…жҘҡOracle Hintзҡ„жӯЈзЎ®дҪҝз”Ёе§ҝеҠҝ
жҖ§иғҪдјҳеҢ–еҲ©еҷЁпјҡж•°жҚ®еә“е®Ўж ёе№іеҸ°Themisзҡ„йҖүеһӢдёҺе®һи·ө
дҪңиҖ…пјҡйҹ©й”Ӣ
жқҘжәҗпјҡе®ңдҝЎжҠҖжңҜеӯҰйҷў
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ