жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
дёҠзҜҮж–Үз« Redisй—Іи°ҲпјҲ1пјүпјҡжһ„е»әзҹҘиҜҶеӣҫи°ұд»Ӣз»ҚдәҶredisзҡ„еҹәжң¬жҰӮеҝөгҖҒдјҳзјәзӮ№д»ҘеҸҠе®ғзҡ„еҶ…еӯҳж·ҳжұ°жңәеҲ¶пјҢзӣёдҝЎеӨ§е®¶еҜ№redisжңүдәҶеҲқжӯҘзҡ„и®ӨиҜҶгҖӮдә’иҒ”зҪ‘зҡ„еҫҲеӨҡеә”з”ЁеңәжҷҜйғҪжңүзқҖRedisзҡ„иә«еҪұпјҢе®ғиғҪеҒҡзҡ„дәӢжғ…иҝңиҝңи¶…еҮәдәҶжҲ‘们зҡ„жғіеғҸгҖӮRedisзҡ„еә•еұӮж•°жҚ®з»“жһ„еҲ°еә•жҳҜд»Җд№Ҳж ·зҡ„е‘ўпјҢдёәд»Җд№Ҳе®ғиғҪеҒҡиҝҷд№ҲеӨҡзҡ„дәӢжғ…пјҹжң¬ж–Үе°ҶжҺўз§ҳRedisзҡ„еә•еұӮж•°жҚ®з»“жһ„д»ҘеҸҠеёёз”Ёзҡ„е‘Ҫд»ӨгҖӮ
жң¬ж–ҮзҹҘиҜҶи„‘еӣҫеҰӮдёӢпјҡ
з”Ё й”®еҖјеҜ№ nameпјҡ"е°ҸжҳҺ"жқҘеұ•зӨәRedisзҡ„ж•°жҚ®жЁЎеһӢеҰӮдёӢпјҡ
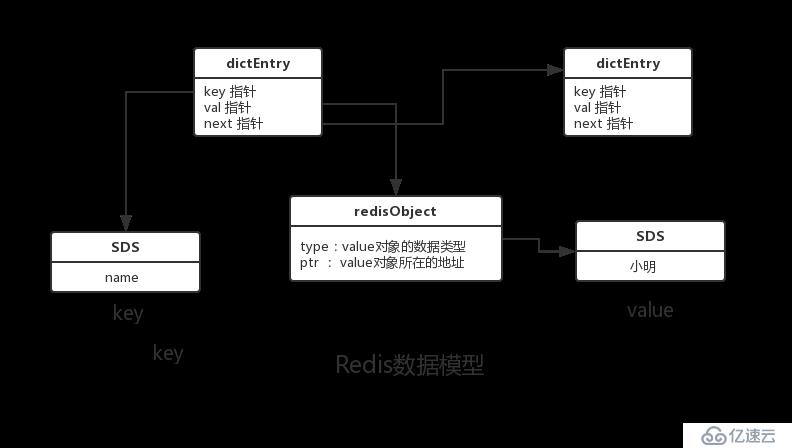
RedisObjectеҜ№иұЎеҫҲйҮҚиҰҒпјҢRedisеҜ№иұЎзҡ„зұ»еһӢгҖҒеҶ…йғЁзј–з ҒгҖҒеҶ…еӯҳеӣһ收гҖҒе…ұдә«еҜ№иұЎзӯүеҠҹиғҪпјҢйғҪжҳҜеҹәдәҺRedisObjectеҜ№иұЎжқҘе®һзҺ°зҡ„гҖӮ
иҝҷж ·и®ҫи®Ўзҡ„еҘҪеӨ„жҳҜпјҡеҸҜд»Ҙй’ҲеҜ№дёҚеҗҢзҡ„дҪҝз”ЁеңәжҷҜпјҢеҜ№5з§Қеёёз”Ёзұ»еһӢи®ҫзҪ®еӨҡз§ҚдёҚеҗҢзҡ„ж•°жҚ®з»“жһ„е®һзҺ°пјҢд»ҺиҖҢдјҳеҢ–еҜ№иұЎеңЁдёҚеҗҢеңәжҷҜдёӢзҡ„дҪҝз”Ёж•ҲзҺҮгҖӮ
Redisе°ҶjemallocдҪңдёәй»ҳи®ӨеҶ…еӯҳеҲҶй…ҚеҷЁпјҢеҮҸе°ҸеҶ…еӯҳзўҺзүҮгҖӮjemallocеңЁ64дҪҚзі»з»ҹдёӯпјҢе°ҶеҶ…еӯҳз©әй—ҙеҲ’еҲҶдёәе°ҸгҖҒеӨ§гҖҒе·ЁеӨ§дёүдёӘиҢғеӣҙпјӣжҜҸдёӘиҢғеӣҙеҶ…еҸҲеҲ’еҲҶдәҶи®ёеӨҡе°Ҹзҡ„еҶ…еӯҳеқ—еҚ•дҪҚпјӣеҪ“RedisеӯҳеӮЁж•°жҚ®ж—¶пјҢдјҡйҖүжӢ©еӨ§е°ҸжңҖеҗҲйҖӮзҡ„еҶ…еӯҳеқ—иҝӣиЎҢеӯҳеӮЁгҖӮ
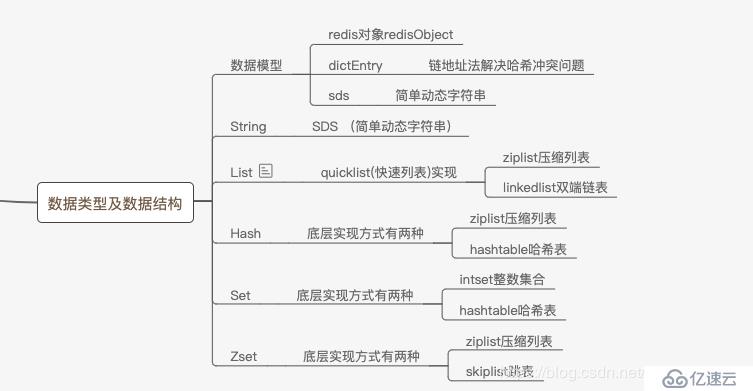
Redisж”ҜжҢҒзҡ„ж•°жҚ®з»“жһ„жңүе“Әдәӣпјҹ
еҰӮжһңеӣһзӯ”жҳҜStringгҖҒListгҖҒHashгҖҒSetгҖҒZsetе°ұдёҚеҜ№дәҶпјҢиҝҷ5з§ҚжҳҜredisзҡ„еёёз”Ёеҹәжң¬ж•°жҚ®зұ»еһӢпјҢжҜҸдёҖз§Қж•°жҚ®зұ»еһӢеҶ…йғЁиҝҳеҢ…еҗ«зқҖеӨҡз§Қж•°жҚ®з»“жһ„гҖӮ
з”ЁencodingжҢҮд»ӨжқҘзңӢдёҖдёӘеҖјзҡ„ж•°жҚ®з»“жһ„гҖӮжҜ”еҰӮпјҡ
127.0.0.1:6379> set name tom
OK
127.0.0.1:6379> object encoding name
"embstr"жӯӨеӨ„и®ҫзҪ®дәҶnameеҖјжҳҜtomпјҢе®ғзҡ„ж•°жҚ®з»“жһ„жҳҜembstrпјҢдёӢж–Үд»Ӣз»Қеӯ—з¬ҰдёІж—¶дјҡиҜҰи§ЈиҜҙжҳҺгҖӮ
127.0.0.1:6379> set age 18
OK
127.0.0.1:6379> object encoding age
"int"еҰӮдёӢиЎЁж јжҖ»з»“RedisдёӯжүҖжңүзҡ„ж•°жҚ®з»“жһ„зұ»еһӢпјҡ
| еә•еұӮж•°жҚ®з»“жһ„ | зј–з ҒеёёйҮҸ | object encodingжҢҮд»Өиҫ“еҮә |
|---|---|---|
| ж•ҙж•°зұ»еһӢ | REDIS_ENCODING_INT | "int" |
| embstrеӯ—з¬ҰдёІзұ»еһӢ | REDIS_ENCODING_EMBSTR | "embstr" |
| з®ҖеҚ•еҠЁжҖҒеӯ—з¬ҰдёІ | REDIS_ENCODING_RAW | "raw" |
| еӯ—е…ёзұ»еһӢ | REDIS_ENCODING_HT | "hashtable" |
| еҸҢз«Ҝй“ҫиЎЁ | REDIS_ENCODING_LINKEDLIST | "linkedlist" |
| еҺӢзј©еҲ—иЎЁ | REDIS_ENCODING_ZIPLIST | "ziplist" |
| ж•ҙж•°йӣҶеҗҲ | REDIS_ENCODING_INTSET | "intset" |
| и·іиЎЁе’Ңеӯ—е…ё | REDIS_ENCODING_SKIPLIST | "skiplist" |
иЎҘе……иҜҙжҳҺ
еҒҮеҰӮйқўиҜ•е®ҳй—®пјҡredisзҡ„ж•°жҚ®зұ»еһӢжңүе“Әдәӣпјҹ
еӣһзӯ”пјҡStringгҖҒlistгҖҒhashгҖҒsetгҖҒzet
дёҖиҲ¬жғ…еҶөдёӢиҝҷж ·еӣһзӯ”жҳҜжӯЈзЎ®зҡ„пјҢеүҚж–Үд№ҹжҸҗеҲ°redisзҡ„ж•°жҚ®зұ»еһӢзЎ®е®һжҳҜеҢ…еҗ«иҝҷ5з§ҚпјҢдҪҶз»Ҷеҝғзҡ„еҗҢеӯҰиӮҜе®ҡеҸ‘зҺ°дәҶд№ӢеүҚиҜҙзҡ„жҳҜвҖңеёёз”ЁвҖқзҡ„5з§Қж•°жҚ®зұ»еһӢгҖӮе…¶е®һпјҢйҡҸзқҖRedisзҡ„дёҚж–ӯжӣҙж–°е’Ңе®Ңе–„пјҢRedisзҡ„ж•°жҚ®зұ»еһӢж—©е·ІдёҚжӯў5з§ҚдәҶгҖӮ
зҷ»еҪ•redisзҡ„е®ҳж–№зҪ‘з«ҷжү“ејҖе®ҳж–№зҡ„ж•°жҚ®зұ»еһӢд»Ӣз»Қпјҡ
https://redis.io/topics/data-types-intro

еҸ‘зҺ°Redisж”ҜжҢҒзҡ„ж•°жҚ®з»“жһ„дёҚжӯў5з§ҚпјҢиҖҢжҳҜ8з§ҚпјҢеҗҺдёүз§Қзұ»еһӢеҲҶеҲ«жҳҜпјҡ
жң¬ж–Үдё»иҰҒд»Ӣз»Қ5з§Қеёёз”Ёзҡ„ж•°жҚ®зұ»еһӢпјҢдёҠиҝ°дёүз§Қд»ҘеҗҺеҶҚе…ұеҗҢжҺўзҙўгҖӮ
еӯ—з¬ҰдёІзұ»еһӢжҳҜredisжңҖеёёз”Ёзҡ„ж•°жҚ®зұ»еһӢпјҢеңЁRedisдёӯпјҢеӯ—з¬ҰдёІжҳҜеҸҜд»Ҙдҝ®ж”№зҡ„пјҢеңЁеә•еұӮе®ғжҳҜд»Ҙеӯ—иҠӮж•°з»„зҡ„еҪўејҸеӯҳеңЁзҡ„гҖӮ
Redisдёӯзҡ„еӯ—з¬ҰдёІиў«з§°дёәз®ҖеҚ•еҠЁжҖҒеӯ—з¬ҰдёІгҖҢSDSгҖҚпјҢиҝҷз§Қз»“жһ„еҫҲеғҸJavaдёӯзҡ„ArrayListпјҢе…¶й•ҝеәҰжҳҜеҠЁжҖҒеҸҜеҸҳзҡ„.
struct SDS<T> {
T capacity; // ж•°з»„е®№йҮҸ
T len; // ж•°з»„й•ҝеәҰ
byte[] content; // ж•°з»„еҶ…е®№
}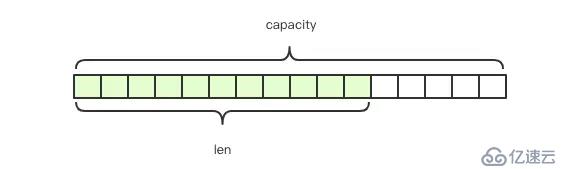
content[] еӯҳеӮЁзҡ„жҳҜеӯ—з¬ҰдёІзҡ„еҶ…е®№пјҢcapacityиЎЁзӨәж•°з»„еҲҶй…Қзҡ„й•ҝеәҰпјҢlenиЎЁзӨәеӯ—з¬ҰдёІзҡ„е®һйҷ…й•ҝеәҰгҖӮ
еӯ—з¬ҰдёІзҡ„зј–з Ғзұ»еһӢжңүintгҖҒembstrе’Ңrawдёүз§ҚпјҢеҰӮдёҠиЎЁжүҖзӨәпјҢйӮЈд№Ҳиҝҷдёүз§Қзј–з Ғзұ»еһӢжңүд»Җд№ҲдёҚеҗҢе‘ўпјҹ
int зј–з Ғпјҡдҝқеӯҳзҡ„жҳҜеҸҜд»Ҙз”Ё long зұ»еһӢиЎЁзӨәзҡ„ж•ҙж•°еҖјгҖӮ
raw зј–з Ғпјҡдҝқеӯҳй•ҝеәҰеӨ§дәҺ44еӯ—иҠӮзҡ„еӯ—з¬ҰдёІпјҲredis3.2зүҲжң¬д№ӢеүҚжҳҜ39еӯ—иҠӮпјҢд№ӢеҗҺжҳҜ44еӯ—иҠӮпјүгҖӮ
и®ҫзҪ®дёҖдёӘеҖјжөӢиҜ•дёҖдёӢпјҡ
127.0.0.1:6379> set num 300
127.0.0.1:6379> object encoding num
"int"
127.0.0.1:6379> set key1 wealwaysbyhappyhahaha
OK
127.0.0.1:6379> object encoding key1
"embstr"
127.0.0.1:6379> set key2 hahahahahahahaahahahahahahahahahahahaha
OK
127.0.0.1:6379> strlen key2
(integer) 39
127.0.0.1:6379> object encoding key2
"embstr"
127.0.0.1:6379> set key2 hahahahahahahaahahahahahahahahahahahahahahaha
OK
127.0.0.1:6379> object encoding key2
"raw"
127.0.0.1:6379> strlen key2
(integer) 45embstrзј–з Ғзҡ„з»“жһ„:

rawзј–з Ғзҡ„з»“жһ„пјҡ
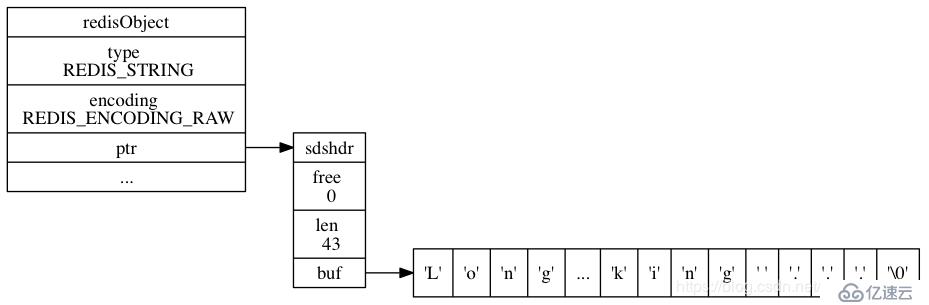
embstrе’ҢrawйғҪжҳҜз”ұredisObjectе’Ңsdsз»„жҲҗзҡ„гҖӮдёҚеҗҢзҡ„жҳҜпјҡembstrзҡ„redisObjectе’ҢsdsжҳҜиҝһз»ӯзҡ„пјҢеҸӘйңҖиҰҒдҪҝз”ЁmallocеҲҶй…ҚдёҖж¬ЎеҶ…еӯҳпјӣиҖҢrawйңҖиҰҒдёәredisObjectе’ҢsdsеҲҶеҲ«еҲҶй…ҚеҶ…еӯҳпјҢеҚійңҖиҰҒеҲҶй…ҚдёӨж¬ЎеҶ…еӯҳгҖӮ
жүҖжңүзӣёжҜ”иҫғиҖҢиЁҖпјҢembstrе°‘еҲҶй…ҚдёҖж¬ЎеҶ…еӯҳпјҢжӣҙж–№дҫҝгҖӮдҪҶembstrд№ҹжңүжҳҺжҳҫзҡ„зјәзӮ№пјҡеҰӮиҰҒеўһеҠ й•ҝеәҰпјҢredisObjectе’ҢsdsйғҪйңҖиҰҒйҮҚж–°еҲҶй…ҚеҶ…еӯҳгҖӮ
дёҠж–Үд»Ӣз»ҚдәҶembstrе’Ңrawз»“жһ„дёҠзҡ„дёҚеҗҢгҖӮйҮҚзӮ№жқҘдәҶ~
дёәд»Җд№ҲдјҡйҖүжӢ©44дҪңдёәдёӨз§Қзј–з Ғзҡ„еҲҶз•ҢзӮ№пјҹеңЁ3.2зүҲжң¬д№ӢеүҚдёәд»Җд№ҲжҳҜ39пјҹиҝҷдёӨдёӘеҖјжҳҜжҖҺд№Ҳеҫ—еҮәжқҘзҡ„е‘ўпјҹ
1пјү и®Ўз®—RedisObjectеҚ з”Ёзҡ„еӯ—иҠӮеӨ§е°Ҹ
struct RedisObject {
int4 type; // 4bits
int4 encoding; // 4bits
int24 lru; // 24bits
int32 refcount; // 4bytes = 32bits
void *ptr; // 8bytesпјҢ64-bit system
}и®Ўз®—пјҡ 4 + 4 + 24 + 32 + 64 = 128bits = 16bytes
第дёҖжӯҘе°ұе®ҢжҲҗдәҶпјҢRedisObjectеҜ№иұЎеӨҙдҝЎжҒҜдјҡеҚ з”Ё16еӯ—иҠӮзҡ„еӨ§е°ҸпјҢиҝҷдёӘеӨ§е°ҸйҖҡеёёжҳҜеӣәе®ҡдёҚеҸҳзҡ„.
2) sdsеҚ з”Ёеӯ—иҠӮеӨ§е°Ҹи®Ўз®—
ж—§зүҲжң¬пјҡ
struct SDS {
unsigned int capacity; // 4byte
unsigned int len; // 4byte
byte[] content; // еҶ…иҒ”ж•°з»„пјҢй•ҝеәҰдёә capacity
}иҝҷйҮҢзҡ„unsigned int дёҖдёӘ4еӯ—иҠӮпјҢеҠ иө·жқҘжҳҜ8еӯ—иҠӮ.
еҶ…еӯҳеҲҶй…ҚеҷЁjemallocеҲҶй…Қзҡ„еҶ…еӯҳеҰӮжһңи¶…еҮәдәҶ64дёӘеӯ—иҠӮе°ұи®ӨдёәжҳҜдёҖдёӘеӨ§еӯ—з¬ҰдёІпјҢе°ұдјҡз”ЁеҲ°rawзј–з ҒгҖӮ
еүҚйқўжҸҗеҲ° SDS з»“жһ„дҪ“дёӯзҡ„ content зҡ„еӯ—з¬ҰдёІжҳҜд»Ҙеӯ—иҠӮ\0з»“е°ҫзҡ„еӯ—з¬ҰдёІпјҢд№ӢжүҖд»ҘеӨҡеҮәиҝҷж ·дёҖдёӘеӯ—иҠӮпјҢжҳҜдёәдәҶдҫҝдәҺзӣҙжҺҘдҪҝз”Ё glibc зҡ„еӯ—з¬ҰдёІеӨ„зҗҶеҮҪж•°пјҢд»ҘеҸҠдёәдәҶдҫҝдәҺеӯ—з¬ҰдёІзҡ„и°ғиҜ•жү“еҚ°иҫ“еҮәгҖӮжүҖд»ҘжҲ‘们иҝҳиҰҒеҮҸеҺ»1еӯ—иҠӮ
64byte - 16byte - 8byte - 1byte = 39byte
ж–°зүҲжң¬пјҡ
struct SDS {
int8 capacity; // 1byte
int8 len; // 1byte
int8 flags; // 1byte
byte[] content; // еҶ…иҒ”ж•°з»„пјҢй•ҝеәҰдёә capacity
}иҝҷйҮҢunsigned int еҸҳжҲҗдәҶuint8_tгҖҒuint16_t.зҡ„еҪўејҸпјҢиҝҳеҠ дәҶдёҖдёӘchar flagsж ҮиҜҶпјҢжҖ»е…ұеҸӘз”ЁдәҶ3дёӘеӯ—иҠӮзҡ„еӨ§е°ҸгҖӮзӣёеҪ“дәҺдјҳеҢ–дәҶsdsзҡ„еҶ…еӯҳдҪҝз”ЁпјҢзӣёеә”зҡ„з”ЁдәҺеӯҳеӮЁеӯ—з¬ҰдёІзҡ„еҶ…еӯҳе°ұдјҡеҸҳеӨ§гҖӮ
然еҗҺиҝӣиЎҢи®Ўз®—пјҡ

64byte - 16byte -3byte -1byte = 44byteгҖӮ
жҖ»з»“пјҡ
жүҖд»ҘпјҢredis 3.2зүҲжң¬д№ӢеҗҺembstrжңҖеӨ§иғҪе®№зәізҡ„еӯ—з¬ҰдёІй•ҝеәҰжҳҜ44пјҢд№ӢеүҚжҳҜ39гҖӮй•ҝеәҰеҸҳеҢ–зҡ„еҺҹеӣ жҳҜSDSдёӯеҶ…еӯҳзҡ„дјҳеҢ–гҖӮ
RedisдёӯListеҜ№иұЎзҡ„еә•еұӮжҳҜз”ұquicklist(еҝ«йҖҹеҲ—иЎЁ)е®һзҺ°зҡ„пјҢеҝ«йҖҹеҲ—иЎЁж”ҜжҢҒд»Һй“ҫиЎЁеӨҙе’Ңе°ҫж·»еҠ е…ғзҙ пјҢ并且еҸҜд»ҘиҺ·еҸ–жҢҮе®ҡдҪҚзҪ®зҡ„е…ғзҙ еҶ…е®№гҖӮ
йӮЈд№ҲпјҢеҝ«йҖҹеҲ—иЎЁзҡ„еә•еұӮжҳҜеҰӮдҪ•е®һзҺ°зҡ„е‘ўпјҹдёәд»Җд№ҲиғҪеӨҹиҫҫеҲ°еҰӮжӯӨеҝ«зҡ„жҖ§иғҪпјҹ
зҪ—马дёҚжҳҜдёҖж—Ҙе»әжҲҗзҡ„пјҢquicklistд№ҹдёҚжҳҜдёҖж—Ҙе®һзҺ°зҡ„пјҢиө·еҲқredisзҡ„listзҡ„еә•еұӮжҳҜziplistпјҲеҺӢзј©еҲ—иЎЁпјүжҲ–иҖ…жҳҜ linkedlistпјҲеҸҢз«ҜеҲ—иЎЁпјүгҖӮе…ҲеҲҶеҲ«д»Ӣз»ҚиҝҷдёӨз§Қж•°жҚ®з»“жһ„гҖӮ
еҪ“дёҖдёӘеҲ—иЎЁдёӯеҸӘеҢ…еҗ«е°‘йҮҸеҲ—иЎЁйЎ№пјҢдё”жҳҜе°Ҹж•ҙж•°еҖјжҲ–й•ҝеәҰжҜ”иҫғзҹӯзҡ„еӯ—з¬ҰдёІж—¶пјҢredisе°ұдҪҝз”ЁziplistпјҲеҺӢзј©еҲ—иЎЁпјүжқҘеҒҡеҲ—иЎЁй”®зҡ„еә•еұӮе®һзҺ°гҖӮ
жөӢиҜ•пјҡ
127.0.0.1:6379> rpush dotahero sf qop doom
(integer) 3
127.0.0.1:6379> object encoding dotahero
"ziplist"жӯӨеӨ„дҪҝз”ЁиҖҒзүҲжң¬redisиҝӣиЎҢжөӢиҜ•пјҢеҗ‘dotaиӢұйӣ„еҲ—иЎЁдёӯеҠ е…ҘдәҶqopз—ӣиӢҰеҘізҺӢгҖҒsfеҪұйӯ”гҖҒdoomжң«ж—ҘдҪҝиҖ…дёүдёӘиӢұйӣ„пјҢж•°жҚ®з»“жһ„зј–з ҒдҪҝз”Ёзҡ„жҳҜziplistгҖӮ
еҺӢзј©еҲ—иЎЁйЎҫеҗҚжҖқд№үжҳҜиҝӣиЎҢдәҶеҺӢзј©пјҢжҜҸдёҖдёӘиҠӮзӮ№д№Ӣй—ҙжІЎжңүжҢҮй’Ҳзҡ„жҢҮеҗ‘пјҢиҖҢжҳҜеӨҡдёӘе…ғзҙ зӣёйӮ»пјҢжІЎжңүзјқйҡҷгҖӮжүҖд»Ҙ ziplistжҳҜRedisдёәдәҶиҠӮзәҰеҶ…еӯҳиҖҢејҖеҸ‘зҡ„пјҢжҳҜз”ұдёҖзі»еҲ—зү№ж®Ҡзј–з Ғзҡ„иҝһз»ӯеҶ…еӯҳеқ—з»„жҲҗзҡ„йЎәеәҸеһӢж•°жҚ®з»“жһ„гҖӮе…·дҪ“з»“жһ„зӣёеҜ№жҜ”иҫғеӨҚжқӮпјҢеӨ§е®¶жңүе…ҙи¶Јең°иҜқеҸҜд»Ҙж·ұе…ҘдәҶи§ЈгҖӮ
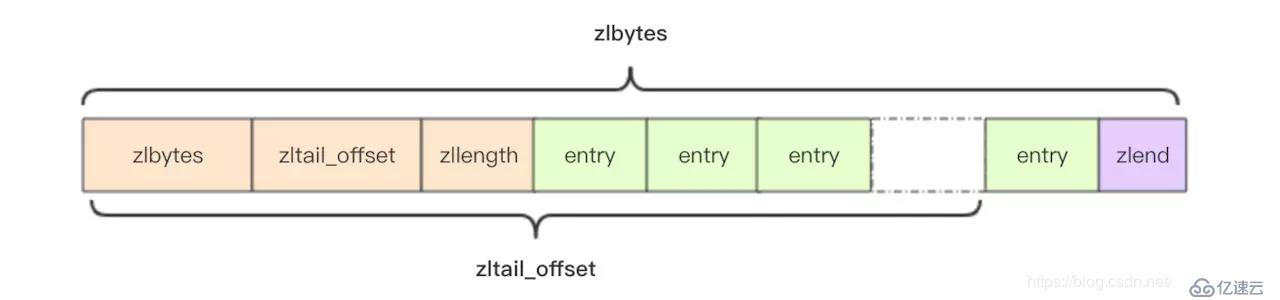
struct ziplist<T> {
int32 zlbytes; // ж•ҙдёӘеҺӢзј©еҲ—иЎЁеҚ з”Ёеӯ—иҠӮж•°
int32 zltail_offset; // жңҖеҗҺдёҖдёӘе…ғзҙ и·қзҰ»еҺӢзј©еҲ—иЎЁиө·е§ӢдҪҚзҪ®зҡ„еҒҸ移йҮҸпјҢз”ЁдәҺеҝ«йҖҹе®ҡдҪҚеҲ°жңҖеҗҺдёҖдёӘиҠӮзӮ№
int16 zllength; // е…ғзҙ дёӘж•°
T[] entries; // е…ғзҙ еҶ…е®№еҲ—иЎЁпјҢжҢЁдёӘжҢЁдёӘзҙ§еҮ‘еӯҳеӮЁ
int8 zlend; // ж Үеҝ—еҺӢзј©еҲ—иЎЁзҡ„з»“жқҹпјҢеҖјжҒ’дёә 0xFF
}
еҸҢз«ҜеҲ—иЎЁеӨ§е®¶йғҪеҫҲзҶҹжӮүпјҢиҝҷйҮҢзҡ„еҸҢз«ҜеҲ—иЎЁе’Ңjavaдёӯзҡ„linkedlistеҫҲзұ»дјјгҖӮ
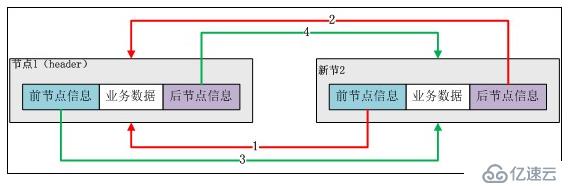
д»ҺеӣҫдёӯеҸҜд»ҘзңӢеҮәRedisзҡ„linkedlistеҸҢз«Ҝй“ҫиЎЁжңүд»ҘдёӢзү№жҖ§пјҡиҠӮзӮ№еёҰжңүprevгҖҒnextжҢҮй’ҲгҖҒheadжҢҮй’Ҳе’ҢtailжҢҮй’ҲпјҢиҺ·еҸ–еүҚзҪ®иҠӮзӮ№гҖҒеҗҺзҪ®иҠӮзӮ№гҖҒиЎЁеӨҙиҠӮзӮ№е’ҢиЎЁе°ҫиҠӮзӮ№гҖҒиҺ·еҸ–й•ҝеәҰзҡ„еӨҚжқӮеәҰйғҪжҳҜO(1)гҖӮ
еҺӢзј©еҲ—иЎЁеҚ з”ЁеҶ…еӯҳе°‘пјҢдҪҶжҳҜжҳҜйЎәеәҸеһӢзҡ„ж•°жҚ®з»“жһ„пјҢжҸ’е…ҘеҲ йҷӨе…ғзҙ зҡ„ж“ҚдҪңжҜ”иҫғеӨҚжқӮпјҢжүҖд»ҘеҺӢзј©еҲ—иЎЁйҖӮеҗҲж•°жҚ®жҜ”иҫғе°Ҹзҡ„жғ…еҶөпјҢеҪ“ж•°жҚ®жҜ”иҫғеӨҡзҡ„ж—¶еҖҷпјҢеҸҢз«ҜеҲ—иЎЁзҡ„й«ҳж•ҲжҸ’е…ҘеҲ йҷӨиҝҳжҳҜжӣҙеҘҪзҡ„йҖүжӢ©
еңЁRedisејҖеҸ‘иҖ…зҡ„зңјдёӯпјҢж•°жҚ®з»“жһ„зҡ„йҖүжӢ©пјҢж—¶й—ҙдёҠгҖҒз©әй—ҙдёҠйғҪиҰҒиҫҫеҲ°жһҒиҮҙпјҢжүҖд»ҘпјҢ他们е°ҶеҺӢзј©еҲ—иЎЁе’ҢеҸҢз«ҜеҲ—иЎЁеҗҲдәҢдёәдёҖпјҢеҲӣе»әдәҶеҝ«йҖҹеҲ—иЎЁпјҲquicklistпјүгҖӮе’Ңjavaдёӯзҡ„hashmapдёҖж ·пјҢз»“еҗҲдәҶж•°з»„е’Ңй“ҫиЎЁзҡ„дјҳзӮ№гҖӮ
struct ziplist {
...
}
struct ziplist_compressed {
int32 size;
byte[] compressed_data;
}
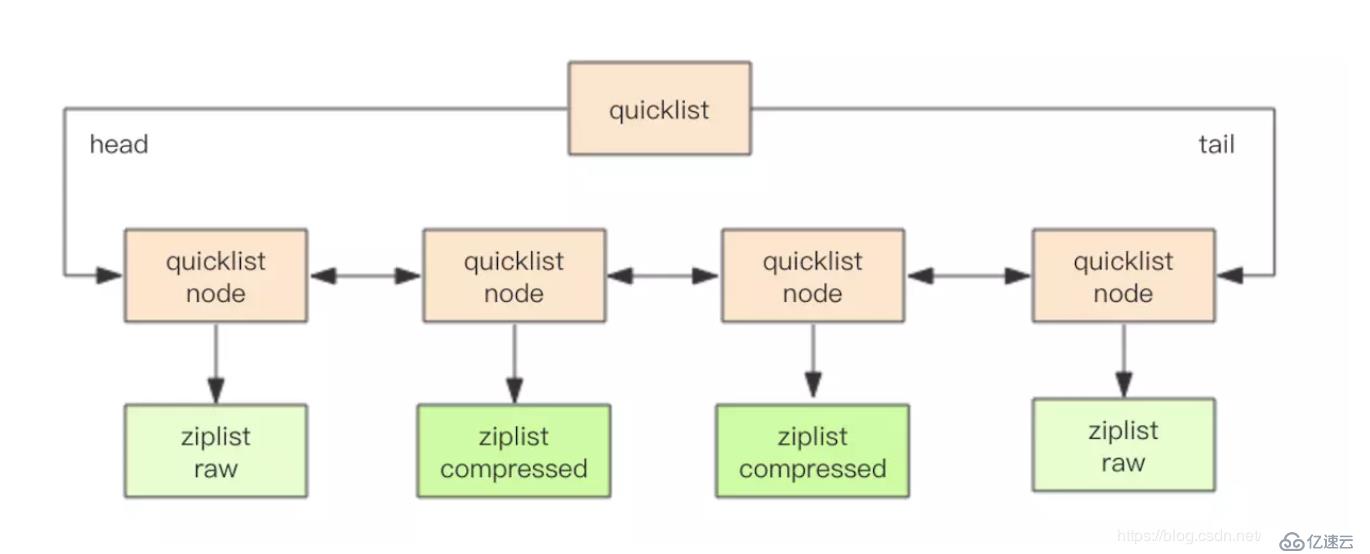
struct quicklistNode {
quicklistNode* prev;
quicklistNode* next;
ziplist* zl; // жҢҮеҗ‘еҺӢзј©еҲ—иЎЁ
int32 size; // ziplist зҡ„еӯ—иҠӮжҖ»ж•°
int16 count; // ziplist дёӯзҡ„е…ғзҙ ж•°йҮҸ
int2 encoding; // еӯҳеӮЁеҪўејҸ 2bitпјҢеҺҹз”ҹеӯ—иҠӮж•°з»„иҝҳжҳҜ LZF еҺӢзј©еӯҳеӮЁ
...
}
struct quicklist {
quicklistNode* head;
quicklistNode* tail;
long count; // е…ғзҙ жҖ»ж•°
int nodes; // ziplist иҠӮзӮ№зҡ„дёӘж•°
int compressDepth; // LZF з®—жі•еҺӢзј©ж·ұеәҰ
...
}quicklist й»ҳи®Өзҡ„еҺӢзј©ж·ұеәҰжҳҜ 0пјҢд№ҹе°ұжҳҜдёҚеҺӢзј©гҖӮеҺӢзј©зҡ„е®һйҷ…ж·ұеәҰз”ұй…ҚзҪ®еҸӮж•°list-compress-depthеҶіе®ҡгҖӮдёәдәҶж”ҜжҢҒеҝ«йҖҹзҡ„ push/pop ж“ҚдҪңпјҢquicklist зҡ„йҰ–е°ҫдёӨдёӘ ziplist дёҚеҺӢзј©пјҢжӯӨж—¶ж·ұеәҰе°ұжҳҜ 1гҖӮеҰӮжһңж·ұеәҰдёә 2пјҢиЎЁзӨә quicklist зҡ„йҰ–е°ҫ第дёҖдёӘ ziplist д»ҘеҸҠйҰ–е°ҫ第дәҢдёӘ ziplist йғҪдёҚеҺӢзј©гҖӮ
Hashж•°жҚ®зұ»еһӢзҡ„еә•еұӮе®һзҺ°жҳҜziplistпјҲеҺӢзј©еҲ—иЎЁпјүжҲ–еӯ—е…ёпјҲд№ҹз§°дёәhashtableжҲ–ж•ЈеҲ—иЎЁпјүгҖӮиҝҷйҮҢеҺӢзј©еҲ—иЎЁжҲ–иҖ…еӯ—е…ёзҡ„йҖүжӢ©пјҢд№ҹжҳҜж №жҚ®е…ғзҙ зҡ„ж•°йҮҸеӨ§е°ҸеҶіе®ҡзҡ„гҖӮ

еҰӮеӣҫhsetдәҶдёүдёӘй”®еҖјеҜ№пјҢжҜҸдёӘеҖјзҡ„еӯ—иҠӮж•°дёҚи¶…иҝҮ64зҡ„ж—¶еҖҷпјҢй»ҳи®ӨдҪҝз”Ёзҡ„ж•°жҚ®з»“жһ„жҳҜziplistгҖӮ

еҪ“жҲ‘们еҠ е…ҘдәҶеӯ—иҠӮж•°и¶…иҝҮ64зҡ„еҖјзҡ„ж•°жҚ®ж—¶пјҢй»ҳи®Өзҡ„ж•°жҚ®з»“жһ„е·Із»ҸжҲҗдёәдәҶhashtableгҖӮ
HashеҜ№иұЎеҸӘжңүеҗҢж—¶ж»Ўи¶ідёӢйқўдёӨдёӘжқЎд»¶ж—¶пјҢжүҚдјҡдҪҝз”ЁziplistпјҲеҺӢзј©еҲ—иЎЁпјүпјҡ
еҺӢзј©еҲ—иЎЁеҲҡжүҚе·Із»ҸдәҶи§ЈдәҶпјҢhashtablesзұ»дјјдәҺjdk1.7д»ҘеүҚзҡ„hashmapгҖӮhashmapйҮҮз”ЁдәҶй“ҫең°еқҖжі•зҡ„ж–№жі•и§ЈеҶідәҶе“ҲеёҢеҶІзӘҒзҡ„й—®йўҳгҖӮ
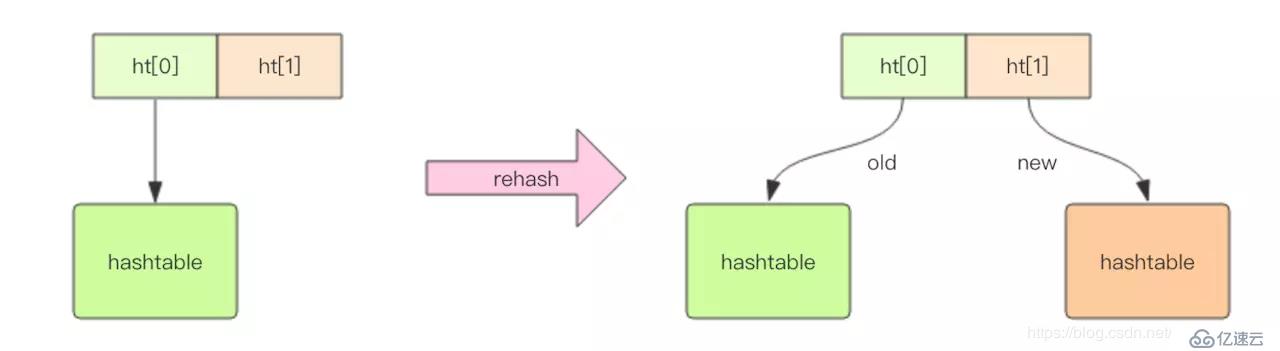
redisдёӯзҡ„dict з»“жһ„еҶ…йғЁеҢ…еҗ«дёӨдёӘ hashtableпјҢйҖҡеёёжғ…еҶөдёӢеҸӘжңүдёҖдёӘ hashtable жҳҜжңүеҖјзҡ„гҖӮдҪҶжҳҜеңЁ dict жү©е®№зј©е®№ж—¶пјҢйңҖиҰҒеҲҶй…Қж–°зҡ„ hashtableпјҢ然еҗҺиҝӣиЎҢжёҗиҝӣејҸжҗ¬иҝҒпјҢиҝҷж—¶дёӨдёӘ hashtable еӯҳеӮЁзҡ„еҲҶеҲ«жҳҜж—§зҡ„ hashtable е’Ңж–°зҡ„ hashtableгҖӮеҫ…жҗ¬иҝҒз»“жқҹеҗҺпјҢж—§зҡ„ hashtable иў«еҲ йҷӨпјҢж–°зҡ„ hashtable еҸ–иҖҢд»Јд№ӢгҖӮ
Setж•°жҚ®зұ»еһӢзҡ„еә•еұӮеҸҜд»ҘжҳҜintset(ж•ҙж•°йӣҶ)жҲ–иҖ…жҳҜhashtable(ж•ЈеҲ—иЎЁд№ҹеҸ«е“ҲеёҢиЎЁ)гҖӮ
еҪ“ж•°жҚ®йғҪжҳҜж•ҙ数并且数йҮҸдёҚеӨҡж—¶пјҢдҪҝз”ЁintsetдҪңдёәеә•еұӮж•°жҚ®з»“жһ„пјӣеҪ“жңүйҷӨж•ҙж•°д»ҘеӨ–зҡ„ж•°жҚ®жҲ–иҖ…ж•°жҚ®йҮҸеўһеӨҡж—¶пјҢдҪҝз”ЁhashtableдҪңдёәеә•еұӮж•°жҚ®з»“жһ„гҖӮ
127.0.0.1:6379> sadd myset 111 222 333
(integer) 3
127.0.0.1:6379> object encoding myset
"intset"
127.0.0.1:6379> sadd myset hahaha
(integer) 1
127.0.0.1:6379> object encoding myset
"hashtable"insetзҡ„ж•°жҚ®з»“жһ„дёәпјҡ
typedef struct intset {
// зј–з Ғж–№ејҸ
uint32_t encoding;
// йӣҶеҗҲеҢ…еҗ«зҡ„е…ғзҙ ж•°йҮҸ
uint32_t length;
// дҝқеӯҳе…ғзҙ зҡ„ж•°з»„
int8_t contents[];
} intset;intsetеә•еұӮе®һзҺ°дёәжңүеәҸгҖҒж— йҮҚеӨҚж•°зҡ„ж•°з»„гҖӮ intsetзҡ„ж•ҙж•°зұ»еһӢеҸҜд»ҘжҳҜ16дҪҚзҡ„гҖҒ32дҪҚзҡ„гҖҒ64дҪҚзҡ„гҖӮеҰӮжһңж•°з»„йҮҢжүҖжңүзҡ„ж•ҙж•°йғҪжҳҜ16дҪҚй•ҝеәҰзҡ„пјҢж–°еҠ е…ҘдёҖдёӘ32дҪҚзҡ„ж•ҙж•°пјҢйӮЈд№Ҳж•ҙдёӘ16зҡ„ж•°з»„е°ҶеҚҮзә§жҲҗдёҖдёӘ32дҪҚзҡ„ж•°з»„гҖӮеҚҮзә§еҸҜд»ҘжҸҗеҚҮintsetзҡ„зҒөжҙ»жҖ§пјҢеҸҲеҸҜд»ҘиҠӮзәҰеҶ…еӯҳпјҢдҪҶдёҚеҸҜйҖҶгҖӮ
Redisдёӯзҡ„ZsetпјҢд№ҹеҸ«еҒҡжңүеәҸйӣҶеҗҲгҖӮе®ғзҡ„еә•еұӮжҳҜziplistпјҲеҺӢзј©еҲ—иЎЁпјүжҲ– skiplistпјҲи·іи·ғиЎЁпјүгҖӮ
еҺӢзј©еҲ—иЎЁеүҚж–Үе·Із»Ҹд»Ӣз»ҚиҝҮдәҶпјҢеҗҢзҗҶжҳҜеңЁе…ғзҙ ж•°йҮҸжҜ”иҫғе°‘зҡ„ж—¶еҖҷдҪҝз”ЁгҖӮжӯӨеӨ„дё»иҰҒд»Ӣз»Қи·іи·ғеҲ—иЎЁгҖӮ
и·іи·ғеҲ—иЎЁпјҢйЎҫеҗҚжҖқд№үжҳҜеҸҜд»Ҙи·ізҡ„пјҢи·ізқҖжҹҘиҜўиҮӘе·ұжғіиҰҒжҹҘеҲ°зҡ„е…ғзҙ гҖӮеӨ§е®¶еҸҜиғҪеҜ№иҝҷз§Қж•°жҚ®з»“жһ„жҜ”иҫғйҷҢз”ҹпјҢиҷҪ然平时жҺҘи§Ұзҡ„е°‘пјҢдҪҶе®ғзЎ®е®һжҳҜдёҖдёӘеҗ„ж–№йқўжҖ§иғҪйғҪеҫҲеҘҪзҡ„ж•°жҚ®з»“жһ„пјҢеҸҜд»Ҙж”ҜжҢҒеҝ«йҖҹзҡ„жҹҘиҜўгҖҒжҸ’е…ҘгҖҒеҲ йҷӨж“ҚдҪңпјҢејҖеҸ‘йҡҫеәҰд№ҹжҜ”зәўй»‘ж ‘иҰҒе®№жҳ“зҡ„еӨҡгҖӮ
дёәд»Җд№Ҳи·іиЎЁжңүеҰӮжӯӨй«ҳзҡ„жҖ§иғҪе‘ўпјҹе®ғ究з«ҹжҳҜеҰӮдҪ•вҖңи·івҖқзҡ„е‘ўпјҹи·іиЎЁеҲ©з”ЁдәҶдәҢеҲҶзҡ„жҖқжғіпјҢеңЁж•°з»„дёӯеҸҜд»Ҙз”ЁдәҢеҲҶжі•жқҘеҝ«йҖҹиҝӣиЎҢжҹҘжүҫпјҢеңЁй“ҫиЎЁдёӯд№ҹжҳҜеҸҜд»Ҙзҡ„гҖӮ
дёҫдёӘдҫӢеӯҗпјҢй“ҫиЎЁеҰӮдёӢпјҡ

еҒҮи®ҫиҰҒжүҫеҲ°10иҝҷдёӘиҠӮзӮ№пјҢйңҖиҰҒдёҖдёӘдёҖдёӘеҺ»йҒҚеҺҶпјҢеҲӨж–ӯжҳҜдёҚжҳҜиҰҒжүҫзҡ„иҠӮзӮ№гҖӮйӮЈеҰӮдҪ•жҸҗй«ҳж•ҲзҺҮе‘ўпјҹmysqlзҙўеј•зӣёдҝЎеӨ§е®¶йғҪеҫҲзҶҹжӮүпјҢеҸҜд»ҘжҸҗй«ҳж•ҲзҺҮпјҢиҝҷйҮҢд№ҹеҸҜд»ҘдҪҝз”Ёзҙўеј•гҖӮжҠҪеҮәдёҖдёӘзҙўеј•еұӮжқҘпјҡ
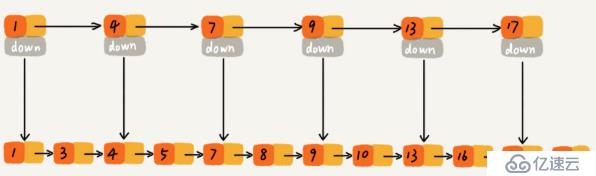
иҝҷж ·еҸӘйңҖиҰҒжүҫеҲ°9然еҗҺеҶҚжүҫ10е°ұеҸҜд»ҘдәҶпјҢеӨ§еӨ§иҠӮзңҒдәҶжҹҘжүҫзҡ„ж—¶й—ҙгҖӮ
иҝҳеҸҜд»ҘеҶҚжҠҪеҮәжқҘдёҖеұӮзҙўеј•пјҢеҸҜд»ҘжӣҙеҘҪең°иҠӮзәҰж—¶й—ҙ:
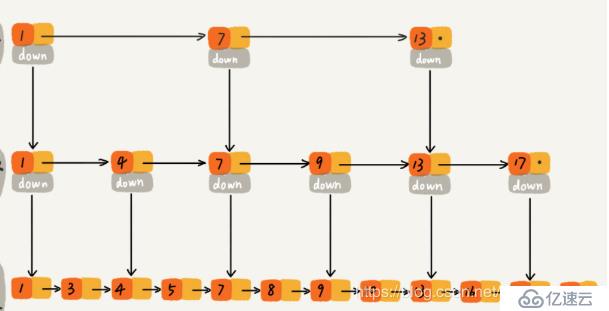
иҝҷж ·еҹәдәҺй“ҫиЎЁзҡ„вҖңдәҢеҲҶжҹҘжүҫвҖқж”ҜжҢҒеҝ«йҖҹзҡ„жҸ’е…ҘгҖҒеҲ йҷӨпјҢж—¶й—ҙеӨҚжқӮеәҰйғҪжҳҜO(logn)гҖӮ
з”ұдәҺи·іиЎЁзҡ„еҝ«йҖҹжҹҘжүҫж•ҲзҺҮпјҢд»ҘеҸҠе®һзҺ°зҡ„з®ҖеҚ•гҖҒжҳ“иҜ»гҖӮжүҖд»ҘRedisж”ҫејғдәҶзәўй»‘ж ‘иҖҢйҖүжӢ©дәҶжӣҙдёәз®ҖеҚ•зҡ„и·іиЎЁгҖӮ
Redisдёӯзҡ„и·іи·ғиЎЁпјҡ
typedef struct zskiplist {
// иЎЁеӨҙиҠӮзӮ№е’ҢиЎЁе°ҫиҠӮзӮ№
struct zskiplistNode *header, *tail;
// иЎЁдёӯиҠӮзӮ№зҡ„ж•°йҮҸ
unsigned long length;
// иЎЁдёӯеұӮж•°жңҖеӨ§зҡ„иҠӮзӮ№зҡ„еұӮж•°
int level;
} zskiplist;
typedef struct zskiplistNode {
// жҲҗе‘ҳеҜ№иұЎ
robj *obj;
// еҲҶеҖј
double score;
// еҗҺйҖҖжҢҮй’Ҳ
struct zskiplistNode *backward;
// еұӮ
struct zskiplistLevel {
// еүҚиҝӣжҢҮй’Ҳ
struct zskiplistNode *forward;
// и·ЁеәҰ---еүҚиҝӣжҢҮй’ҲжүҖжҢҮеҗ‘иҠӮзӮ№дёҺеҪ“еүҚиҠӮзӮ№зҡ„и·қзҰ»
unsigned int span;
} level[];
} zskiplistNode;zadd---zslinsert---е№іеқҮO(logN), жңҖеқҸO(N)
zrem---zsldelete---е№іеқҮO(logN), жңҖеқҸO(N)
zrank--zslGetRank---е№іеқҮO(logN), жңҖеқҸO(N)
жң¬ж–ҮеӨ§жҰӮд»Ӣз»ҚдәҶRedisзҡ„5з§Қеёёз”Ёж•°жҚ®зұ»еһӢзҡ„еә•еұӮе®һзҺ°пјҢеёҢжңӣеӨ§е®¶з»“еҗҲжәҗз Ғе’Ңиө„ж–ҷжӣҙж·ұе…Ҙең°дәҶи§ЈгҖӮ
ж•°жҚ®з»“жһ„д№ӢзҫҺеңЁRedisдёӯдҪ“зҺ°еҫ—ж·Ӣжј“е°ҪиҮҙпјҢд»ҺStringеҲ°еҺӢзј©еҲ—иЎЁгҖҒеҝ«йҖҹеҲ—иЎЁгҖҒж•ЈеҲ—иЎЁгҖҒи·іиЎЁпјҢиҝҷдәӣж•°жҚ®з»“жһ„йғҪйҖӮз”ЁеңЁдәҶдёҚеҗҢзҡ„ең°ж–№пјҢеҗ„еҸёе…¶иҒҢгҖӮ
дёҚд»…еҰӮжӯӨпјҢRedisе°Ҷиҝҷдәӣж•°жҚ®з»“жһ„еҠ д»ҘеҚҮзә§гҖҒз»“еҗҲпјҢе°ҶеҶ…еӯҳеӯҳеӮЁзҡ„ж•ҲзҺҮжҖ§иғҪиҫҫеҲ°дәҶжһҒиҮҙпјҢжӯЈеӣ дёәеҰӮжӯӨпјҢRedisжүҚиғҪжҲҗдёәдј—еӨҡдә’иҒ”зҪ‘е…¬еҸёдёҚеҸҜзјәе°‘зҡ„й«ҳжҖ§иғҪгҖҒз§’зә§зҡ„key-valueеҶ…еӯҳж•°жҚ®еә“гҖӮ
дҪңиҖ…пјҡжқЁдәЁ
жӢ“еұ•йҳ…иҜ»пјҡRedisй—Іи°ҲпјҲ1пјүпјҡжһ„е»әзҹҘиҜҶеӣҫи°ұ
жқҘжәҗпјҡе®ңдҝЎжҠҖжңҜеӯҰйҷў
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ