您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
一、索引结构
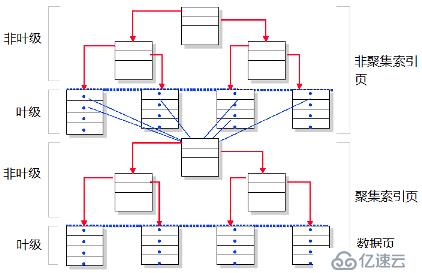
在聚集索引上建立非聚集索引,在日常应用中经常发生。
二、实验[三E]
继续使用上一篇文章中创建的唯一聚集索引,在此基础之上新建一个非聚集索引。
1. 创建非聚集索引
| CREATE INDEX IX_person1_UserIDModifyDate ON person1 (UserID,ModifyDate) |
2. 查看索引占用的空间
| DBCC SHOWCONTIG ('person1') WITH ALL_INDEXES |
结果如下:
| DBCC SHOWCONTIG 正在扫描 'person1' 表... 表: 'person1' (389576426);索引 ID: 1,数据库 ID: 8 已执行 TABLE 级别的扫描。 - 扫描页数................................: 4000 - 扫描区数..............................: 500 - 区切换次数..............................: 499 - 每个区的平均页数........................: 8.0 - 扫描密度 [最佳计数:实际计数].......: 100.00% [500:500] - 逻辑扫描碎片 ..................: 0.03% - 区扫描碎片 ..................: 2.20% - 每页的平均可用字节数.....................: 76.0 - 平均页密度(满).....................: 99.06% DBCC SHOWCONTIG 正在扫描 'person1' 表... 已执行 LEAF 级别的扫描。 - 扫描页数................................: 179 - 扫描区数..............................: 23 - 区切换次数..............................: 22 - 每个区的平均页数........................: 7.8 - 扫描密度 [最佳计数:实际计数].......: 100.00% [23:23] - 逻辑扫描碎片 ..................: 0.00% - 区扫描碎片 ..................: 4.35% - 每页的平均可用字节数.....................: 51.3 - 平均页密度(满).....................: 99.37% DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。 |
3. 查看索引的层次
对于建立在聚集索引上的非聚集索引,
| SELECT index_depth, index_level, record_count, page_count, min_record_size_in_bytes as 'MinLen', max_record_size_in_bytes as 'MaxLen', avg_record_size_in_bytes as 'AvgLen', convert(decimal(6,2),avg_page_space_used_in_percent) as 'PageDensity' FROM sys.dm_db_index_physical_stats (8, OBJECT_ID('person1'),2,NULL,'DETAILED') |
结果如下表所示:
index _depth | Index _level | Record _count | Page _count | MinLen | MaxLen | AvgLen | PageDensity |
2 | 0 | 80000 | 179 | 16 | 16 | 16 | 99.36 |
2 | 1 | 179 | 1 | 22 | 22 | 22 | 53.05 |
根据上表的数据,可以发现它与堆上的非聚集索引的数据是一样的。该索引共有2层。level=0 是叶级,它有179个页面,指向底层的聚集索引的根页;level=1 是这个非聚集索引的根页,它只有1个页面,指向叶级的179个索引页。
三、比较三类索引占用的页数
比较前面几个实验,各类索引占用的页数如下:
1. 堆
在实验[三A]中,堆是最原始的结构,index_id = 0,存储了 80000 条记录,占用了4000 页。
2. 聚集索引
聚集索引的 index_id = 1。
唯一聚集索引在叶级将数据页重新进行物理排序,不会额外增加数据页。由于索引宽度固定,因此在根级只占用了1个页,中间级占用了7个页。一共占用了1+7+4000=4008 页。与堆相比,非叶级的索引页多了8页。
非唯一聚集索引需要在后台保持数据的唯一,因此在后台增加了一个 4 字节的uniqueifier 列,有可能需要增加额外的数据页。在前面的案例中,非唯一聚集索引使用了4009页,也就是多了9个页。同时由于索引宽度的开销较大,中间级占用了10个页,加上根级占用了1个页,一共占用了1+10+4009=4020 页。与堆相比,叶级索引页(数据页)多了9页,非叶级的索引页多了11页。
3. 非聚集索引
堆上的非聚集索引与聚集索引上的非聚集索引,index_id >= 2,占用了相同数量的索引页面,页面数量为:179+1=180 页。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。