жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
дёҖгҖҒз”ҹжҲҗејҸ
1гҖҒе®ҡд№ү
з”ҹжҲҗејҸе°ұжҳҜдёҖдёӘз”ЁжқҘеҝ«йҖҹз”ҹжҲҗзү№е®ҡиҜӯжі•еҪўејҸзҡ„иЎЁиҫҫејҸгҖӮ
еҲ—иЎЁз”ҹжҲҗејҸпјҡз”ЁжқҘеҝ«йҖҹз”ҹжҲҗеҲ—иЎЁ
еӯ—е…ёз”ҹжҲҗејҸпјҡз”ЁжқҘеҝ«йҖҹз”ҹжҲҗеӯ—е…ё
йӣҶеҗҲз”ҹжҲҗејҸпјҡз”ЁжқҘеҝ«йҖҹз”ҹжҲҗйӣҶеҗҲ
2гҖҒиҜӯжі•ж јејҸ
пјҲ1пјүжҷ®йҖҡзҡ„иҜӯжі•ж јејҸпјҡ[exp for iter_var in iterable]
пјҲ2пјүеёҰиҝҮж»ӨеҠҹиғҪиҜӯжі•ж јејҸ: [exp for iter_var in iterable if_exp]
пјҲ3пјүеҫӘзҺҜеөҢеҘ—иҜӯжі•ж јејҸ: [exp for iter_var_A in iterable_A for iter_var_B in iterable_B]
#йңҖжұӮ: з”ҹжҲҗ100дёӘ1пҪһ50д№Ӣй—ҙзҡ„йҡҸжңәж•°еҖјгҖӮ
import random
def use_list_expression(count=100, start=0, end=50):
"""第дёҖз§Қпјҡ дҪҝз”ЁеҲ—иЎЁз”ҹжҲҗејҸе®һзҺ°йңҖжұӮ"""
return [random.randint(start, end) for count in range(count)]
def use_loop(count=100, start=0, end=50):
"""第дәҢз§Қ: дҪҝз”ЁforеҫӘзҺҜдёҺдј з»ҹзҡ„ж–№ејҸе®һзҺ°йңҖжұӮ"""
nums = []
for count in range(count):
num = random.randint(start, end)
nums.append(num)
return nums
print(use_list_expression(count=5))
print(use_loop(count=8))"""#йңҖжұӮ: жүҫеҮә1-100д№Ӣй—ҙиғҪиў«3ж•ҙйҷӨзҡ„ж•°еҖј;
def use_loop(start=1, end=100, div_num=3):
"""дҪҝз”Ёдј з»ҹзҡ„ж–№ејҸе®һзҺ°йңҖжұӮ"""
nums = []
for num in range(start, end + 1):
if num % div_num == 0:
nums.append(num)
return nums
def use_list_expression(start=1, end=100, div_num=3):
"""дҪҝз”ЁеҲ—иЎЁз”ҹжҲҗејҸе®һзҺ°йңҖжұӮ"""
return [num for num in range(start, end + 1) if num % div_num == 0]
print(use_loop(1, 10, 4))
print(use_loop(div_num=50))
"""nums = [item1+ item2 for item1 in 'abc' for item2 in '123']
print(nums)
nums = []
for item1 in 'abc': # item1='a' item1='b' item1='c'
for item2 in '123': # item2='1', '2', '3' item2='1', '2', '3' item2='1', '2', '3'
nums.append(item1 + item2)
print(nums)#йңҖжұӮ: з”ҹжҲҗ100дёӘ1пҪһ200д№Ӣй—ҙзҡ„йҡҸжңәдё”дёҚйҮҚеӨҚж•°еҖјгҖӮ
import random
nums = {random.randint(1, 200) for count in range(100)}
print(nums)
nulldict = {
'key1' : 'value1',
'key1' : 'value1'
}
import pprint
#йңҖжұӮ: з”ҹжҲҗ100дёӘз”ЁжҲ·еӯ—е…ё, keyжҳҜз”ЁжҲ·еҗҚuserx(x=1, 2, 3, ....), valueжҳҜеҜҶз Ғpasswordx(x=1, 2, 3...)
users_info = {'user' + str(x+1): 'password'+ str(x+1) for x in range(100)}
pprint.pprint(users_info)"""
nullimport math
def circle_example():
"""жұӮд»ҘrдёәеҚҠеҫ„зҡ„еңҶзҡ„йқўз§Ҝе’Ңе‘Ёй•ҝ(rзҡ„иҢғеӣҙд»Һ1еҲ°10)гҖӮ"""
square = lambda r: math.pi * (r ** 2)
C = lambda r: 2 * math.pi * r
return [(square(r), C(r)) for r in range(1, 11)]
def swap_key_value(dictObj):
"""е°Ҷеӯ—е…ёзҡ„keyеҖје’ҢvalueеҖји°ғжҚў"""
return {value: key for key, value in dictObj.items()}
def is_prime(num):
"""еҲӨж–ӯnumжҳҜеҗҰдёәиҙЁж•°пјҹеҰӮжһңжҳҜпјҢиҝ”еӣһTrue, еҗҰеҲҷиҝ”еӣһFalse. е…·дҪ“зҡ„д»Јз ҒиҮӘиЎҢиЎҘе……е®Ңж•ҙ"""
return True
def find_prime():
"""жүҫеҮә1~100д№Ӣй—ҙжүҖжңүзҡ„иҙЁж•°"""
return [num for num in range(1, 101) if is_prime(num)]
if __name__ == '__main__':
result1 = circle_example()
print(result1)
d = {
'user1': 'passwd1',
'user2': 'passwd2',
}
result2 = swap_key_value(d)
print(result2)дәҢгҖҒз”ҹжҲҗеҷЁ
1гҖҒе®ҡд№үе’Ңзү№зӮ№
пјҲ1пјүеңЁpythonдёӯ,дёҖиҫ№еҫӘзҺҜдёҖиҫ№и®Ўз®—зҡ„жңәеҲ¶,з§°дёәз”ҹжҲҗеҷЁ(Generator)
пјҲ2пјүеә”з”ЁеңәжҷҜпјҡ
жҖ§иғҪйҷҗеҲ¶йңҖиҰҒз”ЁеҲ°пјҢжҜ”еҰӮиҜ»еҸ–дёҖдёӘ10Gзҡ„ж–Ү件,еҰӮжһңдёҖж¬ЎжҖ§е°Ҷ10Gзҡ„ж–Ү件еҠ иҪҪеҲ°еҶ…еӯҳеӨ„зҗҶзҡ„иҜқ (readж–№жі•)пјҢеҶ…еӯҳиӮҜе®ҡдјҡжәўеҮәгҖӮдҪҶдҪҝз”Ёз”ҹжҲҗеҷЁжҠҠиҜ»еҶҷдәӨеҸүеӨ„зҗҶиҝӣиЎҢ,жҜ”еҰӮдҪҝз”Ё(readlineе’Ңreadlines) е°ұеҸҜд»ҘеҶҚеҫӘзҺҜиҜ»еҸ–зҡ„еҗҢж—¶дёҚж–ӯеӨ„зҗҶ,иҝҷж ·е°ұеҸҜд»ҘиҠӮзңҒеӨ§йҮҸзҡ„еҶ…еӯҳз©әй—ҙгҖӮ
пјҲ3пјүзү№зӮ№:
1> и§ЈиҖҰгҖӮ зҲ¬иҷ«дёҺж•°жҚ®еӯҳеӮЁи§ЈиҖҰ;
2> еҮҸе°‘еҶ…еӯҳеҚ з”Ё.гҖӮйҡҸж—¶з”ҹдә§, еҚіж—¶ж¶Ҳиҙ№, дёҚз”Ёе Ҷз§ҜеңЁеҶ…еӯҳеҪ“дёӯ;
3> еҸҜдёҚз»Ҳжӯўи°ғз”Ё.гҖӮеҶҷдёҠеҫӘзҺҜ, еҚіеҸҜеҫӘзҺҜжҺҘ收数жҚ®, еҜ№еңЁеҫӘзҺҜд№ӢеүҚе®ҡд№үзҡ„еҸҳйҮҸ, еҸҜйҮҚеӨҚдҪҝз”Ё;
4> з”ҹжҲҗеҷЁзҡ„еҫӘзҺҜ, еңЁ yield еӨ„дёӯж–ӯ, жІЎйӮЈд№ҲеҚ cpu
2гҖҒеҲӣе»әе’Ңи®ҝй—®
пјҲ1пјүеҲӣе»әпјҡ
ж–№жі•дёҖпјҡеҲ—иЎЁз”ҹжҲҗејҸзҡ„ж”№еҶҷгҖӮ []ж”№жҲҗ()
ж–№жі•дәҢпјҡyieldе…ій”®еӯ—
пјҲ2пјүи®ҝй—®пјҡ
ж–№жі•дёҖпјҡйҖҡиҝҮforеҫӘзҺҜпјҢ дҫқ次计算并з”ҹжҲҗжҜҸдёҖдёӘе…ғзҙ
ж–№жі•дәҢпјҡйҖҡиҝҮ next() еҮҪж•°дёҖдёӘдёҖдёӘиҺ·еҸ–
第дёҖз§Қж–№жі•: еҲ—иЎЁз”ҹжҲҗејҸзҡ„ж”№еҶҷгҖӮ []ж”№жҲҗ()
#еҲ—иЎЁз”ҹжҲҗејҸ
nums = [num for num in range(1, 10001) if num % 8 == 0]
print(nums)#з”ҹжҲҗеҷЁеҲӣе»ә
nums_gen = (num for num in range(1, 10001) if num % 8 == 0)
print(nums_gen) # <generator object <genexpr> at 0x7f8f2cb92350>
print(type(nums_gen)) # <class 'generator'>#жҹҘзңӢдёҖдёӘеҜ№иұЎжҳҜеҗҰеҸҜд»ҘforеҫӘзҺҜ?
from collections.abc import Iterable
print("з”ҹжҲҗеҷЁжҳҜеҗҰдёәеҸҜиҝӯд»ЈеҜ№иұЎ?", isinstance(nums_gen, Iterable))
#и®ҝй—®з”ҹжҲҗеҷЁеҜ№иұЎе…ғзҙ зҡ„ж–№жі•дёҖ: йҖҡиҝҮforеҫӘзҺҜ, дҫқ次计算并з”ҹжҲҗжҜҸдёҖдёӘе…ғзҙ гҖӮ
"""
for num in nums_gen:
if num > 50:
break
print(num)
"""#и®ҝй—®з”ҹжҲҗеҷЁеҜ№иұЎе…ғзҙ зҡ„ж–№жі•дәҢ: еҰӮжһңиҰҒдёҖдёӘдёҖдёӘжү“еҚ°еҮәжқҘ,еҸҜд»ҘйҖҡиҝҮnext()еҮҪж•°иҺ·еҫ—з”ҹжҲҗеҷЁзҡ„дёӢдёҖдёӘиҝ”еӣһеҖјгҖӮ
print(next(nums_gen)) #жү§иЎҢдёҖж¬Ўnextз”ҹжҲҗдёҖдёӘеҖј
print(next(nums_gen))
print(next(nums_gen))
"""
Fibж•°еҲ—зҡ„жЎҲдҫӢзҗҶи§Јз”ҹжҲҗеҷЁзҡ„еҲӣе»ә
"""
def fib1(num):
"""йҖ’еҪ’е®һзҺ°Fibж•°еҲ—"""
if num in (1, 2):
return 1
return fib1(num - 1) + fib1(num - 2)#第дәҢз§Қж–№жі•: еҮҪж•°дёӯеҢ…еҗ«yieldе…ій”®еӯ—
def fib2(num):
"""дёҚдҪҝз”ЁйҖ’еҪ’ж–№ејҸе®һзҺ°Fibж•°еҲ—"""
count = 0
a = b = 1
while True:
if count < num:
count += 1
yield a
a, b = b, a + b
else:
break#еҰӮжһңеҮҪж•°дёӯжңүyieldе…ій”®еӯ—пјҢ йӮЈд№ҲеҮҪж•°зҡ„иҝ”еӣһеҖјжҳҜз”ҹжҲҗеҷЁеҜ№иұЎ.
result = fib2(100)
print(result)#и®ҝй—®з”ҹжҲҗеҷЁеҜ№иұЎе…ғзҙ зҡ„ж–№жі•дёҖ: йҖҡиҝҮforеҫӘзҺҜ, дҫқ次计算并з”ҹжҲҗжҜҸдёҖдёӘе…ғзҙ гҖӮ
"""
for num in result:
if num > 50:
break
print(num)
"""#и®ҝй—®з”ҹжҲҗеҷЁеҜ№иұЎе…ғзҙ зҡ„ж–№жі•дәҢ: еҰӮжһңиҰҒдёҖдёӘдёҖдёӘжү“еҚ°еҮәжқҘ,еҸҜд»ҘйҖҡиҝҮnext()еҮҪж•°иҺ·еҫ—з”ҹжҲҗеҷЁзҡ„дёӢдёҖдёӘиҝ”еӣһеҖјгҖӮ
print(next(result)) # жү§иЎҢдёҖж¬Ўnextз”ҹжҲҗдёҖдёӘеҖј
print(next(result))
print(next(result))
"""
yield:
еҮҪж•°дёӯеҢ…еҗ«yieldе…ій”®еӯ—пјҢ иҝ”еӣһзҡ„жҳҜз”ҹжҲҗеҷЁеҜ№иұЎ
еҪ“第дёҖж¬Ўи°ғз”Ёnext(genObj)пјҢ жүҚејҖе§Ӣжү§иЎҢеҮҪж•°еҶ…е®№гҖӮ
йҒҮеҲ°yieldе…ій”®еӯ—, жү§иЎҢеҒңжӯўгҖӮ
еҶҚж¬Ўи°ғз”Ёnextж–№жі•ж—¶пјҢ д»ҺдёҠж¬ЎеҒңжӯўзҡ„д»Јз ҒдҪҚзҪ®з»§з»ӯжү§иЎҢгҖӮ
йҒҮеҲ°yieldе…ій”®еӯ—, жү§иЎҢеҒңжӯўгҖӮ
"""
#def return_example():
#зҗҶи§Јreturnзҡ„е·ҘдҪңеҺҹзҗҶ
#1). еҮҪж•°иҝҗиЎҢз»“жһңжҳҜд»Җд№Ҳ?
#2). жҳҜеҗҰдјҡжү“еҚ°'step 1'? why?
#3). жҳҜеҗҰдјҡжү“еҚ°'step 2'? why?
#"""
#print('step 1')
##еҮҪж•°йҒҮеҲ°returnпјҢ еҮҪж•°ж—§жү§иЎҢз»“жқҹгҖӮ еҗҺйқўзҡ„д»Јз ҒдёҚдјҡжү§иЎҢзҡ„гҖӮ
#return True
#print('step 2')
def yield_example():
"""
зҗҶи§Јyieldзҡ„е·ҘдҪңеҺҹзҗҶ
1). еҮҪж•°зҡ„иҝҗиЎҢз»“жһңжҳҜд»Җд№Ҳ?
еҮҪж•°дёӯеҢ…еҗ«yieldе…ій”®еӯ—пјҢ иҝ”еӣһзҡ„жҳҜз”ҹжҲҗеҷЁеҜ№иұЎгҖӮ
еҪ“第дёҖж¬Ўи°ғз”Ёnext(genObj)пјҢ жүҚжү§иЎҢеҮҪж•°еҶ…е®№.
йҒҮеҲ°yieldе…ій”®еӯ—, жү§иЎҢеҒңжӯўгҖӮ
еҶҚж¬Ўи°ғз”Ёnextж–№жі•ж—¶пјҢ д»ҺдёҠиҜҚеҒңжӯўзҡ„д»Јз ҒдҪҚзҪ®з»§з»ӯжү§иЎҢгҖӮ
йҒҮеҲ°yieldе…ій”®еӯ—, жү§иЎҢеҒңжӯўгҖӮ
............
"""
for count in range(100):
yield 'step' + str(count + 1)
print("suucess")
if __name__ == '__main__':
#return_example()
#resultжҳҜдёҖдёӘз”ҹжҲҗеҷЁпјҢ еӣ дёәи°ғз”Ёзҡ„еҮҪж•°дёӯеҢ…еҗ«yieldе…ій”®еӯ—гҖӮ
result = yield_example()
print(next(result))
print(next(result))
""""""
def grep(kw):
"""жҗңзҙўе…ій”®еӯ—"""
while True:
response = ''
request = yield response
if kw in request:
print(request)
if __name__ == '__main__':
grep_gen = grep('python')
next(grep_gen)
#sendж–№жі•еҸҜд»Ҙз»ҷз”ҹжҲҗеҷЁдј йҖ’ж•°жҚ®пјҢ 并дёҖзӣҙжү§иЎҢпјҢ йҒҮеҲ°yieldеҒңжӯўгҖӮ
grep_gen.send('I love python')
grep_gen.send('I love Java')"""
"""
def chatRobot():
response = ''
while True:
request = yield response
if '姓еҗҚ' in request:
response = '姓еҗҚжҡӮж—¶дҝқеҜҶ'
elif 'дҪ еҘҪ' in request:
response = 'дҪ еҘҪпјҒHello'
else:
response = 'жҲ‘дёҚзҹҘйҒ“дҪ еңЁиҜҙдәӣд»Җд№ҲпјҢ иҜ·жҚўз§ҚиҜҙжі•'
if __name__ == '__main__':
#з”ҹжҲҗеҷЁеҜ№иұЎ
Robot = chatRobot()# и°ғз”Ёnextж–№жі•
next(Robot)
while True:
request = input("Me: >> ")
if request == 'еҶҚи§Ғ':
print("ж¬ўиҝҺдёӢж¬ЎиҒҠеӨ©.....")
break
response = Robot.send(request)
print("Robot: >> ", response)"""
д»Јз ҒйңҖиҰҒиҒ”зҪ‘иҝҗиЎҢ
"""
#requestsеә“жҳҜpythonе®һзҺ°зҡ„жңҖз®ҖеҚ•жҳ“з”Ёзҡ„HTTPеә“пјҢеӨҡз”ЁдәҺзҪ‘з»ңзҲ¬иҷ«гҖӮ
import requests
#jsonеә“жҳҜpythonдёӯе®һзҺ°jsonзҡ„еәҸеҲ—еҢ–дёҺеҸҚеәҸеҲ—еҢ–зҡ„жЁЎеқ—гҖӮ
import json
def robot_api(word):
#йқ’дә‘жҸҗдҫӣзҡ„иҒҠеӨ©жңәеҷЁдәәAPIең°еқҖ
url = 'http://api.qingyunke.com/api.php?key=free&appid=0&msg=%s' %(word)
try:
#и®ҝй—®URLпјҢ иҺ·еҸ–зҪ‘йЎөе“Қеә”зҡ„еҶ…е®№гҖӮ
response_text = requests.get(url).text
#е°Ҷjsonеӯ—з¬ҰдёІиҪ¬жҲҗеӯ—е…ёпјҢ 并иҺ·еҸ–еӯ—е…ёзҡ„вҖҳcontentвҖҷkeyеҜ№еә”зҡ„valueеҖј
#eg: {'result': 0, 'content': 'жңүеҒҡе№ҝе‘Ҡзҡ„е«Ңз–‘пјҢжё…йқҷзӮ№еҲ«жү“е№ҝе‘ҠиЎҢд№Ҳ'}
return json.loads(response_text).get('content', "ж— е“Қеә”")
except Exception as e:
#еҰӮжһңи®ҝй—®еӨұиҙҘпјҢ е“Қеә”зҡ„еҶ…е®№дёә''
return ''
def chatRobot():
response = ''
while True:
#yield response: responseе°ұжҳҜз”ҹжҲҗеҷЁжү§иЎҢnextж–№жі•жҲ–иҖ…sendж–№жі•зҡ„иҝ”еӣһеҖјгҖӮ
#request = yield
request = yield response
if '姓еҗҚ' in request:
response = '姓еҗҚжҡӮж—¶дҝқеҜҶ'
elif 'дҪ еҘҪ' in request:
response = 'дҪ еҘҪпјҒHello'
else:
response = robot_api(request)
if __name__ == '__main__':
#з”ҹжҲҗеҷЁеҜ№иұЎ
Robot = chatRobot()
#и°ғз”Ёnextж–№жі•
next(Robot)
while True:
request = input("Me: >> ")
if request == 'еҶҚи§Ғ':
print("ж¬ўиҝҺдёӢж¬ЎиҒҠеӨ©.....")
break
response = Robot.send(request)
print("Robot: >> ", response)
"""дёүгҖҒз”ҹжҲҗеҷЁгҖҒиҝӯд»ЈеҷЁгҖҒеҸҜиҝӯд»ЈеҜ№иұЎжҖ»з»“
з”ҹжҲҗејҸпјҡеҝ«йҖҹз”ҹжҲҗеҲ—иЎЁпјҢйӣҶеҗҲпјҢеӯ—е…ё
з”ҹжҲҗеҷЁпјҲgenerator)пјҡдёҖиҫ№еҫӘзҺҜдёҖиҫ№и®Ўз®—
иҝӯд»ЈеҷЁпјҲiterator)пјҡеҸҜд»Ҙи°ғз”Ёnext()ж–№жі•и®ҝй—®е…ғзҙ
еҸҜиҝӯд»ЈеҜ№иұЎпјҡеҸҜд»ҘйҖҡиҝҮforеҫӘзҺҜи®ҝй—®
з”ҹжҲҗеҷЁйғҪжҳҜиҝӯд»ЈеҷЁпјҢйғҪжҳҜеҸҜиҝӯд»ЈеҜ№иұЎ
еҸҜиҝӯд»ЈеҜ№иұЎдёҚдёҖе®ҡжҳҜиҝӯд»ЈеҷЁпјҢдҫӢеҰӮпјҡstr,list,tuple,set,dict
жҖҺд№Ҳе°ҶеҸҜиҝӯд»ЈеҜ№иұЎиҪ¬жҚўжҲҗиҝӯд»ЈеҷЁпјҡйҖҡиҝҮiter()е…ій”®еӯ—
з”ҹжҲҗеҷЁ: generator, дёҖиҫ№еҫӘзҺҜдёҖиҫ№и®Ўз®—зҡ„е·Ҙе…·гҖӮ
иҝӯд»ЈеҷЁ: iterator, еҸҜд»Ҙи°ғз”Ёnextж–№жі•и®ҝй—®е…ғзҙ зҡ„еҜ№иұЎ.
еҸҜиҝӯд»ЈеҜ№иұЎ: Iterable, еҸҜд»Ҙе®һзҺ°forеҫӘзҺҜзҡ„
з”ҹжҲҗеҷЁйғҪжҳҜиҝӯд»ЈеҷЁд№Ҳ? Yes, з”ҹжҲҗеҷЁеҶ…йғЁе®һзҺ°дәҶиҝӯд»ЈеҷЁзҡ„еҚҸи®®гҖӮ
з”ҹжҲҗеҷЁйғҪжҳҜеҸҜиҝӯд»ЈеҜ№иұЎеҗ—? Yes
еҸҜиҝӯд»ЈеҜ№иұЎйғҪжҳҜиҝӯд»ЈеҷЁеҗ—? Not Always, жҜ”еҰӮ: str,list,tuple,set,dict.
еҰӮдҪ•е°ҶеҸҜиҝӯд»ЈеҜ№иұЎиҪ¬жҚўжҲҗиҝӯд»ЈеҷЁ? iter()еҶ…зҪ®еҮҪж•°
""""""
еӣӣгҖҒй—ӯеҢ…
1гҖҒе®ҡд№ү
й—ӯеҢ…е°ұжҳҜжҢҮжңүжқғи®ҝй—®еҸҰдёҖдёӘеҮҪж•°дҪңз”Ёеҹҹдёӯзҡ„еҸҳйҮҸзҡ„еҮҪж•°гҖӮ
еёёи§ҒеҪўејҸ:
пјҲ1пјүеҮҪж•°еөҢеҘ—
пјҲ2пјүеҶ…йғЁеҮҪж•°дҪҝз”ЁеӨ–йғЁеҮҪж•°зҡ„еҸҳйҮҸ
пјҲ3пјүеӨ–йғЁеҮҪж•°зҡ„иҝ”еӣһеҖјжҳҜеҶ…йғЁеҮҪж•°зҡ„еҗҚз§°
еә”з”ЁеңәжҷҜ:иЈ…йҘ°еҷЁ
дјҳзӮ№пјҡжҸҗй«ҳд»Јз ҒеҸҜеӨҚз”ЁжҖ§
line_conf:жҳҜеӨ–йғЁеҮҪж•°
lineпјҡ жҳҜеҶ…йғЁеҮҪж•°
lineжҳҜеҗҰдёәй—ӯеҢ…? Yes, lineи°ғз”ЁдәҶline_confзҡ„еұҖйғЁеҸҳйҮҸaе’Ңb
"""
import matplotlib.pyplot as plt
def line_conf(a, b): # a=2, b=3
"""y = ax + b """
def line(x):
return a * x + b
return line
#line1жҳҜдёҖдёӘеҮҪж•°еҗҚ
line1 = line_conf(2, 3) # и°ғз”ЁеҮҪж•°пјҢ a=2, b=3
line2 = line_conf(3, 3) # и°ғз”ЁеҮҪж•°пјҢ a=3, b=3
line3 = line_conf(4, 3) # и°ғз”ЁеҮҪж•°пјҢ a=4, b=3
#x = [1, 3, 5, 7 .....99]
x = list(range(1, 100, 2))
y1 = [line1(item) for item in x]
y2 = [line2(item) for item in x]
y3 = [line3(item) for item in x]
#plot:жҠҳзәҝеӣҫ
#plt.plot(x, y1, label='y=2x+3')
#plt.plot(x, y2, label='y=3x+3')
#plt.plot(x, y3, label='y=4x+3')
#scatter: ж•ЈзӮ№еӣҫ
plt.scatter(x, y1, label='y=2x+3')
plt.scatter(x, y2, label='y=3x+3')
plt.scatter(x, y3, label='y=4x+3')
#жҳҫзӨәз»ҳеҲ¶зҡ„еӣҫеҪў
plt.title('line display') # ж·»еҠ ж Үйўҳ
plt.legend() # ж·»еҠ еӣҫдҫӢ
plt.show()дә”гҖҒиЈ…йҘ°еҷЁ
1гҖҒе®ҡд№ү
пјҲ1пјүеҷЁжҢҮзҡ„жҳҜе·Ҙе…·пјҢиҖҢзЁӢеәҸдёӯзҡ„еҮҪж•°е°ұжҳҜе…·еӨҮжҹҗдёҖеҠҹиғҪзҡ„е·Ҙе…·пјҢжүҖд»ҘиЈ…йҘ°еҷЁжҢҮзҡ„жҳҜдёәиў«иЈ…йҘ°еҷЁеҜ№иұЎж·»еҠ йўқеӨ–еҠҹиғҪзҡ„е·Ҙе…·/еҮҪж•°гҖӮ
пјҲ2пјүдёәд»Җд№ҲиҰҒдҪҝз”ЁиЈ…йҘ°еҷЁ
еҰӮжһңжҲ‘们已з»ҸдёҠзәҝдәҶдёҖдёӘйЎ№зӣ®пјҢжҲ‘们йңҖиҰҒдҝ®ж”№жҹҗдёҖдёӘж–№жі•пјҢдҪҶжҳҜжҲ‘们дёҚжғідҝ®ж”№ж–№жі•зҡ„дҪҝз”Ёж–№жі•пјҢиҝҷдёӘж—¶ еҖҷеҸҜд»ҘдҪҝз”ЁиЈ…йҘ°еҷЁгҖӮеӣ дёәиҪҜ件зҡ„з»ҙжҠӨеә”иҜҘйҒөеҫӘејҖж”ҫе°Ғй—ӯеҺҹеҲҷпјҢеҚіиҪҜ件дёҖж—ҰдёҠзәҝиҝҗиЎҢеҗҺпјҢиҪҜ件зҡ„з»ҙжҠӨеҜ№дҝ® ж”№жәҗд»Јз ҒжҳҜе°Ғй—ӯзҡ„пјҢеҜ№жү©еұ•еҠҹиғҪжҢҮзҡ„жҳҜејҖж”ҫзҡ„гҖӮ
иЈ…йҘ°еҷЁзҡ„е®һзҺ°еҝ…йЎ»йҒөеҫӘдёӨеӨ§еҺҹеҲҷпјҡ
1> е°Ғй—ӯ: еҜ№е·Із»Ҹе®һзҺ°зҡ„еҠҹиғҪд»Јз Ғеқ—е°Ғй—ӯгҖӮ дёҚдҝ®ж”№иў«иЈ…йҘ°еҜ№иұЎзҡ„жәҗд»Јз Ғ
2> ејҖж”ҫ: еҜ№жү©еұ•ејҖеҸ‘ иЈ…йҘ°еҷЁе…¶е®һе°ұжҳҜеңЁйҒөеҫӘд»ҘдёҠдёӨдёӘеҺҹеҲҷзҡ„еүҚжҸҗдёӢдёәиў«иЈ…йҘ°еҜ№иұЎж·»еҠ ж–°еҠҹиғҪгҖӮ
(3)еҰӮдҪ•е®һзҺ°иЈ…йҘ°еҷЁпјҡ
иЈ…йҘ°еҷЁжң¬иҙЁдёҠжҳҜдёҖдёӘеҮҪж•°пјҢиҜҘеҮҪж•°з”ЁжқҘеӨ„зҗҶе…¶д»–еҮҪж•°пјҢе®ғеҸҜд»Ҙи®©е…¶д»–еҮҪж•°еңЁдёҚйңҖиҰҒдҝ®ж”№д»Јз Ғзҡ„еүҚжҸҗдёӢеўһеҠ йўқеӨ–зҡ„еҠҹиғҪпјҢиЈ…йҘ°еҷЁзҡ„иҝ”еӣһеҖјд№ҹжҳҜдёҖдёӘеҮҪж•°еҜ№иұЎгҖӮ
#logging:дё“й—ЁеҒҡж—Ҙеҝ—и®°еҪ•жҲ–иҖ…еӨ„зҗҶзҡ„жЁЎеқ—гҖӮ
import logging
#ж—Ҙеҝ—зҡ„еҹәжң¬й…ҚзҪ®
#е®ҳж–№з¬ҰзҪ‘з«ҷеҹәжң¬й…ҚзҪ®еҸҠдҪҝз”Ё: https://docs.python.org/zh-cn/3/howto/logging.html#logging-basic-tutorial
logging.basicConfig(
level=logging.DEBUG, # жҺ§еҲ¶еҸ°жү“еҚ°зҡ„ж—Ҙеҝ—зә§еҲ«
filename='message.log', # ж—Ҙеҝ—ж–Ү件дҪҚзҪ®
filemode='a', # еҶҷе…Ҙж–Ү件зҡ„жЁЎејҸ,aжҳҜиҝҪеҠ жЁЎејҸпјҢй»ҳи®ӨжҳҜиҝҪеҠ жЁЎејҸ
#ж—Ҙеҝ—ж јејҸ
format='%(asctime)s - %(pathname)s[line:%(lineno)d] - %(levelname)s: %(message)s'
)
#logging.debug('Network start Ok')
#logging.warning('Network start Failed')
#1). е®ҡд№үиЈ…йҘ°еҷЁ
from functools import wraps
def logger(func):
"""жҸ’е…Ҙж—Ҙеҝ—зҡ„иЈ…йҘ°еҷЁ"""
#wrapsиЈ…йҘ°еҷЁпјҢ з”ЁжқҘдҝқз•ҷfuncеҮҪж•°еҺҹжңүзҡ„еҮҪж•°еҗҚе’Ңеё®жҠ“ж–ҮжЎЈгҖӮ
@wraps(func)
def wrapper(*args, **kwargs): # args, kwargsжҳҜеҪўеҸӮпјҢ argsжҳҜе…ғз»„пјҢ kwargsжҳҜеӯ—е…ё.
"""й—ӯеҢ…еҮҪж•°"""
logging.debug("еҮҪж•°%sејҖе§Ӣжү§иЎҢ" % (func.__name__))
result = func(*args, **kwargs) # args, kwargsжҳҜе®һеҸӮпјҢ *args, **kwargsи§ЈеҢ…
logging.debug("еҮҪж•°%sжү§иЎҢз»“жқҹ" % (func.__name__))
return result
return wrapper
#2). еҰӮдҪ•дҪҝз”ЁиЈ…йҘ°еҷЁ?
#1). @loggerиҜӯжі•зі–, login = logger(login), pythonи§ЈйҮҠеҷЁйҒҮеҲ°иҜӯжі•зі–е°ұзӣҙжҺҘжү§иЎҢ
#2). loginеҮҪж•°зӣ®еүҚжҢҮеҗ‘logger(login)еҮҪж•°зҡ„иҝ”еӣһеҖјwrapperпјҢ login=wrapper
@logger
def login(username, password):
"""з”ЁжҲ·зҷ»еҪ•"""
if username == 'root' and password == 'redhat':
print('LOGIN OK')
logging.debug('%s LOGIN OK' % (username))
else:
print('LOGIN FAILED')
logging.error('%s LOGIN FAILED' % (username))
#е®һиҙЁдёҠжү§иЎҢзҡ„жҳҜиЈ…йҘ°еҷЁйҮҢйқўзҡ„wrapperеҮҪж•°
login('root', 'westos')
#print(login.__name__)
#print(login.__doc__)2019-12-21 17:15:53,226 - /home/kiosk/201911python/day08_code/16_иЈ…йҘ°еҷЁ.py[line:32] - DEBUG: еҮҪж•°loginејҖе§Ӣжү§иЎҢ
2019-12-21 17:15:53,227 - /home/kiosk/201911python/day08_code/16_иЈ…йҘ°еҷЁ.py[line:46] - ERROR: root LOGIN FAILED
2019-12-21 17:15:53,227 - /home/kiosk/201911python/day08_code/16_иЈ…йҘ°еҷЁ.py[line:34] - DEBUG: еҮҪж•°loginжү§иЎҢз»“жқҹ
2019-12-21 17:17:00,105 - /home/kiosk/201911python/day08_code/16_иЈ…йҘ°
"""
import os
#ж–Ү件еҗҚз§°зҡ„еҢ№й…ҚпјҢ并且еҢ№й…Қзҡ„жЁЎејҸдҪҝз”Ёзҡ„unix shellйЈҺж ј
import fnmatch
def locate(pattern, root=os.curdir):
"""з”ҹдә§иҖ…пјҡ з”ҹдә§з¬ҰеҗҲжқЎд»¶зҡ„ж–Ү件еҗҚ"""
#os.walkиҝ”еӣһдёүдёӘеҖј: жҹҘиҜўж №зӣ®еҪ•пјҢ еӯҗзӣ®еҪ•пјҢзӣ®еҪ•ж–Ү件
for path, dirs, files in os.walk(os.path.abspath(root)):
# fnmatch.filterе®һзҺ°еҲ—иЎЁзү№ж®Ҡеӯ—з¬Ұзҡ„иҝҮж»ӨжҲ–зӯӣйҖү,иҝ”еӣһз¬ҰеҗҲеҢ№й…ҚжЁЎејҸзҡ„еӯ—з¬ҰеҲ—иЎЁ
for filename in fnmatch.filter(files, pattern):
# жӢјжҺҘж–Ү件зҡ„з»қеҜ№и·Ҝеҫ„
yield os.path.join(path, filename)
def rename():
"""ж¶Ҳиҙ№иҖ…: ж–Ү件йҮҚе‘ҪеҗҚ"""
while True:
filename = yield
dirname, basename = os.path.split(filename)
rename = os.path.join(dirname, '[иҘҝйғЁејҖжәҗ]_' + basename)
os.rename(filename, rename)
if __name__ == '__main__':
fname = locate('*.py')
rename_gen = rename()
next(rename_gen)
for name in fname:
rename_gen.send(name)иЈ…йҘ°еҷЁзҡ„еә”з”ЁеңәжҷҜ
иЈ…йҘ°еҷЁз»Ҹеёёз”ЁдәҺжңүеҲҮйқўйңҖжұӮзҡ„еңәжҷҜпјҢжҜ”еҰӮпјҡ
жҸ’е…Ҙж—Ҙеҝ—гҖҒжҖ§иғҪжөӢиҜ•гҖҒдәӢеҠЎеӨ„зҗҶгҖҒзј“еӯҳгҖҒ жқғйҷҗж ЎйӘҢзӯүеә”з”ЁеңәжҷҜгҖӮ
from functools import wraps
import time
def timeit(func): # 2 func=download_music
"""жү“еҚ°иў«иЈ…йҘ°еҮҪж•°иҝҗиЎҢжҖ»ж—¶й—ҙзҡ„иЈ…йҘ°еҷЁ"""
#@wrapsдҝқз•ҷиў«иЈ…йҘ°еҮҪж•°зҡ„еҮҪж•°еҗҚе’Ңеё®еҠ©ж–ҮжЎЈпјҢ еҗҰеҲҷжҳҜwrapperзҡ„дҝЎжҒҜ.
@wraps(func)
def wrapper(*args, **kwargs): # 5 args=('Music', ), kwargs={}
start_time = time.time()
result = func(*args, **kwargs) # 6 func('Music')=download_music('Music')
end_time = time.time()
print("%sеҮҪж•°иҝҗиЎҢжҖ»ж—¶й—ҙдёә%fs" %(func.__name__, end_time-start_time))
return result # 7
return wrapper # 3
@timeit # 1 @timeitе®һиҙЁдёҠжү§иЎҢзҡ„еҶ…е®№: download_music = timeit(download_music) = wrapper
def download_music(name): # 7
time.sleep(0.4)
print('[Download]: ', name)
return True
#и°ғз”Ёdownload_musicеҮҪж•°ж—¶е®һиҙЁдёҠи°ғз”Ёзҡ„жҳҜwrapperеҮҪж•°гҖӮ
download_music('Music') # 4
"""import json
from functools import wraps
import string
def json_result(func): # 2
"""иў«иЈ…йҘ°еҮҪж•°зҡ„иҝ”еӣһеҖјеәҸеҲ—еҢ–жҲҗjsonж јејҸеӯ—з¬ҰдёІ"""
#дҝқз•ҷиў«иЈ…йҘ°еҮҪж•°зҡ„еҮҪж•°еҗҚе’Ңеё®еҠ©ж–ҮжЎЈгҖӮ
@wraps(func)
def wrapper(*args, **kwargs): # 5
result = func(*args, **kwargs) # 6
return json.dumps(result) # 8
return wrapper # 3
@json_result # 1
def get_users(): # 7
return {'user' + item: 'passwd' + item for item in string.digits}
result = get_users() # 4
print(result) # 9
"""е®һзҺ°ж–җжіўйӮЈеҘ‘ж•°еҲ—пјҢз”ұдәҺйҮҚеӨҚжҖ§еҚ з”ЁеҫҲеӨ§зҡ„з©әй—ҙдё”и®Ўз®—зј“ж…ўпјҢжүҖд»ҘеҸҜд»ҘеҲ©з”Ёзј“еӯҳжқҘиҠӮзңҒж—¶й—ҙ
from functools import lru_cache
from functools import wraps
import time
def timeit(func): # 2 func=download_music
"""жү“еҚ°иў«иЈ…йҘ°еҮҪж•°иҝҗиЎҢжҖ»ж—¶й—ҙзҡ„иЈ…йҘ°еҷЁ"""
#@wrapsдҝқз•ҷиў«иЈ…йҘ°еҮҪж•°зҡ„еҮҪж•°еҗҚе’Ңеё®еҠ©ж–ҮжЎЈпјҢ еҗҰеҲҷжҳҜwrapperзҡ„дҝЎжҒҜ.
@wraps(func)
def wrapper(*args, **kwargs): # 5 args=('Music', ), kwargs={}
start_time = time.time()
result = func(*args, **kwargs) # 6 func('Music')=download_music('Music')
end_time = time.time()
print("%sеҮҪж•°иҝҗиЎҢжҖ»ж—¶й—ҙдёә%fs" % (func.__name__, end_time - start_time))
return result # 7
return wrapper # 3
def fib_cache(func):
"""жү“еҚ°иў«иЈ…йҘ°еҮҪж•°иҝҗиЎҢжҖ»ж—¶й—ҙзҡ„иЈ…йҘ°еҷЁ"""
caches = {1: 1, 2: 1, 3: 2, 4: 4}
#@wrapsдҝқз•ҷиў«иЈ…йҘ°еҮҪж•°зҡ„еҮҪж•°еҗҚе’Ңеё®еҠ©ж–ҮжЎЈпјҢ еҗҰеҲҷжҳҜwrapperзҡ„дҝЎжҒҜ.
@wraps(func)
def wrapper(num):
# еҰӮжһңзј“еӯҳдёӯиғҪжүҫеҲ°з¬¬numдёӘFibж•°еҲ—зҡ„еҖјпјҢ зӣҙжҺҘиҝ”еӣһгҖӮ
if num in caches:
return caches.get(num)
#еҰӮжһңзј“еӯҳдёӯдёҚиғҪжүҫеҲ°з¬¬numдёӘFibж•°еҲ—зҡ„еҖјпјҢ
#1). е…Ҳжү§иЎҢеҮҪж•°func(num)и®Ўз®—з»“жһңгҖӮ
#2). 然еҗҺе°Ҷе°Ҷи®Ўз®—зҡ„дҝЎжҒҜеӯҳеӮЁеңЁзј“еӯҳдёӯгҖӮ并иҝ”еӣһи®Ўз®—з»“жһң
else:
result = func(num)
caches[num] = result
return result
return wrapper
#@fib_cache
@lru_cache(maxsize=10000)
def fib1(num):
"""计算第numдёӘFibж•°еҲ—"""
if num in (1, 2):
return 1
else:
return fib1(num - 1) + fib1(num - 2)
def fib2(num):
"""计算第numдёӘFibж•°еҲ—"""
if num in (1, 2):
return 1
else:
return fib2(num - 1) + fib2(num - 2)
@timeit # use_cache = timeit(use_cache)
def use_cache():
result = fib1(20)
print(result)
@timeit
def no_cache():
result = fib2(20)
print(result)
if __name__ == '__main__':
use_cache()
no_cache()
"""дёҖиҲ¬жғ…еҶөдёӢпјҢеңЁеҮҪж•°дёӯеҸҜд»ҘдҪҝз”ЁдёҖдёӘиЈ…йҘ°еҷЁпјҢдҪҶжҳҜжңүж—¶д№ҹдјҡжңүдёӨдёӘжҲ–дёӨдёӘд»ҘдёҠзҡ„иЈ…йҘ°еҷЁгҖӮ еӨҡдёӘиЈ…йҘ°еҷЁиЈ…йҘ°зҡ„йЎәеәҸжҳҜиҮӘдёӢиҖҢдёҠ(е°ұиҝ‘еҺҹеҲҷ)пјҢиҖҢи°ғз”Ёзҡ„йЎәеәҸжҳҜиҮӘдёҠиҖҢдёӢпјҲйЎәеәҸжү§иЎҢпјү
from functools import wraps
#зі»з»ҹдёӯзҡ„з”ЁжҲ·дҝЎжҒҜ;
db = {
'root': {
'name': 'root',
'passwd': 'westos',
'is_super': 0 # 0-дёҚжҳҜ 1-жҳҜ
},
'admin': {
'name': 'admin',
'passwd': 'westos',
'is_super': 1 # 0-дёҚжҳҜ 1-жҳҜ
}
}
#еӯҳеӮЁеҪ“еүҚзҷ»еҪ•з”ЁжҲ·зҡ„дҝЎжҒҜ;
login_user_session = {}
def is_login(func):
"""еҲӨж–ӯз”ЁжҲ·жҳҜеҗҰзҷ»еҪ•зҡ„иЈ…йҘ°еҷЁ"""
#@wrapsдҝқз•ҷиў«иЈ…йҘ°еҮҪж•°зҡ„еҮҪж•°еҗҚе’Ңеё®еҠ©ж–ҮжЎЈпјҢ еҗҰеҲҷжҳҜwrapperзҡ„дҝЎжҒҜ.
@wraps(func)
def wrapper1(*args, **kwargs):
if login_user_session:
result = func(*args, **kwargs)
return result
else:
print("жңӘзҷ»еҪ•, иҜ·е…Ҳзҷ»еҪ•.......")
print("и·іиҪ¬зҷ»еҪ•".center(50, '*'))
user = input("User: ")
passwd = input('Password: ')
if user in db:
if db[user]['passwd'] == passwd:
login_user_session['username'] = user
print('зҷ»еҪ•жҲҗеҠҹ')
#***** з”ЁжҲ·зҷ»еҪ•жҲҗеҠҹпјҢ жү§иЎҢbuyзҡ„ж“ҚдҪң;
result = func(*args, **kwargs)
return result
else:
print("еҜҶз Ғй”ҷиҜҜ")
else:
print("з”ЁжҲ·дёҚеӯҳеңЁ")
return wrapper1
def is_permission(func):
"""еҲӨж–ӯз”ЁжҲ·жҳҜеҗҰжңүжқғйҷҗзҡ„иЈ…йҘ°еҷЁ"""
#@wrapsдҝқз•ҷиў«иЈ…йҘ°еҮҪж•°зҡ„еҮҪж•°еҗҚе’Ңеё®еҠ©ж–ҮжЎЈпјҢ еҗҰеҲҷжҳҜwrapperзҡ„дҝЎжҒҜ.
@wraps(func)
def wrapper2(*args, **kwargs):
print("еҲӨж–ӯжҳҜеҗҰжңүжқғйҷҗ......")
current_user = login_user_session.get('username')
permissson = db[current_user]['is_super']
if permissson == 1:
result = func(*args, **kwargs)
return result
else:
print("з”ЁжҲ·%sжІЎжңүжқғйҷҗ" % (current_user))
return wrapper2
#еӨҡдёӘиЈ…йҘ°еҷЁиЈ…йҘ°зҡ„йЎәеәҸжҳҜиҮӘдёӢиҖҢдёҠ(е°ұиҝ‘еҺҹеҲҷ),иҖҢи°ғз”Ё/жү§иЎҢзҡ„йЎәеәҸжҳҜиҮӘдёҠиҖҢдёӢ(йЎәеәҸжү§иЎҢ)гҖӮ
"""
иў«иЈ…йҘ°зҡ„иҝҮзЁӢ:
1). @is_permission: buy = is_permission(buy) ===> buy=wrapper2
2). @is_login: buy = is_login(buy) ===> buy = is_login(wrapper2) ===> buy=wrapper1
"""
@is_login
@is_permission
def buy():
print("иҙӯд№°е•Ҷе“Ғ........")
"""
еҲӨж–ӯз”ЁжҲ·жҳҜеҗҰзҷ»еҪ•..........
еҲӨж–ӯз”ЁжҲ·жҳҜеҗҰжңүжқғйҷҗ..........
иҙӯд№°е•Ҷе“Ғ........
и°ғз”Ёзҡ„иҝҮзЁӢ:
1). buy() ===> wrapper1() print("еҲӨж–ӯз”ЁжҲ·жҳҜеҗҰзҷ»еҪ•..........")
2). wrapper2() print("еҲӨж–ӯз”ЁжҲ·жҳҜеҗҰжңүжқғйҷҗ..........")
3). buy() print("иҙӯд№°е•Ҷе“Ғ........")
"""
buy()
"""ж— еҸӮиЈ…йҘ°еҷЁеҸӘеҘ—дәҶдёӨеұӮпјҢжңүеҸӮиЈ…йҘ°еҷЁ: еҘ—дёүеұӮзҡ„иЈ…йҘ°еҷЁ
from functools import wraps
def auth(type):
print("и®ӨиҜҒзұ»еһӢдёә: ", type)
def desc(func):
@wraps(func)
def wrapper(*args, **kwargs):
if type == 'local':
user = input("User:")
passwd = input("Passwd:")
if user == 'root' and passwd == 'westos':
result = func(*args, **kwargs)
return result
else:
print("з”ЁжҲ·еҗҚ/еҜҶз Ғй”ҷиҜҜ")
else:
print("жҡӮдёҚж”ҜжҢҒиҝңзЁӢз”ЁжҲ·зҷ»еҪ•")
return wrapper
return desc
з»“и®ә: @еҗҺйқўи·ҹзҡ„жҳҜиЈ…йҘ°еҷЁеҮҪж•°зҡ„еҗҚз§°пјҢ еҰӮжһңдёҚжҳҜеҗҚз§°пјҢ е…Ҳжү§иЎҢпјҢеҶҚе’Ң@з»“еҗҲгҖӮ
1). @auth(type='local')
2). desc = auth(type='local')
3). @desc
4). login = desc(login)
4). login = wrapper
"""
@auth(type='remote')
def home():
print('зҪ‘з«ҷдё»йЎө')
home()еҶ…зҪ®й«ҳйҳ¶еҮҪж•°
жҠҠеҮҪж•°дҪңдёәеҸӮж•°дј е…ҘпјҢжҲ–иҖ…дҪңдёәиҝ”еӣһеҖјиҝ”еӣһ
1гҖҒmap()еҮҪж•°
map(function, *iterable)
дј е…ҘеҮҪж•°е’ҢеҸҜиҝӯд»ЈеҜ№иұЎ
ж №жҚ®жҸҗдҫӣзҡ„еҮҪж•°еҜ№жҢҮе®ҡеәҸеҲ—еҒҡжҳ е°„гҖӮ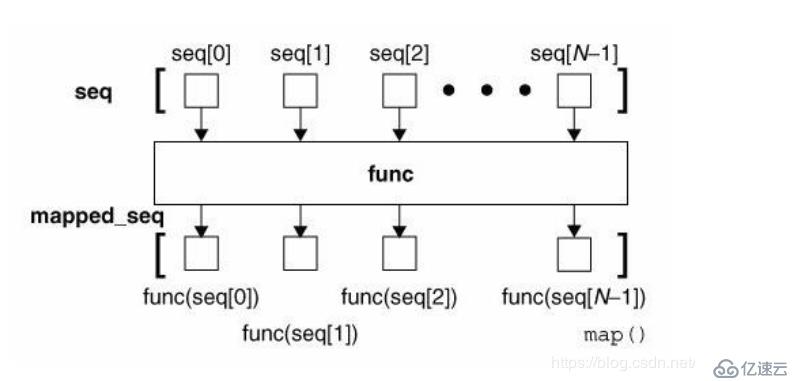
еҪ“еәҸеҲ—еӨҡдәҺдёҖдёӘж—¶пјҢmapеҸҜд»Ҙ并иЎҢпјҲжіЁж„ҸжҳҜ并иЎҢпјүең°еҜ№жҜҸдёӘеәҸеҲ—жү§иЎҢеҰӮдёӢеӣҫжүҖзӨәзҡ„иҝҮзЁӢпјҡ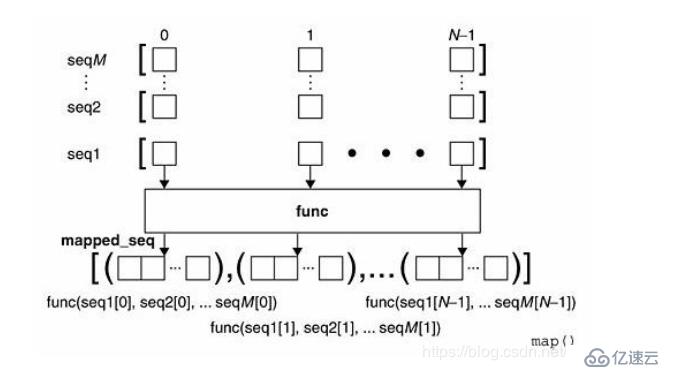
#1+1*3
#add(1,cheng(1, 3))
#map() дјҡж №жҚ®жҸҗдҫӣзҡ„еҮҪж•°еҜ№жҢҮе®ҡеәҸеҲ—еҒҡжҳ е°„гҖӮ
#1). mapзҡ„дј йҖ’еҮҪж•°еҗҚеҸҜд»ҘжҳҜеҶ…зҪ®еҮҪж•°
map_object = map(int, ['1', '2', '3'])
for item in map_object:
print(item, type(item))
#2). mapзҡ„дј йҖ’еҮҪж•°еҗҚеҸҜд»ҘжҳҜеҢҝеҗҚеҮҪж•°
iterator_object = (int(item) for item in ['1', '2', '3'])
for item in iterator_object:
print(item, type(item))
map_object = map(lambda x: x ** 2, [1, 2, 3, 4])
print(list(map_object)) # [1, 4, 9, 16]
def data_process(x):
return x + 4
#3). mapзҡ„дј йҖ’еҮҪж•°еҗҚеҸҜд»ҘжҳҜйқһеҢҝеҗҚеҮҪж•°
map_object = map(data_process, [1, 2, 3, 4])
print(list(map_object)) # [1, 4, 9, 16]#4). mapзҡ„дј йҖ’зҡ„еҸҜиҝӯд»ЈеҜ№иұЎеҸҜд»ҘжҳҜеӨҡдёӘ
x, y = 1, 1 2
x, y = 2, 2 6
x, y = 3, 3 12
"""
map_object = map(lambda x, y: x ** 2 + y, [1, 2, 3], [1, 2, 3])
print(list(map_object))
reduce() еҮҪж•°
reduce(function, sequence[, initial]) -> value
еҜ№еҸӮж•°еәҸеҲ—дёӯе…ғзҙ иҝӣиЎҢзҙҜз§Ҝ
еңЁpython2дёӯпјҢreduceжҳҜеҶ…зҪ®й«ҳйҳ¶еҮҪж•°
еңЁpython3дёӯпјҢreduceеҮҪж•°йңҖиҰҒеҜје…Ҙпјҡ
from functools import reduce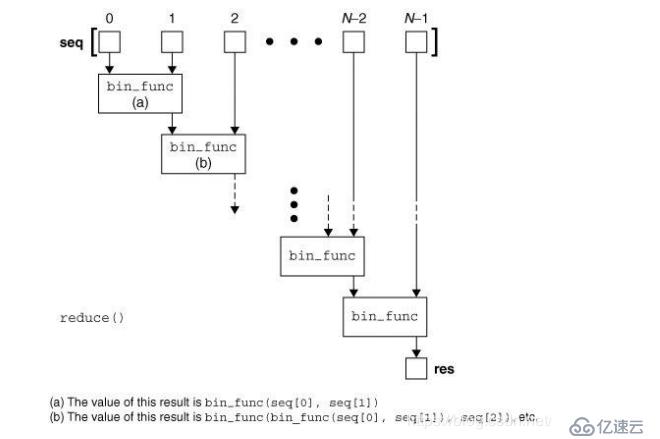
#reduce() еҮҪж•°дјҡеҜ№еҸӮж•°еәҸеҲ—дёӯе…ғзҙ иҝӣиЎҢзҙҜз§ҜгҖӮ
#py2дёӯпјҢ reduceжҳҜеҶ…зҪ®й«ҳйҳ¶еҮҪж•°пјӣ
#py3дёӯпјҢ reduceеҮҪж•°йңҖиҰҒеҜје…Ҙ;
from functools import reduce
nums_add = reduce(lambda x, y: x + y, list(range(1, 101)))
print(nums_add)
#йңҖжұӮ: йҖҡиҝҮreduceеҮҪж•°ж—¶е…Ҳйҳ¶д№ҳ
N = 5
result = reduce(lambda x, y: x * y, list(range(1, N + 1))) # 1, 2, 3, 4, 5
print(result)filter() еҮҪж•°
filter(function or None, iterable)
з”ЁдәҺиҝҮж»ӨеәҸеҲ—пјҢиҝҮж»ӨжҺүдёҚз¬ҰеҗҲжқЎд»¶зҡ„е…ғзҙ пјҢиҝ”еӣһз”ұз¬ҰеҗҲжқЎд»¶е…ғзҙ з»„жҲҗзҡ„ж–°еҲ—иЎЁгҖӮ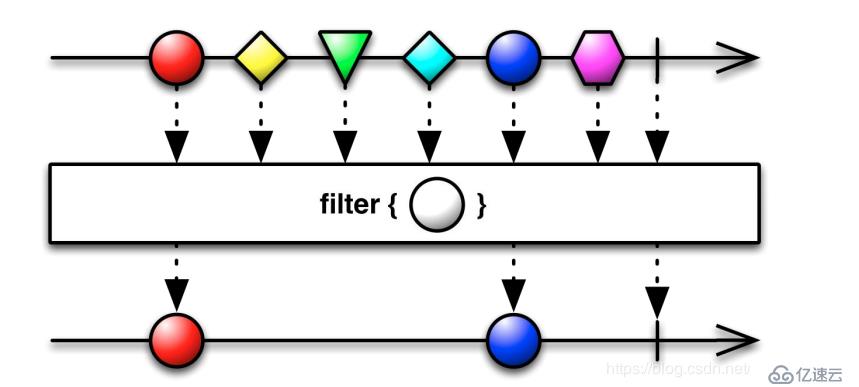
#filter() еҮҪж•°з”ЁдәҺиҝҮж»ӨеәҸеҲ—,иҝҮж»ӨжҺүдёҚз¬ҰеҗҲжқЎд»¶зҡ„е…ғзҙ ,иҝ”еӣһз”ұз¬ҰеҗҲжқЎд»¶е…ғзҙ з»„жҲҗзҡ„ж–°еҲ—иЎЁгҖӮ
result = filter(lambda x: x % 3 == 0, list(range(1, 11)))
print(list(result))
result = [item for item in range(1, 11) if item % 3 == 0]
print(result)
def is_prime(x):
"""еҲӨж–ӯxжҳҜеҗҰдёәиҙЁж•°"""
pass
result = filter(is_prime, list(range(2, 101)))
print(list(result))"""sorted() еҮҪж•°
sorted(iterable, key=None, reverse=False)
key: дё»иҰҒжҳҜз”ЁжқҘиҝӣиЎҢжҜ”иҫғзҡ„е…ғзҙ пјҢеҸӘжңүдёҖдёӘеҸӮж•°
reverse: жҺ’еәҸ规еҲҷпјҢTrue йҷҚеәҸ пјҢFalse еҚҮеәҸпјҲй»ҳи®ӨпјүгҖӮ
еҜ№жүҖжңүеҸҜиҝӯд»Јзҡ„еҜ№иұЎиҝӣиЎҢжҺ’еәҸж“ҚдҪңгҖӮиҝ”еӣһйҮҚж–°жҺ’еәҸзҡ„еҲ—иЎЁгҖӮ
sort() е’Ң sorted() зҡ„еҢәеҲ«пјҡ
пјҲ1пјүжҺ’еәҸеҜ№иұЎдёҚеҗҢ: sort жҳҜеә”з”ЁеңЁ list дёҠзҡ„ж–№жі•пјҢsorted еҸҜд»ҘеҜ№жүҖжңүеҸҜиҝӯд»Јзҡ„еҜ№иұЎиҝӣиЎҢжҺ’еәҸж“ҚдҪңгҖӮ
пјҲ2пјүиҝ”еӣһеҖјдёҚеҗҢ:
list зҡ„ sort ж–№жі•иҝ”еӣһзҡ„жҳҜеҜ№е·Із»ҸеӯҳеңЁзҡ„еҲ—иЎЁиҝӣиЎҢж“ҚдҪңпјҢж— иҝ”еӣһеҖј
еҶ…е»әеҮҪж•° sorted ж–№жі•иҝ”еӣһзҡ„жҳҜдёҖдёӘж–°зҡ„ listпјҢиҖҢдёҚжҳҜеңЁеҺҹжқҘзҡ„еҹәзЎҖдёҠиҝӣиЎҢзҡ„ж“ҚдҪңгҖӮ
import random
def is_odd(x):
"""еҲӨж–ӯжҳҜеҗҰдёәеҒ¶ж•°"""
return x % 2 == 0
#жҺ’еәҸйңҖжұӮпјҡ еҒ¶ж•°жҺ’еүҚйқўпјҢ еҘҮж•°жҺ’еҗҺйқў
nums = list(range(10)) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
random.shuffle(nums)
print("жҺ’еәҸеүҚ: ", nums)
nums.sort(key=lambda x: 0 if is_odd(x) else 1)
print("жҺ’еәҸеҗҺ: ", nums)
#sortedеҸҜд»ҘеҜ№жүҖжңүеҸҜиҝӯд»Јзҡ„еҜ№иұЎиҝӣиЎҢжҺ’еәҸж“ҚдҪңгҖӮ
result = sorted({2, 3, 4, 5, 1})
print(list(result))"""е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ