您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
进入循环链表之前我先解决一下上篇博文最后提到到的一种更方便的管理链表的结构:
typedef struct node //节点类型
{
type value;
struct node *next;
}Node;
typedef struct list
{
Node *phead;
Node *ptail;
int length;
}List;
首先来说这种结构只是为了方便管理,对于链表之前提的带头节点与不带头结点所提的区别依然是有效的,ok我们继续上图,先认识一下这种结构:
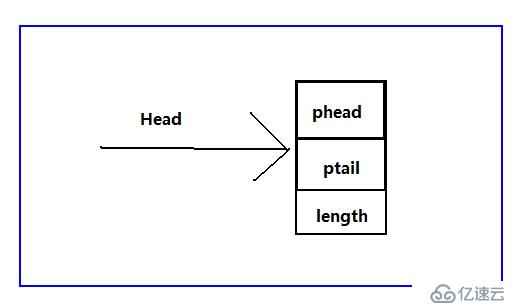
分别通过phead、ptail指向链表的头和尾,length记录链表的长度,这样就可以方便的记录链表的信息,我们之前说过带头结点的链表方便操作,那么两者加起来就更方便。接下来进入今天的主题,循环链表,为什么会出现循环链表,我个人认为,就是为了弥补单链表的不足,在单链表中,当我们已经遍历过某个元素,当我们希望再次查找时,就需要让临时指针重新指向头首元结点,重新遍历。这样就很麻烦,有了单循环链表,由于尾结点是指向头,就可以直接找到头,不需用额外语句,我想这就是单循环链表出来的缘故。找到头的问题解决了,之前单链表按位置插入删除的时候,当我们在需要插入、删除某个元素的时候不仅要找到特定元素,还需要记住这个元素之前的元素,才能找到特定元素的地址。ok,为了解决这个问题,我们聪明的计算机前辈,又发明了双循环链表,解决了这个问题。接下来,依然为了便于理解,给出我在学习过程中的一些理解图:带头结点、不带头结点的链表,这里都给出。不过,这里不在采用之前给出的管理链表的方式管理链表,通过我刚给出的方式处理,请看下图:
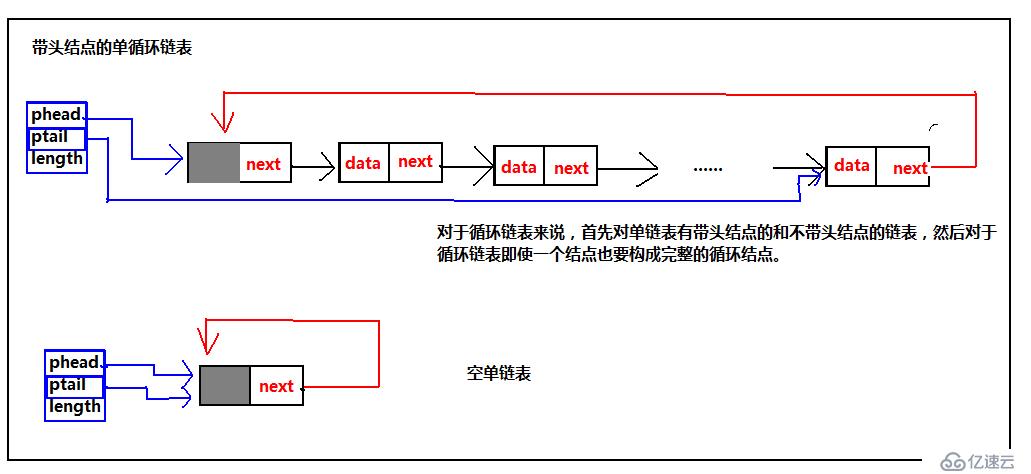
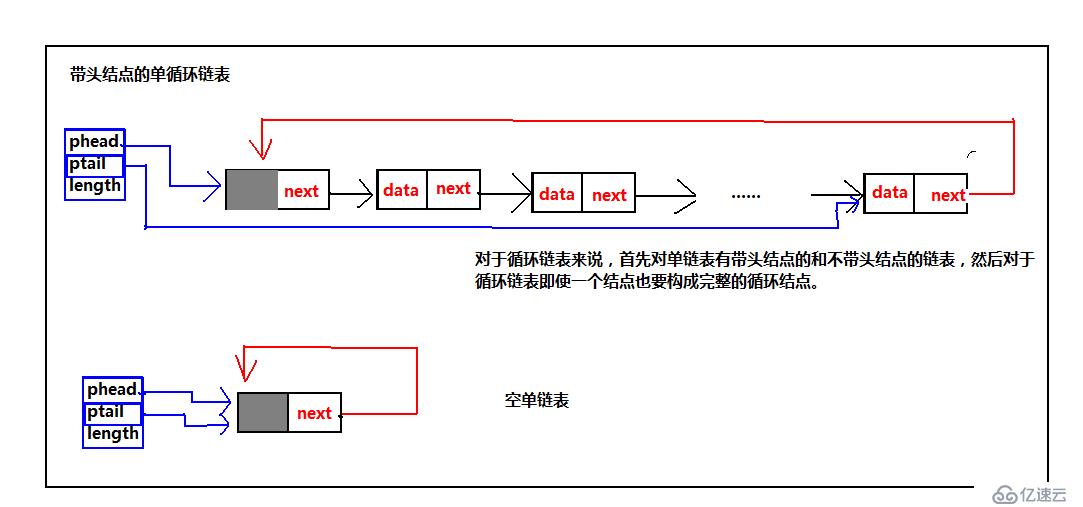
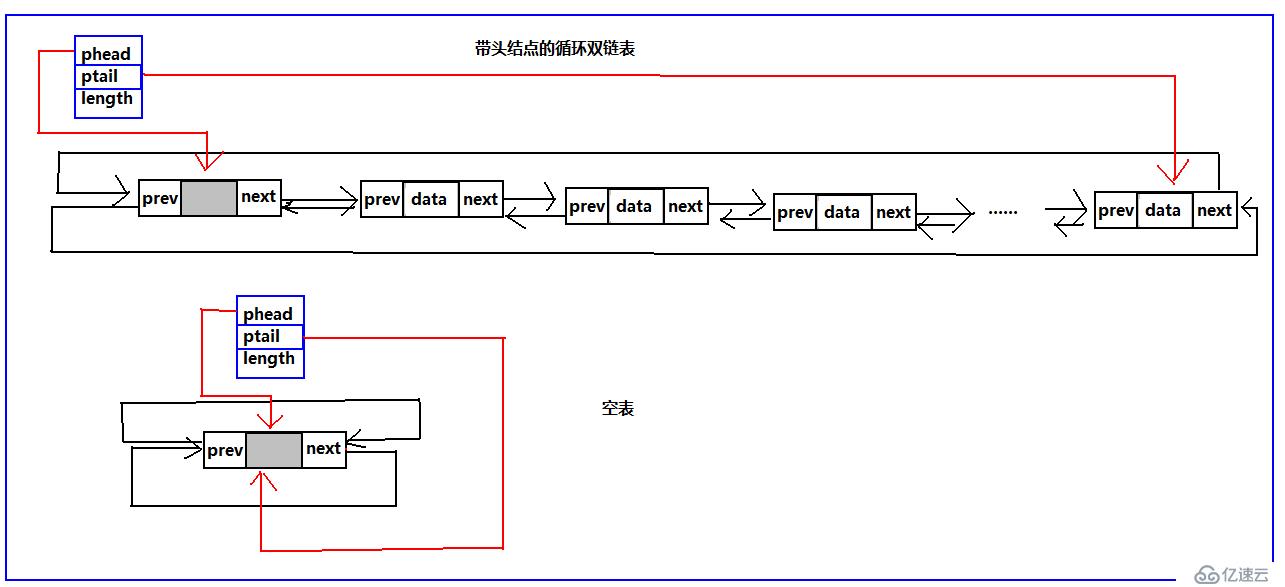
ok看完了结构图,我们来看循环链表主要的基本操作,同样的这里把带头结点的操作,不带头结点的的结构的操作都按照我个人的理解都给出。这里先给出单循环链表的代码以及示意图
首先我们先给出结构定义等部分的代码:
typedef int Status;
#define OK 1
#define ERROR 0
#define TRUE 1
#define FALSE 0
typedef int ElemType;
//定义单链表的结点
typedef struct node
{
ElemType data;
struct node *next;
}Node;
typedef struct node *LinkNode;
//定义管理链表的结构
typedef struct list
{
LinkNode Phead;
LinkNode Ptail;
int length ;
}List;
//构造新结点,写后面的插入函数后会重复使用构造节点的代码,因此将重复代码封装在函数中减少重复代码量
Node * BuyNode(ElemType x)
{
LinkNode s = (Node *)malloc(sizeof(Node));
if(NULL == s)
{
return NULL;
}
s->data = x;
s->next = NULL;
return s;
}
//同样构造完结点后多次使用到判断是否为空,因此也将代码封装成函数精简代码。
//判断是空返回FALSE;不是空返回TRUE;
Status IsEmpty(LinkNode s )
{
if(NULL == s)
{
printf("Out of memory\n");
return FALSE;
}
return TRUE;
}
初始化
//初始化不带头结点的循环单链表,初始化成功返回TRUE;失败返回FALSE;
Status Init_No_Head(List * head)
{
head->length = 0;
head->Phead = NULL;
head->Ptail = NULL;
return TRUE;
}
//初始化带头结点是循环单链表,初始化成功返回TRUE;失败返回FALSE;
Status Init_Yes_Head(List *head)
{
LinkNode s = BuyNode(0);
if(NULL == s)
{
printf("内存不足,初始化失败\n");
return ERROR;
}
head->length = 0;
head->Phead = head->Ptail = s;
s->next = head->Phead;
return TRUE;
}
单循环链表的头插
同样也为了便于理解,我这里给出头插操作的示意图:
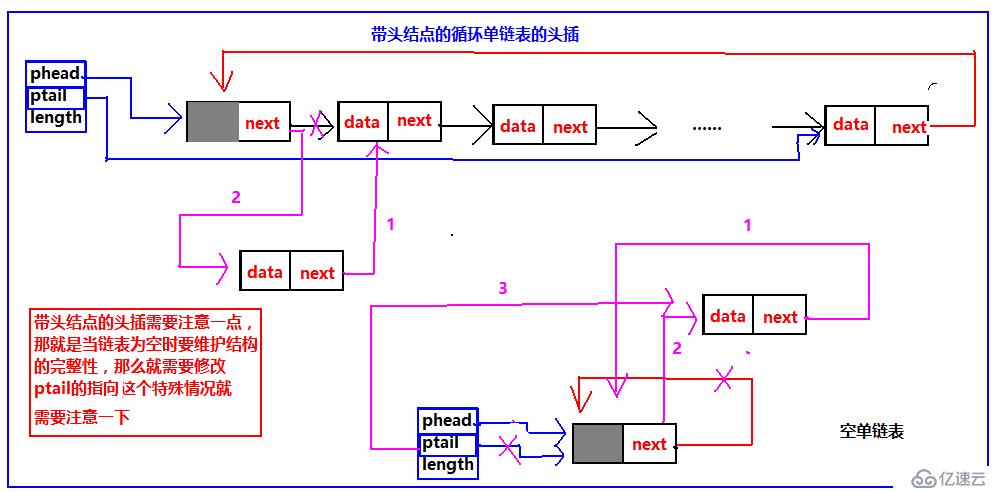
带头结点的头插,由于带头结点,所以头指针phead始终指向头结点,但是有一种特殊情况,为了维护其结构的完整性,那么对于空表的头插就是一种特殊情况,就要单独处理,需要把尾指针的指向修改。
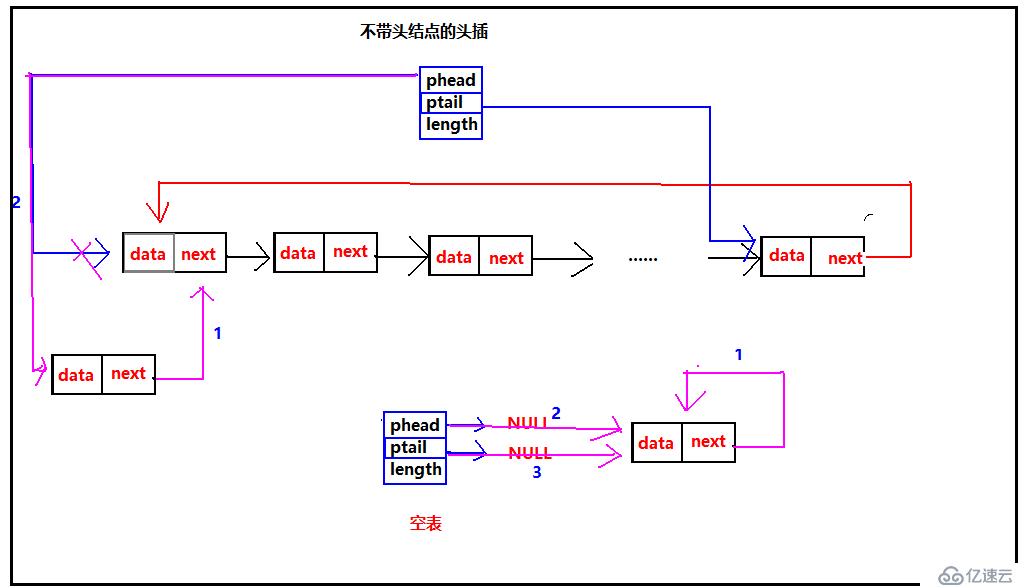
由于不带头结点,所以每次头插就需要修改头指针的指向。所以不带头结点的头插就会出现两种情况,1、表中已经有多个元素,头插时需要把phead始终指向第一个结点,这里没有头结点,因此就需要每次需改phead,2、空表的时候,就需要修改头指针phead和尾指针ptail的指向,并且要把第一个结点next指向自己,构成循环。
具体实现代码如下:
//不带头结点的头插,插入成功返回TRUE,失败返回FASLE
Status Insert_No_Head(List *head,ElemType x)
{
LinkNode s = BuyNode(x); //构造新结点
if(FALSE == IsEmpty(s))
{
return FALSE;
}
if(0 == head->length) //处理空链表的情况
{
head->Ptail = head->Phead = s;
}
s->next = head->Phead;
head->Phead = s;
head->Ptail->next = s;
head->length++;
return TRUE;
}
//带头结点的循环单链表的头插,插入成功返回TRUE,失败返回FASLE
//带头结点的头插需要注意一点,那就是当链表为空时要维护结构的完整性,那么就需要修改ptail的指向
Status Isert_Yse_Head(List *head ,ElemType x)
{
LinkNode s = BuyNode(x);
if(FALSE == IsEmpty(s))
{
return FALSE;
}
s->next = head->Phead->next;
head->Phead->next= s;
if(0 == head->length) //处理空链表的情况
{
head->Ptail = s;
s->next = head->Phead;
}
head->length++;
return TRUE;
}
单循环链表的尾插
同样我们来看尾插的示意图:
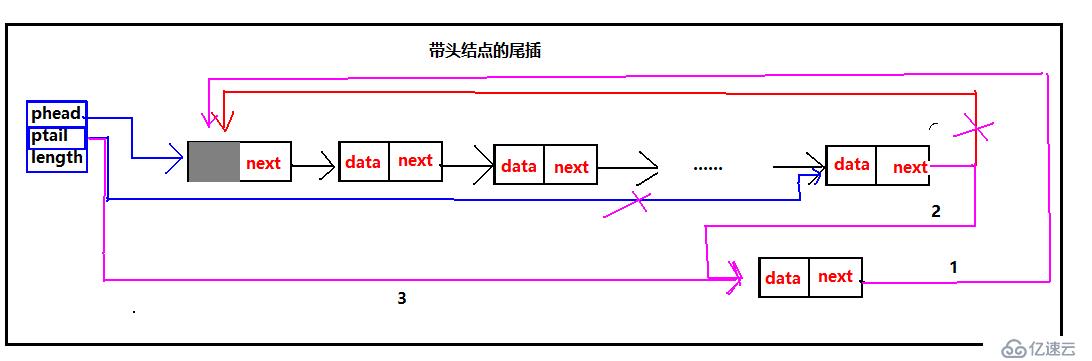
带头结点的尾插不论是空表还是有元素的表处理的情况是一样,每次都要修改ptail的指向
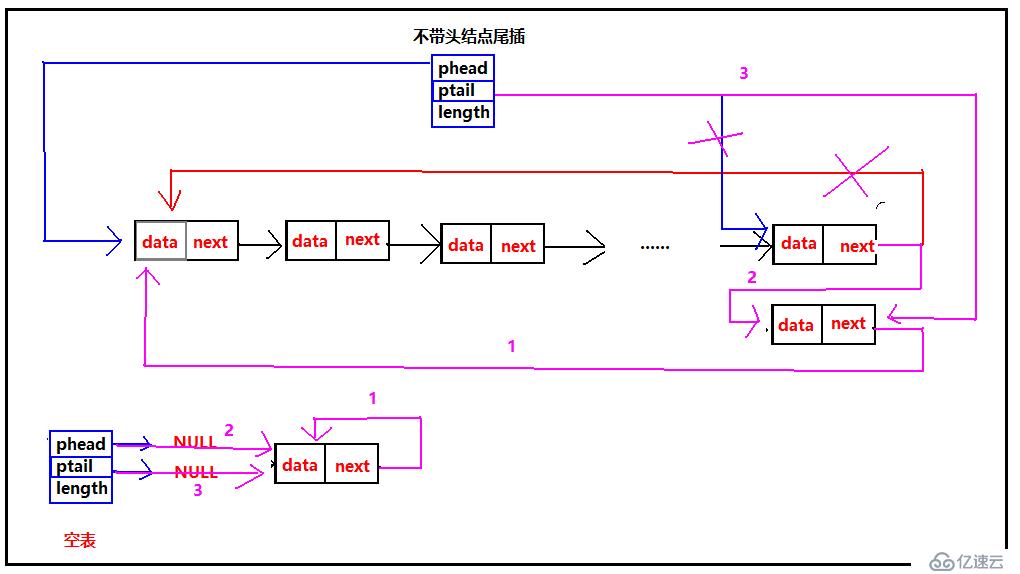
对于不带头结点的链表,需要注意空表时的情况,此时链表为空phead和ptail都指向空,所以就需要修改phead的指向。
具体实现代码如下:
//不带头结点的循环单链表的尾插,插入成功返回RUE,失败返回FALSE
Status Isert_No_Tail(list *head,ElemType x)
{
LinkNode s = BuyNode(x);
if(FALSE == IsEmpty(s))
{
return FALSE;
}
if(0 == head->length) //处理空链表的情况
{
head->Phead = head->Ptail = s;
}
s->next = head->Phead;
head->Ptail->next = s;
head->Ptail = s;
//带头结点的循环单链表尾插,插入成功返回RUE,失败返回FALSE
Status Insert_Yes_Tail(list *head, ElemType x)
{
LinkNode s = BuyNode(x);
if(FALSE == IsEmpty(s))
{
return FALSE;
}
s->next = head->Phead;
head->Ptail->next = s;
head->Ptail = s;
head->length++;
return TRUE;
}
单循环链表的头删
我们继续来循环单链表的头删的示意图:
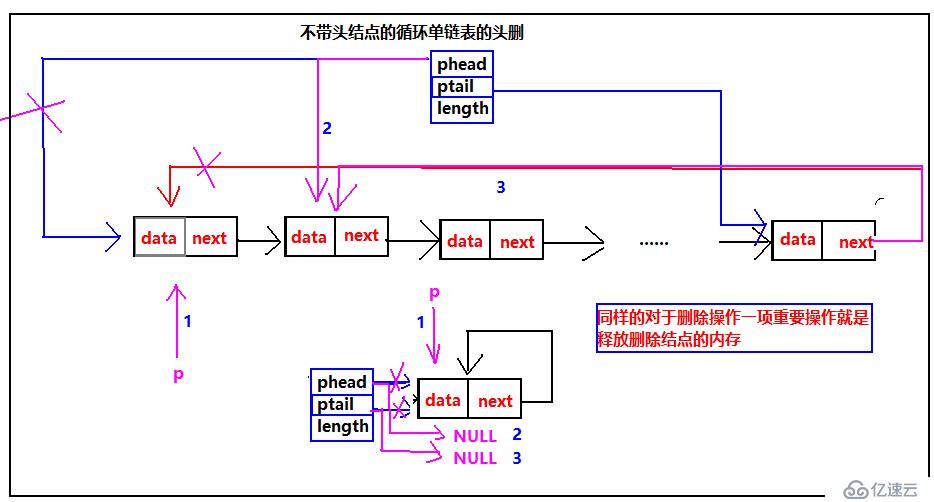
对于不带头结点的循环单链表,表中有多个元素的时候,按照步骤修改指向,特别注意一定要释放删除的结点内存,不让会造成内存泄露,并且为了防止产生野指针,把指向删除结点的指针指向NULL;头删一个结点的时候是一个种特殊情况,需要特别关注,需要把phead和ptail 的指向全部修改。
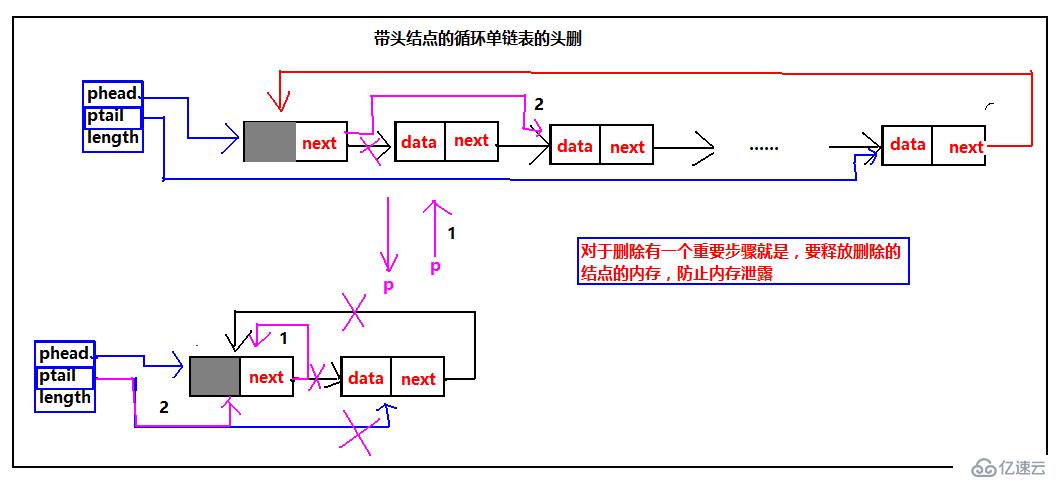
对于带头结点的循环单链表,表中元素较多时,依然是按照图中标的步骤操作,这没得说,当然也需要注意释放删除的结点的空间并把指针指向NULL;带头结点的循环单链表一个结点的时候,也是一种特殊情况。需要把ptail的指向修改,当然释放内存空间,并把指针指向NULL,依然没的说。
具体实现代码如下:
//不带头结点的头删,删除成功返回TRUE,失败失败返回FALSE;
Status Delite_No_Head(list *head,ElemType *x)
{
LinkNode p = head->Phead;
if(NULL == p)
{
printf("链表已空,不能删除了\n");
return FALSE;
}
*x = p->data;
head->Phead = p->next;
head->Ptail->next = head->Phead;
if(1 == head->length) //处理只有一个结点的情况
{
head->Phead = NULL;
head->Ptail = NULL;
}
free(p);
p = NULL;
head->length--;
return TRUE;
}
//带头结点的头删,删除成功返回TRUE,失败失败返回FALSE;
Status Delite_Yes_Head(list *head,ElemType *x)
{
LinkNode p = head->Phead->next;
if(head->Phead == p)
{
printf("链表已空,已经无法删除\n");
return FALSE;
}
head->Phead->next = p->next;
*x = p->data;
if(1 == head->length) //处理只有一个结点的情况
{
head->Ptail = head->Phead;
}
free(p);
p = NULL;
head->length--;
return TRUE;
}
单循环链表的尾删
最后我们来看循环单链表尾删的示意图:
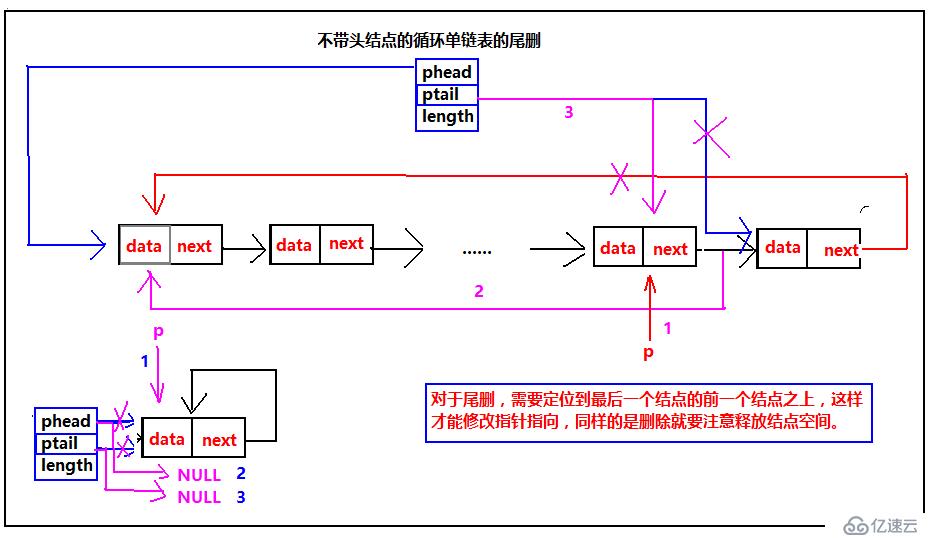
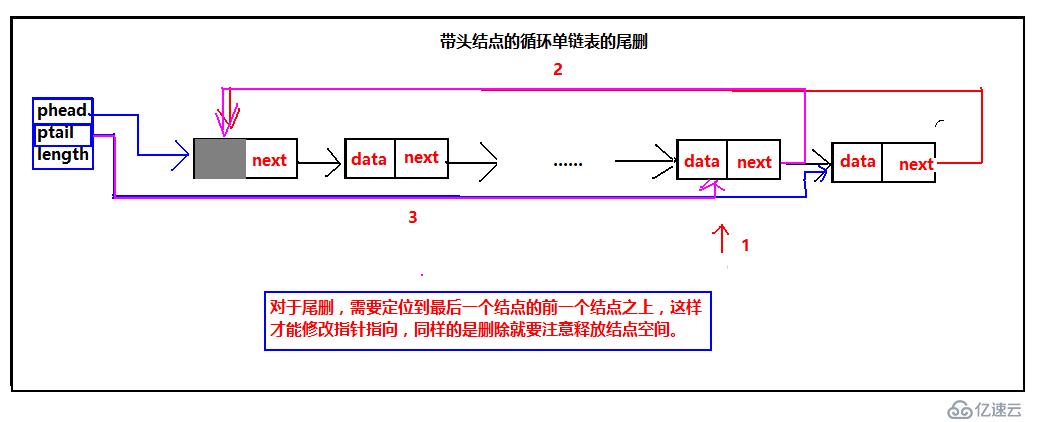
不管是带头结点还是不带头结点的循环单链表的尾删,都需要定位到最后一个结点的前一个结点,只有前一个结点才知道后一个节点的内存,并且,尾删的时候需要修改最后一个结点的前一个结点的指针指向。最后还是要强调一下释放内存空间并且把指针指向指向NULL。需要注意:不带头结点的尾删,当是一个结点的时候需要单独处理。
//不带头结点的尾删,删除成功返回TRUE,失败失败返回FALSE;
Status Delite_No_Tail(list *head,ElemType *x)
{
LinkNode s = head->Phead;
if(NULL == s)
{
printf("链表已空,已经无元素可以删除\n");
return FALSE;
}
if(1 == head->length) //处理只有一个结点的情况
{
head->Phead = head->Ptail = NULL;
*x = s->data;
head->length--;
return TRUE;
}
while(head->Ptail != s->next) //寻找最后一个结点的前一个结点
{
s = s->next;
}
*x = s->next->data;
head->Ptail = s;
free(s->next);
s->next = head->Phead;
head->length--;
return TRUE;
}
//带头结点尾删,删除成功返回TRUE,失败失败返回FALSE;
Status Delite_Yes_Tail(list *head,ElemType *x)
{
LinkNode s = head->Phead->next;
if(0 == head->length)
{
printf("链表已空,已经无元素可以删除\n");
return FALSE;
}
while(head->Ptail != s->next) //寻找最后一个结点的前一个结点
{
s = s->next;
}
head->Ptail = s;
*x = s->next->data;
free(s->next);
s->next = head->Phead;
head->length--;
return TRUE;
}
以上就是按照我个人理解总结的单循环链表的基本操作,已经经过测试。上边尽可能详细的给出了操作的主要思想以及示意图,代码还有许多可以优化的地方。希望读者提出意见和建议。双循环链表的基本操作不在本篇总结了,在后续的博文中会对其按照我个人的理解总结。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。