您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
java的jvm垃圾收集算法有哪些算法?一般大家对jvm垃圾收集算法了解可能停留在概念的层面上,而对于jvm具体有哪些算法了解相对较少。今天就跟大家聊聊jvm垃圾收集算法的主要算法。
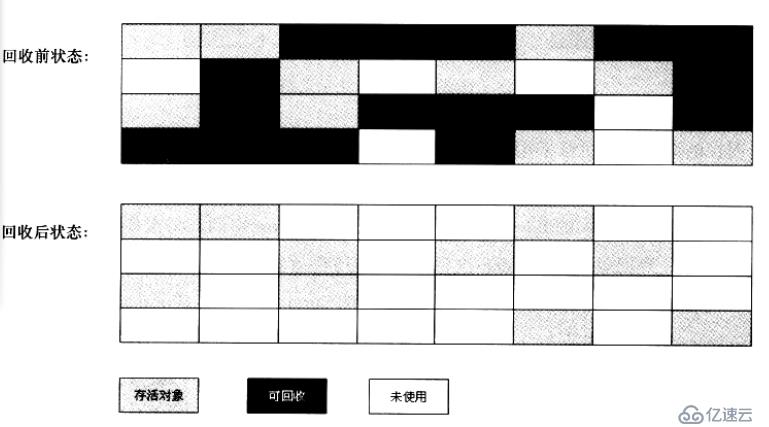
从图中可以看出这种算法的缺点在于,垃圾被回收以后造成了大量不连续的内存碎片。碎片太多可能会导致以后需要分配较大对象时,无法找到连续的足够内存从而频繁触发垃圾收集,降低系统效率。
复制算法:为了解决“标记,清除”算法的问题一种被称为复制的算法出现了,它将内存平均分为两块,每次只使用其中一块,当这一块存满时触发垃圾收集,将还存活的对象复制到另一块内存,然后将这块内存清掉,这样就不会存在内存碎片的问题。

标记整理算法:
复制算法在存活对象较多的时候需要复制的操作也较多,最关键的是只能利用一半的内存,标记整理算法可以解决这个问题,标记整理算法中的标记和标记清除算法一样,要被回收的对象找出来以后让所有存活的对象向一端移动,然后将内存的剩余部分直接清理掉。
为什么需要两块Survivor区?
为了避免内存碎片化的问题,大家想想复制算法是如何解决标记清除算法的内存碎片化问题的,将内存分为大小相等的两块,将存活的对象复制到另一块内存,这里也是一样的道理。
老年代:
因为老年代中对象的生命力比较顽强,如果采用复制算法那些存活的对象需要被复制很多次,所以老年代采用的是标记整理算法。
什么样的对象会进入老年代呢?
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。