жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
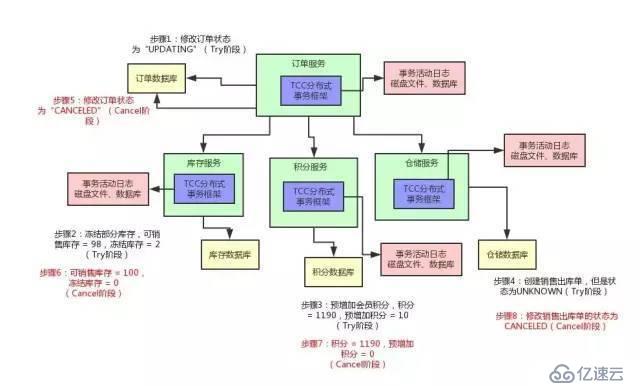
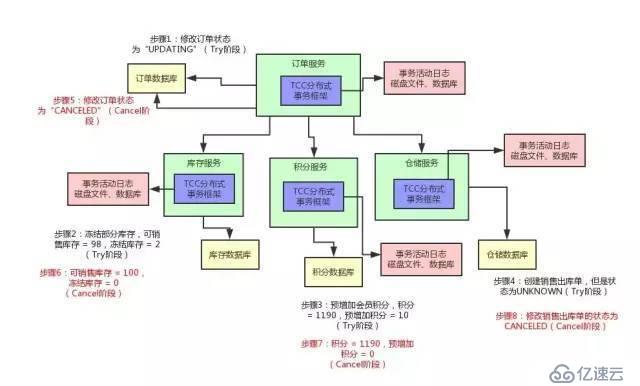
дәӢеҠЎжҳҜж•°жҚ®еә“д»ҺдёҖдёӘзЁіе®ҡзҠ¶жҖҒеҸҳиҝҒеҲ°еҸҰдёҖдёӘзЁіе®ҡзҠ¶жҖҒзҡ„дҝқиҜҒпјҢе…·еӨҮ ACID иҝҷ 4 дёӘзү№жҖ§пјҡ
еҺҹеӯҗжҖ§пјҲAtomicityпјүпјҡдёҖдёӘдәӢеҠЎдёӯзҡ„жүҖжңүж“ҚдҪңпјҢиҰҒд№Ҳе…ЁйғЁе®ҢжҲҗпјҢиҰҒд№Ҳе…ЁйғЁдёҚе®ҢжҲҗпјҢдёҚдјҡз»“жқҹеңЁдёӯй—ҙжҹҗдёӘзҺҜиҠӮгҖӮдәӢеҠЎеңЁжү§иЎҢиҝҮзЁӢдёӯеҸ‘з”ҹй”ҷиҜҜпјҢдјҡиў«еӣһж»ҡеҲ°дәӢеҠЎејҖе§ӢеүҚзҡ„зҠ¶жҖҒгҖӮ
дёҖиҮҙжҖ§пјҲConsistencyпјүпјҡеңЁдәӢеҠЎејҖе§Ӣд№ӢеүҚе’ҢдәӢеҠЎз»“жқҹд»ҘеҗҺпјҢж•°жҚ®еә“зҡ„е®Ңж•ҙжҖ§йҷҗеҲ¶жІЎжңүиў«з ҙеқҸгҖӮ
йҡ”зҰ»жҖ§пјҲIsolationпјүпјҡдёӨдёӘдәӢеҠЎзҡ„жү§иЎҢжҳҜдә’дёҚе№Іжү°зҡ„пјҢдёӨдёӘдәӢеҠЎж—¶й—ҙдёҚдјҡдә’зӣёеҪұе“ҚгҖӮ
дҫӢеҰӮеә”з”ЁзЁӢеәҸйңҖиҰҒжӣҙж–°еӨҡжқЎзӣёе…іж•°жҚ®ж—¶е°ұйңҖиҰҒиҝӣиЎҢдәӢеҠЎеӨ„зҗҶгҖӮ
еҪ“йҒҮеҲ°еӨҚжқӮдёҡеҠЎи°ғз”Ёж—¶пјҢеҸҜиғҪдјҡеҮәзҺ°и·Ёеә“еӨҡиө„жәҗи°ғз”Ё(дёҖдёӘдәӢеҠЎз®ЎзҗҶеҷЁпјҢеӨҡдёӘиө„жәҗ)/еӨҡжңҚеҠЎи°ғз”ЁпјҲеӨҡдёӘдәӢеҠЎз®ЎзҗҶеҷЁпјҢеӨҡдёӘиө„жәҗпјүпјҢжңҹжңӣе…ЁйғЁжҲҗеҠҹжҲ–еӨұиҙҘеӣһж»ҡпјҢиҝҷе°ұжҳҜеҲҶеёғејҸдәӢеҠЎпјҢз”Ёд»ҘдҝқиҜҒвҖңж“ҚдҪңеӨҡдёӘйҡ”зҰ»иө„жәҗзҡ„ж•°жҚ®дёҖиҮҙжҖ§вҖқгҖӮ
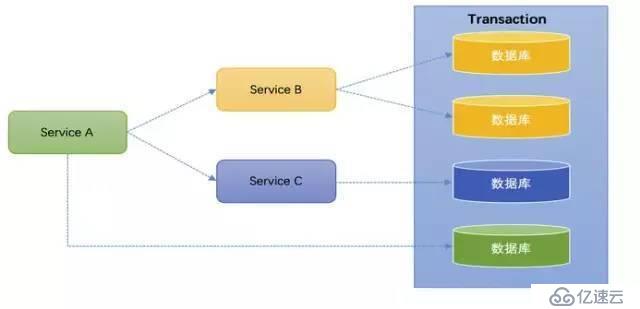
еҲҶеёғејҸдәӢеҠЎжҳҜжҢҮдјҡж¶үеҸҠеҲ°ж“ҚдҪңеӨҡдёӘж•°жҚ®еә“зҡ„дәӢеҠЎпјҢеҗҢж ·еҝ…йЎ»дҝқиҜҒ ACIDгҖӮе…¶е°ұжҳҜе°ҶеҜ№еҗҢдёҖеә“дәӢеҠЎзҡ„жҰӮеҝөжү©еӨ§еҲ°дәҶеҜ№еӨҡдёӘеә“зҡ„дәӢеҠЎпјҡеҜ№еҗҢдёҖеә“зҡ„ SQL ж“ҚдҪңеҜ№еә”дәҶеҲҶеёғејҸдәӢеҠЎдёӯеҜ№дёҖдёӘеә“зҡ„дәӢеҠЎгҖӮ
X/Open XA е®ҡд№үдәҶеҲҶеёғејҸдәӢеҠЎеӨ„зҗҶзҡ„规иҢғпјҢ并з”ұж•°жҚ®еә“еҺӮе•ҶеңЁй©ұеҠЁеұӮйқўиҝӣиЎҢе®һзҺ°гҖӮXA 规иҢғзҡ„еҹәзЎҖжҳҜдёӨйҳ¶ж®өжҸҗдәӨеҚҸи®®пјҢ并е®ҡд№үдәҶеҲҶеёғејҸдәӢеҠЎеӨ„зҗҶжүҖж¶үеҸҠзҡ„и§’иүІпјҡ
еә”з”ЁзЁӢеәҸпјҲAPпјү
дәӢеҠЎз®ЎзҗҶеҷЁпјҲTMпјү
иө„жәҗз®ЎзҗҶеҷЁпјҲRMпјү
йҖҡдҝЎиө„жәҗз®ЎзҗҶеҷЁпјҲCRMпјү
еёёи§Ғзҡ„дәӢеҠЎз®ЎзҗҶеҷЁпјҲ TM пјүжҳҜдәӨжҳ“дёӯй—ҙ件пјҢеёёи§Ғзҡ„иө„жәҗз®ЎзҗҶеҷЁпјҲ RM пјүжҳҜж•°жҚ®еә“пјҢеёёи§Ғзҡ„йҖҡдҝЎиө„жәҗз®ЎзҗҶеҷЁпјҲ CRM пјүжҳҜж¶ҲжҒҜдёӯй—ҙ件гҖӮ
еҸҜд»Ҙиҝҷж ·и®ӨдёәпјҢдәӢеҠЎз®ЎзҗҶеҷЁеҚідәӢеҠЎеӨ„зҗҶдёӯй—ҙ件пјҲеҲҶеёғејҸдәӢеҠЎеӨ„зҗҶзі»з»ҹпјүпјӣиө„жәҗз®ЎзҗҶеҷЁеҚіеҗ„дёӘж•°жҚ®еә“гҖӮ
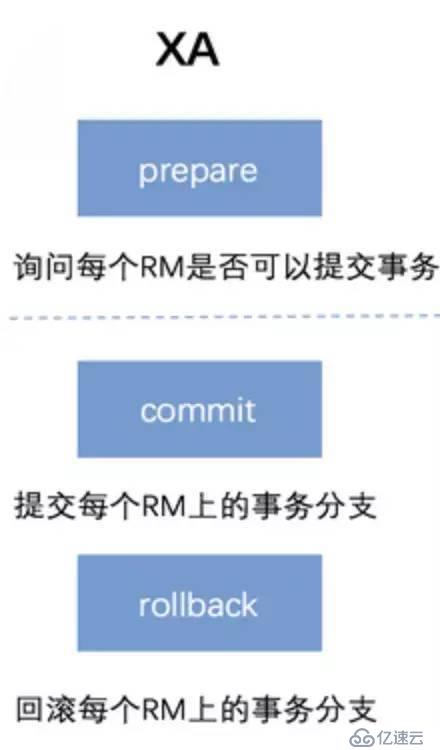
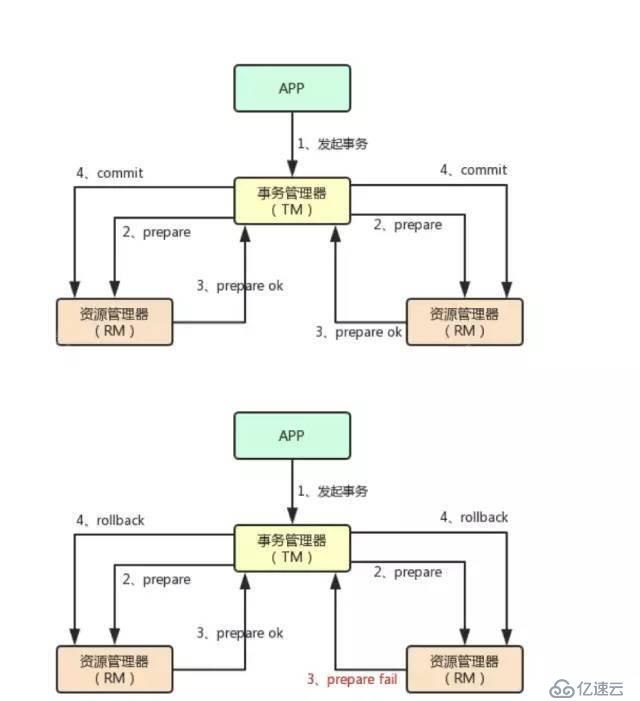
дёӨйҳ¶ж®өжҸҗдәӨеҚҸи®®пјҲTwo-phase commit protocol, 2PCпјүе°ҶдёҖж¬ЎеҲҶеёғејҸдәӢеҠЎеӨ„зҗҶеҲ’еҲҶдёәдёӨдёӘйҳ¶ж®өпјҡйў„жҸҗдәӨйҳ¶ж®өпјҲд№ҹз§°дёәеҮҶеӨҮйҳ¶ж®өжҲ–жҠ•зҘЁйҳ¶ж®өпјүпјҢжҸҗдәӨйҳ¶ж®өгҖӮ
1 йў„жҸҗдәӨйҳ¶ж®ө
иҝҷжҳҜдёӨйҳ¶ж®өжҸҗдәӨеҚҸи®®зҡ„第дёҖдёӘйҳ¶ж®өпјҢеҲҶеёғејҸдәӢеҠЎеӨ„зҗҶзі»з»ҹе’ЁиҜўеҗ„дёӘиө„жәҗз®ЎзҗҶеҷЁжҳҜеҗҰеҸҜд»ҘжҸҗдәӨжң¬ең°дәӢеҠЎпјҢеҗ„дёӘиө„жәҗз®ЎзҗҶеҷЁдјҡжҠҠиҝҷдёӘе’ЁиҜўиҝҮзЁӢеҶҷе…Ҙж—Ҙеҝ—пјҢд»ҘдҫҝиҝӣиЎҢеӣһж»ҡжҲ–жҸҗдәӨгҖӮ
еҪ“дёҖдёӘж•°жҚ®еә“жҺҘ收еҲ°е’ЁиҜўеҗҺпјҢе®ғдјҡе°ҶйңҖиҰҒжү§иЎҢзҡ„ж“ҚдҪңеҶҷе…Ҙж—Ҙеҝ—пјҢзҰҒжӯўе…¶д»–еҶҷе…Ҙж“ҚдҪңпјҲй”Ғе®ҡиө„жәҗпјүгҖӮ
еҰӮжһңеҲҶеёғејҸдәӢеҠЎдёӯжҹҗж•°жҚ®еә“йў„жҸҗдәӨеӨұиҙҘжҲ–жҸҗдәӨеӨұиҙҘпјҢйӮЈиҜҘж•°жҚ®еә“дјҡж №жҚ®ж—Ҙеҝ—иҝӣиЎҢиҮӘиә«зҡ„ж“ҚдҪңеӣһж»ҡпјҢ并解й”ҒгҖӮ
2 жҸҗдәӨйҳ¶ж®ө
еҲҶеёғејҸдәӢеҠЎеӨ„зҗҶзі»з»ҹеҜ№еҗ„дёӘиө„жәҗз®ЎзҗҶеҷЁдёӢиҫҫжҸҗдәӨ/еӣһж»ҡзҡ„жҢҮд»ӨпјҢдҪҝж•ҙдёӘеҲҶеёғејҸдәӢеҠЎз»“жқҹгҖӮ
еҪ“дёҖдёӘж•°жҚ®еә“жҺҘеҸ—еҲ°жҸҗдәӨ/еӣһж»ҡжҢҮд»Өж—¶пјҢе®ғе°Ҷж №жҚ®з¬¬дёҖйҳ¶ж®өзҡ„ж—Ҙеҝ—иҝӣиЎҢжҸҗдәӨ/еӣһж»ҡеӨ„зҗҶгҖӮ
дёӨйҳ¶ж®өжҸҗдәӨеҚҸи®®еҸҜд»ҘеңЁж•°жҚ®еә“еұӮйқўйҖҡиҝҮй©ұеҠЁж”ҜжҢҒпјҢд№ҹеҸҜд»ҘеңЁеә”з”ЁжЎҶжһ¶дёӯжҢүз…§е…¶еҺҹзҗҶиҝӣиЎҢи®ҫи®Ўе®һзҺ°гҖӮ
дёӨйҳ¶ж®өжҸҗдәӨеҚҸи®®пјҲTwo Phase Commitment ProtocolпјүжҳҜеҲҶеёғејҸдәӢеҠЎзҡ„еҹәзЎҖеҚҸи®®гҖӮ
еңЁжӯӨеҚҸи®®дёӯпјҢдёҖдёӘдәӢеҠЎеҚҸи°ғеҷЁпјҲTM, transaction managerпјүеҚҸи°ғеӨҡдёӘиө„жәҗз®ЎзҗҶеҷЁпјҲRM, resource managerпјүзҡ„жҙ»еҠЁпјӣеңЁдёҖйҳ¶ж®өжүҖжңүиө„жәҗз®ЎзҗҶеҷЁпјҲRMпјүеҗ‘дәӢеҠЎз®ЎзҗҶеҷЁпјҲTMпјүжұҮжҠҘиҮӘиә«жҙ»еҠЁзҠ¶жҖҒпјҢеңЁз¬¬дәҢйҳ¶ж®өдәӢеҠЎз®ЎзҗҶеҷЁпјҲTMпјүж №жҚ®еҗ„иө„жәҗз®ЎзҗҶеҷЁпјҲRMпјүжұҮжҠҘзҡ„зҠ¶жҖҒпјҢжқҘеҶіе®ҡеҗ„RMжҳҜжү§иЎҢжҸҗдәӨж“ҚдҪңиҝҳжҳҜеӣһж»ҡж“ҚдҪңпјӣе…·дҪ“жҸҸиҝ°еҰӮдёӢпјҡ
еә”з”ЁзЁӢеәҸеҗ‘дәӢеҠЎз®ЎзҗҶеҷЁпјҲTMпјүжҸҗдәӨиҜ·жұӮпјҢеҸ‘иө·ж–№еҲҶеёғејҸдәӢеҠЎпјӣ
дёҖйҳ¶ж®өпјҢдәӢеҠЎз®ЎзҗҶеҷЁпјҲTMпјүиҒ”з»ңжүҖжңүиө„жәҗз®ЎзҗҶеҷЁпјҲRMпјүпјҢйҖҡзҹҘе®ғ们жү§иЎҢеҮҶеӨҮж“ҚдҪңпјӣ
иө„жәҗз®ЎзҗҶеҷЁпјҲRMпјүиҝ”еӣһеҮҶеӨҮжҲҗеҠҹпјҢжҲ–иҖ…еӨұиҙҘзҡ„ж¶ҲжҒҜз»ҷTMпјҲе“Қеә”и¶…ж—¶з®—дҪңеӨұиҙҘпјүпјӣ
йҖҡиҝҮдәӢеҠЎз®ЎзҗҶеҷЁ2йҳ¶ж®өеҚҸи°ғиө„жәҗз®ЎзҗҶеҷЁпјҢдҪҝжүҖжңүиө„жәҗз®ЎзҗҶеҷЁзҡ„зҠ¶жҖҒжңҖз»ҲйғҪжҳҜдёҖиҮҙзҡ„пјҢиҰҒд№Ҳе…ЁйғЁжҸҗдәӨпјҢиҰҒд№Ҳе…ЁйғЁеӣһж»ҡгҖӮ
XAжҳҜX/Openз»„з»ҮжҸҗеҮәзҡ„пјҢе®ҡд№үдәҶдәӢеҠЎз®ЎзҗҶеҷЁдёҺиө„жәҗз®ЎзҗҶеҷЁд№Ӣй—ҙйҖҡдҝЎзҡ„жҺҘеҸЈеҚҸи®®пјӣXAеҚҸи®®з”ұж•°жҚ®еә“е®һзҺ°пјҢзӣ®еүҚж”ҜжҢҒXAеҚҸи®®зҡ„ж•°жҚ®еә“жңүOracleгҖҒMySqlгҖҒBD2зӯүпјӣ
XAе®ҡд№үдәҶдёҖзі»еҲ—зҡ„жҺҘеҸЈпјҡ
xa_start: еҗҜеҠЁXAдәӢеҠЎ
xa_end: з»“жқҹXAдәӢеҠЎ
xa_prepare: еҮҶеӨҮйҳ¶ж®өпјҢXAдәӢеҠЎйў„жҸҗдәӨ
xa_commitпјҡжҸҗдәӨXAдәӢеҠЎ
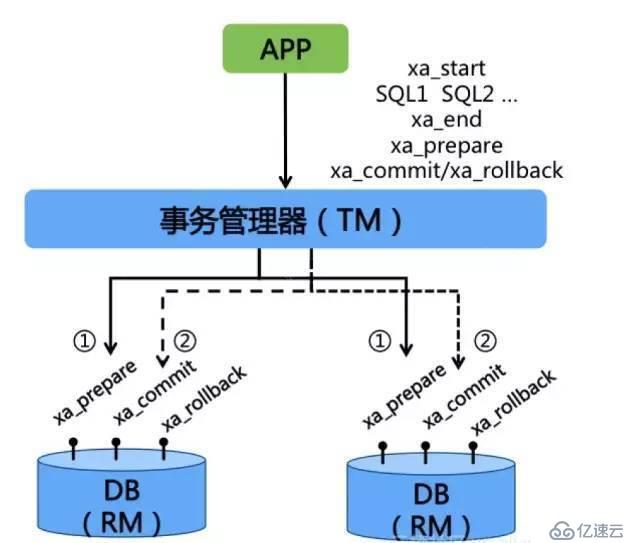
дёҖдёӘж•°жҚ®еә“е®һзҺ°XAеҚҸи®®д№ӢеҗҺпјҢе®ғе°ұеҸҜд»ҘдҪңдёәдҪңдёәдёҖдёӘиө„жәҗз®ЎзҗҶеҷЁеҸӮдёҺеҲ°еҲҶеёғејҸдәӢеҠЎдёӯ;
еңЁдёҖйҳ¶ж®өпјҢдәӢеҠЎз®ЎзҗҶеҷЁеҚҸи°ғжүҖжңүж•°жҚ®еә“жү§иЎҢXAдәӢеҠЎпјҲxa_startгҖҒз”ЁжҲ·SQLгҖҒxa_endпјүпјҢ并е®ҢжҲҗXAдәӢеҠЎйў„жҸҗдәӨпјҲxa_prepareпјүпјӣ
еңЁдәҢйҳ¶ж®өпјҢеҰӮжһңжүҖжңүж•°жҚ®еә“дёҠXAдәӢеҠЎйў„жҸҗдәӨеқҮжҲҗеҠҹпјҢйӮЈд№ҲдәӢеҠЎз®ЎзҗҶеҷЁеҚҸи°ғжүҖжңүж•°жҚ®еә“жҸҗдәӨXAдәӢеҠЎпјҲxa_commitпјүпјӣеҰӮжһңд»»дёҖж•°жҚ®еә“дёҠXAжҳҜжҲ‘йў„жҸҗдәӨеӨұиҙҘпјҢйӮЈд№ҲдәӢеҠЎз®ЎзҗҶеҷЁдјҡеҚҸи°ғжүҖжңүж•°жҚ®з»„еӣһж»ҡXAдәӢеҠЎпјҲxa_rollbackпјү;
еҲҶеёғејҸдәӢзү©еҹәжң¬зҗҶи®ә: еҹәжң¬йҒөеҫӘCPAзҗҶи®әпјҢйҮҮз”Ёжҹ”жҖ§дәӢзү©зү№еҫҒпјҢиҪҜзҠ¶жҖҒжҲ–иҖ…жңҖз»ҲдёҖиҮҙжҖ§зү№зӮ№дҝқиҜҒеҲҶеёғејҸдәӢзү©дёҖиҮҙжҖ§й—®йўҳгҖӮ
еҲҶеёғејҸдәӢеҠЎеёёи§Ғи§ЈеҶіж–№жЎҲ:
2PCдёӨж®өжҸҗдәӨеҚҸи®®
3PCдёүж®өжҸҗдәӨеҚҸи®®(ејҘиЎҘдёӨз«ҜжҸҗдәӨеҚҸи®®зјәзӮ№)
TCCжҲ–иҖ…GTS(йҳҝйҮҢ)
ж¶ҲжҒҜдёӯй—ҙ件жңҖз»ҲдёҖиҮҙжҖ§
дёӨйҳ¶ж®өжҸҗдәӨеҸҲз§°2PC,2PCжҳҜдёҖдёӘйқһеёёз»Ҹе…ёзҡ„ејәдёҖиҮҙгҖҒдёӯеҝғеҢ–зҡ„еҺҹеӯҗжҸҗдәӨеҚҸи®®гҖӮ
иҝҷйҮҢжүҖиҜҙзҡ„дёӯеҝғеҢ–жҳҜжҢҮеҚҸи®®дёӯжңүдёӨзұ»иҠӮзӮ№пјҡдёҖдёӘжҳҜдёӯеҝғеҢ–еҚҸи°ғиҖ…иҠӮзӮ№пјҲcoordinatorпјүе’ҢNдёӘеҸӮдёҺиҖ…иҠӮзӮ№пјҲpartcipantпјүгҖӮ
дёӨдёӘйҳ¶ж®өпјҡ第дёҖйҳ¶ж®өпјҡжҠ•зҘЁйҳ¶ж®өВ е’Ң第дәҢйҳ¶ж®өпјҡжҸҗдәӨ/жү§иЎҢйҳ¶ж®өгҖӮ
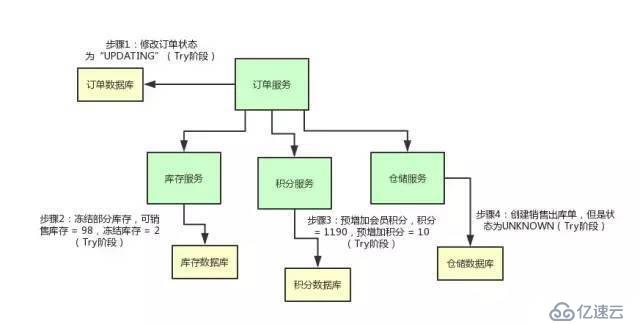
дёҫдҫӢВ и®ўеҚ•жңҚеҠЎAпјҢйңҖиҰҒи°ғз”ЁВ ж”Ҝд»ҳжңҚеҠЎBВ еҺ»ж”Ҝд»ҳпјҢж”Ҝд»ҳжҲҗеҠҹеҲҷеӨ„зҗҶиҙӯзү©и®ўеҚ•дёәеҫ…еҸ‘иҙ§зҠ¶жҖҒпјҢеҗҰеҲҷе°ұйңҖиҰҒе°Ҷиҙӯзү©и®ўеҚ•еӨ„зҗҶдёәеӨұиҙҘзҠ¶жҖҒгҖӮ
йӮЈд№ҲзңӢ2PCйҳ¶ж®өжҳҜеҰӮдҪ•еӨ„зҗҶзҡ„
image
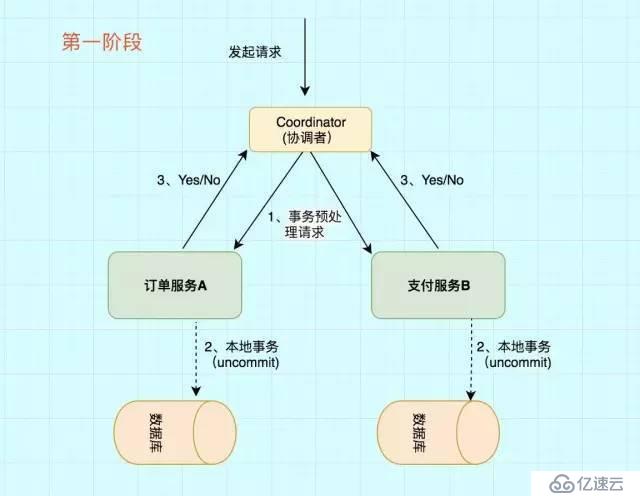
第дёҖйҳ¶ж®өдё»иҰҒеҲҶдёә3жӯҘ
1пјүдәӢеҠЎиҜўй—®
еҚҸи°ғиҖ…В еҗ‘жүҖжңүзҡ„В еҸӮдёҺиҖ…В еҸ‘йҖҒдәӢеҠЎйў„еӨ„зҗҶиҜ·жұӮпјҢз§°д№ӢдёәPrepareпјҢ并ејҖе§Ӣзӯүеҫ…еҗ„В еҸӮдёҺиҖ…В зҡ„е“Қеә”гҖӮ
2пјүжү§иЎҢжң¬ең°дәӢеҠЎ
еҗ„дёӘВ еҸӮдёҺиҖ…В иҠӮзӮ№жү§иЎҢжң¬ең°дәӢеҠЎж“ҚдҪң,дҪҶеңЁжү§иЎҢе®ҢжҲҗеҗҺ并дёҚдјҡзңҹжӯЈжҸҗдәӨж•°жҚ®еә“жң¬ең°дәӢеҠЎпјҢиҖҢжҳҜе…Ҳеҗ‘В еҚҸи°ғиҖ…В жҠҘе‘ҠиҜҙпјҡвҖңжҲ‘иҝҷиҫ№еҸҜд»ҘеӨ„зҗҶдәҶ/жҲ‘иҝҷиҫ№дёҚиғҪеӨ„зҗҶвҖқгҖӮ.
3пјүеҗ„еҸӮдёҺиҖ…еҗ‘еҚҸи°ғиҖ…еҸҚйҰҲдәӢеҠЎиҜўй—®зҡ„е“Қеә”
еҰӮжһңВ еҸӮдёҺиҖ…В жҲҗеҠҹжү§иЎҢдәҶдәӢеҠЎж“ҚдҪң,йӮЈд№Ҳе°ұеҸҚйҰҲз»ҷеҚҸи°ғиҖ…В YesВ е“Қеә”,иЎЁзӨәдәӢеҠЎеҸҜд»Ҙжү§иЎҢ,еҰӮжһңжІЎжңүВ еҸӮдёҺиҖ…В жҲҗеҠҹжү§иЎҢдәӢеҠЎ,йӮЈд№Ҳе°ұеҸҚйҰҲз»ҷеҚҸи°ғиҖ…В NoВ е“Қеә”,иЎЁзӨәдәӢеҠЎдёҚеҸҜд»Ҙжү§иЎҢгҖӮ
第дёҖйҳ¶ж®өжү§иЎҢе®ҢеҗҺпјҢдјҡжңүдёӨз§ҚеҸҜиғҪгҖӮ1гҖҒжүҖжңүйғҪиҝ”еӣһYes. 2гҖҒжңүдёҖдёӘжҲ–иҖ…еӨҡдёӘиҝ”еӣһNoгҖӮ
жҲҗеҠҹжқЎд»¶пјҡжүҖжңүеҸӮдёҺиҖ…йғҪиҝ”еӣһYesгҖӮ
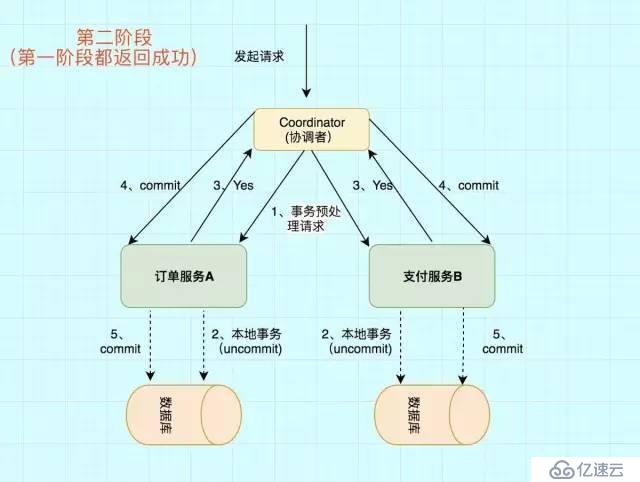
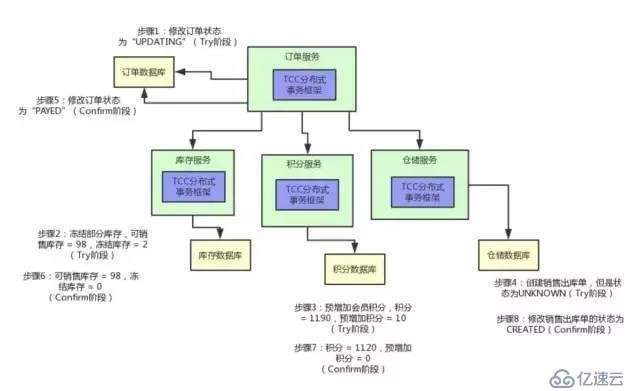
第дәҢйҳ¶ж®өдё»иҰҒеҲҶдёәдёӨжӯҘ
1)жүҖжңүзҡ„еҸӮдёҺиҖ…еҸҚйҰҲз»ҷеҚҸи°ғиҖ…зҡ„дҝЎжҒҜйғҪжҳҜYes,йӮЈд№Ҳе°ұдјҡжү§иЎҢдәӢеҠЎжҸҗдәӨ
В еҚҸи°ғиҖ…В еҗ‘В жүҖжңүеҸӮдёҺиҖ…В иҠӮзӮ№еҸ‘еҮәCommitиҜ·жұӮ.
2)дәӢеҠЎжҸҗдәӨ
В еҸӮдёҺиҖ… 收еҲ°CommitиҜ·жұӮд№ӢеҗҺ,е°ұдјҡжӯЈејҸжү§иЎҢжң¬ең°дәӢеҠЎCommitж“ҚдҪң,并еңЁе®ҢжҲҗжҸҗдәӨд№ӢеҗҺйҮҠж”ҫж•ҙдёӘдәӢеҠЎжү§иЎҢжңҹй—ҙеҚ з”Ёзҡ„дәӢеҠЎиө„жәҗгҖӮ
ејӮеёёжқЎд»¶пјҡд»»дҪ•дёҖдёӘВ еҸӮдёҺиҖ…В еҗ‘В еҚҸи°ғиҖ…В еҸҚйҰҲдәҶВ NoВ е“Қеә”,жҲ–иҖ…зӯүеҫ…и¶…ж—¶д№ӢеҗҺ,еҚҸи°ғиҖ…е°ҡжңӘ收еҲ°жүҖжңүеҸӮдёҺиҖ…зҡ„еҸҚйҰҲе“Қеә”гҖӮ
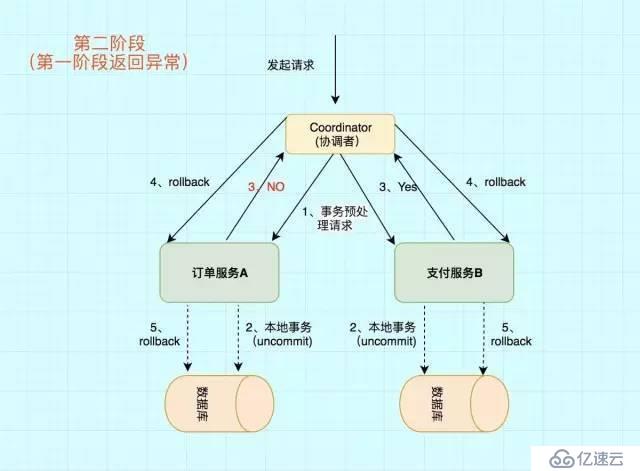
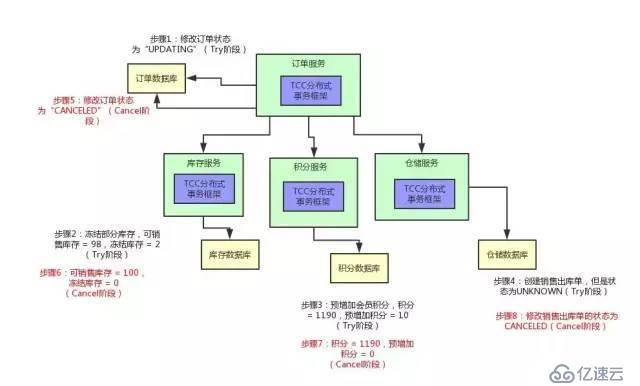
ејӮеёёжөҒзЁӢ第дәҢйҳ¶ж®өд№ҹеҲҶдёәдёӨжӯҘ
1)еҸ‘йҖҒеӣһж»ҡиҜ·жұӮ
В еҚҸи°ғиҖ…В еҗ‘жүҖжңүеҸӮдёҺиҖ…иҠӮзӮ№еҸ‘еҮәВ RoollBackВ иҜ·жұӮ.
2)дәӢеҠЎеӣһж»ҡ
В еҸӮдёҺиҖ…В жҺҘ收еҲ°RoollBackиҜ·жұӮеҗҺ,дјҡеӣһж»ҡжң¬ең°дәӢеҠЎгҖӮ
йҖҡиҝҮдёҠйқўзҡ„жј”зӨәпјҢеҫҲе®№жҳ“жғіеҲ°2pcжүҖеёҰжқҘзҡ„зјәйҷ·
1пјүжҖ§иғҪй—®йўҳ
ж— и®әжҳҜеңЁз¬¬дёҖйҳ¶ж®өзҡ„иҝҮзЁӢдёӯ,иҝҳжҳҜеңЁз¬¬дәҢйҳ¶ж®ө,жүҖжңүзҡ„еҸӮдёҺиҖ…иө„жәҗе’ҢеҚҸи°ғиҖ…иө„жәҗйғҪжҳҜиў«й”ҒдҪҸзҡ„,еҸӘжңүеҪ“жүҖжңүиҠӮзӮ№еҮҶеӨҮе®ҢжҜ•пјҢдәӢеҠЎВ еҚҸи°ғиҖ…В жүҚдјҡйҖҡзҹҘиҝӣиЎҢе…ЁеұҖжҸҗдәӨпјҢ
еҸӮдёҺиҖ…В иҝӣиЎҢжң¬ең°дәӢеҠЎжҸҗдәӨеҗҺжүҚдјҡйҮҠж”ҫиө„жәҗгҖӮиҝҷж ·зҡ„иҝҮзЁӢдјҡжҜ”иҫғжј«й•ҝпјҢеҜ№жҖ§иғҪеҪұе“ҚжҜ”иҫғеӨ§гҖӮ
2пјүеҚ•иҠӮзӮ№ж•…йҡң
з”ұдәҺеҚҸи°ғиҖ…зҡ„йҮҚиҰҒжҖ§пјҢдёҖж—ҰВ еҚҸи°ғиҖ…В еҸ‘з”ҹж•…йҡңгҖӮеҸӮдёҺиҖ…В дјҡдёҖзӣҙйҳ»еЎһдёӢеҺ»гҖӮе°Өе…¶еңЁз¬¬дәҢйҳ¶ж®өпјҢеҚҸи°ғиҖ…В еҸ‘з”ҹж•…йҡңпјҢйӮЈд№ҲжүҖжңүзҡ„В еҸӮдёҺиҖ…В иҝҳйғҪеӨ„дәҺ
й”Ғе®ҡдәӢеҠЎиө„жәҗзҡ„зҠ¶жҖҒдёӯпјҢиҖҢж— жі•з»§з»ӯе®ҢжҲҗдәӢеҠЎж“ҚдҪңгҖӮпјҲиҷҪ然еҚҸи°ғиҖ…жҢӮжҺүпјҢеҸҜд»ҘйҮҚж–°йҖүдёҫдёҖдёӘеҚҸи°ғиҖ…пјҢдҪҶжҳҜж— жі•и§ЈеҶіеӣ дёәеҚҸи°ғиҖ…е®•жңәеҜјиҮҙзҡ„еҸӮдёҺиҖ…еӨ„дәҺйҳ»еЎһзҠ¶жҖҒзҡ„й—®йўҳпјү
2PCеҮәзҺ°еҚ•зӮ№й—®йўҳзҡ„дёүз§Қжғ…еҶө
(1)еҚҸи°ғиҖ…жӯЈеёё,еҸӮдёҺиҖ…е®•жңә
з”ұдәҺВ еҚҸи°ғиҖ…В ж— жі•ж”¶йӣҶеҲ°жүҖжңүВ еҸӮдёҺиҖ…В зҡ„еҸҚйҰҲпјҢдјҡйҷ·е…Ҙйҳ»еЎһжғ…еҶөгҖӮ
В и§ЈеҶіж–№жЎҲ:еј•е…Ҙи¶…ж—¶жңәеҲ¶,еҰӮжһңеҚҸи°ғиҖ…еңЁи¶…иҝҮжҢҮе®ҡзҡ„ж—¶й—ҙиҝҳжІЎжңү收еҲ°еҸӮдёҺиҖ…зҡ„еҸҚйҰҲ,дәӢеҠЎе°ұеӨұиҙҘ,еҗ‘жүҖжңүиҠӮзӮ№еҸ‘йҖҒз»ҲжӯўдәӢеҠЎиҜ·жұӮгҖӮ
(2)еҚҸи°ғиҖ…е®•жңә,еҸӮдёҺиҖ…жӯЈеёё
ж— и®әеӨ„дәҺе“ӘдёӘйҳ¶ж®өпјҢз”ұдәҺеҚҸи°ғиҖ…е®•жңәпјҢж— жі•еҸ‘йҖҒжҸҗдәӨиҜ·жұӮпјҢжүҖжңүеӨ„дәҺжү§иЎҢдәҶж“ҚдҪңдҪҶжҳҜжңӘжҸҗдәӨзҠ¶жҖҒзҡ„еҸӮдёҺиҖ…йғҪдјҡйҷ·е…Ҙйҳ»еЎһжғ…еҶө.
В и§ЈеҶіж–№жЎҲ:еј•е…ҘеҚҸи°ғиҖ…еӨҮд»Ҫ,еҗҢж—¶еҚҸи°ғиҖ…йңҖи®°еҪ•ж“ҚдҪңж—Ҙеҝ—.еҪ“жЈҖжөӢеҲ°еҚҸи°ғиҖ…е®•жңәдёҖж®өж—¶й—ҙеҗҺпјҢеҚҸи°ғиҖ…еӨҮд»ҪеҸ–д»ЈеҚҸи°ғиҖ…пјҢ并иҜ»еҸ–ж“ҚдҪңж—Ҙеҝ—пјҢеҗ‘жүҖжңүеҸӮдёҺиҖ…иҜўй—®зҠ¶жҖҒгҖӮ
(3)еҚҸи°ғиҖ…е’ҢеҸӮдёҺиҖ…йғҪе®•жңә
2)еҸ‘з”ҹеңЁз¬¬дәҢйҳ¶ж®ө 并且 жҢӮдәҶзҡ„еҸӮдёҺиҖ…еңЁжҢӮжҺүд№ӢеүҚжІЎжңү收еҲ°еҚҸи°ғиҖ…зҡ„жҢҮд»ӨгҖӮд№ҹе°ұжҳҜдёҠйқўзҡ„第4жӯҘжҢӮдәҶпјҢиҝҷжҳҜеҸҜиғҪеҚҸи°ғиҖ…иҝҳжІЎжңүеҸ‘йҖҒ第4жӯҘе°ұжҢӮдәҶгҖӮиҝҷз§Қжғ…еҪўдёӢпјҢж–°зҡ„еҚҸи°ғиҖ…йҮҚж–°жү§иЎҢ第дёҖйҳ¶ж®өе’Ң第дәҢйҳ¶ж®өж“ҚдҪңгҖӮ
3)еҸ‘з”ҹеңЁз¬¬дәҢйҳ¶ж®ө 并且 жңүйғЁеҲҶеҸӮдёҺиҖ…е·Із»Ҹжү§иЎҢе®Ңcommitж“ҚдҪңгҖӮе°ұеҘҪжҜ”иҝҷйҮҢи®ўеҚ•жңҚеҠЎAе’Ңж”Ҝд»ҳжңҚеҠЎBйғҪ收еҲ°еҚҸи°ғиҖ…В еҸ‘йҖҒзҡ„commitдҝЎжҒҜпјҢејҖе§ӢзңҹжӯЈжү§иЎҢжң¬ең°дәӢеҠЎcommit,дҪҶзӘҒеҸ‘жғ…еҶөпјҢAcommitжҲҗеҠҹпјҢBзЎ®жҢӮдәҶгҖӮиҝҷдёӘж—¶еҖҷзӣ®еүҚжқҘи®Іж•°жҚ®жҳҜдёҚдёҖиҮҙзҡ„гҖӮиҷҪ然иҝҷдёӘж—¶еҖҷеҸҜд»ҘеҶҚйҖҡиҝҮжүӢж®өи®©д»–е’ҢеҚҸи°ғиҖ…йҖҡдҝЎпјҢеҶҚжғіеҠһжі•жҠҠж•°жҚ®жҗһжҲҗдёҖиҮҙзҡ„пјҢдҪҶжҳҜпјҢиҝҷж®өж—¶й—ҙеҶ…д»–зҡ„ж•°жҚ®зҠ¶жҖҒе·Із»ҸжҳҜдёҚдёҖиҮҙзҡ„дәҶпјҒ2PC ж— жі•и§ЈеҶіиҝҷдёӘй—®йўҳгҖӮ
дёүйҳ¶ж®өжҸҗдәӨеҚҸи®®пјҲ3PCпјүдё»иҰҒжҳҜдёәдәҶи§ЈеҶідёӨйҳ¶ж®өжҸҗдәӨеҚҸи®®зҡ„йҳ»еЎһй—®йўҳпјҢ2pcеӯҳеңЁзҡ„й—®йўҳжҳҜеҪ“еҚҸдҪңиҖ…еҙ©жәғж—¶пјҢеҸӮдёҺиҖ…дёҚиғҪеҒҡеҮәжңҖеҗҺзҡ„йҖүжӢ©гҖӮеӣ жӯӨеҸӮдёҺиҖ…еҸҜиғҪеңЁеҚҸдҪңиҖ…жҒўеӨҚд№ӢеүҚдҝқжҢҒйҳ»еЎһгҖӮ
дёүйҳ¶ж®өжҸҗдәӨпјҲThree-phase commitпјүпјҢжҳҜдәҢйҳ¶ж®өжҸҗдәӨпјҲ2PCпјүзҡ„ж”№иҝӣзүҲжң¬гҖӮ
дёҺдёӨйҳ¶ж®өжҸҗдәӨдёҚеҗҢзҡ„жҳҜпјҢдёүйҳ¶ж®өжҸҗдәӨжңүдёӨдёӘж”№еҠЁзӮ№гҖӮ
1гҖҒ еј•е…Ҙи¶…ж—¶жңәеҲ¶гҖӮеҗҢж—¶еңЁеҚҸи°ғиҖ…е’ҢеҸӮдёҺиҖ…дёӯйғҪеј•е…Ҙи¶…ж—¶жңәеҲ¶гҖӮ
2гҖҒеңЁз¬¬дёҖйҳ¶ж®өе’Ң第дәҢйҳ¶ж®өдёӯжҸ’е…ҘдёҖдёӘеҮҶеӨҮйҳ¶ж®өгҖӮдҝқиҜҒдәҶеңЁжңҖеҗҺжҸҗдәӨйҳ¶ж®өд№ӢеүҚеҗ„еҸӮдёҺиҠӮзӮ№зҡ„зҠ¶жҖҒжҳҜдёҖиҮҙзҡ„гҖӮ
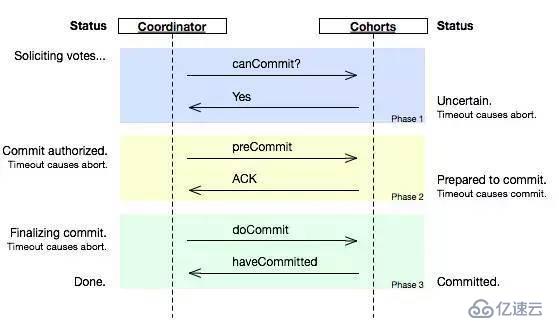
д№ҹе°ұжҳҜиҜҙпјҢйҷӨдәҶеј•е…Ҙи¶…ж—¶жңәеҲ¶д№ӢеӨ–пјҢ3PCжҠҠ2PCзҡ„еҮҶеӨҮйҳ¶ж®өеҶҚж¬ЎдёҖеҲҶдёәдәҢпјҢиҝҷж ·дёүйҳ¶ж®өжҸҗдәӨе°ұжңү
CanCommitгҖҒPreCommitгҖҒDoCommit
дёүдёӘйҳ¶ж®өгҖӮ
д№ӢеүҚ2PCзҡ„дёҖйҳ¶ж®өжҳҜжң¬ең°дәӢеҠЎжү§иЎҢз»“жқҹеҗҺпјҢжңҖеҗҺдёҚCommit,зӯүе…¶е®ғжңҚеҠЎйғҪжү§иЎҢз»“жқҹ并иҝ”еӣһYesпјҢз”ұеҚҸи°ғиҖ…еҸ‘з”ҹcommitжүҚзңҹжӯЈжү§иЎҢcommitгҖӮиҖҢиҝҷйҮҢзҡ„CanCommitжҢҮзҡ„жҳҜВ е°қиҜ•иҺ·еҸ–ж•°жҚ®еә“й”ҒВ еҰӮжһңеҸҜд»ҘпјҢе°ұиҝ”еӣһYesгҖӮ
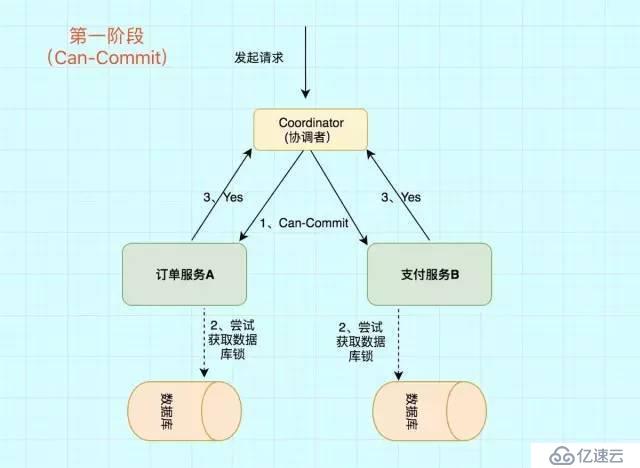
иҝҷйҳ¶ж®өдё»иҰҒеҲҶдёә2жӯҘ
дәӢеҠЎиҜўй—®В еҚҸи°ғиҖ…В еҗ‘В еҸӮдёҺиҖ…В еҸ‘йҖҒCanCommitиҜ·жұӮгҖӮиҜўй—®жҳҜеҗҰеҸҜд»Ҙжү§иЎҢдәӢеҠЎжҸҗдәӨж“ҚдҪңгҖӮ然еҗҺејҖе§Ӣзӯүеҫ…В еҸӮдёҺиҖ…В зҡ„е“Қеә”гҖӮе“Қеә”еҸҚйҰҲВ еҸӮдёҺиҖ…В жҺҘеҲ°CanCommitиҜ·жұӮд№ӢеҗҺпјҢжӯЈеёёжғ…еҶөдёӢпјҢеҰӮжһңе…¶иҮӘиә«и®ӨдёәеҸҜд»ҘйЎәеҲ©жү§иЎҢдәӢеҠЎпјҢеҲҷиҝ”еӣһYesе“Қеә”пјҢ并иҝӣе…Ҙйў„еӨҮзҠ¶жҖҒгҖӮеҗҰеҲҷеҸҚйҰҲNo
еңЁйҳ¶ж®өдёҖдёӯпјҢеҰӮжһңжүҖжңүзҡ„еҸӮдёҺиҖ…йғҪиҝ”еӣһYesзҡ„иҜқпјҢйӮЈд№Ҳе°ұдјҡиҝӣе…ҘPreCommitйҳ¶ж®өиҝӣиЎҢдәӢеҠЎйў„жҸҗдәӨгҖӮиҝҷйҮҢзҡ„PreCommitйҳ¶ж®өВ и·ҹдёҠйқўзҡ„第дёҖйҳ¶ж®өжҳҜе·®дёҚеӨҡзҡ„пјҢеҸӘдёҚиҝҮиҝҷйҮҢВ еҚҸи°ғиҖ…е’ҢеҸӮдёҺиҖ…йғҪеј•е…ҘдәҶи¶…ж—¶жңәеҲ¶В пјҲ2PCдёӯеҸӘжңүеҚҸи°ғиҖ…еҸҜд»Ҙи¶…ж—¶пјҢеҸӮдёҺиҖ…жІЎжңүи¶…ж—¶жңәеҲ¶пјүгҖӮ
иҝҷйҮҢи·ҹ2pcзҡ„йҳ¶ж®өдәҢжҳҜе·®дёҚеӨҡзҡ„гҖӮ
жҖ»з»“
зӣёжҜ”иҫғ2PCиҖҢиЁҖпјҢ3PCеҜ№дәҺеҚҸи°ғиҖ…пјҲCoordinatorпјүе’ҢеҸӮдёҺиҖ…пјҲPartcipantпјүйғҪи®ҫзҪ®дәҶи¶…ж—¶ж—¶й—ҙпјҢиҖҢ2PCеҸӘжңүеҚҸи°ғиҖ…жүҚжӢҘжңүи¶…ж—¶жңәеҲ¶гҖӮиҝҷи§ЈеҶідәҶдёҖдёӘд»Җд№Ҳй—®йўҳе‘ўпјҹ
иҝҷдёӘдјҳеҢ–зӮ№пјҢдё»иҰҒжҳҜйҒҝе…ҚдәҶеҸӮдёҺиҖ…еңЁй•ҝж—¶й—ҙж— жі•дёҺеҚҸи°ғиҖ…иҠӮзӮ№йҖҡи®ҜпјҲеҚҸи°ғиҖ…жҢӮжҺүдәҶпјүзҡ„жғ…еҶөдёӢпјҢж— жі•йҮҠж”ҫиө„жәҗзҡ„й—®йўҳпјҢеӣ дёәеҸӮдёҺиҖ…иҮӘиә«жӢҘжңүи¶…ж—¶жңәеҲ¶дјҡеңЁи¶…ж—¶еҗҺпјҢ
иҮӘеҠЁиҝӣиЎҢжң¬ең°commitд»ҺиҖҢиҝӣиЎҢйҮҠж”ҫиө„жәҗгҖӮиҖҢиҝҷз§ҚжңәеҲ¶д№ҹдҫ§йқўйҷҚдҪҺдәҶж•ҙдёӘдәӢеҠЎзҡ„йҳ»еЎһж—¶й—ҙе’ҢиҢғеӣҙгҖӮ
еҸҰеӨ–пјҢйҖҡиҝҮCanCommitгҖҒPreCommitгҖҒDoCommitдёүдёӘйҳ¶ж®өзҡ„и®ҫи®ЎпјҢзӣёиҫғдәҺ2PCиҖҢиЁҖпјҢеӨҡи®ҫзҪ®дәҶдёҖдёӘзј“еҶІйҳ¶ж®өдҝқиҜҒдәҶеңЁжңҖеҗҺжҸҗдәӨйҳ¶ж®өд№ӢеүҚеҗ„еҸӮдёҺиҠӮзӮ№зҡ„зҠ¶жҖҒжҳҜдёҖиҮҙзҡ„гҖӮ
д»ҘдёҠе°ұжҳҜ3PCзӣёеҜ№дәҺ2PCзҡ„дёҖдёӘжҸҗй«ҳпјҲзӣёеҜ№зј“и§ЈдәҶ2PCдёӯзҡ„еүҚдёӨдёӘй—®йўҳпјүпјҢдҪҶжҳҜ3PCдҫқ然没жңүе®Ңе…Ёи§ЈеҶіж•°жҚ®дёҚдёҖиҮҙзҡ„й—®йўҳгҖӮ
TCCдёүдёӘж“ҚдҪңжҸҸиҝ°пјҡ
Try: жЈҖжөӢгҖҒйў„з•ҷиө„жәҗ;
Confirm: дёҡеҠЎзі»з»ҹжү§иЎҢжҸҗдәӨпјӣй»ҳи®ӨConfirmйҳ¶ж®өжҳҜдёҚдјҡеҮәй”ҷзҡ„пјҢеҸӘиҰҒTRYжҲҗеҠҹпјҢCONFIRMдёҖе®ҡжҲҗеҠҹпјӣ
Cancel: дёҡеҠЎеҸ–ж¶ҲпјҢйў„з•ҷиө„жәҗйҮҠж”ҫ;
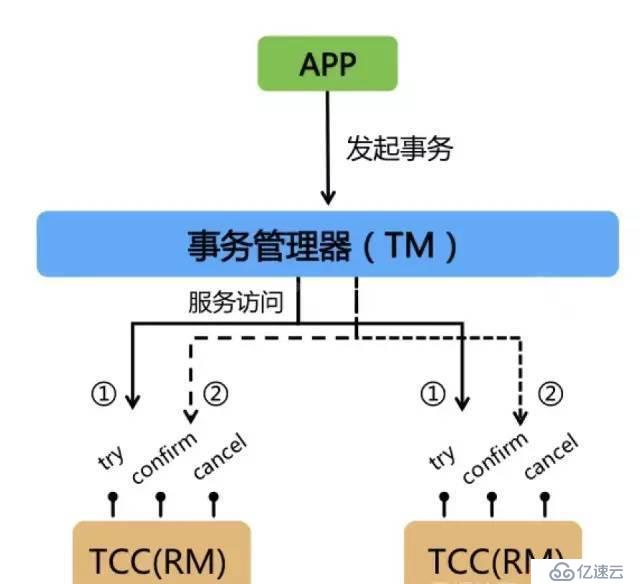
TCCеҸҲз§°иЎҘеҒҝдәӢеҠЎгҖӮе…¶ж ёеҝғжҖқжғіжҳҜпјҡ"й’ҲеҜ№жҜҸдёӘж“ҚдҪңйғҪиҰҒжіЁеҶҢдёҖдёӘдёҺе…¶еҜ№еә”зҡ„зЎ®и®Өе’ҢиЎҘеҒҝпјҲж’Өй”Җж“ҚдҪңпјү"гҖӮе®ғеҲҶдёәдёүдёӘж“ҚдҪңпјҡ
1гҖҒTryйҳ¶ж®өпјҡдё»иҰҒжҳҜеҜ№дёҡеҠЎзі»з»ҹеҒҡжЈҖжөӢеҸҠиө„жәҗйў„з•ҷгҖӮ
2гҖҒConfirmйҳ¶ж®өпјҡзЎ®и®Өжү§иЎҢдёҡеҠЎж“ҚдҪңгҖӮ
3гҖҒCancelйҳ¶ж®өпјҡеҸ–ж¶Ҳжү§иЎҢдёҡеҠЎж“ҚдҪңгҖӮ
TCCеҜ№еә”В TryгҖҒConfirmгҖҒCancelВ дёүз§Қж“ҚдҪңеҸҜд»ҘзҗҶи§ЈжҲҗе…ізі»еһӢж•°жҚ®еә“дәӢеҠЎзҡ„дёүз§Қж“ҚдҪңпјҡDMLгҖҒCommitгҖҒRollbackгҖӮ
еңЁдёҖдёӘи·Ёеә”з”Ёзҡ„дёҡеҠЎж“ҚдҪңдёӯ
TryпјҡTryж“ҚдҪңжҳҜе…ҲжҠҠеӨҡдёӘеә”з”Ёдёӯзҡ„дёҡеҠЎиө„жәҗйў„з•ҷе’Ңй”Ғе®ҡдҪҸпјҢдёәеҗҺз»ӯзҡ„зЎ®и®Өжү“дёӢеҹәзЎҖпјҢзұ»дјјзҡ„пјҢDMLж“ҚдҪңиҰҒй”Ғе®ҡж•°жҚ®еә“и®°еҪ•иЎҢпјҢжҢҒжңүж•°жҚ®еә“иө„жәҗгҖӮ
ConfirmпјҡConfirmж“ҚдҪңжҳҜеңЁTryж“ҚдҪңдёӯж¶үеҸҠзҡ„жүҖжңүеә”з”ЁеқҮжҲҗеҠҹд№ӢеҗҺиҝӣиЎҢзЎ®и®ӨпјҢдҪҝз”Ёйў„з•ҷзҡ„дёҡеҠЎиө„жәҗпјҢе’ҢCommitзұ»дјјпјӣ
CancelпјҡCancelеҲҷжҳҜеҪ“Tryж“ҚдҪңдёӯж¶үеҸҠзҡ„жүҖжңүеә”з”ЁжІЎжңүе…ЁйғЁжҲҗеҠҹпјҢйңҖиҰҒе°Ҷе·ІжҲҗеҠҹзҡ„еә”з”ЁиҝӣиЎҢеҸ–ж¶Ҳ(еҚіRollbackеӣһж»ҡ)гҖӮе…¶дёӯConfirmе’ҢCancelж“ҚдҪңжҳҜдёҖеҜ№еҸҚеҗ‘дёҡеҠЎж“ҚдҪңгҖӮ
TCCзҡ„е…·дҪ“еҺҹзҗҶеӣҫеҰӮпјҲзӣ—еӣҫпјү:
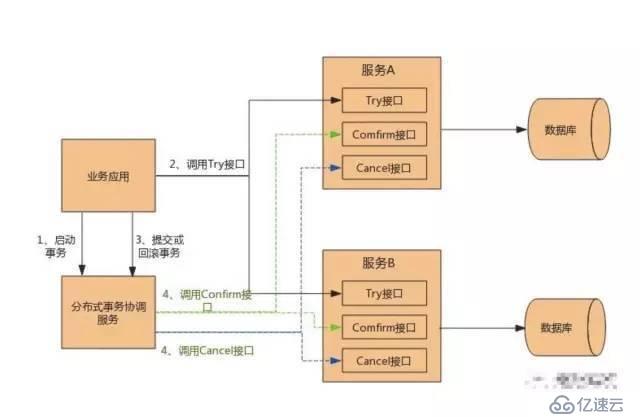
д»ҺеӣҫдёӯжҲ‘们еҸҜд»ҘжҳҺжҳҫзңӢеҲ°Confirmе’ҢCancelж“ҚдҪңжҳҜдёҖеҜ№еҸҚеҗ‘дёҡеҠЎж“ҚдҪңВ еҚіиҰҒtryиҝ”еӣһжҲҗеҠҹжү§иЎҢConfirm,иҰҒд№Ҳtryиҝ”еӣһеӨұиҙҘжү§иЎҢCancelж“ҚдҪңгҖӮ
еҲҶеёғејҸдәӢеҠЎеҚҸи°ғиҖ…пјҡеҲҶеёғејҸдәӢеҠЎеҚҸи°ғиҖ…з®ЎзҗҶжҺ§еҲ¶ж•ҙдёӘдёҡеҠЎжҙ»еҠЁпјҢеҢ…жӢ¬и®°еҪ•з»ҙжҠӨTCCе…ЁеұҖдәӢеҠЎзҡ„дәӢеҠЎзҠ¶жҖҒе’ҢжҜҸдёӘд»ҺдёҡеҠЎжңҚеҠЎзҡ„еӯҗдәӢеҠЎзҠ¶жҖҒпјҢ并еңЁдёҡеҠЎжҙ»еҠЁжҸҗдәӨж—¶зЎ®и®ӨжүҖжңүзҡ„TCCеһӢ
ж“ҚдҪңзҡ„confirmж“ҚдҪңпјҢеңЁдёҡеҠЎжҙ»еҠЁеҸ–ж¶Ҳж—¶и°ғз”ЁжүҖжңүTCCеһӢж“ҚдҪңзҡ„cancelж“ҚдҪңгҖӮ
дҫӢеӯҗпјҡAжңҚеҠЎиҪ¬30еқ—й’ұгҖҒBжңҚеҠЎиҪ¬50еқ—й’ұпјҢдёҖиө·еҲ°CжңҚеҠЎдёҠгҖӮ
Tryпјҡе°қиҜ•жү§иЎҢдёҡеҠЎгҖӮе®ҢжҲҗжүҖжңүдёҡеҠЎжЈҖжҹҘ(дёҖиҮҙжҖ§)пјҡжЈҖжҹҘAгҖҒBгҖҒCзҡ„еёҗжҲ·зҠ¶жҖҒжҳҜеҗҰжӯЈеёёпјҢеёҗжҲ·Aзҡ„дҪҷйўқжҳҜеҗҰдёҚе°‘дәҺ30е…ғпјҢеёҗжҲ·Bзҡ„дҪҷйўқжҳҜеҗҰдёҚе°‘дәҺ50е…ғгҖӮйў„з•ҷеҝ…йЎ»дёҡеҠЎиө„жәҗ
(еҮҶйҡ”зҰ»жҖ§)пјҡеёҗжҲ·Aзҡ„еҶ»з»“йҮ‘йўқеўһеҠ 30е…ғпјҢеёҗжҲ·Bзҡ„еҶ»з»“йҮ‘йўқеўһеҠ 50е…ғпјҢиҝҷж ·е°ұдҝқиҜҒдёҚдјҡеҮәзҺ°е…¶д»–并еҸ‘иҝӣзЁӢжүЈеҮҸдәҶиҝҷдёӨдёӘеёҗжҲ·зҡ„дҪҷйўқиҖҢеҜјиҮҙеңЁеҗҺз»ӯзҡ„зңҹжӯЈиҪ¬еёҗж“ҚдҪңиҝҮзЁӢдёӯпјҢ
еёҗжҲ·Aе’ҢBзҡ„еҸҜз”ЁдҪҷйўқдёҚеӨҹзҡ„жғ…еҶөгҖӮ
ConfirmпјҡзЎ®и®Өжү§иЎҢдёҡеҠЎгҖӮзңҹжӯЈжү§иЎҢдёҡеҠЎпјҡеҰӮжһңTryйҳ¶ж®өеёҗжҲ·AгҖҒBгҖҒCзҠ¶жҖҒжӯЈеёёпјҢдё”еёҗжҲ·AгҖҒBдҪҷйўқеӨҹз”ЁпјҢеҲҷжү§иЎҢеёҗжҲ·Aз»ҷиҙҰжҲ·CиҪ¬иҙҰ30е…ғгҖҒеёҗжҲ·Bз»ҷиҙҰжҲ·CиҪ¬иҙҰ50е…ғзҡ„иҪ¬еёҗ
ж“ҚдҪңгҖӮВ иҝҷж—¶е·Із»ҸдёҚйңҖиҰҒеҒҡд»»дҪ•дёҡеҠЎжЈҖжҹҘпјҢTryйҳ¶ж®өе·Із»Ҹе®ҢжҲҗдәҶдёҡеҠЎжЈҖжҹҘгҖӮеҸӘдҪҝз”ЁTryйҳ¶ж®өйў„з•ҷзҡ„дёҡеҠЎиө„жәҗпјҡеҸӘйңҖиҰҒдҪҝз”ЁTryйҳ¶ж®өеёҗжҲ·Aе’ҢеёҗжҲ·BеҶ»з»“зҡ„йҮ‘йўқеҚіеҸҜгҖӮ
CancelпјҡеҸ–ж¶Ҳжү§иЎҢдёҡеҠЎйҮҠж”ҫTryйҳ¶ж®өйў„з•ҷзҡ„дёҡеҠЎиө„жәҗпјҡеҰӮжһңTryйҳ¶ж®өйғЁеҲҶжҲҗеҠҹпјҢжҜ”еҰӮеёҗжҲ·Aзҡ„дҪҷйўқеӨҹз”ЁпјҢдё”еҶ»з»“зӣёеә”йҮ‘йўқжҲҗеҠҹпјҢеёҗжҲ·Bзҡ„дҪҷйўқдёҚеӨҹиҖҢеҶ»з»“еӨұиҙҘпјҢеҲҷйңҖиҰҒ
еҜ№еёҗжҲ·AеҒҡCancelж“ҚдҪңпјҢе°ҶеёҗжҲ·Aиў«еҶ»з»“зҡ„йҮ‘йўқи§ЈеҶ»жҺүгҖӮ
2PCжҳҜиө„жәҗеұӮйқўзҡ„еҲҶеёғејҸдәӢеҠЎпјҢејәдёҖиҮҙжҖ§пјҢеңЁдёӨйҳ¶ж®өжҸҗдәӨзҡ„ж•ҙдёӘиҝҮзЁӢдёӯпјҢдёҖзӣҙдјҡжҢҒжңүиө„жәҗзҡ„й”ҒгҖӮ
XAдәӢеҠЎдёӯзҡ„дёӨйҳ¶ж®өжҸҗдәӨеҶ…йғЁиҝҮзЁӢжҳҜеҜ№ејҖеҸ‘иҖ…еұҸи”Ҫзҡ„пјҢдәӢеҠЎз®ЎзҗҶеҷЁеңЁдёӨйҳ¶ж®өжҸҗдәӨиҝҮзЁӢдёӯпјҢд»ҺprepareеҲ°commit/rollbackиҝҮзЁӢдёӯпјҢиө„жәҗе®һйҷ…дёҠдёҖзӣҙйғҪжҳҜиў«еҠ й”Ғзҡ„гҖӮ
еҰӮжһңжңүе…¶д»–дәәйңҖиҰҒжӣҙж–°иҝҷдёӨжқЎи®°еҪ•пјҢйӮЈд№Ҳе°ұеҝ…йЎ»зӯүеҫ…й”ҒйҮҠж”ҫгҖӮ
TCCжҳҜдёҡеҠЎеұӮйқўзҡ„еҲҶеёғејҸдәӢеҠЎпјҢжңҖз»ҲдёҖиҮҙжҖ§пјҢдёҚдјҡдёҖзӣҙжҢҒжңүиө„жәҗзҡ„й”ҒгҖӮ
жҲ‘зҡ„зҗҶи§Је°ұжҳҜеҪ“жү§иЎҢtryжҺҘеҸЈзҡ„ж—¶еҖҷпјҢе·Із»ҸжҠҠжүҖйңҖзҡ„иө„жәҗз»ҷйў„жүЈдәҶпјҢжҜ”еҰӮдёҠйқўдёҫдҫӢзҡ„AжңҚеҠЎе·Із»Ҹйў„жүЈ30е…ғпјҢBжңҚеҠЎе·Із»Ҹйў„жүЈ50е…ғпјҢе®ғжҳҜз”ұtryжҺҘеҸЈе®һзҺ°пјҢиҝҷж ·е°ұдҝқиҜҒдёҚдјҡ
еҮәзҺ°е…¶д»–并еҸ‘иҝӣзЁӢжүЈеҮҸдәҶиҝҷдёӨдёӘеёҗжҲ·зҡ„дҪҷйўқиҖҢеҜјиҮҙеңЁеҗҺз»ӯзҡ„зңҹжӯЈиҪ¬еёҗж“ҚдҪңиҝҮзЁӢдёӯпјҢеёҗжҲ·Aе’ҢBзҡ„еҸҜз”ЁдҪҷйўқдёҚеӨҹзҡ„жғ…еҶөпјҢеҗҢж—¶дҝқиҜҒдёҚдјҡдёҖзӣҙй”ҒдҪҸж•ҙдёӘиө„жәҗгҖӮпјҲж ёеҝғзӮ№еә”иҜҘе°ұеңЁиҝҷпјү
TCCдёӯзҡ„дёӨйҳ¶ж®өжҸҗдәӨ并没жңүеҜ№ејҖеҸ‘иҖ…е®Ңе…ЁеұҸи”ҪпјҢд№ҹе°ұжҳҜиҜҙд»Һд»Јз ҒеұӮйқўпјҢејҖеҸ‘иҖ…жҳҜеҸҜд»Ҙж„ҹеҸ—еҲ°дёӨйҳ¶ж®өжҸҗдәӨзҡ„еӯҳеңЁгҖӮ
1гҖҒtryиҝҮзЁӢзҡ„жң¬ең°дәӢеҠЎпјҢжҳҜдҝқиҜҒиө„жәҗйў„з•ҷзҡ„дёҡеҠЎйҖ»иҫ‘зҡ„жӯЈзЎ®жҖ§гҖӮ
2гҖҒconfirm/cancelжү§иЎҢзҡ„жң¬ең°дәӢеҠЎйҖ»иҫ‘зЎ®и®Ө/еҸ–ж¶Ҳйў„з•ҷиө„жәҗпјҢд»ҘдҝқиҜҒжңҖз»ҲдёҖиҮҙжҖ§пјҢд№ҹе°ұжҳҜжүҖи°“зҡ„иЎҘеҒҝеһӢдәӢеҠЎгҖӮ
з”ұдәҺжҳҜеӨҡдёӘзӢ¬з«Ӣзҡ„жң¬ең°дәӢеҠЎпјҢеӣ жӯӨдёҚдјҡеҜ№иө„жәҗдёҖзӣҙеҠ й”ҒгҖӮ
TCC е®һиҙЁдёҠжҳҜеә”з”ЁеұӮзҡ„2PC пјҢеҘҪжҜ”жҠҠ XA дёӨйҳ¶ж®өжҸҗдәӨйӮЈз§ҚеңЁж•°жҚ®иө„жәҗеұӮеҒҡзҡ„дәӢеҠЎз®ЎзҗҶе·ҘдҪңжҸҗеҲ°дәҶж•°жҚ®еә”з”ЁеұӮгҖӮ
2PCжҳҜиө„жәҗеұӮйқўзҡ„еҲҶеёғејҸдәӢеҠЎпјҢжҳҜејәдёҖиҮҙжҖ§пјҢеңЁдёӨйҳ¶ж®өжҸҗдәӨзҡ„ж•ҙдёӘиҝҮзЁӢдёӯпјҢдёҖзӣҙдјҡжҢҒжңүиө„жәҗзҡ„й”ҒгҖӮ
TCCжҳҜдёҡеҠЎеұӮйқўзҡ„еҲҶеёғејҸдәӢеҠЎпјҢжңҖз»ҲдёҖиҮҙжҖ§пјҢдёҚдјҡдёҖзӣҙжҢҒжңүиө„жәҗзҡ„й”ҒгҖӮ
TCCзӣёжҜ”иҫғдәҺ2PCжқҘи®ІжҖ§иғҪдјҡеҘҪеҫҲеӨҡпјҢдҪҶжҳҜеӣ дёәеҗҢж—¶йңҖиҰҒж”№йҖ tryгҖҒconfirmгҖҒcanel3дёӘжҺҘеҸЈпјҢејҖеҸ‘жҲҗжң¬й«ҳгҖӮ
жіЁж„Ҹ:иҝҳжңүдёҖзӮ№йңҖиҰҒжіЁж„Ҹзҡ„жҳҜConfirmе’ҢCancelж“ҚдҪңеҸҜиғҪиў«йҮҚеӨҚи°ғз”ЁпјҢж•…иҰҒжұӮConfirmе’ҢCancelдёӨдёӘжҺҘеҸЈеҝ…йЎ»жҳҜе№ӮзӯүгҖӮ
еҲ—еӯҗпјҡеҒҮи®ҫВ AВ з»ҷВ BВ иҪ¬В 100еқ—й’ұпјҢеҗҢж—¶е®ғ们дёҚжҳҜеҗҢдёҖдёӘжңҚеҠЎдёҠгҖӮ
зӣ®ж Үпјҡе°ұжҳҜВ AВ еҮҸ100еқ—й’ұпјҢBВ еҠ 100еқ—й’ұгҖӮ
е®һйҷ…жғ…еҶөеҸҜиғҪжңүеӣӣз§Қпјҡ
1пјүе°ұжҳҜAиҙҰжҲ·еҮҸ100 пјҲжҲҗеҠҹпјүпјҢBиҙҰжҲ·еҠ 100 пјҲжҲҗеҠҹпјү2пјүе°ұжҳҜAиҙҰжҲ·еҮҸ100пјҲеӨұиҙҘпјүпјҢBиҙҰжҲ·еҠ 100 пјҲеӨұиҙҘпјү3пјүе°ұжҳҜAиҙҰжҲ·еҮҸ100пјҲжҲҗеҠҹпјүпјҢBиҙҰжҲ·еҠ 100 пјҲеӨұиҙҘпјү4пјүе°ұжҳҜAиҙҰжҲ·еҮҸ100 пјҲеӨұиҙҘпјүпјҢBиҙҰжҲ·еҠ 100 пјҲжҲҗеҠҹпјүиҝҷйҮҢ 第1е’Ң第2В з§Қжғ…еҶөжҳҜиғҪеӨҹдҝқиҜҒдәӢеҠЎзҡ„дёҖиҮҙжҖ§зҡ„пјҢдҪҶжҳҜ 第3е’Ң第4В жҳҜж— жі•дҝқиҜҒдәӢеҠЎзҡ„дёҖиҮҙжҖ§зҡ„гҖӮ
еҚ•ж•°жҚ®еә“дәӢеҠЎе®Ңе…ЁйҒөеҫӘACID规иҢғпјҢеұһдәҺеҲҡжҖ§дәӢеҠЎпјҢеҲҶеёғејҸдәӢеҠЎиҰҒе®Ңе…ЁйҒөеҫӘACID规иҢғжҜ”иҫғеӣ°йҡҫ, еҲҶеёғејҸдәӢеҠЎеұһдәҺжҹ”жҖ§дәӢеҠЎпјҢж»Ўи¶іBASEзҗҶи®әпјӣ
BASEжҸҸиҝ°пјҡBAпјҲBasic Availability еҹәжң¬дёҡеҠЎеҸҜз”ЁжҖ§пјүгҖҒSпјҲSoft state жҹ”жҖ§зҠ¶жҖҒпјүгҖҒEпјҲEventual consistency жңҖз»ҲдёҖиҮҙжҖ§пјүпјӣ
жҹ”жҖ§дәӢеҠЎеҜ№ACIDзҡ„ж”ҜжҢҒпјҡ
1гҖҒеҺҹеӯҗжҖ§пјҡдёҘж јйҒөеҫӘпјӣ
2гҖҒдёҖиҮҙжҖ§пјҡдәӢеҠЎе®ҢжҲҗеҗҺзҡ„дёҖиҮҙжҖ§дёҘж јйҒөеҫӘпјҢдәӢеҠЎдёӯзҡ„дёҖиҮҙжҖ§еҸҜйҖӮеҪ“ж”ҫе®Ҫпјӣ
3гҖҒйҡ”зҰ»жҖ§пјҡ并иЎҢдәӢеҠЎй—ҙдёҚеҸҜеҪұе“ҚпјӣдәӢеҠЎдёӯй—ҙз»“жһңеҸҜи§ҒжҖ§е…Ғи®ёе®үе…Ёж”ҫе®Ҫпјӣ
4гҖҒжҢҒд№…жҖ§пјҡдёҘж јйҒөеҫӘ
дёәдәҶеҸҜз”ЁжҖ§гҖҒжҖ§иғҪзҡ„йңҖиҰҒпјҢжҹ”жҖ§дәӢеҠЎйҷҚдҪҺдәҶдёҖиҮҙжҖ§(C)дёҺйҡ”зҰ»жҖ§(I) зҡ„иҰҒжұӮпјҢеҚівҖңеҹәжң¬еҸҜз”ЁпјҢжңҖз»ҲдёҖиҮҙвҖқ.
йӮЈжҲ‘们жқҘзңӢдёӢRocketMQжҳҜеҰӮдҪ•жқҘдҝқиҜҒдәӢеҠЎзҡ„дёҖиҮҙжҖ§зҡ„гҖӮ
RocketMQиҷҪ然д№ӢеүҚд№ҹж”ҜжҢҒеҲҶеёғејҸдәӢеҠЎпјҢдҪҶ并没жңүејҖжәҗпјҢзӯүеҲ°RocketMQ 4.3жүҚжӯЈејҸејҖжәҗгҖӮ
жңҖз»ҲдёҖиҮҙжҖ§
RocketMQжҳҜдёҖз§ҚжңҖз»ҲдёҖиҮҙжҖ§зҡ„еҲҶеёғејҸдәӢеҠЎпјҢе°ұжҳҜиҜҙе®ғдҝқиҜҒзҡ„жҳҜж¶ҲжҒҜжңҖз»ҲдёҖиҮҙжҖ§пјҢиҖҢдёҚжҳҜеғҸ2PCгҖҒ3PCгҖҒTCCйӮЈж ·ејәдёҖиҮҙеҲҶеёғејҸдәӢеҠЎпјҢиҮідәҺдёәд»Җд№ҲиҜҙе®ғжҳҜжңҖз»ҲдёҖиҮҙжҖ§дәӢеҠЎдёӢйқўдјҡиҜҰз»ҶиҜҙжҳҺгҖӮ
Half Message(еҚҠж¶ҲжҒҜ)
жҳҜжҢҮжҡӮдёҚиғҪиў«Consumerж¶Ҳиҙ№зҡ„ж¶ҲжҒҜгҖӮProducer е·Із»ҸжҠҠж¶ҲжҒҜжҲҗеҠҹеҸ‘йҖҒеҲ°дәҶ Broker з«ҜпјҢдҪҶжӯӨж¶ҲжҒҜиў«ж Үи®°дёәжҡӮдёҚиғҪжҠ•йҖ’зҠ¶жҖҒпјҢеӨ„дәҺиҜҘз§ҚзҠ¶жҖҒдёӢзҡ„ж¶ҲжҒҜз§°дёәеҚҠж¶ҲжҒҜгҖӮйңҖиҰҒ Producer
еҜ№ж¶ҲжҒҜзҡ„дәҢж¬ЎзЎ®и®ӨеҗҺпјҢConsumerжүҚиғҪеҺ»ж¶Ҳиҙ№е®ғгҖӮ
ж¶ҲжҒҜеӣһжҹҘ
з”ұдәҺзҪ‘з»ңй—Әж®өпјҢз”ҹдә§иҖ…еә”з”ЁйҮҚеҗҜзӯүеҺҹеӣ гҖӮеҜјиҮҙ Producer з«ҜдёҖзӣҙжІЎжңүеҜ№В Half Message(еҚҠж¶ҲжҒҜ)В иҝӣиЎҢВ дәҢж¬ЎзЎ®и®ӨгҖӮиҝҷжҳҜBrockжңҚеҠЎеҷЁдјҡе®ҡж—¶жү«жҸҸй•ҝжңҹеӨ„дәҺеҚҠж¶ҲжҒҜзҡ„ж¶ҲжҒҜпјҢдјҡ
дё»еҠЁиҜўй—® Producerз«Ҝ иҜҘж¶ҲжҒҜзҡ„жңҖз»ҲзҠ¶жҖҒ(CommitжҲ–иҖ…Rollback),иҜҘж¶ҲжҒҜеҚідёәВ ж¶ҲжҒҜеӣһжҹҘгҖӮ
зҗҶи§Јиҝҷеј йҳҝйҮҢе®ҳж–№зҡ„еӣҫпјҢе°ұиғҪзҗҶи§ЈRocketMQеҲҶеёғејҸдәӢеҠЎзҡ„еҺҹзҗҶдәҶгҖӮ
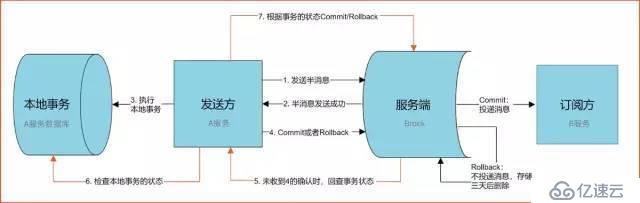
жҲ‘们жқҘиҜҙжҳҺдёӢдёҠйқўиҝҷеј еӣҫ
1гҖҒAжңҚеҠЎе…ҲеҸ‘йҖҒдёӘHalf Messageз»ҷBrockз«ҜпјҢж¶ҲжҒҜдёӯжҗәеёҰ BжңҚеҠЎ еҚіе°ҶиҰҒ+100е…ғзҡ„дҝЎжҒҜгҖӮ
2гҖҒеҪ“AжңҚеҠЎзҹҘйҒ“Half MessageеҸ‘йҖҒжҲҗеҠҹеҗҺпјҢйӮЈд№ҲејҖе§Ӣ第3жӯҘжү§иЎҢжң¬ең°дәӢеҠЎгҖӮ
3гҖҒжү§иЎҢжң¬ең°дәӢеҠЎ(дјҡжңүдёүз§Қжғ…еҶө1гҖҒжү§иЎҢжҲҗеҠҹгҖӮ2гҖҒжү§иЎҢеӨұиҙҘгҖӮ3гҖҒзҪ‘з»ңзӯүеҺҹеӣ еҜјиҮҙжІЎжңүе“Қеә”)
4.1)гҖҒеҰӮжһңжң¬ең°дәӢеҠЎжҲҗеҠҹпјҢйӮЈд№ҲProductеғҸBrockжңҚеҠЎеҷЁеҸ‘йҖҒCommit,иҝҷж ·BжңҚеҠЎе°ұеҸҜд»Ҙж¶Ҳиҙ№иҜҘmessageгҖӮ4.2)гҖҒеҰӮжһңжң¬ең°дәӢеҠЎеӨұиҙҘпјҢйӮЈд№ҲProductеғҸBrockжңҚеҠЎеҷЁеҸ‘йҖҒRollback,йӮЈд№Ҳе°ұдјҡзӣҙжҺҘеҲ йҷӨдёҠйқўиҝҷжқЎеҚҠж¶ҲжҒҜгҖӮ4.3)гҖҒеҰӮжһңеӣ дёәзҪ‘з»ңзӯүеҺҹеӣ иҝҹиҝҹжІЎжңүиҝ”еӣһеӨұиҙҘиҝҳжҳҜжҲҗеҠҹпјҢйӮЈд№Ҳдјҡжү§иЎҢRocketMQзҡ„еӣһи°ғжҺҘеҸЈ,жқҘиҝӣиЎҢдәӢеҠЎзҡ„еӣһжҹҘгҖӮд»ҺдёҠйқўжөҒзЁӢеҸҜд»Ҙеҫ—зҹҘВ еҸӘжңүAжңҚеҠЎжң¬ең°дәӢеҠЎжү§иЎҢжҲҗеҠҹ пјҢBжңҚеҠЎжүҚиғҪж¶Ҳиҙ№иҜҘmessageгҖӮ
然еҗҺжҲ‘们еҶҚжқҘжҖқиҖғеҮ дёӘй—®йўҳпјҹ
дёәд»Җд№ҲиҰҒе…ҲеҸ‘йҖҒHalf Message(еҚҠж¶ҲжҒҜ)
жҲ‘и§үеҫ—дё»иҰҒжңүдёӨзӮ№
1пјүеҸҜд»Ҙе…ҲзЎ®и®Ө BrockжңҚеҠЎеҷЁжҳҜеҗҰжӯЈеёё пјҢеҰӮжһңеҚҠж¶ҲжҒҜйғҪеҸ‘йҖҒеӨұиҙҘдәҶ йӮЈиҜҙжҳҺBrockжҢӮдәҶгҖӮ
2пјүеҸҜд»ҘйҖҡиҝҮеҚҠж¶ҲжҒҜжқҘеӣһжҹҘдәӢеҠЎпјҢеҰӮжһңеҚҠж¶ҲжҒҜеҸ‘йҖҒжҲҗеҠҹеҗҺдёҖзӣҙжІЎжңүиў«дәҢж¬ЎзЎ®и®ӨпјҢйӮЈд№Ҳе°ұдјҡеӣһжҹҘдәӢеҠЎзҠ¶жҖҒгҖӮд»Җд№Ҳжғ…еҶөдјҡеӣһжҹҘ
д№ҹдјҡжңүдёӨз§Қжғ…еҶө
1пјүжү§иЎҢжң¬ең°дәӢеҠЎзҡ„ж—¶еҖҷпјҢз”ұдәҺзӘҒ然зҪ‘з»ңзӯүеҺҹеӣ дёҖзӣҙжІЎжңүиҝ”еӣһжү§иЎҢдәӢеҠЎзҡ„з»“жһң(commitжҲ–иҖ…rollback)еҜјиҮҙжңҖз»Ҳиҝ”еӣһUNKNOWпјҢйӮЈд№Ҳе°ұдјҡеӣһжҹҘгҖӮ
2) жң¬ең°дәӢеҠЎжү§иЎҢжҲҗеҠҹеҗҺпјҢиҝ”еӣһCommitиҝӣиЎҢж¶ҲжҒҜдәҢж¬ЎзЎ®и®Өзҡ„ж—¶еҖҷзҡ„жңҚеҠЎжҢӮдәҶпјҢеңЁйҮҚеҗҜжңҚеҠЎйӮЈд№ҲиҝҷдёӘж—¶еҖҷеңЁbrockз«Ҝ е®ғиҝҳжҳҜдёӘHalf Message(еҚҠж¶ҲжҒҜ)пјҢиҝҷд№ҹдјҡеӣһжҹҘгҖӮзү№еҲ«жіЁж„Ҹ: еҰӮжһңеӣһжҹҘпјҢйӮЈд№ҲдёҖе®ҡиҰҒе…ҲжҹҘзңӢеҪ“еүҚдәӢеҠЎзҡ„жү§иЎҢжғ…еҶөпјҢеҶҚзңӢжҳҜеҗҰйңҖиҰҒйҮҚж–°жү§иЎҢжң¬ең°дәӢеҠЎгҖӮ
жғіиұЎдёӢеҰӮжһңеҮәзҺ°з¬¬дәҢз§Қжғ…еҶөиҖҢеј•иө·зҡ„еӣһжҹҘпјҢеҰӮжһңдёҚе…ҲжҹҘзңӢеҪ“еүҚдәӢеҠЎзҡ„жү§иЎҢжғ…еҶөпјҢиҖҢжҳҜзӣҙжҺҘжү§иЎҢдәӢеҠЎпјҢйӮЈд№Ҳе°ұзӣёеҪ“дәҺжҲҗеҠҹжү§иЎҢдәҶдёӨдёӘжң¬ең°дәӢеҠЎгҖӮ
дёәд»Җд№ҲиҜҙMQжҳҜжңҖз»ҲдёҖиҮҙжҖ§дәӢеҠЎ
йҖҡиҝҮдёҠйқўиҝҷе№…еӣҫпјҢжҲ‘们еҸҜд»ҘзңӢеҮәпјҢеңЁдёҠйқўдёҫдҫӢдәӢеҠЎдёҚдёҖиҮҙзҡ„дёӨз§Қжғ…еҶөдёӯпјҢж°ёиҝңдёҚдјҡеҸ‘з”ҹ
AиҙҰжҲ·еҮҸ100 пјҲеӨұиҙҘпјүпјҢBиҙҰжҲ·еҠ 100 пјҲжҲҗеҠҹпјүеӣ дёәпјҡеҰӮжһңAжңҚеҠЎжң¬ең°дәӢеҠЎйғҪеӨұиҙҘдәҶпјҢйӮЈBжңҚеҠЎж°ёиҝңдёҚдјҡжү§иЎҢд»»дҪ•ж“ҚдҪңпјҢеӣ дёәж¶ҲжҒҜеҺӢж №е°ұдёҚдјҡдј еҲ°BжңҚеҠЎгҖӮ
йӮЈд№ҲВ AиҙҰжҲ·еҮҸ100 пјҲжҲҗеҠҹпјүпјҢBиҙҰжҲ·еҠ 100 пјҲеӨұиҙҘпјүВ дјҡдёҚдјҡеҸҜиғҪеӯҳеңЁзҡ„гҖӮ
зӯ”жЎҲжҳҜдјҡзҡ„
еӣ дёәAжңҚеҠЎеҸӘиҙҹиҙЈеҪ“жҲ‘ж¶ҲжҒҜжү§иЎҢжҲҗеҠҹдәҶпјҢдҝқиҜҒж¶ҲжҒҜиғҪеӨҹйҖҒиҫҫеҲ°B,иҮідәҺBжңҚеҠЎжҺҘеҲ°ж¶ҲжҒҜеҗҺжңҖз»Ҳжү§иЎҢз»“жһңA并дёҚз®ЎгҖӮ
йӮЈBжңҚеҠЎеӨұиҙҘжҖҺд№ҲеҠһпјҹ
еҰӮжһңBжңҖз»Ҳжү§иЎҢеӨұиҙҘпјҢеҮ д№ҺеҸҜд»Ҙж–ӯе®ҡе°ұжҳҜд»Јз Ғжңүй—®йўҳжүҖд»ҘжүҚеј•иө·зҡ„ејӮеёёпјҢеӣ дёәж¶Ҳиҙ№з«ҜRocketMQжңүйҮҚиҜ•жңәеҲ¶пјҢеҰӮжһңдёҚжҳҜд»Јз Ғй—®йўҳдёҖиҲ¬йҮҚиҜ•еҮ ж¬Ўе°ұиғҪжҲҗеҠҹгҖӮ
еҰӮжһңжҳҜд»Јз Ғзҡ„еҺҹеӣ еј•иө·еӨҡж¬ЎйҮҚиҜ•еӨұиҙҘеҗҺпјҢд№ҹжІЎжңүе…ізі»пјҢе°ҶиҜҘејӮеёёи®°еҪ•дёӢжқҘпјҢз”ұдәәе·ҘеӨ„зҗҶпјҢдәәе·Ҙе…ңеә•еӨ„зҗҶеҗҺпјҢе°ұеҸҜд»Ҙи®©дәӢеҠЎиҫҫеҲ°жңҖз»Ҳзҡ„дёҖиҮҙжҖ§гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ